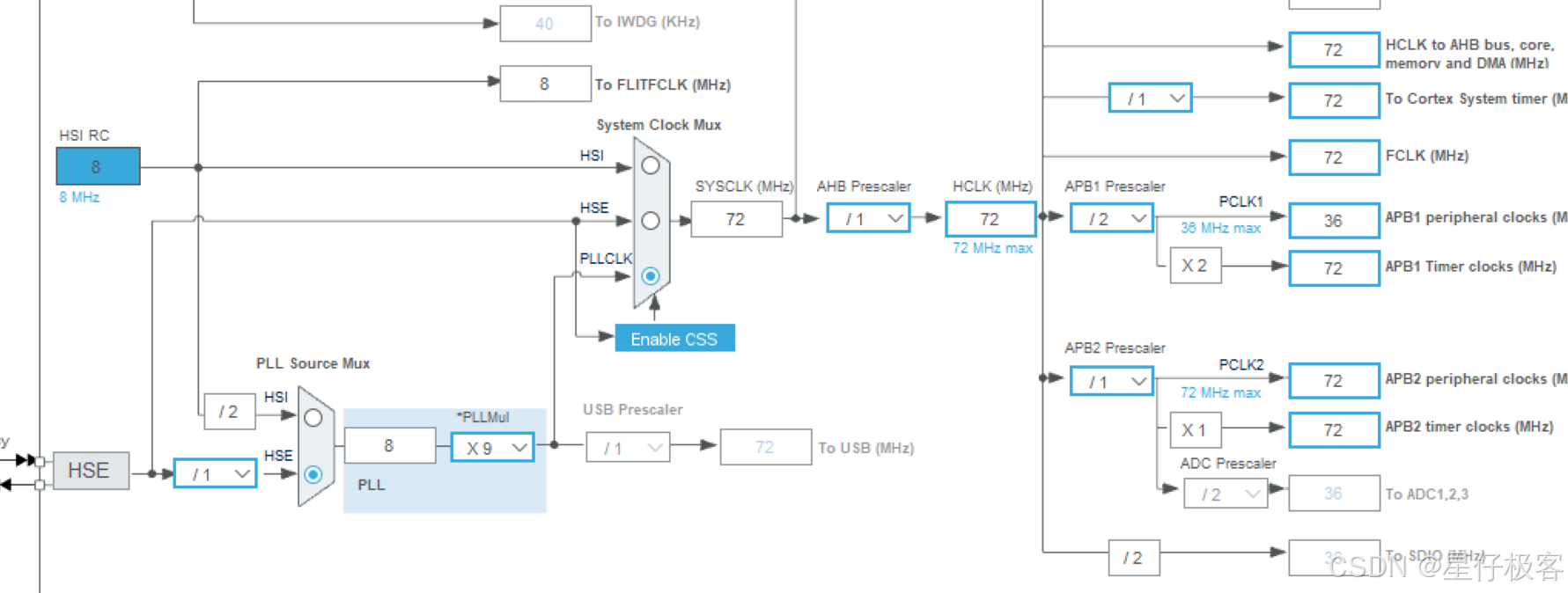
今天从第四章:快速RCNN,方法细节开始介绍。
目录
四、快速RCNN:方法细节
4.1 快速R-CNN回顾
4.2 对抗网络设计
4.2.1 遮挡的对抗空间信息损失
4.2.2 对抗空间Transformer网络
4.2.3 对抗融合
五、实验
5.1 实验设置
5.2 PASCAL VOC2007结果
5.2.1 消融分析
5.2.2 基于种类的分析
5.2.3 定性结果
5.3 PASCAL VOC2012 和 MS COCO数据集结果
5.4 和OHEM的对比
六、结论
四、快速RCNN:方法细节
现在我们来描述一下框架的细节。我们首先简要介绍我们的基础检测器Fast-RCNN。接下来是对抗性生成空间的描述。在本文中,我们特别关注生成不同类型的遮挡和变形。最后,在第5节中,我们描述了我们的实验设置,并展示了与基线相比有显着改进的结果。
4.1 快速R-CNN回顾
我们在Fast-RCNN框架的基础上构建目标检测[6]。Fast-RCNN由两部分组成:(i)用于特征提取的卷积网络;(ii)具有RoI池层和几个输出目标类和边界框的完全连接层的RoI网络。
给定一个输入图像,Fast-RCNN的卷积网络将整个图像作为输入,并产生卷积特征映射作为输出。由于这些操作主要是卷积和max-pooling,所以输出feature map的空间维度会随着输入图像的大小而变化。给定特征映射,使用RoIpooling层将目标建议[40]投影到特征空间上。roi池层裁剪和调整大小,为每个目标提案生成固定大小的特征向量。这些特征向量然后通过完全连接的层。完全连接层的输出是:(i)包括背景类在内的每个目标类的概率;(ii)边界框坐标。
对于训练,分别对这两个输出应用SoftMax损失和回归损失,并将梯度反向传播到所有层以执行端到端学习。
4.2 对抗网络设计
我们考虑了对抗网络与Fast-RCNN (FRCN)检测器竞争的两种类型的特征代。第一种生成类型是遮挡。在这里,我们提出了对抗性空间丢弃网络(ASDN),它学习如何遮挡给定的目标,从而使FRCN难以分类。本文考虑的第二种生成类型是变形。在这种情况下,我们提出了对抗空间变形网络(ASTN),它学习如何旋转物体的“部分”,使它们难以被检测器识别。通过与这些网络竞争并克服障碍,FRCN学习以鲁棒的的方式处理目标遮挡和变形。请注意,在训练期间,ASDN和ASTN是与FRCN同时学习的。联合训练可以防止检测器过度拟合固定生成策略产生的障碍。
