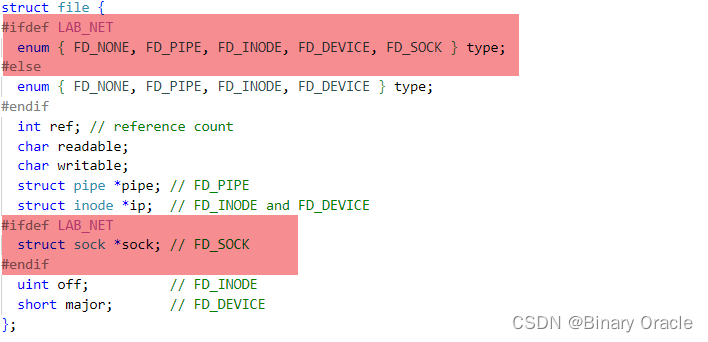
MIT 6.S081 Lab 11 -- NetWork -- 下
- 引言
- 代码解析
- 网络子系统初始化
- 相关数据结构
- lab 分析
- e1000_transmit函数实现
- e1000_recv函数实现
- socket write全流程分析
- socket read全流程分析
- socket关闭
- ARP数据报的发送与接收
引言
本文为 MIT 6.S081 2020 操作系统 实验十一解析。
MIT 6.S081课程前置基础参考: 基于RISC-V搭建操作系统系列
上一节我们总体介绍了一下手册中有关数据接收和传输的章节,本节借助上节的基础来完成lab的具体代码实现。
代码解析
网络子系统初始化
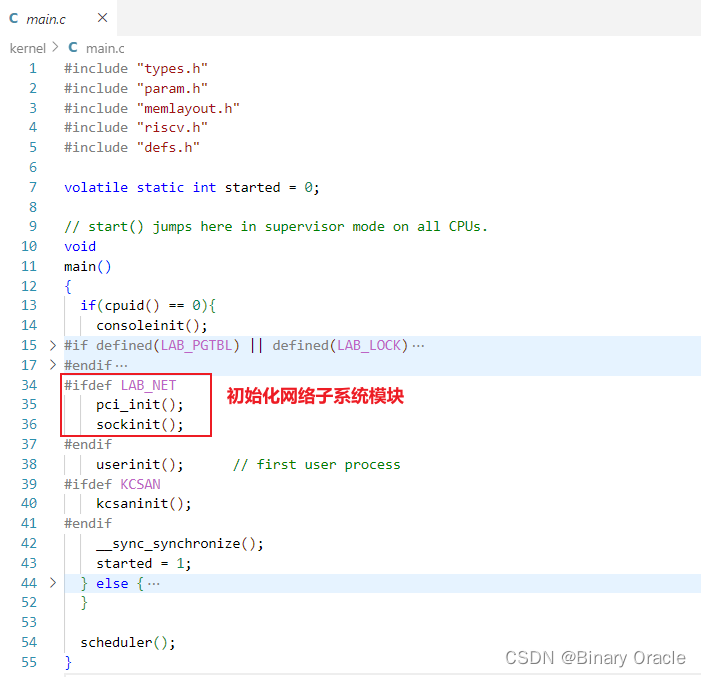
- pci_init函数源码如下:
void
pci_init()
{
// we'll place the e1000 registers at this address.
// vm.c maps this range.
// e1000寄存器的地址
uint64 e1000_regs = 0x40000000L;
// qemu -machine virt puts PCIe config space here.
// vm.c maps this range.
// PCI配置空间的地址
uint32 *ecam = (uint32 *) 0x30000000L;
// look at each possible PCI device on bus 0.
// "bus 0"指的是PCI总线上的第一个总线
// 使用循环遍历PCI总线上每个设备
for(int dev = 0; dev < 32; dev++){
int bus = 0;
int func = 0;
int offset = 0;
// 构造访问PCI配置空间的偏移量(offset)
uint32 off = (bus << 16) | (dev << 11) | (func << 8) | (offset);
// 通过将基地址(ecam)与偏移量相加,得到指向设备的寄存器的指针(base)
volatile uint32 *base = ecam + off;
// 读取设备的ID
uint32 id = base[0];
// 100e:8086 is an e1000
// 判断是否为e1000网卡
if(id == 0x100e8086){
// command and status register.
// bit 0 : I/O access enable
// bit 1 : memory access enable
// bit 2 : enable mastering
// 使能I/O访问,内存访问和主控
base[1] = 7;
__sync_synchronize();
// 对设备的BAR(Base Address Registers)进行处理,通过向BAR写入全1的值,然后再恢复原来的值,从而获取BAR的大小
// 通过将全1的值写入BAR寄存器,促使设备对BAR进行处理,并返回BAR对应资源的大小。
// 设备在接收到全1的值后,会将其替换为对应资源的大小值。将原始值重新写回BAR寄存器是为了保持原有的基地址信息。
for(int i = 0; i < 6; i++){
uint32 old = base[4+i];
// writing all 1's to the BAR causes it to be
// replaced with its size.
base[4+i] = 0xffffffff;
__sync_synchronize();
base[4+i] = old;
}
// tell the e1000 to reveal its registers at
// physical address 0x40000000.
// 将e1000寄存器的物理地址设置给e1000网卡的BAR,使其将寄存器映射到该地址
base[4+0] = e1000_regs;
// 对e1000网卡进行初始化,传递e1000寄存器的地址作为参数
e1000_init((uint32*)e1000_regs);
}
}
}
- e1000_init函数
// called by pci_init().
// xregs is the memory address at which the
// e1000's registers are mapped.
void
e1000_init(uint32 *xregs)
{
int i;
initlock(&e1000_lock, "e1000");
// 拿到e1000寄存器的内存地址
regs = xregs;
// Reset the device
// 重置设备: 禁用中断->触发设置重置操作->再次禁用中断
regs[E1000_IMS] = 0; // disable interrupts
regs[E1000_CTL] |= E1000_CTL_RST;
regs[E1000_IMS] = 0; // redisable interrupts
__sync_synchronize();
// [E1000 14.5] Transmit initialization
// 传输初始化
// 1.tx_ring传输描述符数组清空
memset(tx_ring, 0, sizeof(tx_ring));
// 2.设置每个传输描述符状态为可用
for (i = 0; i < TX_RING_SIZE; i++) {
tx_ring[i].status = E1000_TXD_STAT_DD;
tx_mbufs[i] = 0;
}
// 将传输描述符数组基地址赋值给传输描述符基地址寄存器
regs[E1000_TDBAL] = (uint64) tx_ring;
if(sizeof(tx_ring) % 128 != 0)
panic("e1000");
// 设置传输描述符长度寄存器
regs[E1000_TDLEN] = sizeof(tx_ring);
// 设置传输描述符头寄存器和尾寄存器
regs[E1000_TDH] = regs[E1000_TDT] = 0;
// [E1000 14.4] Receive initialization
// 接收初始化
// 1.rx_ring接收描述符数组清空
memset(rx_ring, 0, sizeof(rx_ring));
// 2.为每个接收描述符每个一个mbuf
for (i = 0; i < RX_RING_SIZE; i++) {
rx_mbufs[i] = mbufalloc(0);
if (!rx_mbufs[i])
panic("e1000");
rx_ring[i].addr = (uint64) rx_mbufs[i]->head;
}
// 将接收描述符数组基地址赋值给接收描述符基地址寄存器
regs[E1000_RDBAL] = (uint64) rx_ring;
if(sizeof(rx_ring) % 128 != 0)
panic("e1000");
// 设置接收描述符头寄存器,尾寄存器和长度寄存器
regs[E1000_RDH] = 0;
regs[E1000_RDT] = RX_RING_SIZE - 1;
regs[E1000_RDLEN] = sizeof(rx_ring);
// 下面是设置Filter Registers,也就是数据接收前,网卡相关filter会进行过滤
// filter by qemu's MAC address, 52:54:00:12:34:56
// 通过将指定的MAC地址写入RA寄存器和RA+1寄存器,可以配置网络接口控制器只接收特定MAC地址的数据包
regs[E1000_RA] = 0x12005452;
regs[E1000_RA+1] = 0x5634 | (1<<31);
// multicast table
// 循环将MTA寄存器中的值设置为零来清除多播表的所有条目
// 这意味着网络接口控制器将不会处理任何多播数据包,因为多播表中的所有条目都被清除
for (int i = 0; i < 4096/32; i++)
regs[E1000_MTA + i] = 0;
// transmitter control bits.
