目录
- 一、二、Tesnsflow入门 & 环境配置 & 认识Tensorflow
- 三、线程与队列与IO操作
- 1.队列
- 实例:完成一个出队列、+1、入队列操作(同步操作)
- 2.队列管理器 创建线程
- 3.线程协调器 管理线程
- 案例:通过队列管理器来实现变量加1,入队,主线程出队列的操作,观察效果?(异步操作)
- 4.文件读取流程
- 1.文件读取API-文件队列构造
- 2.文件读取API-文件阅读器
- 3.文件读取API-文件内容解码器
- 4.开启线程操作
- 5.管道读端批处理
- 案例:CSV文件读取
- 5.图片文件
一、二、Tesnsflow入门 & 环境配置 & 认识Tensorflow
Tensorflow入门(1)——深度学习框架Tesnsflow入门 & 环境配置 & 认识Tensorflow
三、线程与队列与IO操作
1.队列
在训练样本的时候,希望读入的训练样本时有序的
• tf.FIFOQueue 先进先出队列,按顺序出队列
• tf.RandomShuffleQueue 随机出队列

FIFOQueue(capacity, dtypes, name=‘fifo_queue’)
创建一个以先进先出的顺序对元素进行排队的队列
- capacity:整数。可能存储在此队列中的元素数量的上限
- dtypes:DType对象列表。长度dtypes必须等于每个队列元素中的张量数,dtype的类型形状,决定了后面进队列元素形状
- method:
dequeue(name=None):出队列
enqueue(vals, name=None):入队列
enqueue_many(vals, name=None):vals列表或者元组:同时把许多数据放入队列,返回一个进队列操作
size(name=None):队列的size
实例:完成一个出队列、+1、入队列操作(同步操作)
import tensorflow as tf
# tensorflow当中,运行操作有依赖性
# 1、首先定义队列
# 2、定义一些读数据,取数据的过程 , 取数据,+1 ,入队列
# 1\定义队列
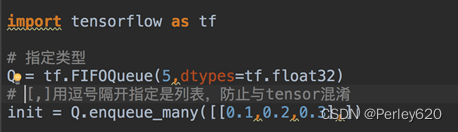
Q = tf.FIFOQueue(3, tf.float32)
# 放入数据
enq_many = Q.enqueue_many([[0.1,0.2,0.3],])# 列表
# 2\处理数据,取数据,+1,入队列
out_q = Q.dequeue()
data = out_q + 1
en_q = Q.enqueue(data)
with tf.Session() as sess:
# 初始化队列
sess.run(enq_many)
# 处理数据
for i in range(100):
sess.run(en_q)# tensorflow当中,运行操作有依赖性
# 训练数据
for i in range(Q.size().eval()):
print(sess.run(Q.dequeue()))
2.队列管理器 创建线程

tf.train.QueueRunner(queue, enqueue_ops=None)
创建一个QueueRunner
- queue:A Queue
- enqueue_ops:添加线程的队列操作列表,[]*2,指定两个线程
- create_threads(sess, coord=None,start=False):创建线程来运行给定会话的入队操作
start:布尔值,如果True启动线程;如果为False调用者必须调用start()启动线程
coord:线程协调器,后面线程管理需要用到
return:
3.线程协调器 管理线程