与在输入图像上产生遮挡和变形相比,我们发现对特征空间的操作更加高效和有效。因此,我们设计我们的对抗网络来修改特征,使目标更难识别。请注意,这两个网络仅在训练期间应用,以改进检测器。我们将首先分别介绍ASDN和ASTN,然后将它们合并在一个统一的框架中。
4.2.1 遮挡的对抗空间信息损失
我们提出了一种对抗性空间Dropout网络(ASDN),用于在前景物体的深层特征上创建遮挡。回想一下,在标准的Fast-RCNN管道中,我们可以在roi池化层之后获得每个前景目标提案的卷积特征。我们使用这些基于区域的特征作为对抗网络的输入。给定目标的特征,ASDN将尝试生成一个掩码,指示特征的哪些部分要删除(分配零),以便检测器无法识别目标。
更具体地说,给定一个目标,我们提取大小为d×d× c的特征X,其中d是空间维度,c表示通道数量(例如,c = 256,d =6在AlexNet中)。考虑到这个特征,我们的ASDN将预测一个掩码M,其d×d值在阈值后要么为0,要么为1。我们在图(b)中可视化了阈值处理前的一些掩模。我们将temij表示为掩码第i行和第j列的值。类似地,Xijk表示特征在位置i, j处通道k中的值。如果Mij =1,我们去掉特征映射X对应空间位置的所有通道的值,即Xijk =0,∀k。
网络架构
我们使用标准的FastRCNN (FRCN)架构。我们使用来自ImageNet[2]的预训练初始化网络。对抗网络与FRCN共享卷积层和roi池层,然后使用自己单独的全连接层。请注意,我们没有与Fast-RCNN共享ASDN中的参数,因为我们正在优化两个网络以执行完全相反的任务。
模型预训练
在我们的实验中,我们发现在使用ASDN来改进Fast-RCNN之前,为创建闭塞的任务预训练ASDN是很重要的。在更快的RCNN检测器[28]的激励下,我们在这里应用了分阶段训练。我们首先在没有ASDN的情况下训练我们的Fast-RCNN检测器进行10K次迭代。由于检测器现在对数据集中的对象有感觉,我们通过固定检测器中的所有层来训练ASDN模型来创建遮挡。
初始化ASDN网络
为了初始化ASDN网络,给定空间布局为d × d的特征映射X,我们在其上应用大小为d3 × d3的滑动窗口。我们通过将窗口投影回图像3(a)来表示滑动窗口过程。对于每个滑动窗口,我们将其空间位置被窗口覆盖的所有通道中的值删除,并为区域建议生成新的特征向量。然后将该特征向量通过分类层来计算损失。根据所有三维×三维窗口的损耗,选择损耗最大的窗口。然后使用该窗口创建单个d × d遮罩(1表示窗口位置,0表示其他像素)。我们为n个正区域建议生成这些空间掩模,得到n对训练样例{(X1, M ~ 1),…, (Xn, M ~ n)}为我们的对抗性辍学网络。这个想法是,ASDN应该学会生成掩码,这可以给检测器网络带来高损失。我们将二值交叉熵损失应用到ASDN的训练中,它可以表示为:
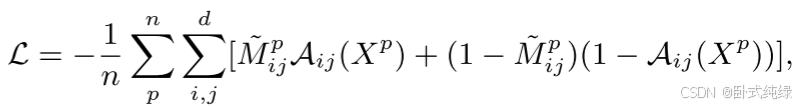

其中Aij(Xp)表示给定输入特征映射Xp, ASDN在位置(i, j)的输出。我们用这个损失训练ASDN进行10K次迭代。图(b)显示,网络开始识别物体的哪一部分对分类有意义。还要注意,我们的输出掩码与[31]中提出的注意力掩码不同,后者使用注意力机制来促进分类。在我们的例子中,我们使用遮罩遮挡部分,使分类更加困难。
采样阈值
ASDN网络产生的输出不是二进制掩码,而是连续的热图。而不是使用直接阈值,我们使用重要性采样来选择前13个像素遮罩。注意,在训练过程中,抽样过程包含了样本的随机性和多样性。更具体地说,给定一张热图,我们首先选择具有最高概率的前1/2个像素,然后随机选择其中的1/3个像素,将其赋值为1,其余的2/3个像素设置为0。
联合训练
给定预训练好的ASDN和FastRCNN模型,我们在每次训练迭代中对这两个网络进行联合优化。为了训练Fast-RCNN检测器,我们首先使用ASDN在前向传播过程中进行roi池化后的特征上生成掩码。我们执行采样来生成二进制蒙版,并使用它们在RoIpooling层之后删除特征中的值。然后,我们转发修改的特征来计算损失并端到端训练检测器。请注意,虽然我们的特性被修改了,但标签保持不变。通过这种方式,我们创建了“更难”和更多样化的示例来训练检测器。
对于训练ASDN,由于我们采用采样策略将热图转换为不可微的二进制掩码,因此我们不能直接从分类损失中反向支持梯度。或者,我们从强化[42]方法中汲取灵感。我们计算了哪些二进制掩码导致Fast-RCNN分类分数显著下降。我们只使用这些硬示例掩模作为真实值,直接使用方程 1中描述的相同损失来训练对抗网络
4.2.2 对抗空间Transformer网络
现在我们介绍对抗性空间变压器网络(ASTN)。其关键思想是在目标特征上产生变形,使检测器难以识别目标。我们的网络建立在b[14]中提出的空间变压器网络(STN)的基础上。在他们的工作中,STN被提出对特征进行变形以使分类更容易。另一方面,我们的网络正在做完全相反的任务。通过与我们的ASTN进行竞争,我们可以训练出一个对变形具有鲁棒的的更好的检测器。