// 设置传输控制寄存器
regs[E1000_TCTL] =
// 当将传输器控制寄存器(TCTL)中的使能位(EN)设置为1时,传输器将启用。如果将该位设置为0,传输器将在发送完正在进行的数据包后停止传输。
// 数据将保留在传输FIFO中,直到设备重新启用。如果希望清空传输FIFO中的数据包,软件应将此操作与复位操作结合使用。
E1000_TCTL_EN | // enable
// 根据 "Pad Short Packets" 位的设置,可以决定是否对短数据包进行填充,以达到最小数据包长度的要求
E1000_TCTL_PSP | // pad short packets
// "Collision Threshold" 是一个决定重新传输尝试次数的参数。当发送数据包时,如果发生了冲突(即多个设备同时发送数据导致冲突),则将根据冲突阈值进行重传
(0x10 << E1000_TCTL_CT_SHIFT) | // collision stuff
// 为了使CSMA/CD操作能够有效工作,数据包在传输过程中会进行填充,以确保在发生冲突时能够检测到。填充使用的是特殊符号而不是有效的数据字节
(0x40 << E1000_TCTL_COLD_SHIFT);
// 设置了传输器间隙寄存器的值,以确定发送数据包之间的间隙时间
regs[E1000_TIPG] = 10 | (8<<10) | (6<<20); // inter-pkt gap
// receiver control bits.
regs[E1000_RCTL] =
// 当将接收器使能位(Receiver Enable)设置为1时,接收器将启用。
// 如果将该位设置为0,则在接收任何正在进行的数据包后停止接收。数据将保留在接收FIFO中,直到设备重新启用。
E1000_RCTL_EN | // enable receiver
// 设置为1时,网络接口控制器将接收并传递所有接收到的广播数据包,而不进行过滤操作
// 设置为0时,网络接口控制器只有在广播数据包通过过滤器匹配时,才会接受或拒绝广播数据包
E1000_RCTL_BAM | // enable broadcast
// 控制接收缓冲区的大小的参数
E1000_RCTL_SZ_2048 | // 2048-byte rx buffers
// 是否从接收的数据包中去除以太网CRC字段
E1000_RCTL_SECRC; // strip CRC
// ask e1000 for receive interrupts.
// 将接收延迟时间寄存器(Receive Delay Timer Register,RDTR)设置为0。这意味着在每接收到一个数据包后,将立即触发接收中断,而不使用定时器来控制中断触发。
regs[E1000_RDTR] = 0; // interrupt after every received packet (no timer)
// 将接收中断延迟寄存器(Receive Interrupt Delay Register,RADV)设置为0。这意味着在每个数据包后立即触发接收中断,而不使用定时器来控制中断触发。
regs[E1000_RADV] = 0; // interrupt after every packet (no timer)
// 接收描述符写回操作触发中断
regs[E1000_IMS] = (1 << 7); // RXDW -- Receiver Descriptor Write Back
}
相关数据结构
- mbuf数据包缓冲区
// kernel/net.h
#define MBUF_SIZE 2048
struct mbuf {
struct mbuf *next; // the next mbuf in the chain
char *head; // the current start position of the buffer
unsigned int len; // the length of the buffer
char buf[MBUF_SIZE]; // the backing store
};
// Allocates a packet buffer.
// 分配一个空闲数据包缓冲区
struct mbuf *
mbufalloc(unsigned int headroom)
{
struct mbuf *m;
if (headroom > MBUF_SIZE)
return 0;
// 分配一个空闲物理页
m = kalloc();
if (m == 0)
return 0;
m->next = 0;
m->head = (char *)m->buf + headroom;
m->len = 0;
memset(m->buf, 0, sizeof(m->buf));
return m;
}
// Frees a packet buffer.
void
mbuffree(struct mbuf *m)
{
kfree(m);
}
- 传输描述符
// kernel/e1000_dev.h
// [E1000 3.3.3] -- 每个字段具体含义可参考上一小节
struct tx_desc
{
uint64 addr;
uint16 length;
uint8 cso;
uint8 cmd;
uint8 status;
uint8 css;
uint16 special;
};

- 接收描述符
// kernel/e1000_dev.h
// [E1000 3.2.3] -- 每个字段具体含义可参考上一小节
struct rx_desc
{
uint64 addr; /* Address of the descriptor's data buffer */
uint16 length; /* Length of data DMAed into data buffer */
uint16 csum; /* Packet checksum */
uint8 status; /* Descriptor status */
uint8 errors; /* Descriptor Errors */
uint16 special;
};
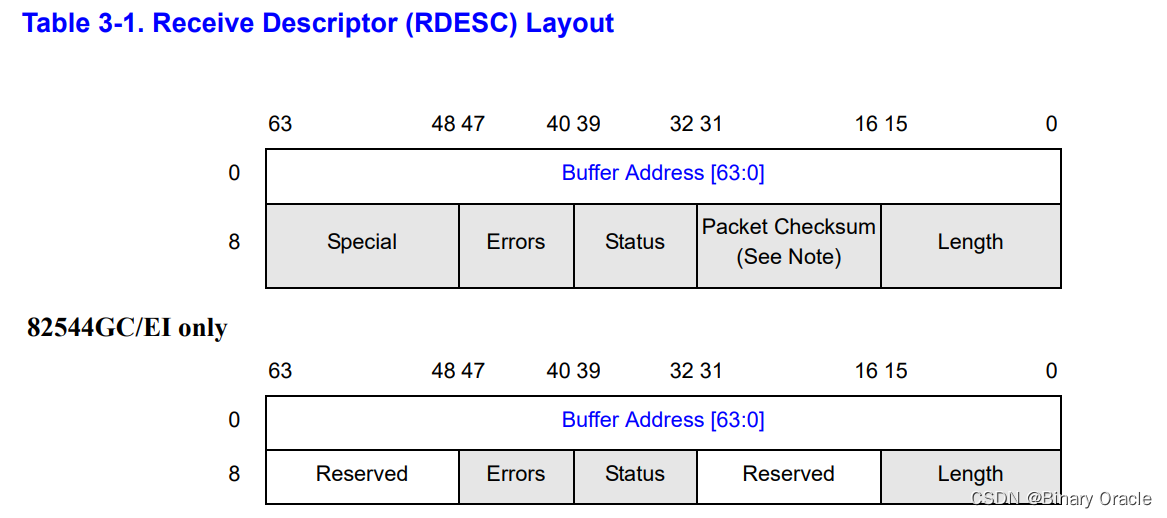
- 传输/接收描述符数组
// kernel/e1000_dev.h
#define TX_RING_SIZE 16
static struct tx_desc tx_ring[TX_RING_SIZE] __attribute__((aligned(16)));
static struct mbuf *tx_mbufs[TX_RING_SIZE];
#define RX_RING_SIZE 16
static struct rx_desc rx_ring[RX_RING_SIZE] __attribute__((aligned(16)));
static struct mbuf *rx_mbufs[RX_RING_SIZE];
lab 分析
本实验的关键在于理解 E1000 网卡硬件与驱动软件的交互逻辑以及相关的数据结构,实验要求实现的两个函数:
- 一个对于网卡驱动发送数据
- 一个对于驱动接收数据.
在驱动的数据结构中, 主要为发送和接收数据的两个循环队列. 其中每个队列实际上又分为描述符队列和缓冲区指针队列, 缓冲区队列依附于描述符队列, 同时有网卡寄存器记录着队列的首尾指针, 这种设计遵循传统的驱动设计方案, 首指针由硬件管理, 尾指针有软件管理, 二者通过队列满足并发的需要.
待实现的 e1000_transmit() 函数用于将要发送的数据放入循环队列尾部, 后续由网卡硬件将数据包进行发送:
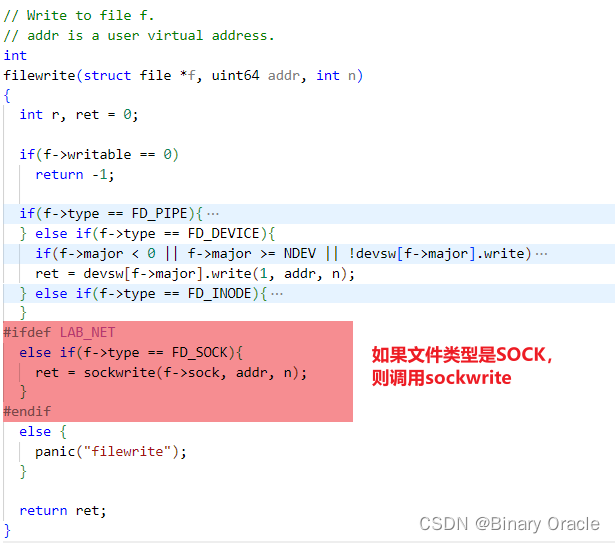
- 根据函数调用关系, 最上层是通过文件描述符的 filewrite() 函数调用到写套接字函数 sockwrite()
- 在该函数中会通过 mbufalloc() 函数分配一个缓冲区用于写入数据
- 接着会嵌套调用 net_tx_udp(), net_tx_ip() 以及 net_tx_eth() 函数, 依次进行 UDP 报文, IP 数据包以及以太网帧的封装
- 最终在 net_tx_eth() 中调用 e1000_transmit() 发送数据到网卡的发送队列, 后续再由网卡硬件完成发送.
