目录
JVM 中的内存区域划分
JVM 的类加载机制
1. 加载
2. 验证
3. 准备
4. 解析
5. 初始化
JVM 中的垃圾回收策略
找,确认垃圾
1. 引用计数
2. 可达行分析
释放”垃圾“对象
1. 标记清除
2. 复制算法
3. 标记整理
分代算法
JVM也就是我们俗称的八股文,作为一个普通的程序员工作中是基本不可能用到的;因为它设计的初衷就是为了让程序员能够比较简单的,感知不到系统层面的一些内容(很多时候,程序员只关注业务逻辑,不需要关注底层实现细节)。
数年前开始,JVM成为了Java程序猿必考的内容。
JVM里的内容非常多,大部分内容咱叶看不懂,JVM本来是写给C/C++ 程序员看的,它的底层实现都是 C/C++ 的代码,研究JVM 的也都是那一批人。
我们这里针对JVM的面试题,作出以下一些讨论。
本篇主要在于以下三点:
- JVM 中的内存区域划分
- JVM 的类加载机制
- JVM 中的垃圾回收策略
本章比的不是你了解多少,比的是你能背下来多少
JVM 中的内存区域划分
JVM 其实是一个 Java 进程, Java 进程 会从操作系统中申请一大块内存区域,给 java代码使用
而这一大块内存区域,就有我们之前 SE 阶段提到的:栈区、堆区、方法区(新版的也叫 元数据区)。
内存区域划分最最核心的部分:
- 堆区: new 出来的对象(成员变量)
- 栈区: 维护方法之间的调用关系(局部变量)
- 方法区/元数据区: 放的是类加载之后的类对象(静态变量)
一般这里的考点就是 给你一段代码,问你某个变量在哪个区。
我们主要就是看这个变量是个什么变量(局部变量,成员变量【注意被 final 修饰过的局部变量】,静态变量)
这里简单举个例子:
void func() {
Test t = new Test();
}
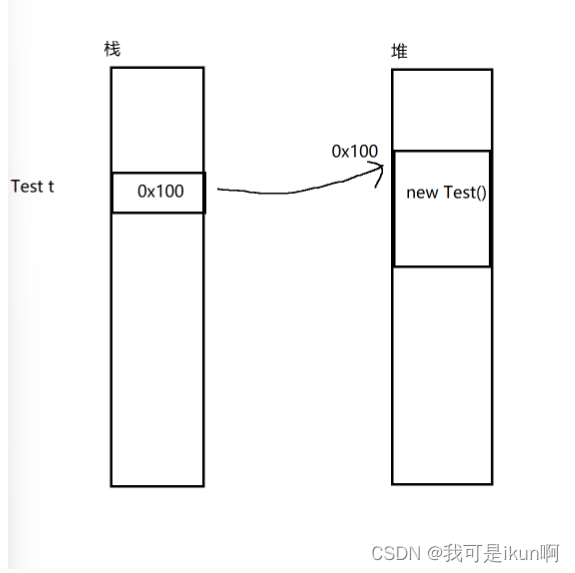
这里的 t 对象是个引用类型,t是个局部变量,所以是在栈上的的,而 new Test(),这个对象本体是在堆上的。至于func() 这个方法是存在方法区的,方法在内存中都是以二进制的方式存储的。
我们来看一张更细节的图:
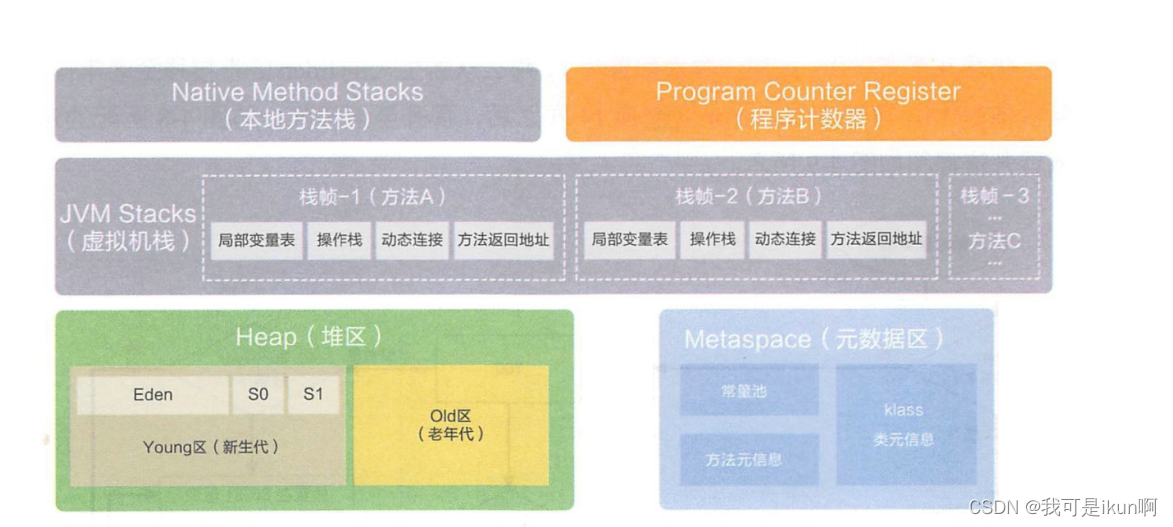
我们在SE 阶段认识的在做细分 。
其中将栈区分为 本地方法栈 和 虚拟机栈 。
这两个栈也很好区分:
- 虚拟机栈,是给 Java 代码使用的
- 本地方法栈,是个JVM 内部的本地方法使用的,我们说 JVM 源码都是 C++ 实现的(可以简单理解为是给 C++ 使用的)
