道路裸土扬尘问题是城市环境中常见的环境污染问题之一。在以往的一些项目中也有实际接触到过类似的检测识别需求,本文的主要目的是单纯地从实验分析的角度来对比裸土这一数据场景下不同量级参数模型的实际性能。
首先看下整体效果:
接下来简单看下数据集:


实例标注数据如下所示:
0 0.248611 0.515278 0.133333 0.119444
0 0.9625 0.688194 0.075 0.068056
0 0.799306 0.636111 0.106944 0.063889
0 0.658333 0.5875 0.119444 0.061111
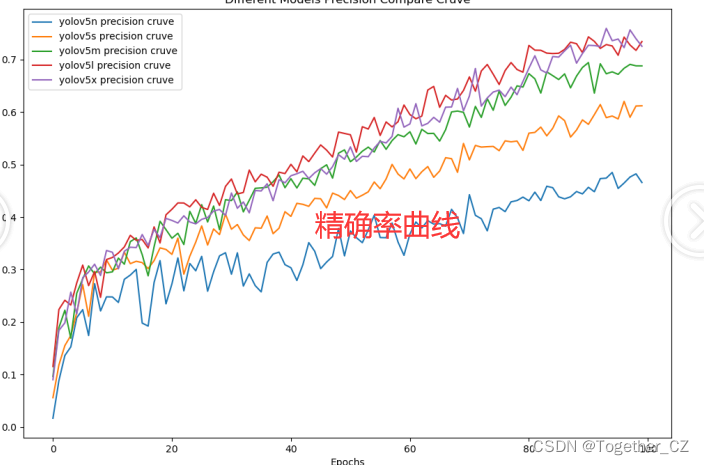
这里依次使用n--->x五款不同参数量级的模型来开发实现最终的目标检测接下里依次看下结果详情:
【n系列模型】

【s系列模型】

【m系列模型】


【l系列模型】