待实现的 e1000_recv() 函数则是由网卡的中断处理程序 e1000_intr() 调用:
- 即网卡硬件收到数据(以太网帧)后会触发中断, 由中断处理程序对数据进行处理.
- 在 e1000_recv() 中会调用 net_rx() 对收到的数据帧进行解封装
- 之后会根据数据包类型分别调用 net_rx_ip() 或 net_rx_arp() 进行 IP 数据包或 ARP 数据包的解封装
- 对于 IP 数据包, 会进一步调用 net_rx_udp() 解封装 UDP 报文, 然后调用 sockrecvudp() 函数
- 其中会调用 mbufq_pushtail() 函数将报文放入一个队列, 在使用 sockread() 读取报文时, 实际上就是通过 mbufq_pophead() 函数从该队列中取出一个报文内容
- 而若队列为空, 则会将线程休眠直至队列有数据时被唤醒. 而对于 ARP 报文, 其本身不再有传输层报文, 而是会调用 net_tx_arp() 进行一个 ARP 报文的回复
待实现的两个函数的作用即驱动程序将以太网帧写入驱动的发送队列, 或是将以太网帧从驱动的接收队列取出并解封装.
e1000_transmit函数实现
实现 kernel/e1000.c 中的 e1000_transmit() 函数, 以完成发送以太网数据帧到网卡的工作:
- 首先需要说明的是网卡的发送数据队列 tx_ring, 其中每个元素是一个发送数据描述符, 同时有 addr 字段指向发送的以太网帧数据的缓冲区地址, 对应 tx_mbufs.
- 根据开发手册 3.4 节描述的发送描述符的队列结构,这其中涉及了队列在内存的地址(E1000_TDBAL )和长度(E1000_TDLEN), 队列的首(E1000_TDH)尾(E1000_TDT)指针
- 这些变量都在对应的寄存器中, 可由 regs 数组进行访问
- 在 kernel/e1000.c 的 e1000_init() 函数中, 会进行发送初始化, 会对以上变量进行初始化.
其中, 最需要关注的是发送队列的首(E1000_TDH)尾(E1000_TDT)指针:
- 发送首指针指向输出队列下一个待输出的描述符, 由网卡硬件维护并更新该指针
- 发送尾指针则指向第一个软件可以写入的描述符的位置, 即由网卡驱动软件维护该指针
- 在 e1000_init() 中, 这两个指针也被初始化为了 0.
具体 e1000_transmit() 的实现, 可以按照实验指导的提示进行完成:
- 首先通过读取发送尾指针对应的寄存器 regs[E1000_TDT] 获取到软件可以写入的位置, 也就是后续放入下一个数据帧的发送队列的索引.
- 检查尾指针指向的描述符是否在状态中写入了 E1000_TXD_STAT_DD标志位. 根据开发手册 3.3.3.2 节关于 DD 标志位的描述, 该标志位会在描述符的数据被处理完成后设置. 因此未设置该标志位的描述符其数据仍未被硬件完成传输, 因此此时还不能进行数据写入, 返回失败.
- 这里实验指导中说是检查"溢出(overflowing)", 但是并未通过检查队满条件 (Tail+1)%Size==Head 判断的, 而是通过 DD 标志位, 根据开发手册, Head 指向的是由硬件所有的描述符的起始位置, 等待发送, 其 DD 标志位理论上还未被设置, 所以若遇到 DD 位未被设置的描述符, 则可说明队列已满.
- 检查尾指针执行的描述符对应的缓冲区是否被释放, 若未被释放使用 mbuffree() 进行释放.
- 更新尾指针指向的描述符的 addr 字段指向数据帧缓冲区的头部 m->head, length 字段记录数据帧的长度 m->len. 在上文也提到过, e1000_transmit() 是网络栈最后进行调用, 在上层 sockwrite() 中分配的缓冲区 m, 同时在一层层封装时会更新缓冲区头部(首地址)的位置字段 m->head
- 更新尾指针指向的描述符的 cmd 字段. 在 kernel/e1000_dev.h 中, 关于描述符 command 定义了 E1000_TXD_CMD_EOP 和 E1000_TXD_CMD_RS 两个标志位, 因此容易想到很可能设置的标志位与这两个有关. 根据开发手册 3.3.3.1 节, 容易判断出 EOP 标志位表示数据包的结束, 因此需要被设置
- RS 字段用于报告状态信息, 只有设置了该字段, 描述符的 status 字段才是有效的, 而网卡将数据包发送完成后会设置 DD 状态, 因此此处也需要对描述符设置 RS 标志位.
- 将数据帧缓冲区 m 记录到缓冲区队列 mbuf 中用于之后的释放. 这里是为步骤 3 做准备的. 数据帧的缓冲区 m 在此时还未被网卡硬件发送因此不能释放, 因此会将其记录到描述符对应的缓冲区队列中, 当后续尾指针又指向该位置时再将其释放.
- 最后即更新发送尾指针,而在这之前需要使用 __sync_synchronize() 来设置内存屏障. 这么做的原因是确保描述符的 cmd 字段设置完成后才会更新尾指针, 避免可能的指令重排导致描述符还未更新完毕就移动了尾指针.
- 由于 e1000_transmit() 上层由 sockwrite() 调用, 可能有多个进程同时调用该函数, 因此需要保证发送队列的指针的并发安全. 结合 e1000_init() 中初始化的 e1000_lock, 此处需要在整个操作过程前后加上锁, 以保证过程中只能有一个进程对队列尾指针进行访问及加载数据到发送队列.
int
e1000_transmit(struct mbuf *m)
{
//
// Your code here.
//
// the mbuf contains an ethernet frame; program it into
// the TX descriptor ring so that the e1000 sends it. Stash
// a pointer so that it can be freed after sending.
//
uint32 tail;
struct tx_desc *desc;
acquire(&e1000_lock);
tail = regs[E1000_TDT];
desc = &tx_ring[tail];
// check if the ring is overflowing
if ((desc->status & E1000_TXD_STAT_DD) == 0) {
release(&e1000_lock);
return -1;
}
// free the last mbuf that was transmitted
if (tx_mbufs[tail]) {
mbuffree(tx_mbufs[tail]);
}
// fill in the descriptor
desc->addr = (uint64) m->head;
desc->length = m->len;
// 当前为最后一个数据包
desc->cmd = E1000_TXD_CMD_EOP | E1000_TXD_CMD_RS;
tx_mbufs[tail] = m;
// a barrier to prevent reorder of instructions
__sync_synchronize();
regs[E1000_TDT] = (tail + 1) % TX_RING_SIZE;
release(&e1000_lock);
return 0;
}
e1000_recv函数实现
实现 kernel/e1000.c 中的 e1000_recv() 函数, 以完成从网卡接收数据到内核的工作.
网卡接收数据同样有接收队列 rx_ring 及其缓冲区 rx_mbufs. 逻辑与发送队列基本相同, 具体可见开发手册 3.2.6 节.
- 这里比较特殊的一点在于接收队列的尾指针 RDT, 其应该表示第一个网卡驱动软件可以写的描述符. 但在 e1000_init() 初始化时, RDT 的值为接收队列大小 Size-1, 即队列的末尾;
- 同时在实验指导中, 需要通过读取 (regs[E1000_RDT]+1)%RX_RING_SIZE 来确定进行解封装的数据帧, 而非直接读取 regs[E1000_RDT].
