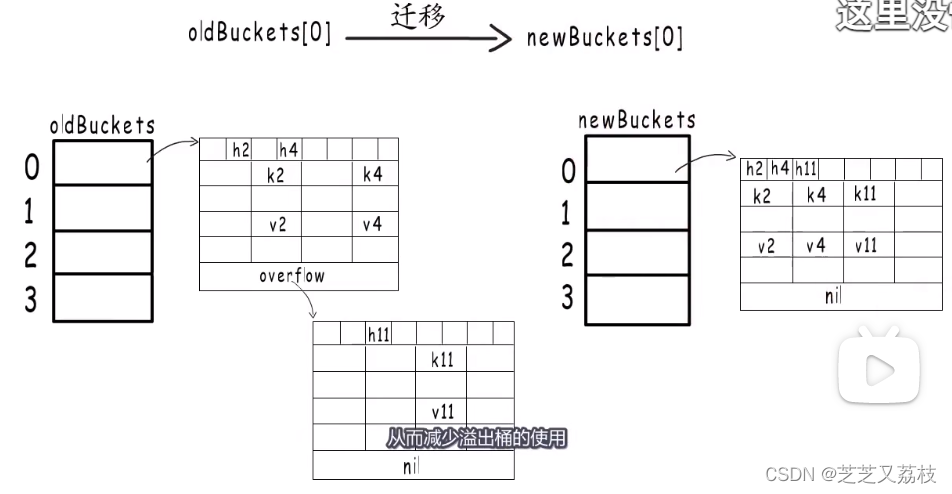
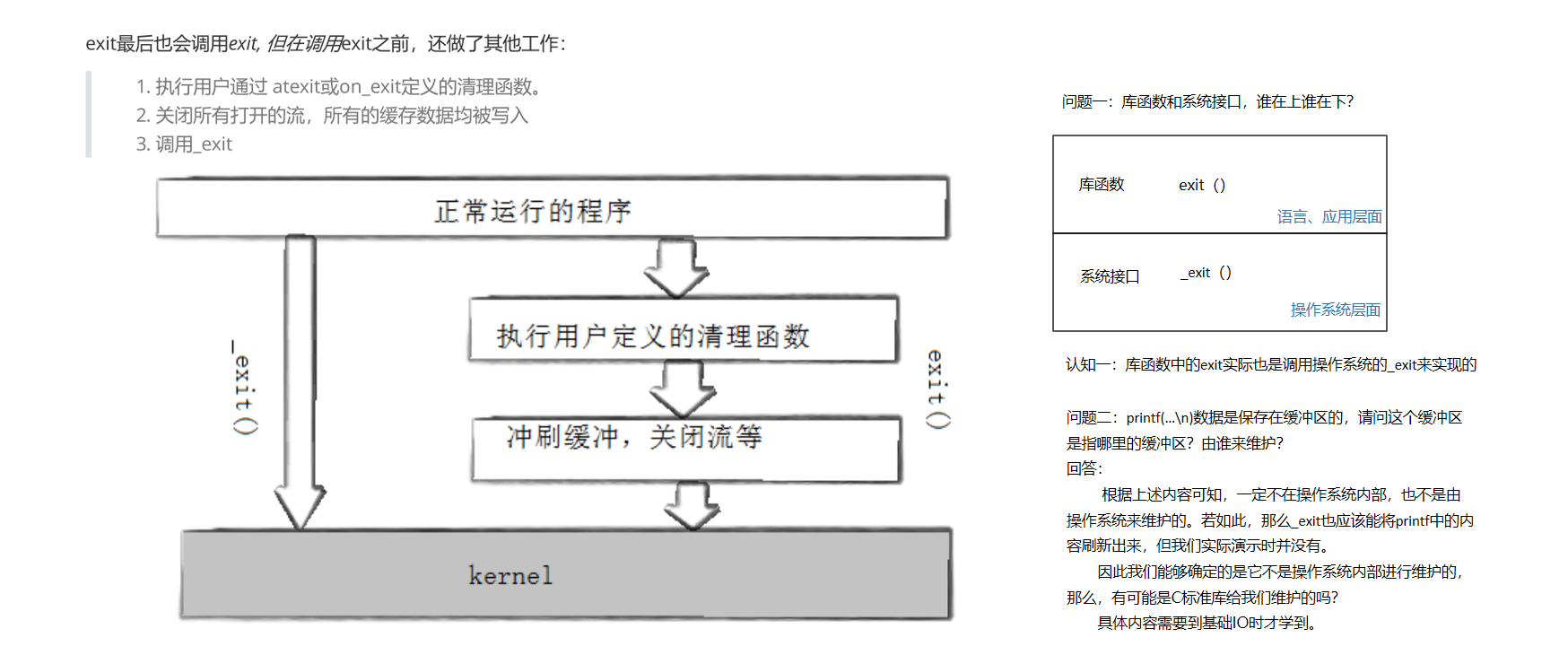
4. Shuffle
(1) Shuffle 的原理和执行过程
在Scala中,Shuffle是指对集合或序列进行随机打乱或重新排列的操作。它可以用于打乱集合中元素的顺序,以便在后续的操作中获得更好的随机性或均匀性。
在Scala中,可以使用scala.util.Random类的shuffle方法来实现Shuffle操作。以下是一个示例:
import scala.util.Random
val list = List(1, 2, 3, 4, 5)
val shuffledList = Random.shuffle(list)
println(shuffledList)
在上述示例中,我们首先定义了一个整数列表list,其中包含了一些元素。然后,使用Random.shuffle方法对该列表进行Shuffle操作,并将结果存储在shuffledList中。最后,通过打印输出,我们可以看到shuffledList中的元素顺序已被打乱。
需要注意的是,Random.shuffle方法返回一个新的打乱后的集合,而不会改变原始集合。如果你希望对原始集合进行Shuffle操作,可以使用可变集合(如ListBuffer)或将打乱后的集合重新赋值给原始集合。
除了scala.util.Random.shuffle方法外,还可以使用其他库或算法来实现Shuffle操作。例如,Apache Spark中的Shuffle操作用于重新分区数据,或在机器学习中用于数据集的随机化。
总之,Shuffle是指对集合或序列进行随机打乱或重新排列的操作,在Scala中可以使用scala.util.Random.shuffle方法来实现。
➢ shuffleWriterProcessor(写处理器)
shuffleWriterProcessor(写处理器)通常是指在分布式计算框架中用于处理Shuffle阶段的组件或模块。Shuffle是指在数据处理过程中,将数据根据某个键(key)进行分组和重新分配的过程。
在分布式计算中,Shuffle是一个关键的阶段,它通常发生在Map阶段和Reduce阶段之间。在Map阶段,数据被划分为多个键值对(key-value pairs),然后根据键进行局部聚合。在Shuffle阶段,数据根据键被重新分组,以便将具有相同键的数据发送给相同的Reduce任务进行全局聚合。
shuffleWriterProcessor是在Shuffle阶段负责将数据写入临时存储(例如磁盘或内存缓冲区)的处理器。它的主要功能是接收从Map任务传来的数据,根据键进行分组,并将相同键的数据写入适当的位置,以便后续的Reduce任务可以读取和处理。
具体而言,shuffleWriterProcessor可能会涉及以下操作:
-
数据分组:接收从Map任务传来的数据,根据键进行分组。相同键的数据会被放入同一个分组中。
-
数据排序:可选的操作,根据键对分组内的数据进行排序。这是为了确保在后续的Reduce任务中按键的顺序进行处理。
-
数据写入:将分组的数据写入临时存储,例如磁盘或内存缓冲区。每个分组的数据通常会写入一个临时文件或数据块中。
-
数据索引:为了在后续的Reduce任务中能够准确地定位和读取数据,可能需要维护一个索引结构,用于记录每个键对应的数据存储位置。
-
数据传输:将临时存储的数据传输给相应的Reduce任务。这通常涉及网络通信和数据传输协议的使用。
-
销毁临时存储:在Shuffle阶段结束后,通常需要清理和销毁使用的临时存储,以释放资源。
需要注意的是,具体的shuffleWriterProcessor实现可能会因分布式计算框架的不同而有所差异。例如,在Apache Spark中,Shuffle阶段的写处理器称为ShuffleWriter,负责将数据写入磁盘上的临时文件,并生成索引以供后续的Reduce任务使用。
总之,shuffleWriterProcessor是用于处理Shuffle阶段的写操作的组件或模块,在分布式计算中扮演着重要的角色,它负责将数据根据键分组并写入临时存储,以便后续的Reduce任务进行全局聚合和处理。具体实现可能因框架而异,但通常涉及数据分组、排序、写入、索引和数据传输等操作。
➢ ShuffleManager: Hash(早期) & Sort(当前)
ShuffleManager(Shuffle 管理器)是在分布式计算框架中负责管理 Shuffle 阶段的组件或模块。它处理数据在 Map 阶段的局部聚合和在 Reduce 阶段的全局聚合,以及数据的分组、排序、传输和持久化等操作。
ShuffleManager 的主要责任是协调和管理 Shuffle 阶段的各个子任务,包括 Map 任务和 Reduce 任务。它通常涉及以下功能:
-
Shuffle 数据的分组和排序:ShuffleManager 负责将 Map 阶段输出的键值对根据键进行分组,并可能根据键的排序要求对数据进行排序,以便后续的 Reduce 阶段能够按键有序地进行处理。
-
Shuffle 数据的传输和持久化:ShuffleManager 管理 Shuffle 数据的传输和存储。它负责将 Map 任务输出的数据传输给对应的 Reduce 任务,并确保数据的可靠传输。在传输过程中,ShuffleManager 可能会使用网络通信协议,将数据从 Map 任务所在的节点发送到 Reduce 任务所在的节点,并在接收端进行数据的缓存或写入磁盘等操作。
-
Shuffle 数据的缓存和合并:在 Shuffle 阶段,ShuffleManager 可能会使用缓存来暂存和管理传输的数据,以提高传输效率和节约存储空间。它可能会在缓存达到一定阈值时触发数据的合并操作,将多个缓存中的数据合并成更大的块,并写入磁盘或其他持久化存储介质。