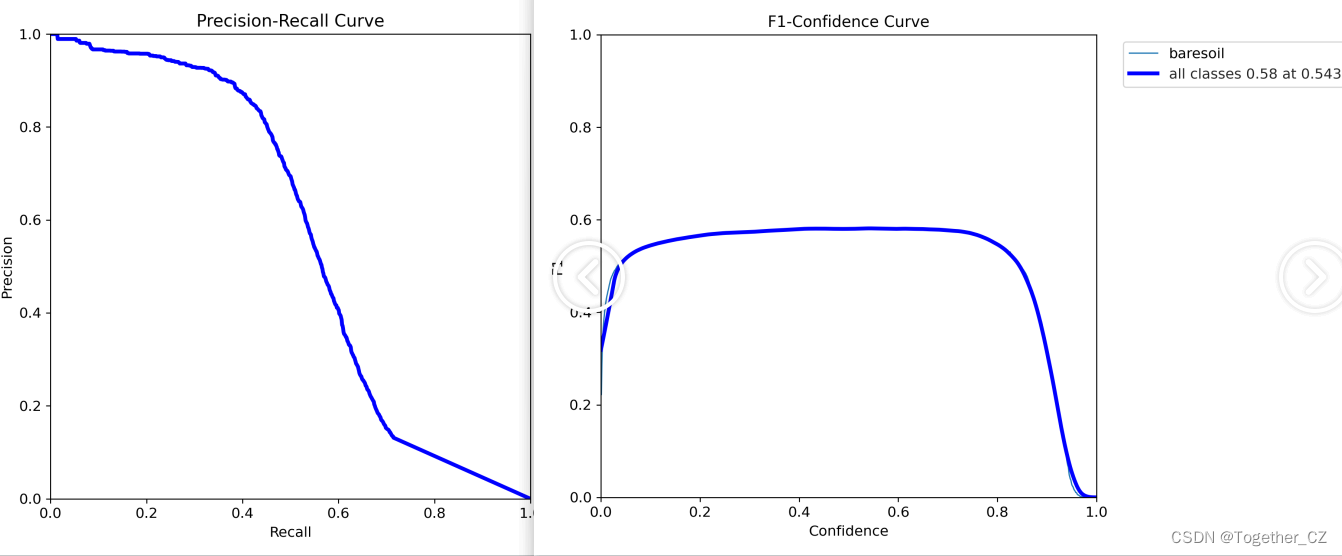

【x系列模型】
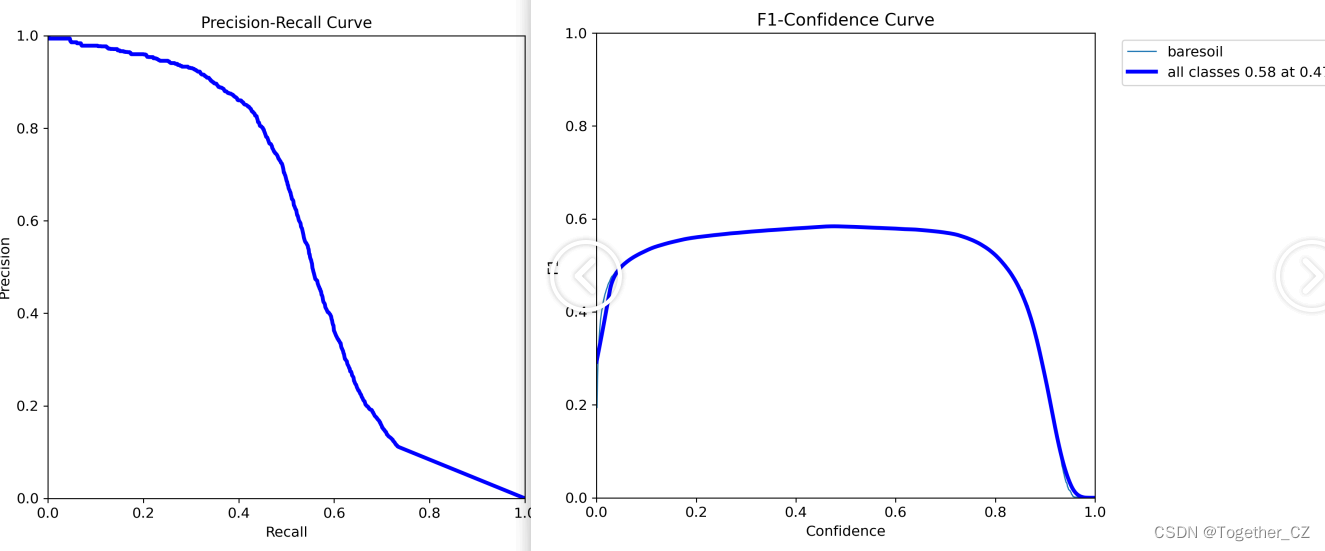
接下来来整体对比分析下关键指标的结果:
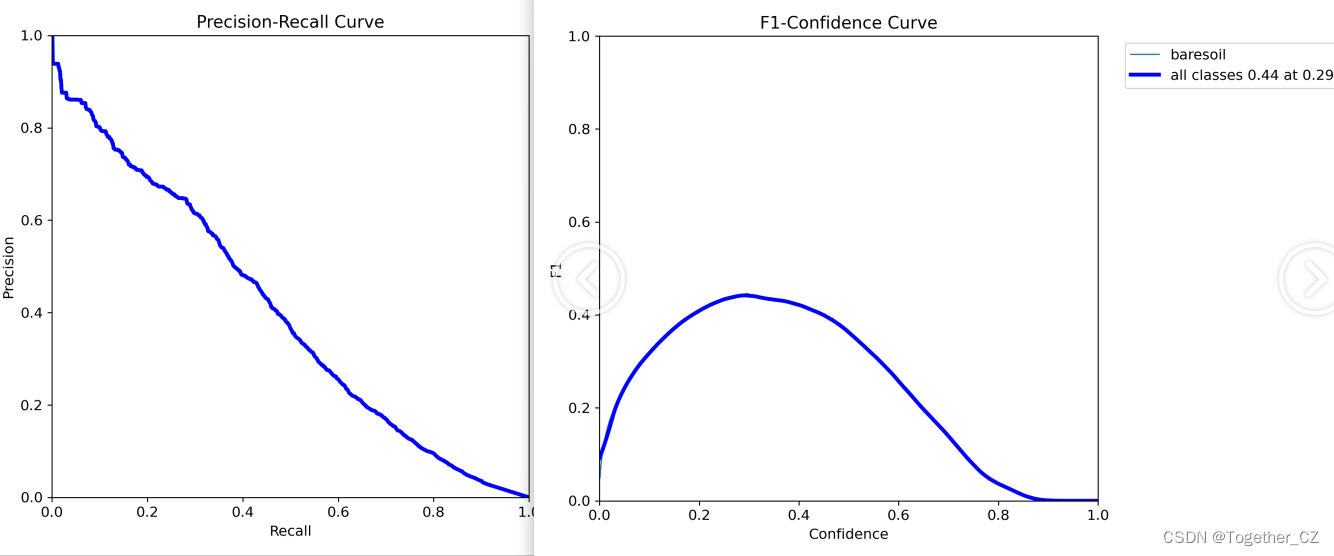
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
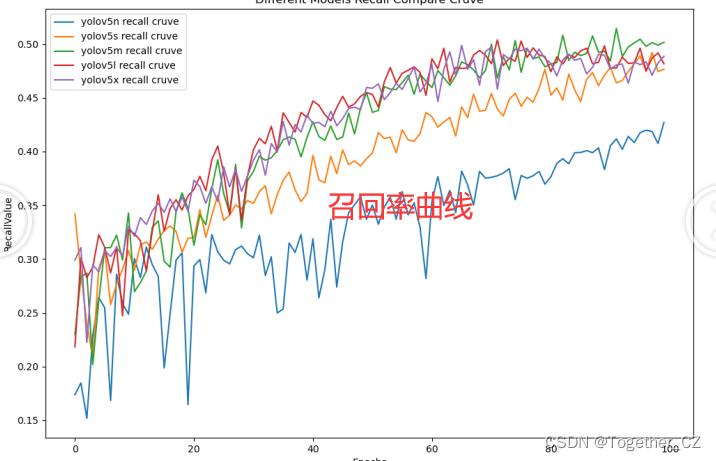
