本章概要
- 复用
- 继承
- “是一个”与“像是一个”的关系
- 多态
复用
一个类经创建和测试后,理应是可复用的。然而很多时候,由于程序员没有足够的编程经验和远见,我们的代码复用性并不强。
代码和设计方案的复用性是面向对象程序设计的优点之一。我们可以通过重复使用某个类的对象来达到这种复用性。同时,我们也可以将一个类的对象作为另一个类的成员变量使用。新的类可以是由任意数量和任意类型的其他对象构成。这里涉及到“组合”和“聚合”的概念:
- 组合(Composition)经常用来表示“拥有”关系(has-a relationship)。例如,“汽车拥有引擎”。
- 聚合(Aggregation)动态的组合。
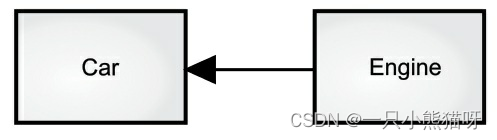
上图中实心三角形指向“ Car ”表示 组合 的关系;如果是 聚合 关系,可以使用空心三角形。
(译者注:组合和聚合都属于关联关系的一种,只是额外具有整体-部分的意义。至于是聚合还是组合,需要根据实际的业务需求来判断。可能相同超类和子类,在不同的业务场景,关联关系会发生变化。只看代码是无法区分聚合和组合的,具体是哪一种关系,只能从语义级别来区分。聚合关系中,整件不会拥有部件的生命周期,所以整件删除时,部件不会被删除。再者,多个整件可以共享同一个部件。组合关系中,整件拥有部件的生命周期,所以整件删除时,部件一定会跟着删除。而且,多个整件不可以同时共享同一个部件。这个区别可以用来区分某个关联关系到底是组合还是聚合。两个类生命周期不同步,则是聚合关系,生命周期同步就是组合关系。)
使用“组合”关系给我们的程序带来极大的灵活性。通常新建的类中,成员对象会使用 private 访问权限,这样应用程序员则无法对其直接访问。我们就可以在不影响客户代码的前提下,从容地修改那些成员。我们也可以在“运行时"改变成员对象从而动态地改变程序的行为,这进一步增大了灵活性。下面一节要讲到的“继承”并不具备这种灵活性,因为编译器对通过继承创建的类进行了限制。
在面向对象编程中经常重点强调“继承”。在新手程序员的印象里,或许先入为主地认为“继承应当随处可见”。沿着这种思路产生的程序设计通常拙劣又复杂。相反,在创建新类时首先要考虑“组合”,因为它更简单灵活,而且设计更加清晰。等我们有一些编程经验后,一旦需要用到继承,就会明显意识到这一点。
继承
“对象”的概念给编程带来便利。它在概念上允许我们将各式各样的数据和功能封装到一起,这样便可恰当表达“问题空间”的概念,而不用受制于必须使用底层机器语言。
通过使用 class 关键字,这些概念形成了编程语言中的基本单元。遗憾的是,这么做还是有很多麻烦:在创建了一个类之后,即使另一个新类与其具有相似的功能,你还是得重新创建一个新类。但我们若能利用现成的数据类型,对其进行“克隆”,再根据情况进行添加和修改,情况就显得理想多了。“继承”正是针对这个目标而设计的。但继承并不完全等价于克隆。在继承过程中,若原始类(正式名称叫作基类、超类或父类)发生了变化,修改过的“克隆”类(正式名称叫作继承类或者子类)也会反映出这种变化。

这个图中的箭头从派生类指向基类。正如你将看到的,通常有多个派生类。类型不仅仅描述一组对象的约束,它还涉及其他类型。两种类型可以具有共同的特征和行为,但是一种类型可能包含比另一种类型更多的特征,并且还可以处理更多的消息(或者以不同的方式处理它们)。继承通过基类和派生类的概念来表达这种相似性。基类包含派生自它的类型之间共享的所有特征和行为。创建基类以表示思想的核心。从基类中派生出其他类型来表示实现该核心的不同方式。