tf.train.Coordinator()
线程协调员,实现一个简单的机制来协调一组线程的终止
request_stop()
should_stop() 检查是否要求停止
join(threads=None, stop_grace_period_secs=120)
等待线程终止
return:线程协调员实例
案例:通过队列管理器来实现变量加1,入队,主线程出队列的操作,观察效果?(异步操作)
import tensorflow as tf
# 模拟异步 子线程:存入样本 ,主线程:读取样本
# 1、定义一个队列,1000
Q = tf.FIFOQueue(1000, tf.float32)
# 2、定义子线程要做的事情 循环 值 +1 ,放入队列中
var = tf.Variable(0.0)
# 不能用data = var + 1
#实现一个自增, tf.assign_add
# data = tf.assign_add(var, tf.constant(1.0))
data = tf.assign_add(var , tf.constant(1.0))
en_q = Q.enqueue(data)
# 3、定义队列管理器 op,指定多少个子线程 以及 子线程该干什么
qr = tf.train.QueueRunner(Q, enqueue_ops=[en_q] * 2)
# 初始化变量 OP
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
# 初始化变量
sess.run(init_op)
# 开启线程管理器
coord = tf.train.Coordinator()
# 开启真正子线程
threads = qr.create_threads(sess, coord=coord ,start=True) # 指定老大是coord
# 主线程,不断读取数据训练
for i in range(300):
print(sess.run(Q.dequeue()))
# 回收你
coord.request_stop()
coord.join(threads) # 听老大的话
4.文件读取流程

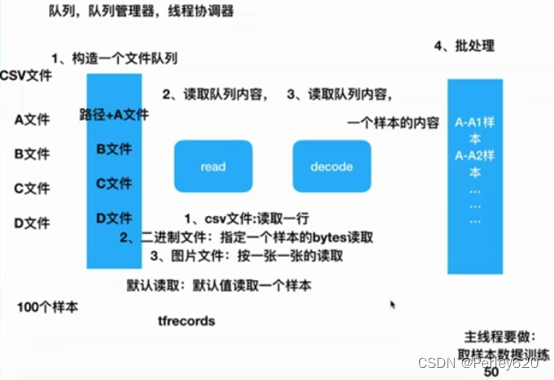
1.文件读取API-文件队列构造

tf.train.string_input_producer(string_tensor , shuffle=True)
将输出字符串(例如文件名)输入到管道队列
string_tensor 含有文件名的1阶张量
num_epochs : 过几遍数据,默认无限过数据
return : 具有输出字符串的队列
2.文件读取API-文件阅读器

根据文件格式,选择对应的文件阅读器
class tf.TextLineReader
阅读文本文件逗号分隔值(CSV)格式 , 默认按行读取
return:读取器实例
tf.FixedLengthRecordReader(record_bytes)
要读取每个记录是固定数量字节的二进制文件
record_bytes:整型,指定每次读取的字节数
return:读取器实例
tf.TFRecordReader
读取TfRecords文件
有一个共同的读取方法:read(file_queue):从队列中指定数量内容
返回一个Tensors元组(key文件名字,value默认的内容(行,字节))
3.文件读取API-文件内容解码器

由于从文件中读取的是字符串,需要函数去解析这些字符串到张量
tf.decode_csv(records,record_defaults=None,field_delim = None,name = None)
- 将CSV转换为张量,与tf.TextLineReader搭配使用
records:tensor 型字符串,每个字符串是csv中的记录行
field_delim : 默认分割符”,”
record_defaults :参数决定了所得张量的类型,并设置一个值在输入字符串中缺少使用默认值,如
tf.decode_raw(bytes,out_type,little_endian = None,name = None)- 将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用,二进制读取为uint8格式
4.开启线程操作

tf.train.start_queue_runners(sess=None,coord=None)
收集所有图中的队列线程,并启动线程
sess:所在的会话中
coord:线程协调器
return:返回所有线程队列
5.管道读端批处理

tf.train.batch(tensors,batch_size,num_threads = 1,capacity = 32,name=None)
读取指定大小(个数)的张量
tensors:可以是包含张量的列表
batch_size:从队列中读取的批处理大小
num_threads:进入队列的线程数
capacity:整数,队列中元素的最大数量
return:tensors
tf.train.shuffle_batch(tensors,batch_size,capacity,min_after_dequeue,num_threads=1,)
乱序读取指定大小(个数)的张量
min_after_dequeue:留下队列里的张量个数,能够保持随机打乱
案例:CSV文件读取