STN回顾
空间变压器网络[14]有三个组成部分:定位网络,电网发电机和采样器。给定特征图作为输入,定位网络将估计变形的变量(例如,旋转度,平移距离和比例因子)。这些变量将被用作网格生成器和采样器在特征图上操作的输入。输出是一个变形的特征映射。注意,我们只需要学习本地化网络中的参数。STN的关键贡献之一是使整个过程可微,从而使定位网络可以通过反向传播直接针对分类目标进行优化。有关更多技术细节,请参阅[14]。
对抗STN
在我们的对抗性空间变形网络中,我们关注的是特征图的旋转。也就是说,给定一个在roi池化层之后的特征图作为输入,我们的ASTN将学习旋转特征图以使其更难识别。我们的定位网络由3个完全连接的层组成,其中前两层使用ImageNet预训练网络中的fc6和fc7层进行初始化,就像我们的对抗性空间丢弃网络一样。
我们联合训练了ASTN和Fast-RCNN检测器。对于检测器的训练,与ASDN中的过程类似,我们的ASTN首先对roi池化后的特征进行变换,然后转发给更高层来计算SoftMax损失。为了训练ASTN,我们对其进行了优化,使检测器将前景对象分类为背景类。与训练ASDN不同的是,由于空间变换是可微的,我们可以直接利用分类损失对ASTN定位网络中的参数进行逆prop和微调。
实现细节
在实验中,我们发现限制ASTN产生的旋转度是非常重要的。否则,很容易将目标颠倒过来,这在大多数情况下是最难识别的。我们将旋转度限制在10◦顺时针和逆时针。我们不是在同一方向上旋转所有的特征图,而是将通道维度上的特征图划分为4个块,并对不同的块估计4个不同的旋转角度。由于每个通道对应于一种类型特征的激活,因此旋转通道分别对应于目标在不同方向上的旋转部分,从而导致变形。我们还发现,如果我们对所有特征图使用一个旋转角度,ASTN通常会预测最大的角度。通过使用4个不同的角度而不是一个角度,我们增加了任务的复杂性,从而防止了网络预测琐碎的变形。
4.2.3 对抗融合
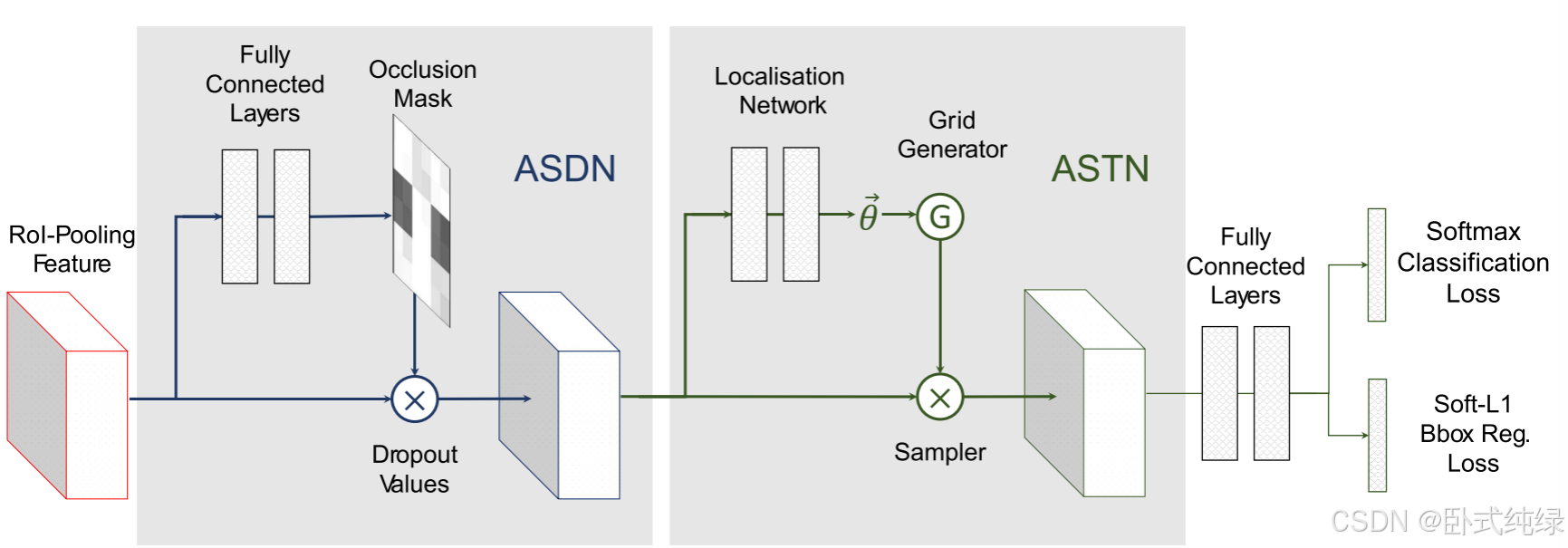
ASDN和ASTN这两个对抗网络也可以在同一个检测框架下进行组合和训练。因为这两个网络提供不同类型的信息。通过同时与这两个网络竞争,我们的检测器变得更加鲁棒的。
我们以顺序的方式将这两个网络组合到Fast-RCNN框架中。如图4所示,roi池后提取的特征映射首先被转发到我们的ASDN,其中删除了一些激活。修改后的特征通过ASTN进一步变形。
五、实验