-
Shuffle 数据的元数据管理:ShuffleManager 维护和管理 Shuffle 阶段的元数据,包括各个 Map 任务和 Reduce 任务的信息、数据块的位置和大小等。这些元数据可以用于后续的任务调度、数据定位和数据读取等操作。
需要注意的是,具体的 ShuffleManager 实现可能因分布式计算框架的不同而有所差异。例如,在 Apache Spark 中,ShuffleManager 负责管理 Shuffle 阶段的数据传输和存储,使用多种策略来优化数据传输和持久化的性能,如 SortShuffleManager 和 HashShuffleManager。
总之,ShuffleManager 是负责管理和协调 Shuffle 阶段的组件或模块,在分布式计算中扮演着重要的角色。它处理 Shuffle 阶段的数据分组、排序、传输和持久化等操作,以确保数据能够按照正确的方式传递给 Reduce 任务并进行全局聚合和处理。具体实现可能因框架而异,但通常涉及数据的分组、排序、传输、持久化和元数据管理等功能。
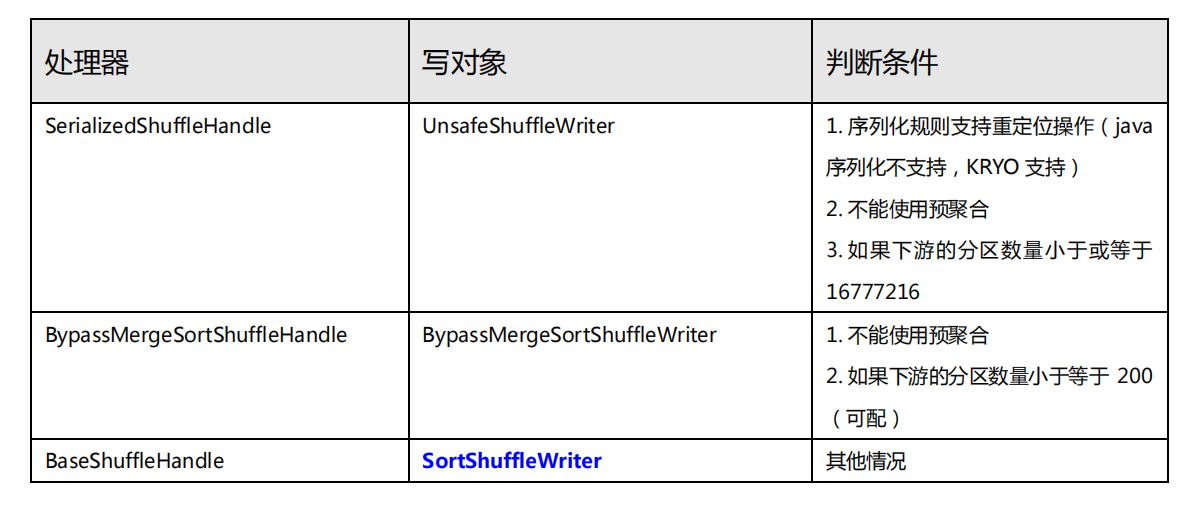
(2) Shuffle 写磁盘
Shuffle 写磁盘是指在分布式计算中的 Shuffle 阶段,将数据从 Map 任务写入到磁盘上的临时文件或数据块中。这是为了在后续的 Reduce 阶段能够根据键(key)对数据进行全局聚合和处理。
在 Shuffle 阶段,Map 任务将局部聚合后的数据根据键分组,并将相同键的数据发送给相应的 Reduce 任务。在这个过程中,Shuffle 写磁盘的步骤通常包括以下操作:
-
数据分组:Map 任务将输出的键值对根据键进行分组,将具有相同键的数据放入同一个分组中。
-
数据排序(可选):根据具体的需求,可能需要对分组内的数据按键进行排序,以确保在后续的 Reduce 阶段能够按键顺序进行处理。排序可以提高 Reduce 阶段的效率和性能,但也会增加计算和存储开销。
-
数据写入:将分组的数据写入磁盘上的临时文件或数据块中。每个分组的数据通常会写入一个独立的文件或数据块,以便后续的 Reduce 任务可以读取和处理。
-
索引和元数据管理:为了在后续的 Reduce 阶段能够准确地定位和读取数据,通常需要维护一个索引或元数据结构,用于记录每个键对应的数据存储位置。这些索引或元数据可以存储在内存中,以提高数据读取的性能和效率。
-
清理和回收资源:在 Shuffle 阶段结束后,通常需要清理和回收临时文件或数据块所占用的磁盘空间,并释放相关的资源。
需要注意的是,具体的 Shuffle 写磁盘实现可能因分布式计算框架的不同而有所差异。例如,在 Apache Spark 中,Shuffle 写磁盘的操作是由 ShuffleWriter 负责的,它将数据写入到磁盘上的临时文件中,并生成相应的索引以供后续的 Reduce 任务使用。