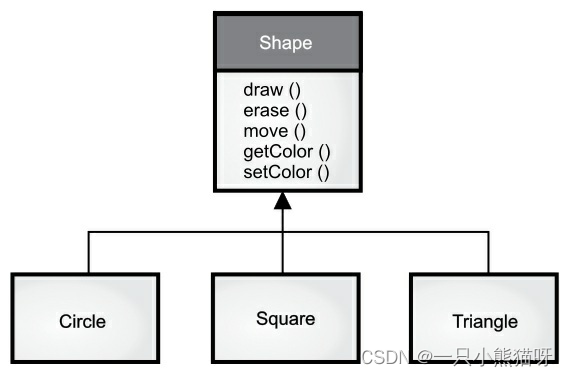
例如,垃圾回收机对垃圾进行分类。基类是“垃圾”。每块垃圾都有重量、价值等特性,它们可以被切碎、熔化或分解。在此基础上,可以通过添加额外的特性(瓶子有颜色,钢罐有磁性)或行为(铝罐可以被压碎)派生出更具体的垃圾类型。此外,一些行为可以不同(纸张的价值取决于它的类型和状态)。使用继承,你将构建一个类型层次结构,来表示你试图解决的某种类型的问题。第二个例子是常见的“形状”例子,可能用于计算机辅助设计系统或游戏模拟。基类是“形状”,每个形状都有大小、颜色、位置等等。每个形状可以绘制、擦除、移动、着色等。由此,可以派生出(继承出)具体类型的形状——圆形、正方形、三角形等等——每个形状可以具有附加的特征和行为。

例如,某些形状可以翻转。有些行为可能不同,比如计算形状的面积。类型层次结构体现了形状之间的相似性和差异性。以相同的术语将解决方案转换成问题是有用的,因为你不需要在问题描述和解决方案描述之间建立许多中间模型。通过使用对象,类型层次结构成为了主要模型,因此你可以直接从真实世界中对系统的描述过渡到用代码对系统进行描述。事实上,有时候,那些善于寻找复杂解决方案的人会被面向对象设计的简单性难倒。从现有类型继承创建新类型。这种新类型不仅包含现有类型的所有成员(尽管私有成员被隐藏起来并且不可访问),而且更重要的是它复制了基类的接口。也就是说,基类对象接收的所有消息也能被派生类对象接收。根据类接收的消息,我们知道类的类型,因此派生类与基类是相同的类型。
在前面的例子中,“圆是形状”。这种通过继承的类型等价性是理解面向对象编程含义的基本门槛之一。因为基类和派生类都具有相同的基本接口,所以伴随此接口的必定有某些具体实现。也就是说,当对象接收到特定消息时,必须有可执行代码。如果继承一个类而不做其他任何事,则来自基类接口的方法直接进入派生类。这意味着派生类和基类不仅具有相同的类型,而且具有相同的行为,这么做没什么特别意义。
有两种方法可以区分新的派生类与原始的基类。第一种方法很简单:在派生类中添加新方法。这些新方法不是基类接口的一部分。这意味着基类不能满足你的所有需求,所以你添加了更多的方法。继承的这种简单而原始的用途有时是解决问题的完美解决方案。然而,还是要仔细考虑是否在基类中也要有这些额外的方法。这种设计的发现与迭代过程在面向对象程序设计中会经常发生。
尽管继承有时意味着你要在接口中添加新方法(尤其是在以 extends 关键字表示继承的 Java 中),但并非总需如此。第二种也是更重要地区分派生类和基类的方法是改变现有基类方法的行为,这被称为覆盖 (overriding)。要想覆盖一个方法,只需要在派生类中重新定义这个方法即可。
“是一个”与“像是一个”的关系
对于继承可能会引发争论:继承应该只覆盖基类的方法(不应该添加基类中没有的方法)吗?如果这样的话,基类和派生类就是相同的类型了,因为它们具有相同的接口。这会造成,你可以用一个派生类对象完全替代基类对象,这叫作"纯粹替代",也经常被称作"替代原则"。在某种意义上,这是一种处理继承的理想方式。我们经常把这种基类和派生类的关系称为是一个(is-a)关系,因为可以说"圆是一个形状"。判断是否继承,就看在你的类之间有无这种 is-a 关系。