我们在PASCAL VOC 2007、PASCAL VOC 2012[4]和MS COCO[18]数据集上进行了实验。作为标准实践,我们对PASCAL VOC 2007数据集进行了大部分烧蚀研究。我们还报告了PASCAL VOC 2012和COCO数据集上的数字。最后,我们将我们的方法与在线硬例挖掘(OHEM)[33]方法进行了比较。
5.1 实验设置
PASCAL VOC
对于VOC数据集,我们使用“trainval”集进行训练,使用“test”集进行测试。我们遵循标准Fast-RCNN[6]的大部分设置进行训练。我们申请SGD 80K来训练我们的模型。学习率从0.001开始,在60K次迭代后下降到0.0001。我们在训练中使用选择性搜索建议[40]。
MS COCO
对于COCO数据集,我们使用' trainval35k '集进行训练,使用' minival '集进行测试。在Fast-RCNN b[6]的训练过程中,我们使用了32万次迭代的SGD。学习率从0.001开始,在280K次迭代后下降到0.0001。对于目标建议,我们使用DeepMask建议[24]。
在所有的实验中,我们用于训练的小批量大小是256个建议和2个图像。我们遵循Fast-RCNN的Torch实现[44]。有了这些设置,我们的基线值略好于[6]中报告的值。为了防止Fast-RCNN对修改后的数据进行过拟合,我们在批处理中提供了一张没有任何对抗性遮挡/变形的图像,并将我们的方法应用于批处理中的另一张图像。
5.2 PASCAL VOC2007结果
我们在表1中报告了Fast-RCNN训练期间使用ASTN和ASDN的结果。对于AlexNet架构[16],我们实现的基线是57.0% mAP。基于此设置,与我们的ASTN模型联合学习达到58.1%,与ASDN模型联合学习的性能更高,达到58.5%。由于这两种方法是互补的,将ASDN和ASTN结合到我们的完整模型中可以再次提高58.9%的mAP。
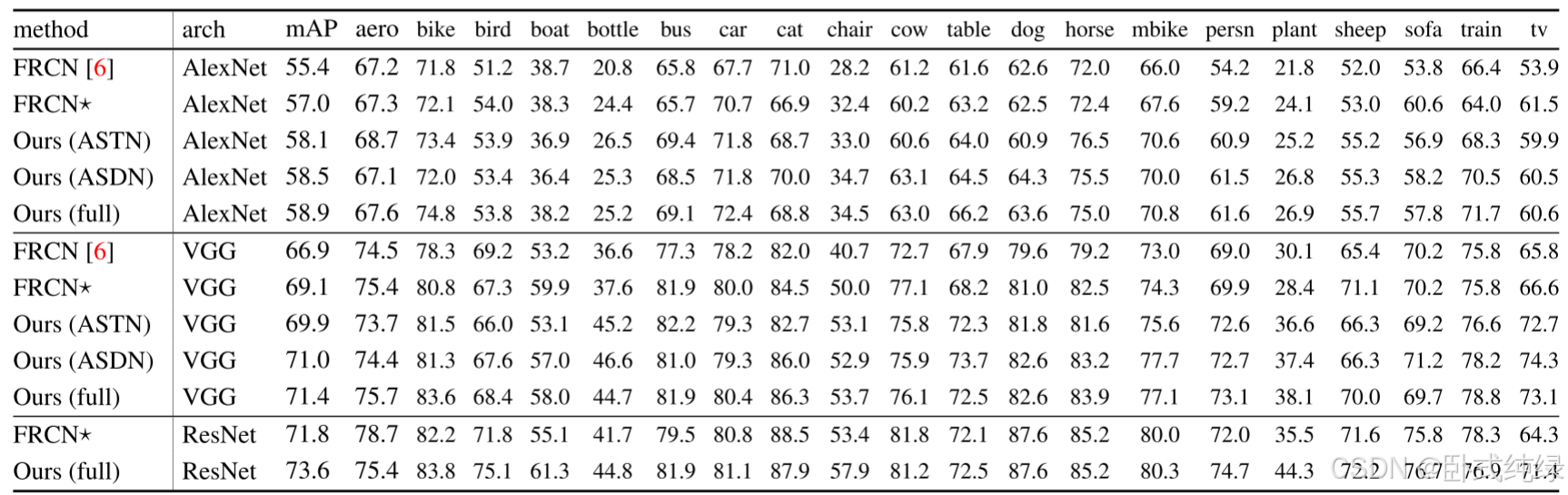
对于VGG16架构[36],我们进行了相同的一组实验。首先,我们的基线模型达到了69.1%的mAP,远高于2010年报道的66.9%。在此基础上,与我们的ASTN模型联合学习,mAP提高到69.9%,ASDN模型的mAP达到71.0%。我们采用ASTN和ASDN的完整模型将性能提高到71.4%。我们的最终结果在基线上提高了2.3%。