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
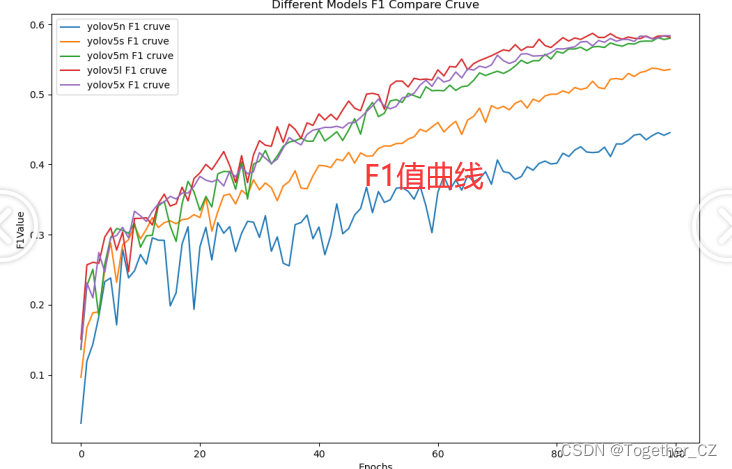
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
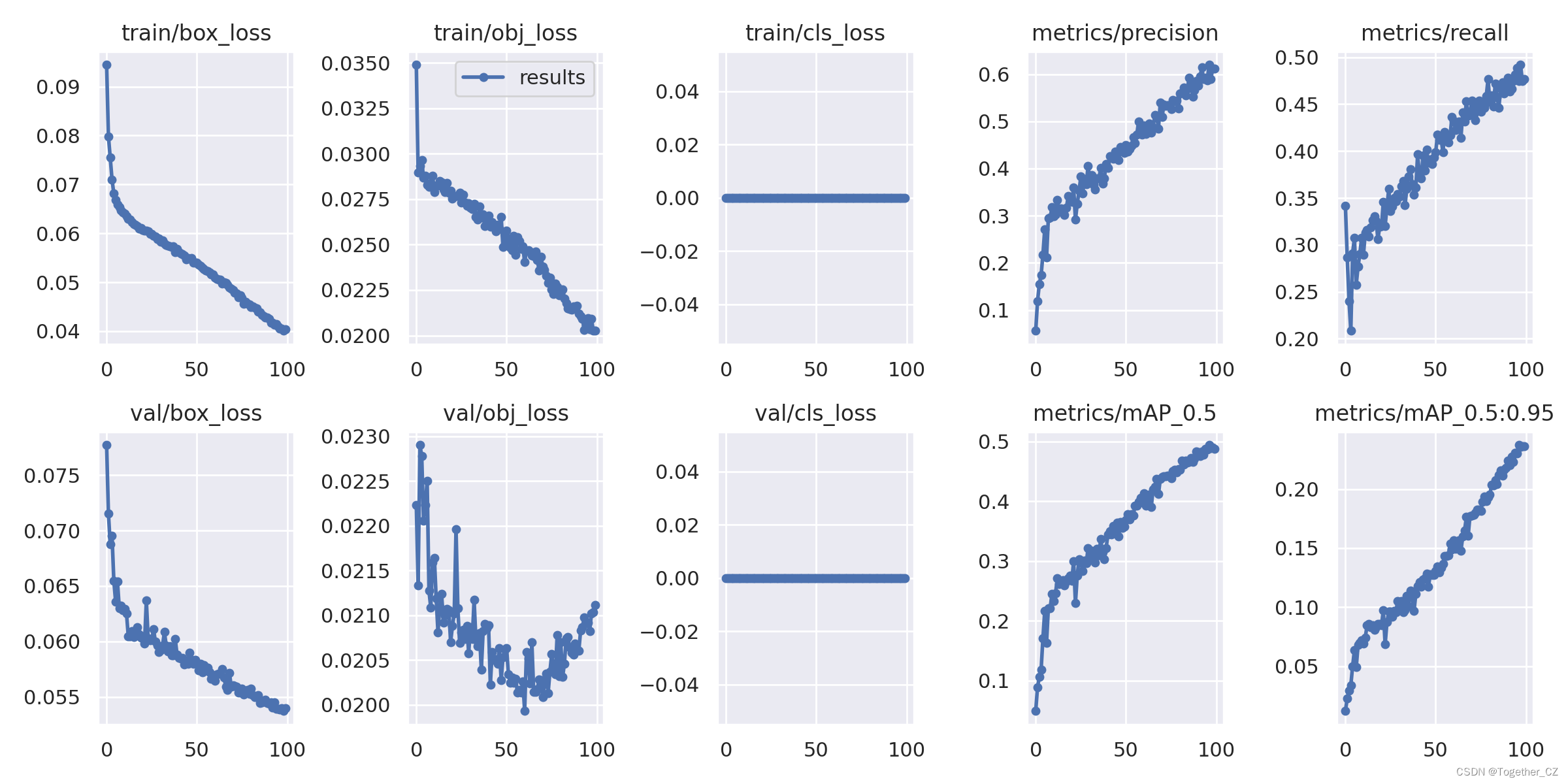
