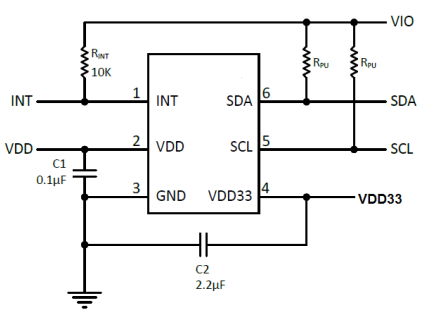
一、说明
在 Athelas,我们使用卷积神经网络 (CNN) 不仅仅是分类!在这篇文章中,我们将看到如何在图像实例分割中使用CNN,并取得很好的效果。
自从 Alex Krizhevsky、Geoff Hinton 和 Ilya Sutskever 在 2012 年赢得 ImageNet 以来,卷积神经网络 (CNN) 已成为图像分类的黄金标准。事实上,从那以后,CNN已经改进到现在在ImageNet挑战赛中胜过人类的程度!
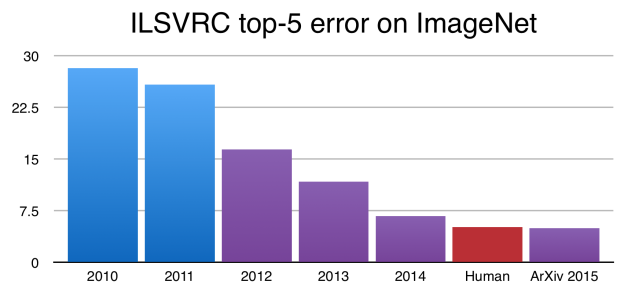
CNN现在在ImageNet挑战赛中的表现优于人类。上图中的 y 轴是 ImageNet 上的错误率。
虽然这些结果令人印象深刻,但图像分类比真正的人类视觉理解的复杂性和多样性要简单得多。

分类质询中使用的图像示例。请注意图像的构图良好且只有一个对象。
在分类中,通常有一个以单个对象为焦点的图像,任务是说出该图像是什么(见上文)。但是,当我们观察周围的世界时,我们执行的任务要复杂得多。

现实生活中的景象通常由许多不同的、重叠的物体、背景和动作组成。
我们看到具有多个重叠物体和不同背景的复杂景象,我们不仅对这些不同的物体进行分类,而且还确定它们的边界、差异和相互关系!

在图像分割中,我们的目标是对图像中的不同对象进行分类,并确定它们的边界。资料来源:Mask R-CNN论文。
CNN能帮助我们完成如此复杂的任务吗?也就是说,给定一个更复杂的图像,我们可以使用CNN来识别图像中的不同对象及其边界吗?正如罗斯·吉尔希克(Ross Girshick)和他的同行在过去几年中所看到的那样,答案肯定是肯定的。
二、本文的目标
通过这篇文章,我们将介绍对象检测和分割中使用的一些主要技术背后的直觉,并了解它们如何从一个实现演变到下一个实现。特别是,我们将介绍R-CNN(区域CNN),CNN在这个问题上的原始应用,以及它的后代Fast R-CNN和Faster R-CNN。最后,我们将介绍Mask R-CNN,这是Facebook Research最近发布的一篇论文,它扩展了这种对象检测技术以提供像素级分割。以下是本文引用的论文:
- R-CNN:https://arxiv.org/abs/1311.2524
- 快速 R-CNN:https://arxiv.org/abs/1504.08083
- 更快的 R-CNN:https://arxiv.org/abs/1506.01497
- Mask R-CNN: https://arxiv.org/abs/1703.06870
三、2014年:R-CNN - CNN在物体检测中的早期应用