- 因此可以推断出, 接收尾指针指向的是已被软件处理的数据帧, 其下一个才为当前需要处理的数据帧. 这与发送队列的尾指针是有所区别的, 如下图所示
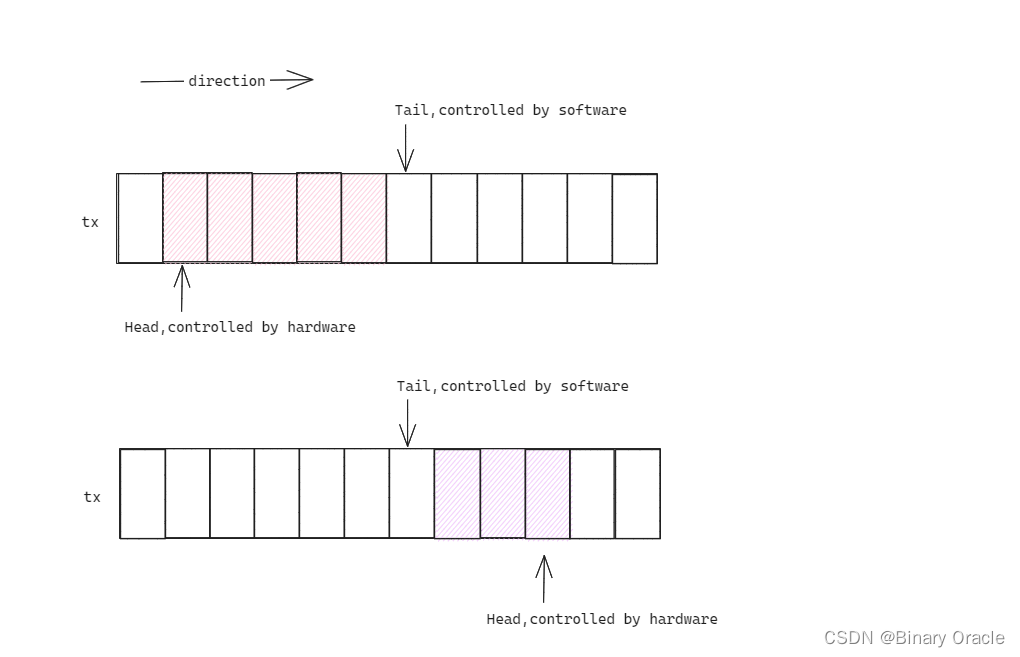
具体 e1000_recv() 的实现, 同样可以按照实验指导的提示进行完成:
- 首先通过读取接收尾指针对应的寄存器并加 1 取余 (regs[E1000_RDT]+1)%RX_RING_SIZE 获取到软件可以读取的位置, 也就是接收且未被软件处理的第一个数据帧在接收队列的索引. 该位置即软件需要解封装的数据帧的描述符.
- 与发送数据类似, 需要检查数据帧状态的 E1000_RXD_STAT_DD 标志位, 以确定当前的数据帧已被网卡硬件处理完毕, 可以由内核解封装. 否则则停止.
- 接收缓冲区 rx_mbufs[idx] 中为待处理的数据帧, 首先将其长度记录到描述符的 length 字段, 然后调用 net_rx() 传递给网络栈进行解封装.
- 调用 mbufalloc() 分配一个新的接收缓冲区替代发送给网络栈的缓冲区, 并更新描述符的 addr 字段, 指向新的缓冲区.
- 这里也能看出与发送缓冲区队列不同的地方, 发送缓冲区队列初始时全为空指针, 而缓冲区实际由 sockwrite() 分配, 在最后时绑定到缓冲区队列中, 主要是为了方便后续释放缓冲区.
- 而接收缓冲区队列在初始化时全部都已分配, 由内核解封装后释放内存.
- 而此处由于缓冲区已经交由网络栈去解封装, 因此需要替换成一个新的缓冲区用于下一次硬件接收数据.
- 由于替换了接收缓冲区, 此时描述符相当于更新为一个用于后续硬件接收数据的新的描述符, 因此需要清空 status 状态字段.
- 在实验指导中指出可能之前到达的数据包超过队列大小, 需要进行处理. 这里笔者考虑的是通过在 e1000_recv() 添加循环, 从而让一次中断触发后网卡软件会一直将可解封装的数据传递到网络栈, 以避免队列中的可处理数据帧的堆积来避免上述情况. 而终止条件即当前描述符的 DD 标志位未被设置, 则证明当前数据还未由硬件处理完毕.
- 最后更新接收尾指针 RDT. 需要注意的是, 正如前文所述, 尾指针需要指向最后一个已被软件处理的描述符, 是终止上述循环时的描述符的前一个. 此外, 此处没有使用 __sync_synchronize() 添加内存屏障(实际上可以添加到更新尾指针前), 原因是考虑到 while 循环的存在, 理论上更新尾指针的语句不会发生指令重排.
- 而关于锁的问题, 与发送数据不同, 接收时该函数只会被中断处理函数 e1000_intr() 调用, 因此不会出现并发的情况; 此外, 网卡的接收和发送的数据结构是独立的, 没有共享, 因此无需加锁. 且需要注意的是, 此处也不能使用 e1000_lock 进行加锁, 因为当接收到 ARP 报文时, 会在解封装的同时调用 net_tx_arp() 发送回复报文, 便会导致死锁 .
static void
e1000_recv(void)
{
//
// Your code here.
//
// Check for packets that have arrived from the e1000
// Create and deliver an mbuf for each packet (using net_rx()).
//
int tail = (regs[E1000_RDT] + 1) % RX_RING_SIZE;
struct rx_desc *desc = &rx_ring[tail];
while ((desc->status & E1000_RXD_STAT_DD)) {
if(desc->length > MBUF_SIZE) {
panic("e1000 len");
}
// update the length reported in the descriptor.
rx_mbufs[tail]->len = desc->length;
// deliver the mbuf to the network stack
net_rx(rx_mbufs[tail]);
// allocate a new mbuf replace the one given to net_rx()
rx_mbufs[tail] = mbufalloc(0);
if (!rx_mbufs[tail]) {
panic("e1000 no mubfs");
}
desc->addr = (uint64) rx_mbufs[tail]->head;
desc->status = 0;
tail = (tail + 1) % RX_RING_SIZE;
desc = &rx_ring[tail];
}
regs[E1000_RDT] = (tail - 1) % RX_RING_SIZE;
}
socket write全流程分析
本节,我们来完整过一遍数据包发送的完整流程,从nettest测试程序的ping函数开始:
// user/nettest.c
// send a UDP packet to the localhost (outside of qemu),
// and receive a response.
static void
ping(uint16 sport, uint16 dport, int attempts)
{
int fd;
char *obuf = "a message from xv6!";
uint32 dst;
// 10.0.2.2, which qemu remaps to the external host,
// i.e. the machine you're running qemu on.
// 目的IP地址
dst = (10 << 24) | (0 << 16) | (2 << 8) | (2 << 0);
// you can send a UDP packet to any Internet address
// by using a different dst.
// 建立UDP连接--目的ip地址,源端口和目的端口--返回对应socket文件的fd
if((fd = connect(dst, sport, dport)) < 0){
fprintf(2, "ping: connect() failed\n");
exit(1);
}
for(int i = 0; i < attempts; i++) {
// 向UDP Socket写入数据
if(write(fd, obuf, strlen(obuf)) < 0){
fprintf(2, "ping: send() failed\n");
exit(1);
}
}
...
}
- 首先第一步是通过connect系统调用建立UDP连接
// kernel/sysfile.c
int
sys_connect(void)
{
struct file *f;
int fd;
uint32 raddr;
uint32 rport;
uint32 lport;
// 获取系统调用参数: 目的IP地址,源端口和目的端口
if (argint(0, (int*)&raddr) < 0 ||
argint(1, (int*)&lport) < 0 ||
argint(2, (int*)&rport) < 0) {
return -1;
}
// 分配一个空闲socket
if(sockalloc(&f, raddr, lport, rport) < 0)
return -1;
// 从当前进程fd列表中分配一个空闲fd
if((fd=fdalloc(f)) < 0){
fileclose(f);
return -1;
}
return fd;
}
scokalloc用于分配一个新的socket对象:
// kernel/sysnet.c
struct sock {
struct sock *next; // the next socket in the list
uint32 raddr; // the remote IPv4 address
uint16 lport; // the local UDP port number
uint16 rport; // the remote UDP port number
struct spinlock lock; // protects the rxq
struct mbufq rxq; // a queue of packets waiting to be received
};
static struct spinlock lock;
static struct sock *sockets;
// socket文件指针,目的ip地址,源端口,目的端口
int
sockalloc(struct file **f, uint32 raddr, uint16 lport, uint16 rport)
{
struct sock *si, *pos;
si = 0;
*f = 0;
// 从全局文件列表中分配一个空闲文件
if ((*f = filealloc()) == 0)
goto bad;
// 分配一个新的socket
if ((si = (struct sock*)kalloc()) == 0)
goto bad;
// initialize objects
// 将通信信息赋值给socket
si->raddr = raddr;
si->lport = lport;
si->rport = rport;
initlock(&si->lock, "sock");
// 初始化当前socket用于暂存数据包的队列
mbufq_init(&si->rxq);
// 设置文件类型为SOCK,可读可写
(*f)->type = FD_SOCK;
(*f)->readable = 1;
(*f)->writable = 1;
// 设置文件的socket实例位si
(*f)->sock = si;
// add to list of sockets
acquire(&lock);
pos = sockets;
// 这里是检查三元组是否重复<目的IP地址,源端口,目的端口>
while (pos) {
if (pos->raddr == raddr &&
pos->lport == lport &&
pos->rport == rport) {
release(&lock);
goto bad;
}
pos = pos->next;
}
// 将新分配的socket加入链表
si->next = sockets;
sockets = si;
release(&lock);
return 0;
bad:
if (si)
kfree((char*)si);
if (*f)
fileclose(*f);
return -1;
}
- 第二步是通过write系统调用向socket文件写入数据
sockwrite用于向socket写入数据:
// 数据包header头部默认占据的大小
#define MBUF_DEFAULT_HEADROOM 128
int
sockwrite(struct sock *si, uint64 addr, int n)
{
struct proc *pr = myproc();
struct mbuf *m;
// 分配一个空闲数据包缓冲区
m = mbufalloc(MBUF_DEFAULT_HEADROOM);
if (!m)
return -1;
// 向mbuf缓冲区中写入数据,数据来自用户态虚拟地址addr,写入数据长度为n
if (copyin(pr->pagetable, mbufput(m, n), addr, n) == -1) {
mbuffree(m);
return -1;
}
// 将数据包传递给UDP处理函数
net_tx_udp(m, si->raddr, si->lport, si->rport);
return n;
}
// Allocates a packet buffer.