import tensorflow as tf
import os
def csvread(filelist):
'''
读取CSV文件
:param filelist: 文件路径+名字的列表
:return: 读取的内容
'''
# 2\构造文件队列
file_queue = tf.train.string_input_producer(filelist)
# 3\构造CSV阅读器读取队列数据(按照一行)
reader = tf.TextLineReader()
key , value = reader.read(file_queue)
# 4\对每行数据进行解码
# record_defaults: 指定每一个样本的每一列的类型,指定默认值
records = [["None"],[4.0]] #指定两列的默认值为字符串和float
example, label = tf.decode_csv(value, record_defaults=records) #有两列,两个参数接受
# 5\想要读取多个数据,就需要批量处理
# 批处理大小,跟队列,数据的数量没有影响,只决定这批次读取多少数据
example_batch ,label_batch= tf.train.batch([example, label],batch_size=9,num_threads = 1,capacity = 9)
return example_batch ,label_batch
if __name__ == '__main__':
# 1\找到文件,放入列表 路径+名字 放入列表当中
file_name = os.listdir("./data/csvdata/")
filelist = [os.path.join("./data/csvdata/" , file) for file in file_name]
example_batch,label_batch = csvread(filelist)
# 开启会话运行结果
with tf.Session() as sess:
# 定义一个线程协调器
coord = tf.train.Coordinator()
# 开启读取文件的线程
threads = tf.train.start_queue_runners(sess, coord=coord)
# 打印读取的内容
print(sess.run([example_batch,label_batch]))
#回收子线程
coord.request_stop()
coord.join(threads) # 听老大的话
5.图片文件

图像读取器
tf.WholeFileReader
将文件的全部内容作为值输出的读取器
return:读取器实例
read(file_queue):输出将是一个文件名(key)和该文件的内容(值)
图像解码器
tf.image.decode_jpeg(contents)
将JPEG编码的图像解码为uint8张量
return:uint8张量,3-D形状[height, width, channels]
tf.image.decode_png(contents)将PNG编码的图像解码为uint8或uint16张量
return:张量类型,3-D形状[height, width, channels]
缩小图片
tf.image.resize_images(images, size)
images:4-D形状[batch, height, width, channels]或3-D形状的张量[height, width, channels]的图片数据
size:1-D int32张量:new_height, new_width,图像的新尺寸返回4-D格式或者3-D格式图片
import tensorflow as tf
import os
def picread(filelist):
"""
读取狗图片并转换成张量
:param filelist: 文件路径+ 名字的列表
:return: 每张图片的张量
"""
# 1、构造文件队列
file_queue = tf.train.string_input_producer(filelist)
# 2、构造阅读器去读取图片内容(默认读取一张图片)
reader = tf.WholeFileReader()
key, value = reader.read(file_queue)
print(value)
# 3、对读取的图片数据进行解码
image = tf.image.decode_jpeg(value)
print(image)
# 5、处理图片的大小(统一大小)
image_resize = tf.image.resize_images(image, [200, 200])
print(image_resize)
# 注意:一定要把样本的形状固定 [200, 200, 3],在批处理的时候要求所有数据形状必须定义
image_resize.set_shape([200, 200, 3])
print(image_resize)
# 6、进行批处理
image_batch = tf.train.batch([image_resize], batch_size=20, num_threads=1, capacity=20)
print(image_batch)
return image_batch
if __name__ == '__main__':
# 1\找到文件,放入列表 路径+名字 放入列表当中
file_name = os.listdir("./data/dog/")
filelist = [os.path.join("./data/dog/" , file) for file in file_name]
image_batch = picread(filelist)
# 开启会话运行结果
with tf.Session() as sess:
# 定义一个线程协调器
coord = tf.train.Coordinator()
# 开启读取文件的线程
threads = tf.train.start_queue_runners(sess, coord=coord)
# 打印读取内容
print(sess.run([image_batch]))
#回收子线程
coord.request_stop()
coord.join(threads) # 听老大的话