程序计数器
这个程序计数器是用来记录当前程序指令到了哪一个指令了。
上述的 堆区 和 元数据区 在一个 JVM 进程中只有一份。
而栈(本地方法栈和 虚拟机栈)和 程序计数器 是存在多份的,每一个 线程 都存在一份
JVM 的类加载机制
类加载其实就是 把 .class 文件,加载到内存中,得到 类对象 这个过程。
咱们 祖师爷(冯诺依曼)提出:程序运行,就需要把依赖的"指令和数据" 加载到内存中。
这个类加载的过程非常复杂(一般不需要我们理解)
在 《深入理解 Java虚拟机(第三版)》这本书中,将类加载总结成了 5 个词 (必备)

类加载的声明周期如下:
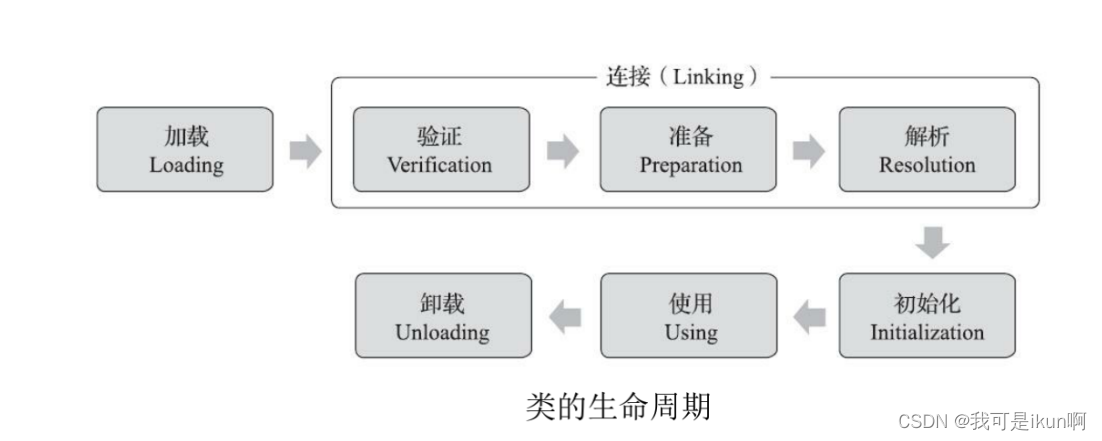
1. 加载
加载其实就是找到 .class 文件,并且读取文件内容
这里涉及到一个非常经典的考点,双亲委派模型,这个等到类加载的最后来讲;
2. 验证
.class 文件有明确的数据格式(二进制的)

源码中 都有一个 ClassFile 来体现一个类有哪些信息
3. 准备
给类对象 分配内存空间(这里还没有走到 初始化阶段,所以这里的内存空间都是全 0 的)
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段。
比如此时有这样一行代码:
public static int value = 123;
它是初始化 value 的 int 值为 0,而非 123。
4. 解析
解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程
这里涉及到 将 符号引用 替换为 直接引用 的过程
我们先来说说符号引用
符号引用就是 字符串常量,我们在 验证 阶段不是加载好了 .class 文件嘛,.class 文件存在了 字符串常量,我们这里就能直到它的相对位置(偏移量),但是并不知道它的实际位置。
这个时候的字符串常量就是 符号引用。
直接引用
当真正加载到内存中,就会把字符串常量填充到内存中的特定地址上;
字符串常量之间的相对位置还是一样的,但是这些字符串有了自己真正的内存地址,此时的字符串就是直接引用。
5. 初始化
其实 4 和 5 可以并做一步,但是人家作者规定了 将其分为两步。
解析是初始化了 字符串常量,而这一步是 初始化 对象【除字符串常量部分】(初始化静态成员,执行静态代码块、如果类存在父类,还需要加载父类)
ok,到这里 上述 五步 也就讲完了。
类加载这个步骤,啥时候会触发呢?