总之,Shuffle 写磁盘是指在分布式计算中的 Shuffle 阶段,将数据从 Map 任务写入到磁盘上的临时文件或数据块中。它包括数据的分组、排序、写入和索引管理等操作,以确保数据能够按键进行全局聚合和处理。具体实现可能因框架而异,但通常涉及将数据写入临时文件或数据块,并管理相应的索引和元数据。
(3) Shuffle 读取磁盘
Shuffle 读取磁盘是指在分布式计算中的 Shuffle 阶段,从磁盘上的临时文件或数据块中读取数据,以进行后续的全局聚合和处理。
在 Shuffle 阶段,数据经过 Map 任务的局部聚合和写入磁盘后,需要被 Reduce 任务读取并进行全局聚合。Shuffle 读取磁盘的步骤通常包括以下操作:
-
读取元数据:首先,需要读取存储在内存或磁盘上的 Shuffle 元数据,其中包含了各个键对应的数据存储位置、文件路径和大小等信息。这些元数据可以帮助确定读取数据的位置和方式。
-
确定数据位置:根据元数据中的信息,确定需要读取的数据所在的磁盘文件或数据块的位置。这可能涉及到根据键的哈希值或排序规则进行数据定位和分配。
-
读取数据:根据确定的位置,从磁盘上的临时文件或数据块中读取数据。读取的方式可能根据具体的分布式计算框架和数据存储格式而有所不同。
-
数据解析和反序列化:根据数据的存储格式,对读取的数据进行解析和反序列化,以将其转换为可操作的数据对象或结构。
-
数据传递给 Reduce 任务:读取并解析的数据将被传递给相应的 Reduce 任务进行全局聚合和处理。这通常涉及数据传输协议和网络通信。
-
清理和回收资源:在 Shuffle 阶段结束后,需要清理和回收使用的临时文件或数据块,释放相关的资源。
具体的 Shuffle 读取磁盘实现可能因分布式计算框架的不同而有所差异。例如,在 Apache Spark 中,Shuffle 读取磁盘的操作是由 ShuffleReader 负责的,它根据元数据信息和数据存储格式,从磁盘上的临时文件中读取和反序列化数据,并将其传递给相应的 Reduce 任务进行全局聚合和处理。
总之,Shuffle 读取磁盘是指在分布式计算中的 Shuffle 阶段,从磁盘上的临时文件或数据块中读取数据进行全局聚合和处理。它涉及元数据的读取、数据位置的确定、数据的读取和解析,以及数据的传递给 Reduce 任务等操作。具体实现可能因框架而异,但通常涉及读取临时文件或数据块,并解析数据以供后续的全局聚合和处理使用。
5. 内存的管理
(1) 内存的分类

内存可以根据不同的标准进行分类。以下是几种常见的内存分类方式:
-
主存(主内存):主存是指计算机中用于存储程序和数据的主要存储区域。它通常是指计算机的主内存,例如随机存取存储器(RAM),用于临时存储正在运行的程序和数据。

-