R-CNN等目标检测算法接收图像并识别图像中主要对象的位置和分类。资料来源:https://arxiv.org/abs/1311.2524。
受到多伦多大学Hinton实验室研究的启发,加州大学伯克利分校的一个由Jitendra Malik教授领导的小团队问自己,今天似乎是一个不可避免的问题:
[Krizhevsky等人的结果]在多大程度上推广到目标检测?
对象检测是在图像中查找不同对象并对其进行分类的任务(如上图所示)。由Ross Girshick(我们将再次看到的名字),Jeff Donahue和Trevor Darrel组成的团队发现,这个问题可以通过Krizhevsky的结果来解决,方法是测试PASCAL VOC Challenge,这是一种类似于ImageNet的流行对象检测挑战。他们写道,
本文首次表明,与基于更简单的类似HOG特征的系统相比,CNN可以在PASCAL VOC上显着提高目标检测性能。
现在让我们花点时间了解一下他们的架构,即具有CNN的区域(R-CNN)是如何工作的。
3.1 了解 R-CNN
R-CNN的目标是获取图像,并正确识别图像中主要对象的位置(通过边界框)。
- 输入:图像
- 输出:图像中每个对象的边界框 + 标签。
但是我们如何找出这些边界框在哪里呢?R-CNN也做了我们直觉上可能做的事情 - 在图像中提出一堆框,看看它们中是否有任何实际对应于一个对象。

“选择性搜索”会浏览多个比例的窗口,并查找共享纹理、颜色或强度的相邻像素。图片来源:https://www.koen.me/research/pub/uijlings-ijcv2013-draft.pdf
R-CNN 使用称为选择性搜索的过程创建这些边界框或区域建议,您可以在此处阅读。在高级别上,选择性搜索(如上图所示)通过不同大小的窗口查看图像,并针对每种大小尝试按纹理、颜色或强度将相邻像素组合在一起以识别对象。

在创建一组区域提案后,R-CNN 将图像传递到 AlexNet 的修改版本,以确定它是否是有效的区域。资料来源:https://arxiv.org/abs/1311.2524。
创建提案后,R-CNN 将该区域扭曲为标准正方形大小,并将其传递给 AlexNet 的修改版本(启发了 R-CNN 的 ImageNet 2012 获奖提交),如上所示。
在CNN的最后一层,R-CNN添加了一个支持向量机(SVM),它简单地对这是否是一个对象进行分类,如果是的话,是什么对象。这是上图中的步骤 4。
3.2 改进边界框
现在,在盒子里找到物体后,我们可以拧紧盒子以适应物体的真实尺寸吗?我们可以,这是R-CNN的最后一步。R-CNN 对区域提案运行简单的线性回归,以生成更严格的边界框坐标以获得最终结果。以下是此回归模型的输入和输出:
- 输入:图像与对象对应的子区域。
- 输出:子区域中对象的新边界框坐标。
所以,总结一下,R-CNN只是以下步骤:
- 为边界框生成一组建议。
- 通过预先训练的 AlexNet 运行边界框中的图像,最后通过 SVM 运行边界框中的图像,以查看框中的图像是什么对象。
- 通过线性回归模型运行盒子,以便在对象分类后为盒子输出更紧密的坐标。
四、2015年:快速R-CNN - 加速和简化R-CNN