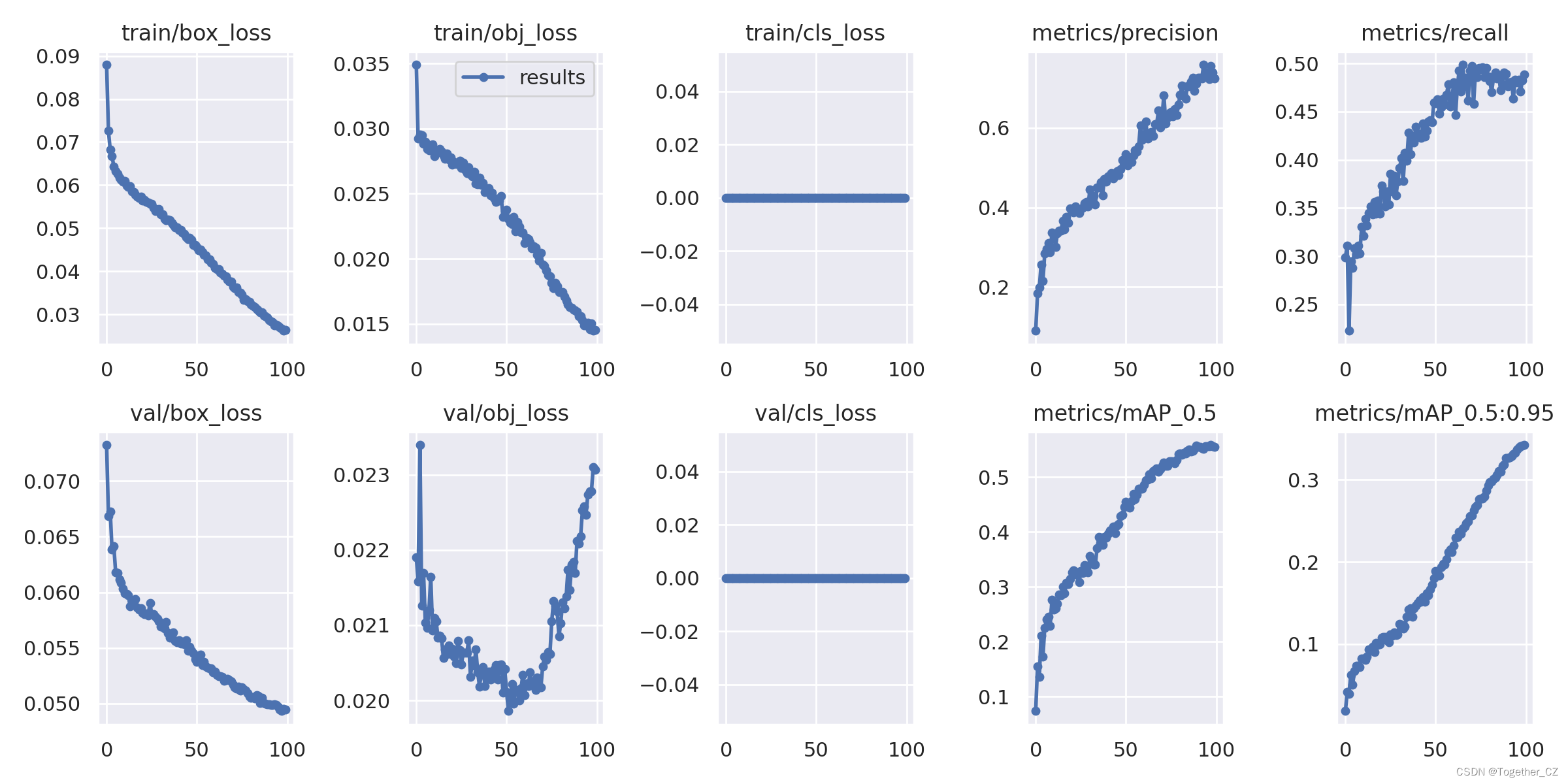
还有最后的Loss对比曲线,如下所示:
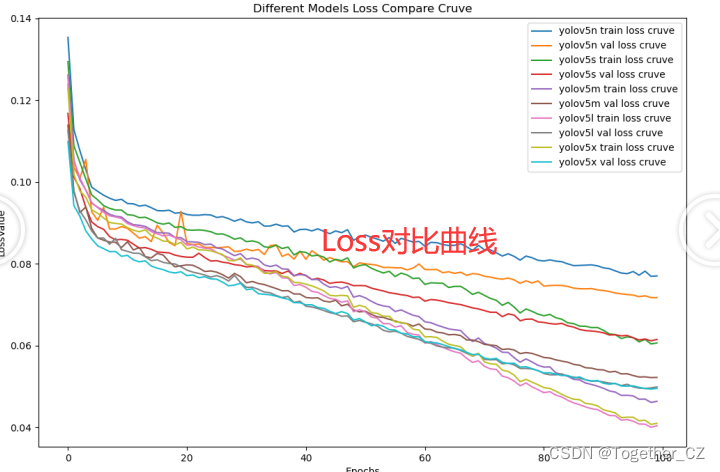
从实际实验结果来看:当参数量级超过一定阈值后继续增加参数量带来的结果提升已经微乎其微了,所以并非一定要使用最大的模型,其实l系列的模型在一定程度的表现上已经是由于x系列的模型了。不过这个也是要根据自己实际业务需要去做选择的。