// 分配一个空闲数据包缓冲区
struct mbuf *
mbufalloc(unsigned int headroom)
{
struct mbuf *m;
if (headroom > MBUF_SIZE)
return 0;
// 分配一个空闲物理页
m = kalloc();
if (m == 0)
return 0;
m->next = 0;
m->head = (char *)m->buf + headroom;
m->len = 0;
memset(m->buf, 0, sizeof(m->buf));
return m;
}
// Appends data to the end of the buffer and returns a pointer to it.
char *
mbufput(struct mbuf *m, unsigned int len)
{
// 当前mbuf缓存区数据起始写入位置=数据包头占据大小+已有数据占据大小
char *tmp = m->head + m->len;
// len用于记录当前mbuf缓冲区内数据量大小
m->len += len;
if (m->len > MBUF_SIZE)
panic("mbufput");
return tmp;
}
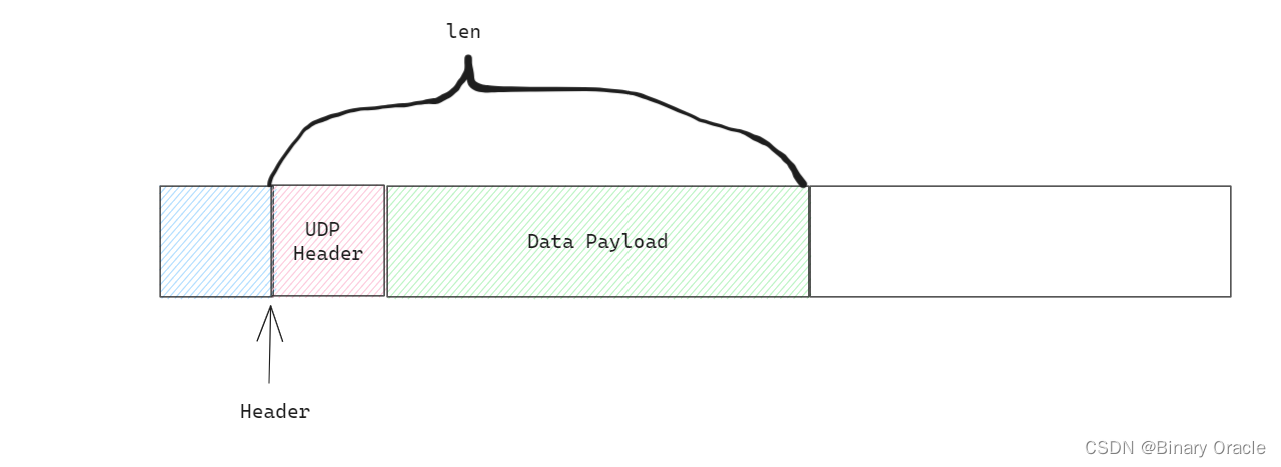
- mbuf传递给UDP层处理函数
#define mbufpushhdr(mbuf, hdr) (typeof(hdr)*)mbufpush(mbuf, sizeof(hdr))
// a UDP packet header (comes after an IP header).
struct udp {
uint16 sport; // source port
uint16 dport; // destination port
uint16 ulen; // length, including udp header, not including IP header
uint16 sum; // checksum
};
// sends a UDP packet
void
net_tx_udp(struct mbuf *m, uint32 dip,
uint16 sport, uint16 dport)
{
struct udp *udphdr;
// put the UDP header -- 填入UDP头部
// mbufpushhdr是宏定义,上面已经给出
udphdr = mbufpushhdr(m, *udphdr);
udphdr->sport = htons(sport);
udphdr->dport = htons(dport);
udphdr->ulen = htons(m->len);
udphdr->sum = 0; // zero means no checksum is provided
// now on to the IP layer --
// 将填充好UDP头部的数据包传递给IP层处理
// mbuf,本层使用UDP协议,目的ip地址
net_tx_ip(m, IPPROTO_UDP, dip);
}
// Prepends data to the beginning of the buffer and returns a pointer to it.
char *
mbufpush(struct mbuf *m, unsigned int len)
{
m->head -= len;
if (m->head < m->buf)
panic("mbufpush");
m->len += len;
return m->head;
}
- 填充好UDP header的mbuf传递到ip层处理
// an IP packet header (comes after an Ethernet header).
struct ip {
uint8 ip_vhl; // version << 4 | header length >> 2
uint8 ip_tos; // type of service
uint16 ip_len; // total length
uint16 ip_id; // identification
uint16 ip_off; // fragment offset field
uint8 ip_ttl; // time to live
uint8 ip_p; // protocol
uint16 ip_sum; // checksum
uint32 ip_src, ip_dst;
};
// sends an IP packet
static void
net_tx_ip(struct mbuf *m, uint8 proto, uint32 dip)
{
struct ip *iphdr;
// push the IP header -- 填充ip头部
iphdr = mbufpushhdr(m, *iphdr);
memset(iphdr, 0, sizeof(*iphdr));
// 设置IP版本和头部长度字段
iphdr->ip_vhl = (4 << 4) | (20 >> 2);
// 设置IP数据报上层使用的协议
iphdr->ip_p = proto;
// 设置源ip和目的ip
iphdr->ip_src = htonl(local_ip);
iphdr->ip_dst = htonl(dip);
// 设置data payload长度
iphdr->ip_len = htons(m->len);
// 设置IP数据报的生存时间(TTL)字段
iphdr->ip_ttl = 100;
// 计算并设置IP头部的校验和字段。校验和用于检测IP头部是否在传输过程中发生了错误或损坏
iphdr->ip_sum = in_cksum((unsigned char *)iphdr, sizeof(*iphdr));
// now on to the ethernet layer
// 将填充好ip头的mbuf传递到数据链路层,并告诉下一层,本层使用IP协议
net_tx_eth(m, ETHTYPE_IP);
}
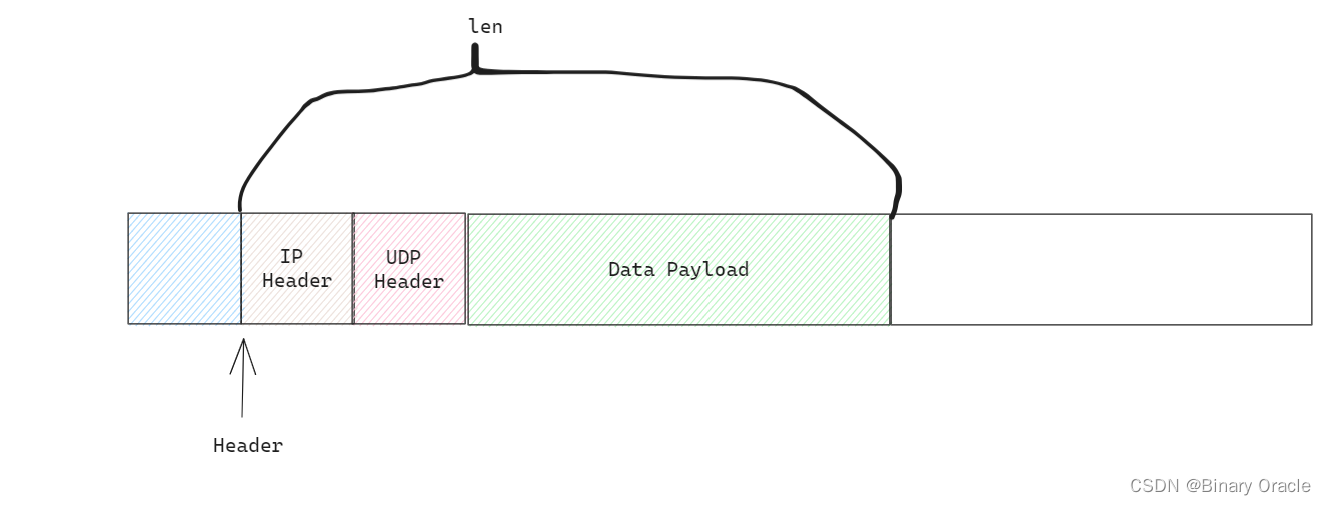
- 填充好ip头的mbuf传递给数据链路层,进行以太网header填充
static uint8 local_mac[ETHADDR_LEN] = { 0x52, 0x54, 0x00, 0x12, 0x34, 0x56 };
static uint8 broadcast_mac[ETHADDR_LEN] = { 0xFF, 0XFF, 0XFF, 0XFF, 0XFF, 0XFF };
// an Ethernet packet header (start of the packet).
struct eth {
uint8 dhost[ETHADDR_LEN];
uint8 shost[ETHADDR_LEN];
uint16 type;
} __attribute__((packed));
// sends an ethernet packet
static void
net_tx_eth(struct mbuf *m, uint16 ethtype)
{
struct eth *ethhdr;
// 填充以太网头部
ethhdr = mbufpushhdr(m, *ethhdr);
// 将本地MAC地址复制到以太网头部的源MAC地址字段
memmove(ethhdr->shost, local_mac, ETHADDR_LEN);
// In a real networking stack, dhost would be set to the address discovered
// through ARP. Because we don't support enough of the ARP protocol, set it
// to broadcast instead.