有时你在派生类添加了新的接口元素,从而扩展接口。虽然新类型仍然可以替代基类,但是这种替代不完美,原因在于基类无法访问新添加的方法。这种关系称为像是一个(is-like-a)关系。新类型不但拥有旧类型的接口,而且包含其他方法,所以不能说新旧类型完全相同。
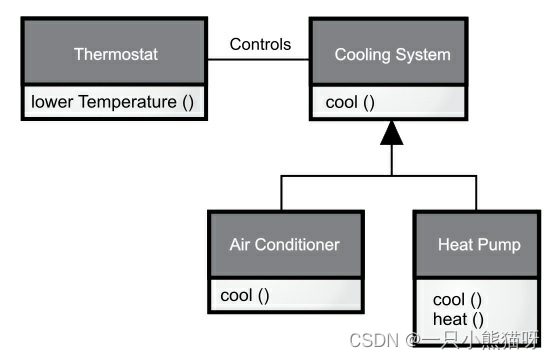
以空调为例,假设房间里已经安装好了制冷设备的控制器,即你有了控制制冷设备的接口。想象一下,现在空调坏了,你重新安装了一个既制冷又制热的热力泵。热力泵就像是一个(is-like-a)空调,但它可以做更多。因为当初房间的控制系统被设计成只能控制制冷设备,所以它只能与新对象(热力泵)的制冷部分通信。新对象的接口已经扩展了,现有控制系统却只知道原来的接口,一旦看到这个设计,你就会发现,作为基类的制冷系统不够一般化,应该被重新命名为"温度控制系统",也应该包含制热功能,这样的话,我们就可以使用替代原则了。上图反映了在现实世界中进行设计时可能会发生的事情。
当你看到替代原则时,很容易会认为纯粹替代是唯一可行的方式,并且使用纯粹替代的设计是很好的。但有些时候,你会发现必须得在派生(扩展)类中添加新方法(提供新的接口)。只要仔细审视,你可以很明显地区分两种设计方式的使用场合。
多态
我们在处理类的层次结构时,通常把一个对象看成是它所属的基类,而不是把它当成具体类。通过这种方式,我们可以编写出不局限于特定类型的代码。在上个“形状”的例子中,“方法”(method)操纵的是通用“形状”,而不关心它们是“圆”、“正方形”、“三角形”还是某种尚未定义的形状。所有的形状都可以被绘制、擦除和移动,因此“方法”向其中的任何代表“形状”的对象发送消息都不必担心对象如何处理信息。
这样的代码不会受添加的新类型影响,并且添加新类型是扩展面向对象程序以处理新情况的常用方法。 例如,你可以通过通用的“形状”基类派生出新的“五角形”形状的子类,而不需要修改通用"形状"基类的方法。通过派生新的子类来扩展设计的这种能力是封装变化的基本方法之一。
这种能力改善了我们的设计,且减少了软件的维护代价。如果我们把派生的对象类型统一看成是它本身的基类(“圆”当作“形状”,“自行车”当作“车”,“鸬鹚”当作“鸟”等等),编译器(compiler)在编译时期就无法准确地知道什么“形状”被擦除,哪一种“车”在行驶,或者是哪种“鸟”在飞行。这就是关键所在:当程序接收这种消息时,程序员并不想知道哪段代码会被执行。“绘图”的方法可以平等地应用到每种可能的“形状”上,形状会依据自身的具体类型执行恰当的代码。
如果不需要知道执行了哪部分代码,那我们就能添加一个新的不同执行方式的子类而不需要更改调用它的方法。那么编译器在不确定该执行哪部分代码时是怎么做的呢?举个例子,下图的 BirdController 对象和通用 Bird 对象中,BirdController 不知道 Bird 的确切类型却还能一起工作。从 BirdController 的角度来看,这是很方便的,因为它不需要编写特别的代码来确定 Bird 对象的确切类型或行为。那么,在调用 move() 方法时是如何保证发生正确的行为(鹅走路、飞或游泳、企鹅走路或游泳)的呢?