缓存内存:缓存内存是位于CPU和主存之间的一层高速存储器,用于临时存储CPU需要频繁访问的数据和指令。缓存内存可以分为多级,例如一级缓存(L1 Cache)、二级缓存(L2 Cache)和三级缓存(L3 Cache)等。
-
虚拟内存:虚拟内存是计算机系统中的一种技术,它将主存和磁盘上的存储空间结合起来,使得程序可以访问比实际物理内存更大的地址空间。虚拟内存可以提供更大的内存容量,并允许多个程序同时运行。

-
显存(图形内存):显存是专门用于图形处理的内存,用于存储图像、纹理、帧缓冲和其他与图形相关的数据。它通常是由独立的显卡或集成显卡提供的。

-
高速缓存(Cache):高速缓存是计算机系统中用于存储近期访问的数据的一种高速存储器。它可以分为指令缓存(Instruction Cache)和数据缓存(Data Cache),用于提高CPU对指令和数据的访问速度。
-
闪存(Flash Memory):闪存是一种非易失性存储器,常用于存储数据和文件。它具有较快的读取速度和较低的功耗,适用于可移动存储介质(如USB闪存驱动器)和固态硬盘(SSD)等应用。
这些分类方式涵盖了内存的不同类型和用途。每种内存类型都具有不同的特点和适用场景,用于满足计算机系统中不同组件和任务的存储需求。
(2) 内存的配置
内存的配置涉及将可用的内存资源分配给不同的组件和任务,以满足系统的需求和性能要求。以下是一些常见的内存配置方式:
-
固定内存分配:固定内存分配是指将内存的一定部分固定分配给特定的组件或任务。这种配置方式适用于内存需求相对稳定且预先可知的情况,例如操作系统的内核空间、显存和固定的系统进程等。
-
动态内存分配:动态内存分配是指根据实际需求和情况,动态地分配内存资源给不同的组件和任务。这种配置方式可以根据需求进行灵活的调整,以提供最佳的性能和资源利用率。
-
内存分段:内存分段是将内存分割成不同的段或区域,每个段用于存储不同类型的数据或服务。例如,操作系统可以将内存分为代码段、数据段、堆栈段等,以便有效地管理和保护不同类型的内存数据。
-
内存分页:内存分页是将内存划分为固定大小的页(Page),并按需将进程的页加载到内存中。这种配置方式允许虚拟内存管理和实现内存的分页和置换,以满足多个进程同时运行时的内存需求。
-
内存通道配置:对于多通道内存架构(如双通道或四通道内存),可以将内存模块均匀地配置在不同的内存通道上,以提高内存的并行访问和带宽。这种配置方式适用于需要高内存带宽的计算任务。
-
缓存配置:缓存配置涉及将缓存资源分配给不同的处理器核心或任务,以提高数据的访问速度和性能。例如,多级缓存中的缓存块可以被分配给不同的处理器核心,以减少缓存争用和提高缓存命中率。
内存的配置取决于具体的系统架构、应用需求和性能目标。在进行内存配置时,需要综合考虑各个组件和任务的内存需求、数据访问模式、并发性、延迟要求和资源限制等因素,以实现最佳的内存资源分配和性能优化。