// 在真实的网络协议栈中,dhost应该被设置为通过ARP协议发现的目标设备的MAC地址。
// 由于本示例中并不完全支持ARP协议,将dhost设置为广播地址(broadcast)。
memmove(ethhdr->dhost, broadcast_mac, ETHADDR_LEN);
// 设置上层协议类型
ethhdr->type = htons(ethtype);
// 调用e1000驱动函数,传输mbuf
if (e1000_transmit(m)) {
// 传输成功后,释放当前mbuf
mbuffree(m);
}
}
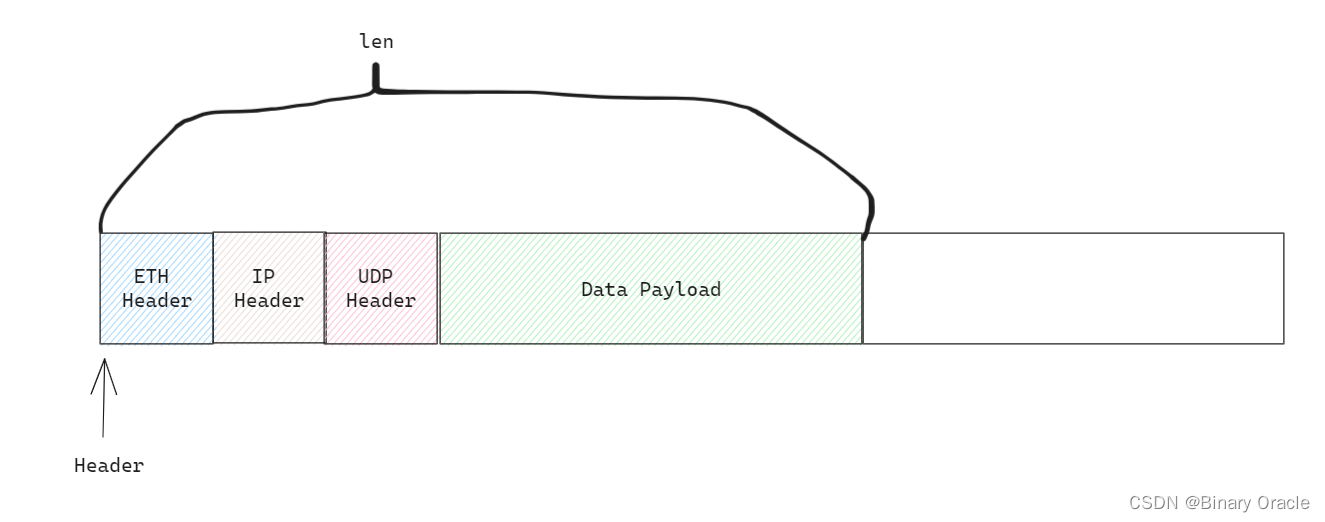
socket read全流程分析
还是继续从nettest.c文件中的ping函数开始继续往下阅读:
//
// send a UDP packet to the localhost (outside of qemu),
// and receive a response.
//
static void
ping(uint16 sport, uint16 dport, int attempts)
{
int fd;
char *obuf = "a message from xv6!";
uint32 dst;
// 10.0.2.2, which qemu remaps to the external host,
// i.e. the machine you're running qemu on.
dst = (10 << 24) | (0 << 16) | (2 << 8) | (2 << 0);
// you can send a UDP packet to any Internet address
// by using a different dst.
if((fd = connect(dst, sport, dport)) < 0){
fprintf(2, "ping: connect() failed\n");
exit(1);
}
...
char ibuf[128];
// 从socket文件读取数据到ibuf中
int cc = read(fd, ibuf, sizeof(ibuf)-1);
if(cc < 0){
fprintf(2, "ping: recv() failed\n");
exit(1);
}
// 关闭socket文件
close(fd);
ibuf[cc] = '\0';
if(strcmp(ibuf, "this is the host!") != 0){
fprintf(2, "ping didn't receive correct payload\n");
exit(1);
}
}
-
read系统调用从socket中读取文件
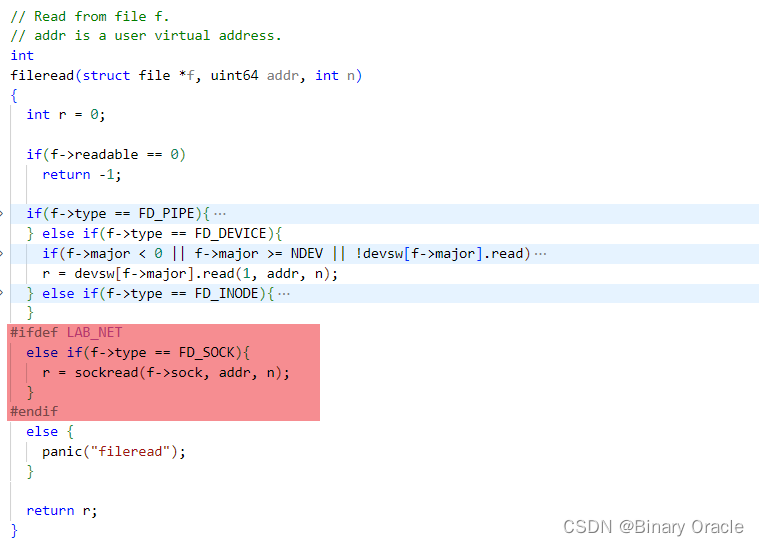
-
sockread从socket中读取数据
int
sockread(struct sock *si, uint64 addr, int n)
{
struct proc *pr = myproc();
struct mbuf *m;
int len;
acquire(&si->lock);
// 当前socket关联的mbuf队列为空,并且当前进程没有被Kill,则进行sleep状态
while (mbufq_empty(&si->rxq) && !pr->killed) {
sleep(&si->rxq, &si->lock);
}
if (pr->killed) {
release(&si->lock);
return -1;
}
// 从mbuf队列弹出头部元素
m = mbufq_pophead(&si->rxq);
release(&si->lock);
// n是期望读取字节数,len是当前mbuf中存在的字节数
len = m->len;
// 如果mbuf中存在的数据量比n大,那么缩小len到n
if (len > n)
len = n;
// 从mbuf中拷贝len个字节数据到用户态虚拟地址addr处
if (copyout(pr->pagetable, addr, m->head, len) == -1) {
mbuffree(m);
return -1;
}
// 当前mbuf使用完了,释放他
mbuffree(m);
return len;
}
- 当网卡接收到数据包后,会触发中断,通知CPU处理收包事件
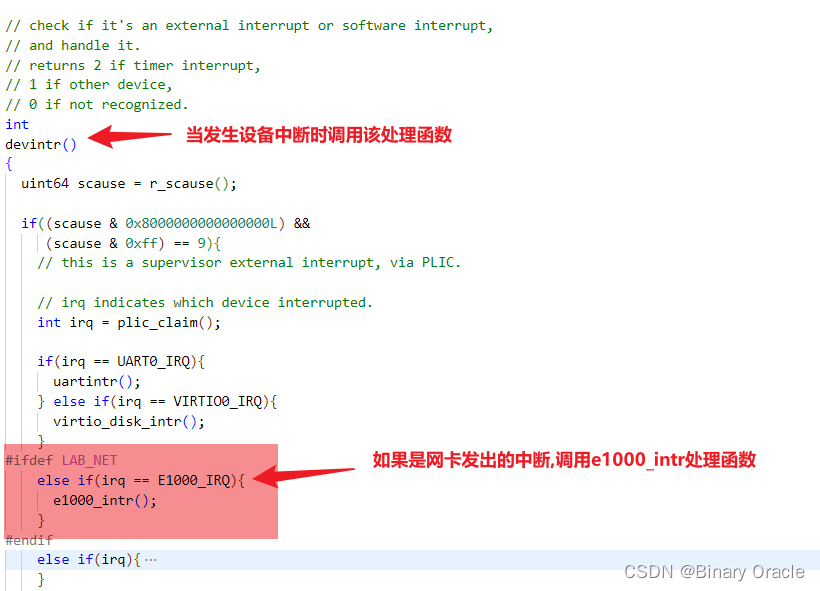
void
e1000_intr(void)
{
// 告知e1000我们已经处理了该中断;
// 如果不执行此操作,e1000将不会触发任何进一步的中断。
regs[E1000_ICR] = 0xffffffff;
// 触发收包操作--然后将接收到的数据包向上层传递
e1000_recv();
}
- e1000_recv就是我们需要实现的函数,这里不多讲,我们看一下该函数内部调用的net_rx函数实现
#define mbufpullhdr(mbuf, hdr) (typeof(hdr)*)mbufpull(mbuf, sizeof(hdr))
// called by e1000 driver's interrupt handler to deliver a packet to the
// networking stack
void net_rx(struct mbuf *m)
{
struct eth *ethhdr;
uint16 type;
// 剥离以太网头部
ethhdr = mbufpullhdr(m, *ethhdr);
if (!ethhdr) {
mbuffree(m);
return;
}
// 拿到上一层协议类型,通过类型进行分发
type = ntohs(ethhdr->type);
// 如果是ip协议,分发给ip处理函数
if (type == ETHTYPE_IP)
net_rx_ip(m);
// 如果是ARP协议,分发给ARP处理函数
else if (type == ETHTYPE_ARP)
net_rx_arp(m);
else
// 无法识别的协议
mbuffree(m);
}
// Strips data from the start of the buffer and returns a pointer to it.