Ross Girshick撰写了R-CNN和Fast R-CNN。他继续在Facebook Research推动计算机视觉的界限。
R-CNN运行得很好,但由于几个简单的原因,它真的很慢:
- 它需要CNN(AlexNet)对每个图像的每个区域提案进行前向传递(每个图像大约2000个前向传递!
- 它必须分别训练三种不同的模型 - 用于生成图像特征的CNN,用于预测类的分类器,以及用于收紧边界框的回归模型。这使得管道极难训练。
2015年,R-CNN的第一作者Ross Girshick解决了这两个问题,导致了我们短暂历史中的第二个算法 - 快速R-CNN。现在让我们回顾一下它的主要见解。
4.1 快速 R-CNN 洞察 1:RoI(感兴趣区域)池化
对于CNN的前向传递,Girshick意识到对于每个图像,图像的许多建议区域总是重叠,导致我们一次又一次地运行相同的CNN计算(~2000次!他的见解很简单——为什么不对每张图像只运行一次CNN,然后找到一种方法在~2000个提案中共享该计算?
这正是Fast R-CNN使用一种称为RoIPool(感兴趣区域池)的技术所做的。RoIPool的核心是在其子区域之间共享CNN图像的正向传递。在上图中,请注意如何通过从 CNN 的特征图中选择相应的区域来获取每个区域的 CNN 特征。然后,对每个区域中的要素进行池化(通常使用最大池化)。因此,我们只需要一次原始图像,而不是~2000!
快速 R-CNN 洞察 2:将所有模型合并到一个网络中
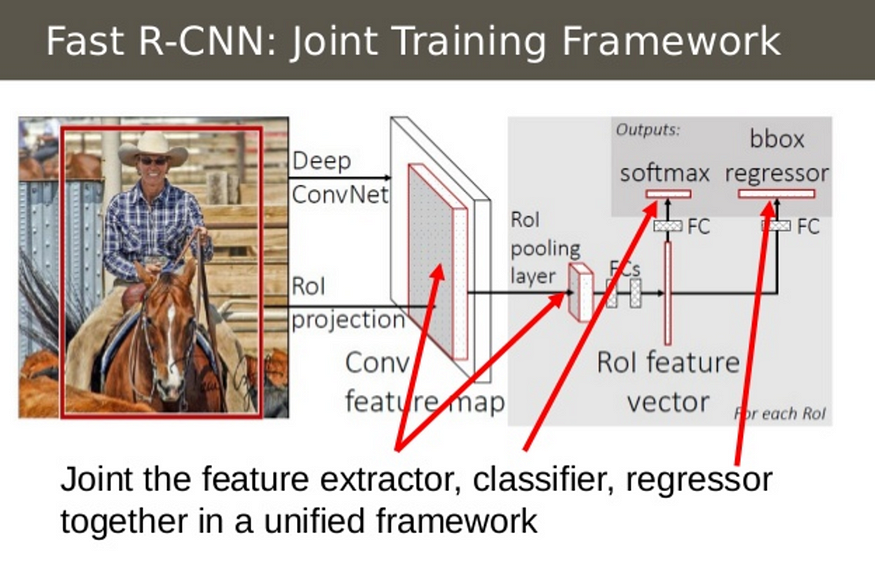
Fast R-CNN 将 CNN、分类器和边界框回归器组合成一个单一的网络。资料来源:https://www.slideshare.net/simplyinsimple/detection-52781995。
Fast R-CNN 的第二个见解是在单个模型中联合训练 CNN、分类器和边界框回归器。早些时候,我们有不同的模型来提取图像特征(CNN),分类(SVM)和收紧边界框(回归器),而Fast R-CNN则使用单个网络来计算这三者。
您可以在上图中看到这是如何完成的。Fast R-CNN用CNN顶部的softmax层取代了SVM分类器,以输出分类。它还添加了平行于 softmax 层的线性回归层,以输出边界框坐标。这样,所需的所有输出都来自一个网络!以下是此整体模型的输入和输出:
- 输入:带有区域建议的图像。
- 输出:每个区域的对象分类以及更严格的边界框。
五、2016年:更快的R-CNN - 加速区域提案
即使取得了所有这些进步,Fast R-CNN流程中仍然存在一个瓶颈 - 区域提议者。正如我们所看到的,检测对象位置的第一步是生成一堆潜在的边界框或感兴趣的区域进行测试。在Fast R-CNN中,这些提案是使用选择性搜索创建的,这是一个相当缓慢的过程,被发现是整个过程的瓶颈。

孙健是微软研究院首席研究员,领导了 Faster R-CNN 团队。资料来源:微软研究人员赢得 ImageNet 计算机视觉挑战 - 人工智能博客
2015 年中,微软研究院的一个由 Shaoqing Ren、Kaiming He、Ross Girshick 和jian Sun 组成的团队找到了一种方法,通过他们(创造性地)命名为 Faster R-CNN 的架构,使区域提议步骤几乎免费。
Faster R-CNN 的见解是,区域提议取决于已经通过 CNN 前向传播(分类的第一步)计算出的图像特征。那么为什么不将这些相同的 CNN 结果重复用于区域建议,而不是运行单独的选择性搜索算法呢?
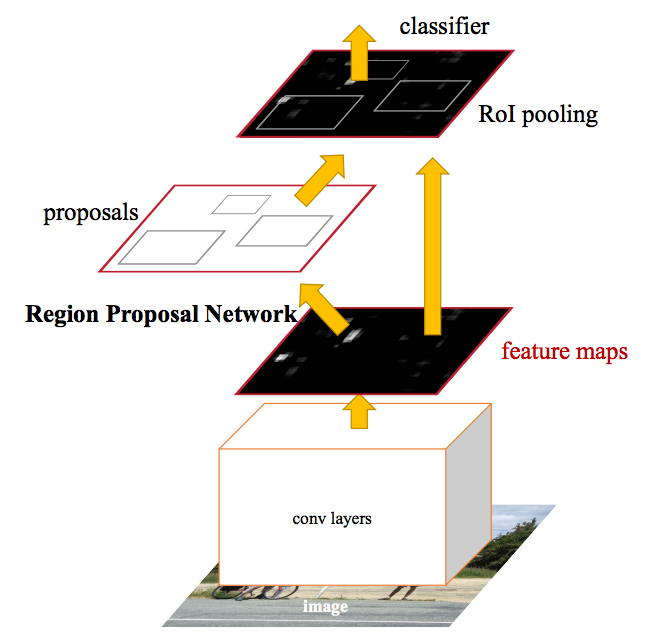
在 Faster R-CNN 中,单个 CNN 用于区域提议和分类。来源:https://arxiv.org/abs/1506.01497。
事实上,这正是 Faster R-CNN 团队所取得的成就。在上图中,您可以看到如何使用单个 CNN 来执行区域提议和分类。这样,只需要训练一个 CNN,我们几乎免费获得区域提案!作者写道:
以下是他们模型的输入和输出:
输入:图像(注意如何不需要区域提案)。
输出:图像中对象的分类和边界框坐标。
区域是如何生成的
让我们花点时间看看 Faster R-CNN 如何根据 CNN 特征生成这些区域建议。 Faster R-CNN 在 CNN 的功能之上添加了全卷积网络,创建了所谓的区域提议网络。