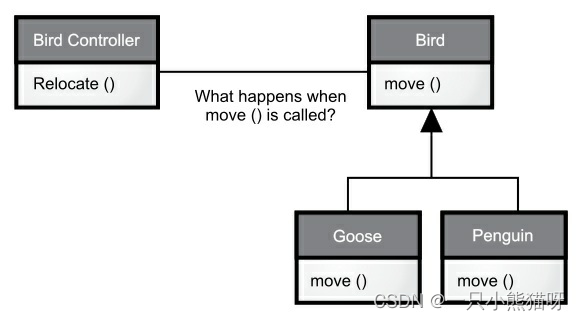
这个问题的答案,是面向对象程序设计的妙诀:在传统意义上,编译器不能进行函数调用。由非 OOP 编译器产生的函数调用会引起所谓的早期绑定,这个术语你可能从未听说过,不会想过其他的函数调用方式。这意味着编译器生成对特定函数名的调用,该调用会被解析为将执行的代码的绝对地址。
通过继承,程序直到运行时才能确定代码的地址,因此发送消息给对象时,还需要其他一些方案。为了解决这个问题,面向对象语言使用后期绑定的概念。当向对象发送信息时,被调用的代码直到运行时才确定。编译器确保方法存在,并对参数和返回值执行类型检查,但是它不知道要执行的确切代码。
为了执行后期绑定,Java 使用一个特殊的代码位来代替绝对调用。这段代码使用对象中存储的信息来计算方法主体的地址(此过程在多态性章节中有详细介绍)。因此,每个对象的行为根据特定代码位的内容而不同。当你向对象发送消息时,对象知道该如何处理这条消息。在某些语言中,必须显式地授予方法后期绑定属性的灵活性。例如,C++ 使用 virtual 关键字。在这些语言中,默认情况下方法不是动态绑定的。在 Java 中,动态绑定是默认行为,不需要额外的关键字来实现多态性。
为了演示多态性,我们编写了一段代码,它忽略了类型的具体细节,只与基类对话。该代码与具体类型信息分离,因此更易于编写和理解。而且,如果通过继承添加了一个新类型(例如,一个六边形),那么代码对于新类型的 Shape 就像对现有类型一样有效。因此,该程序是可扩展的。
代码示例:
void doSomething(Shape shape) {
shape.erase();
// ...
shape.draw();
}
此方法与任何 Shape 对话,因此它与所绘制和擦除的对象的具体类型无关。如果程序的其他部分使用 doSomething() 方法:
Circle circle = new Circle();
Triangle triangle = new Triangle();
Line line = new Line();
doSomething(circle);
doSomething(triangle);
doSomething(line);
可以看到无论传入的“形状”是什么,程序都正确的执行了。
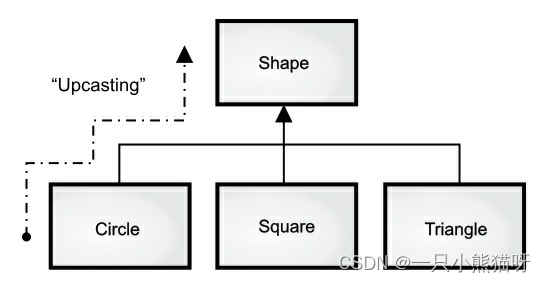
这是一个非常令人惊奇的编程技巧。分析下面这行代码:
doSomething(circle);
当预期接收 Shape 的方法被传入了 Circle,会发生什么。由于 Circle 也是一种 Shape,所
以 doSomething(circle) 能正确地执行。也就是说,doSomething() 能接收任意发送给 Shape 的消息。这是完全安全和合乎逻辑的事情。
这种把子类当成其基类来处理的过程叫做“向上转型”(upcasting)。在面向对象的编程里,经常利用这种方法来给程序解耦。再看下面的 doSomething() 代码示例:
shape.erase();
// ...
shape.draw();
我们可以看到程序并未这样表达:“如果你是一个 Circle ,就这样做;如果你是一个 Square,就那样做…”。若那样编写代码,就需检查 Shape 所有可能的类型,如圆、矩形等等。这显然是非常麻烦的,而且每次添加了一种新的 Shape 类型后,都要相应地进行修改。在这里,我们只需说:“你是一种几何形状,我知道你能删掉 erase() 和绘制 draw(),你自己去做吧,注意细节。”
尽管我们没作出任何特殊指示,程序的操作也是完全正确和恰当的。我们知道,为 Circle 调用draw() 时执行的代码与为一个 Square 或 Line 调用 draw() 时执行的代码是不同的。但在将 draw() 信息发给一个匿名 Shape 时,根据 Shape 句柄当时连接的实际类型,会相应地采取正确的操作。这非常神奇,因为当 Java 编译器为 doSomething() 编译代码时,它并不知道自己要操作的准确类型是什么。
尽管我们确实可以保证最终会为 Shape 调用 erase() 和 draw(),但并不能确定特定的 Circle,Square 或者 Line 调用什么。最后,程序执行的操作却依然是正确的,这是怎么做到的呢?
发送消息给对象时,如果程序不知道接收的具体类型是什么,但最终执行是正确的,这就是对象的“多态性”(Polymorphism)。面向对象的程序设计语言是通过“动态绑定”的方式来实现对象的多态性的。编译器和运行时系统会负责对所有细节的控制;我们只需知道要做什么,以及如何利用多态性来更好地设计程序。