// Returns 0 if less than the full requested length is available.
char *
mbufpull(struct mbuf *m, unsigned int len)
{
char *tmp = m->head;
if (m->len < len)
return 0;
m->len -= len;
m->head += len;
return tmp;
}
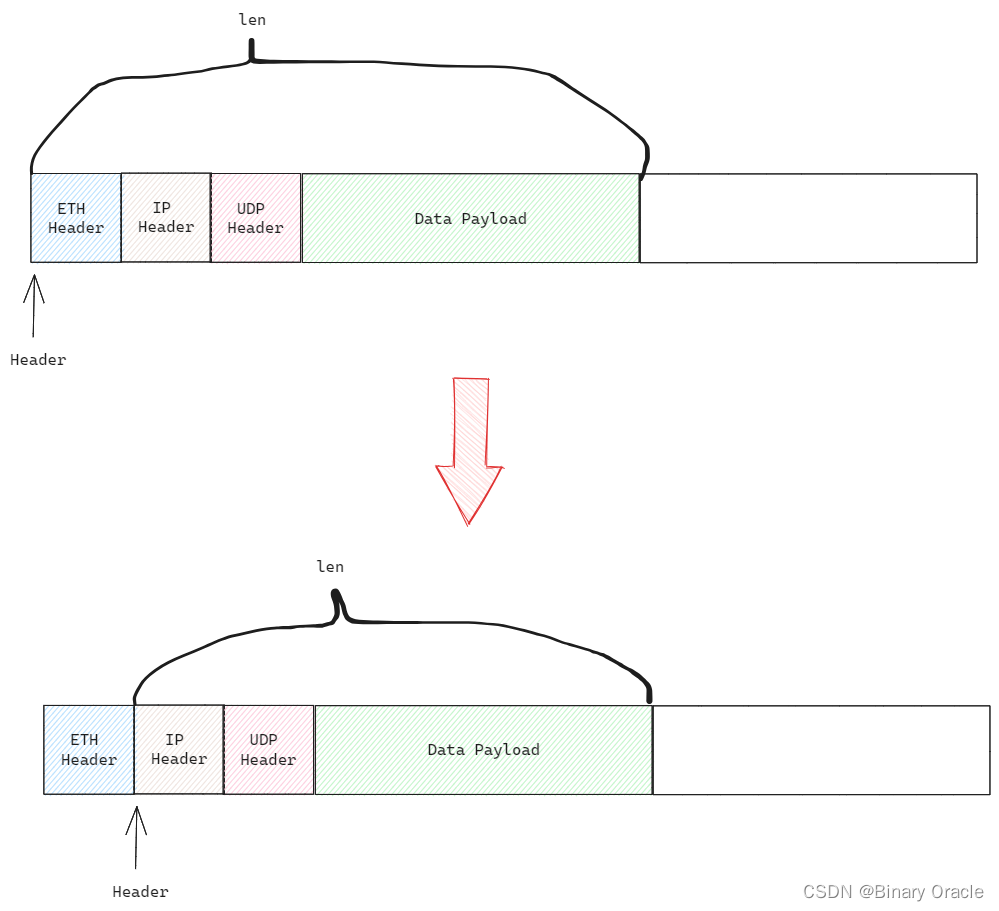
3. 剥离了以太网头部的mbuf继续往上层传递
// receives an IP packet
static void
net_rx_ip(struct mbuf *m)
{
struct ip *iphdr;
uint16 len;
// 剥离ip头部
iphdr = mbufpullhdr(m, *iphdr);
if (!iphdr)
goto fail;
// check IP version and header len
// 判断是否是IP V4,以及IP头部字节数是否符合要求
if (iphdr->ip_vhl != ((4 << 4) | (20 >> 2)))
goto fail;
// validate IP checksum
// 校验IP头部是否损坏
if (in_cksum((unsigned char *)iphdr, sizeof(*iphdr)))
goto fail;
// can't support fragmented IP packets
// 不支持IP分片重组
if (htons(iphdr->ip_off) != 0)
goto fail;
// is the packet addressed to us?
// 当前数据包的ip目的地址是否是本主机
if (htonl(iphdr->ip_dst) != local_ip)
goto fail;
// can only support UDP
// 判断上一层协议是否为UDP,这里只支持UDP协议
if (iphdr->ip_p != IPPROTO_UDP)
goto fail;
len = ntohs(iphdr->ip_len) - sizeof(*iphdr);
// 将剥离了ip头的数据包传递给UDP处理器处理
net_rx_udp(m, len, iphdr);
return;
fail:
mbuffree(m);
}
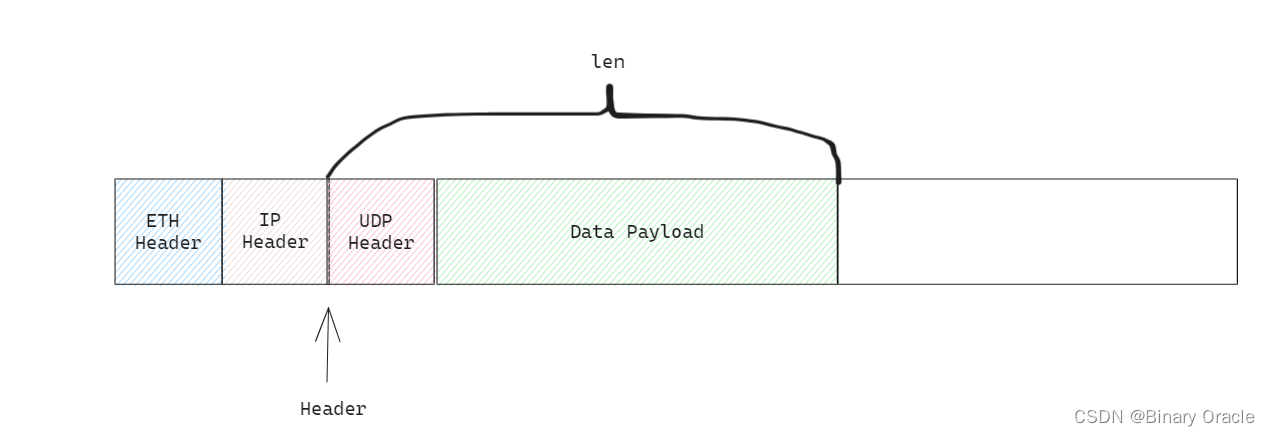
4. 剥离了ip头部的mbuf继续往上层传递
// Strips data from the end of the buffer and returns a pointer to it.