区域提议网络在 CNN 的功能上滑动一个窗口。在每个窗口位置,网络输出每个锚点的分数和边界框(因此 4k 框坐标,其中 k 是锚点的数量)。来源:https://arxiv.org/abs/1506.01497。
区域提议网络的工作原理是在 CNN 特征图上传递一个滑动窗口,并在每个窗口输出 k 个潜在边界框以及每个边界框的预期得分。这些 k 框代表什么?

我们知道,人们的边界框往往是矩形和垂直的。我们可以利用这种直觉来指导我们的区域提案网络创建此类维度的锚点。图片来源:http://vlm1.uta.edu/~athitsos/courses/cse6367_spring2011/assignments/assignment1/bbox0062.jpg。
直观上,我们知道图像中的对象应该符合某些常见的长宽比和尺寸。例如,我们知道我们想要一些类似于人类形状的矩形盒子。同样,我们知道我们不会看到很多非常非常薄的盒子。通过这种方式,我们创建了 k 个常见的长宽比,我们称之为锚框。对于每个这样的锚框,我们输出一个边界框和图像中每个位置的分数。
考虑到这些锚框,让我们看一下该区域提案网络的输入和输出:
输入:CNN 特征图。
输出:每个锚点的边界框。表示该边界框中的图像成为对象的可能性的分数。
然后,我们将每个可能是对象的边界框传递到 Fast R-CNN 中,以生成分类和收紧的边界框。
六、2017: Mask R-CNN - Extending Faster R-CNN for Pixel Level Segmentation

图像实例分割的目标是在像素级别识别场景中的不同对象是什么。来源:https://arxiv.org/abs/1703.06870。
到目前为止,我们已经了解了如何以多种有趣的方式使用 CNN 特征,通过边界框有效地定位图像中的不同对象。
我们是否可以扩展此类技术,进一步定位每个对象的精确像素,而不仅仅是边界框?这个问题被称为图像分割,是 Kaiming He 和包括 Girshick 在内的研究团队在 Facebook AI 中使用名为 Mask R-CNN 的架构进行探索的问题。