为了证明我们的方法也适用于非常深度的cnn,我们在训练Fast-RCNN中应用了ResNet-101[9]架构。如表1中的最后两行所示,使用ResNet-101的Fast-RCNN的性能为71.8% mAP。通过对抗性训练,结果为73.6%的mAP。我们可以看到,我们的方法在不同类型的体系结构上一致地提高了性能。
5.2.1 消融分析
ASDN分析
我们使用AlexNet架构将我们的对抗性空间丢弃网络与训练中的各种丢弃/遮挡策略进行比较。我们尝试的第一个简单基线是RoI-Pooling之后特征上的随机空间dropout。为了进行公平的比较,我们掩盖了与ASDN网络相同数量的神经元的激活。如表2所示,随机dropout的性能为57.3% mAP,略好于基线。我们比较的另一个dropout策略是我们在预训练ASDN中应用的类似策略(图3)。我们详尽地枚举不同类型的遮挡,并在每次迭代中选择最佳遮挡进行训练。性能为57.7% mAP (Ours (hard dropout)),略好于随机dropout。

由于我们发现穷尽策略只能探索非常有限的闭塞策略空间,因此我们使用预训练的ASDN网络来取代它。然而,当我们固定ASDN的参数时,我们发现性能为57.5% mAP (Ours(固定ASDN)),不如穷举策略好。原因是固定的ASDN没有收到任何来自更新的Fast-RCNN的反馈,而穷举搜索得到了。如果我们联合学习ASDN和Fast-RCNN,我们可以得到58.5%的mAP,比基线提高1.5%,没有dropout。这一证据表明,ASDN和FastRCNN的联合学习是不同之处。
ASTN分析
我们比较了我们的对抗性空间Transformer网络与随机抖动的目标建议。增强包括在Fast-RCNN训练过程中对建议的尺度、长宽比和旋转的随机变化。对于AlexNet,使用随机抖动的性能为57.3% mAP,而我们的ASTN结果为58.1%。对于VGG16,我们有68.6%的随机抖动和69.9%的ASTN。对于这两种体系结构,ASTN模型比随机抖动效果更好。
5.2.2 基于种类的分析
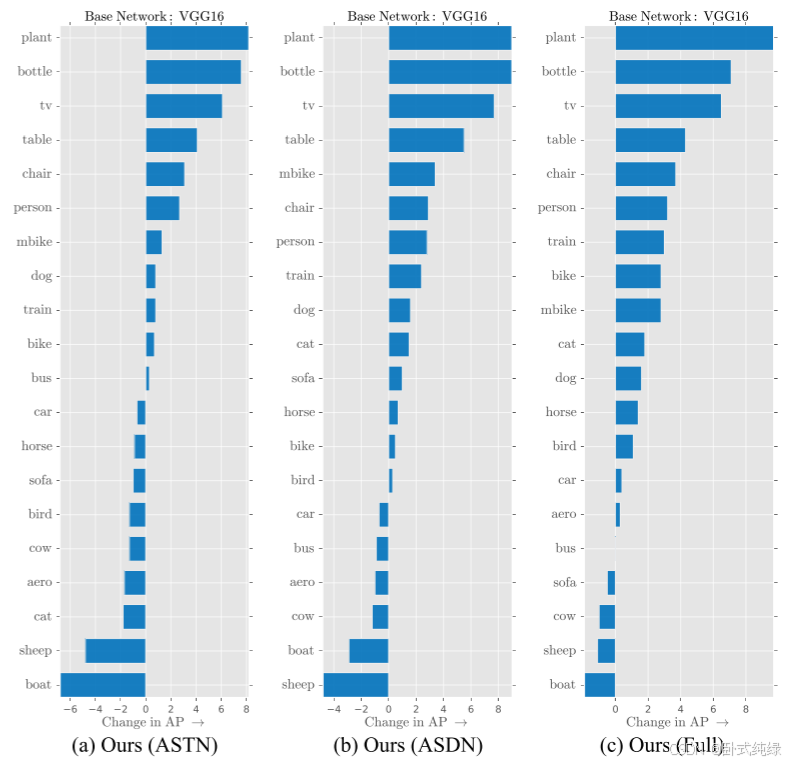
图5显示了每个类别的性能随闭塞和变形的变化情况。有趣的是,被ASTN和ASDN帮助的类别似乎非常相似。似乎植物和瓶子的性能都提高了对抗训练。然而,将两种转换结合在一起似乎可以提高某些类别的性能,这些类别仅使用遮挡或变形会受到伤害。具体来说,像汽车和飞机这样的类别通过结合两个对抗过程而得到帮助。
5.2.3 定性结果