// Returns 0 if less than the full requested length is available.
char *
mbuftrim(struct mbuf *m, unsigned int len)
{
if (len > m->len)
return 0;
m->len -= len;
return m->head + m->len;
}
// receives a UDP packet
static void
net_rx_udp(struct mbuf *m, uint16 len, struct ip *iphdr)
{
struct udp *udphdr;
uint32 sip;
uint16 sport, dport;
// 剥离udp头部
udphdr = mbufpullhdr(m, *udphdr);
if (!udphdr)
goto fail;
// TODO: validate UDP checksum --> UDP数据包校验和检验,待完成
// validate lengths reported in headers
// 校验udp数据包大小是否完整
if (ntohs(udphdr->ulen) != len)
goto fail;
len -= sizeof(*udphdr);
if (len > m->len)
goto fail;
// minimum packet size could be larger than the payload
// 剥离udp头部
mbuftrim(m, m->len - len);
// parse the necessary fields
// 解析udp头部相关字段
sip = ntohl(iphdr->ip_src);
sport = ntohs(udphdr->sport);
dport = ntohs(udphdr->dport);
// 将剥离了udp header的数据报继续向上传递
sockrecvudp(m, sip, dport, sport);
return;
fail:
mbuffree(m);
}
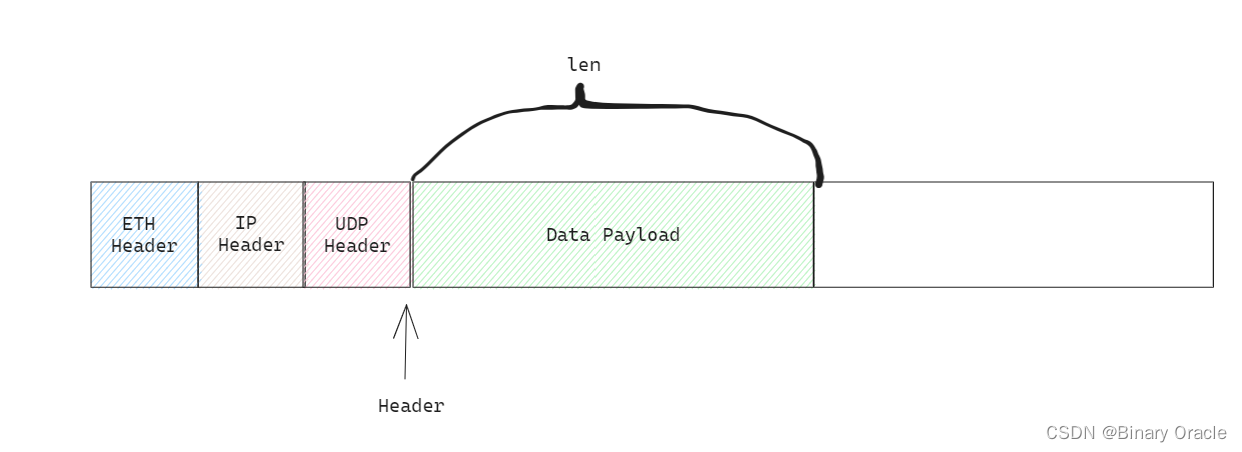
- socket层处理剥离了传输层头部的数据
// called by protocol handler layer to deliver UDP packets
void
sockrecvudp(struct mbuf *m, uint32 raddr, uint16 lport, uint16 rport)
{
//
// Find the socket that handles this mbuf and deliver it, waking
// any sleeping reader. Free the mbuf if there are no sockets
// registered to handle it.
//
struct sock *si;
acquire(&lock);
// 遍历已经建立的socket连接,挨个对比三元组是否相等
si = sockets;
while (si) {
if (si->raddr == raddr && si->lport == lport && si->rport == rport)
goto found;
si = si->next;
}
release(&lock);
mbuffree(m);
return;
found:
acquire(&si->lock);
// 将mbuf添加到对应socket的mbuf队列中去
mbufq_pushtail(&si->rxq, m);
// 唤醒等待在mbuf队列上的socket
wakeup(&si->rxq);
release(&si->lock);
release(&lock);
}
// Pushes an mbuf to the end of the queue.
void
mbufq_pushtail(struct mbufq *q, struct mbuf *m)
{
m->next = 0;
if (!q->head){
q->head = q->tail = m;
return;
}
q->tail->next = m;
q->tail = m;
}
socket关闭
当数据传输和接收完毕后,需要关闭socket连接:
void
sockclose(struct sock *si)
{
struct sock **pos;
struct mbuf *m;
// remove from list of sockets
acquire(&lock);
pos = &sockets;
// 从已经打开的socket连接中寻找到要关闭的那个
while (*pos) {
if (*pos == si){
*pos = si->next;
break;
}
pos = &(*pos)->next;
}
release(&lock);
// free any pending mbufs
// 将socket关联的mbuf队列中所有mbuf全部释放
while (!mbufq_empty(&si->rxq)) {
m = mbufq_pophead(&si->rxq);
mbuffree(m);
}
// 释放socket对象占据空间
kfree((char*)si);
}
ARP数据报的发送与接收
- ARP数据报的接收
// receives an ARP packet
static void
net_rx_arp(struct mbuf *m)
{
struct arp *arphdr;
uint8 smac[ETHADDR_LEN];
uint32 sip, tip;
// 剥离arp头部
arphdr = mbufpullhdr(m, *arphdr);
if (!arphdr)
goto done;
// validate the ARP header
// 验证硬件类型(hrd)是否为以太网类型,协议类型(pro)是否为IP类型
// 以太网地址长度(hln)是否为以太网地址长度,IP地址长度(pln)是否为IP地址长度
if (ntohs(arphdr->hrd) != ARP_HRD_ETHER ||
ntohs(arphdr->pro) != ETHTYPE_IP ||
arphdr->hln != ETHADDR_LEN ||
arphdr->pln != sizeof(uint32)) {
goto done;
}
// only requests are supported so far
// check if our IP was solicited
// 检查ARP操作类型是否为请求(ARP_OP_REQUEST)以及目标IP地址(tip)是否为本地IP地址(local_ip)
tip = ntohl(arphdr->tip); // target IP address
if (ntohs(arphdr->op) != ARP_OP_REQUEST || tip != local_ip)
goto done;
// handle the ARP request
// 如果以上条件满足,则表示接收到了对本地IP地址的ARP请求
// 将发送方的以太网地址(发送方的MAC地址)和发送方的IP地址(qemu's slirp)保存到相应的变量中
memmove(smac, arphdr->sha, ETHADDR_LEN); // sender's ethernet address
sip = ntohl(arphdr->sip); // sender's IP address (qemu's slirp)
// 调用net_tx_arp函数发送ARP应答(ARP_OP_REPLY)给发送方
net_tx_arp(ARP_OP_REPLY, smac, sip);
done:
mbuffree(m);
}
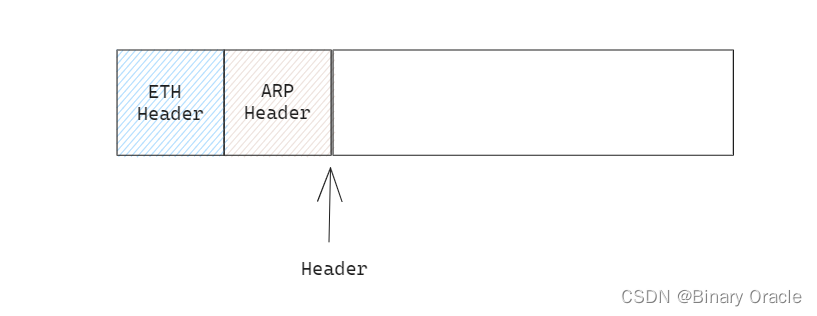
- arp数据报应答发送
// 一个ARP数据包(在以太网头部之后)。
struct arp {
uint16 hrd; // 硬件地址格式
uint16 pro; // 协议地址格式
uint8 hln; // 硬件地址长度
uint8 pln; // 协议地址长度
uint16 op; // 操作类型
char sha[ETHADDR_LEN]; // 发送方硬件地址
uint32 sip; // 发送方IP地址
char tha[ETHADDR_LEN]; // 目标硬件地址
uint32 tip; // 目标IP地址
} __attribute__((packed));
static int
net_tx_arp(uint16 op, uint8 dmac[ETHADDR_LEN], uint32 dip)
{
struct mbuf *m;
struct arp *arphdr;
// 分配一个新的mbuf
m = mbufalloc(MBUF_DEFAULT_HEADROOM);
if (!m)
return -1;
// 填充ARP头部的通用部分
arphdr = mbufputhdr(m, *arphdr);
arphdr->hrd = htons(ARP_HRD_ETHER);
arphdr->pro = htons(ETHTYPE_IP);
arphdr->hln = ETHADDR_LEN;
arphdr->pln = sizeof(uint32);
arphdr->op = htons(op);
// 填充ARP头部的以太网和IP部分
memmove(arphdr->sha, local_mac, ETHADDR_LEN);
arphdr->sip = htonl(local_ip);
memmove(arphdr->tha, dmac, ETHADDR_LEN);
arphdr->tip = htonl(dip);
// 头部填充完毕,发送数据包
net_tx_eth(m, ETHTYPE_ARP);
return 0;
}