Kaiming He,Facebook AI 研究员,Mask R-CNN 的主要作者,也是 Faster R-CNN 的合著者。
与 Fast R-CNN 和 Faster R-CNN 非常相似,Mask R-CNN 的基本直觉是直接的。鉴于 Faster R-CNN 在目标检测方面表现出色,我们是否可以将其扩展为也执行像素级分割?
在Mask R-CNN中,在Faster R-CNN的CNN特征之上添加了全卷积网络(FCN)来生成掩模(分割输出)。请注意这与 Faster R-CNN 的分类和边界框回归网络是如何并行的。来源:https://arxiv.org/abs/1703.06870。
Mask R-CNN 通过向 Faster R-CNN 添加一个分支来实现此目的,该分支输出一个二进制掩码,表示给定像素是否是对象的一部分。与之前一样,分支(上图中白色)只是基于 CNN 特征图之上的全卷积网络。以下是其输入和输出:
输入:CNN 特征图。
输出:矩阵,其中像素属于对象的所有位置均为 1,其他位置均为 0(这称为二进制掩码)。
但 Mask R-CNN 的作者必须进行一个小调整才能使该管道按预期工作。
RoiAlign - 重新调整 RoIPool 使其更加准确
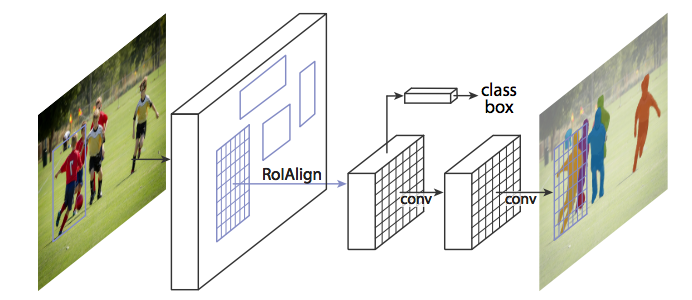
图像不是通过 RoIPool,而是通过 RoIAlign,以便 RoIPool 选择的特征图区域更精确地对应于原始图像的区域。这是必需的,因为像素级分割需要比边界框更细粒度的对齐。来源:https://arxiv.org/abs/1703.06870。
当在原始 Faster R-CNN 架构上未经修改地运行时,Mask R-CNN 作者意识到 RoIPool 选择的特征图区域与原始图像的区域略有偏差。由于图像分割需要像素级特异性,与边界框不同,这自然会导致不准确。
作者通过使用称为 RoIAlign 的方法巧妙地调整 RoIPool 使其更精确地对齐,从而解决了这个问题。

我们如何准确地将原始图像中的感兴趣区域映射到特征图上?
想象一下,我们有一个大小为 128x128 的图像和一个大小为 25x25 的特征图。假设我们想要与原始图像中左上角 15x15 像素对应的区域(见上文)。我们如何从特征图中选择这些像素?
我们知道原始图像中的每个像素对应于特征图中的~25/128像素。要从原始图像中选择 15 像素,我们只需选择 15 * 25/128 ~= 2.93 像素。
在 RoIPool 中,我们将将其四舍五入并选择 2 个像素,从而导致轻微的错位。但是,在 RoIAlign 中,我们避免了这种四舍五入。相反,我们使用双线性插值来精确了解像素 2.93 处的情况。在高层次上,这使我们能够避免由RoIPool引起的错位。
生成这些掩码后,Mask R-CNN 将它们与 Faster R-CNN 的分类和边界框相结合,以生成如此精确的分割:

掩模R-CNN能够分割和分类图像中的对象。资料来源:https://arxiv.org/abs/1703.06870。
七、相关代码
如果您有兴趣自己尝试这些算法,这里有相关的存储库:
更快的 R-CNN
- coffe:GitHub - rbgirshick/py-faster-rcnn: Faster R-CNN (Python implementation) -- see https://github.com/ShaoqingRen/faster_rcnn for the official MATLAB version
- PyTorch: GitHub - longcw/faster_rcnn_pytorch: Faster RCNN with PyTorch
- MatLab: GitHub - ShaoqingRen/faster_rcnn: Faster R-CNN
面具 R-CNN
- PyTorch: https://github.com/felixgwu/mask_rcnn_pytorch
- 张量流:GitHub - CharlesShang/FastMaskRCNN: Mask RCNN in TensorFlow
八、期待
在短短 3 年内,我们已经看到了研究界如何从 Krizhevsky 等人那里取得进步。al的原始结果到R-CNN,最后一直到像Mask R-CNN这样强大的结果。孤立地看,像Mask R-CNN这样的结果似乎是令人难以置信的天才飞跃,是无法接近的。然而,通过这篇文章,我希望你已经看到这些进步实际上是通过多年的辛勤工作和协作实现的直观、渐进式改进的总和。R-CNN,Fast R-CNN,Faster R-CNN和最后的Mask R-CNN提出的每个想法不一定是量子飞跃,但它们的总和产生了非常显着的结果,使我们更接近人类对视觉的理解。
特别让我兴奋的是,R-CNN和Mask R-CNN之间的时间只有三年!有了持续的资金、关注和支持,计算机视觉在未来三年内还能进步多少?