图6显示了使用诊断代码[10]的方法的一些误报。这些例子是精心挑选的,它们只出现在对抗性学习的误报列表中,而不是最初的FastRCNN。这些结果表明了对抗性学习的一些缺点。在某些情况下,对手会产生类似于其他目标类别的变形或遮挡,并导致过度泛化。例如,我们的方法隐藏了自行车的轮子,这导致轮椅被归类为自行车。

5.3 PASCAL VOC2012 和 MS COCO数据集结果
我们在表3中显示了在PASCAL VOC 2012数据集上使用VGG16的结果,其中我们的基线性能为66.4%。我们使用ASDN和ASTN联合学习的完整方法将mAP提高2.6%,达到69.0%。这再次表明VGG对VOC2012的性能提升是显著的。我们还观察到,我们的方法提高了VOC 2012中除沙发以外的所有类别的性能。我们认为这可能是因为VOC 2012的多样性更大。

最后在MS COCO数据集中报告结果。VGG16架构的基线方法在VOC指标上为42.7% AP50,在标准COCO指标上为25.7% AP。通过应用我们的方法,我们在VOC和COCO指标上分别实现了46.2%的AP50和27.1%的AP。
5.4 和OHEM的对比
我们的方法也与在线硬例挖掘(OHEM)方法相关。我们的方法允许我们对数据集中可能不存在的数据点进行采样,而OHEM受数据集的约束。然而,OHEM的特征更真实,因为它们是从真实图像中提取的。比较而言,我们的方法(71.4%)优于OHEM(69.9%)。然而,我们的结果(69.0%)不如OHEM(69.8%)。由于这两种方法在训练中生成或选择不同类型的特征,我们认为它们应该是互补的。为了证明这一点,我们使用了这两种方法的集合,并将其与OHEM和我们单独针对VOC 2012的单独集合进行比较。结果表明,两种方法的mAP合集达到71.7%,而两个OHEM模型(71.2%)或我们的两个模型(70.2%)的mAP合集则不太好,说明两种方法的互补性。
六、结论
目标检测的长期目标之一是学习对遮挡和变形不变化的目标模型。目前的方法主要是通过使用大规模数据集来学习这些不变性。在本文中,我们认为,像类别一样,闭塞和变形也遵循长尾分布:其中一些非常罕见,即使在大规模数据集中也很难对其进行采样。我们建议使用对抗性学习策略来学习这些不变性。关键思想是结合原始目标检测器来学习对手。这个对手在飞行中创建了具有不同遮挡和变形的示例,这样这些遮挡/变形使得原始目标检测器难以分类。我们的对抗网络不是在像素空间中生成示例,而是修改特征来模拟遮挡和变形。我们在实验中表明,这种对抗性学习策略在VOC和COCO数据集上的检测性能显著提高。