并非 jvm 一启动,就会把所有的 .class 都加载了,整体采纳了 (懒汉设计模式)的策略,非必要不加载。
啥叫必要
- 创建了这个类的实例
- 使用了这个类的静态 方法/属性
- 使用了这个类的子类
总之就是与这个类相关的类、属性、方法、实例化对象...
这里还有一个最关键的考点:双亲委派模型
这个模型所做的就是 加载这个步骤中,找一个 .class 文件这个过程
事实上,这个模型并非是类加载中一个很重要的步骤,但是是个非常重要的考点
JVM 中,加载类,需要用到一组特殊的模块:类加载器
在 JVM 中,内置了三个类加载器
BootStrap ClassLoader 负责加载 Java标准库中的类
Extension ClassLoader 负责加载一些非标准的类,但是 是sun/Oracle 扩展的库的类
Application ClassLoader 负责加载项目中自己写的类,以及第三方库 中的类
当具体加载一个类的时候,其过程如下: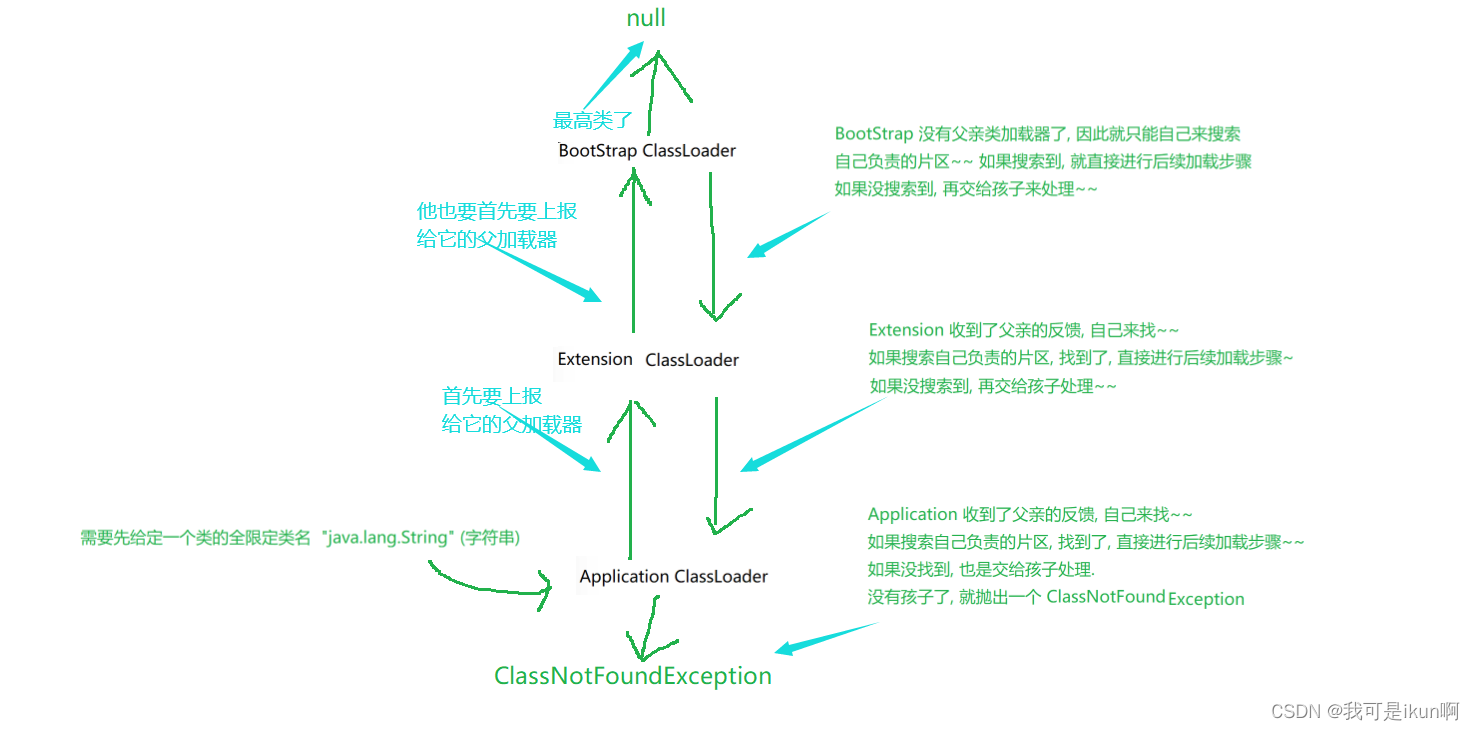
双亲?上面明明就一个 null ,哪里来的双亲?
这个就是个翻译问题,parent 表示双亲中的一个,我们翻译为双亲罢了。
这个双亲委派模型也是可以打破的,自己实现的类加载器,是否遵守上述规则,看个人设计。
JVM 中的垃圾回收策略
垃圾回收机制 也可以叫 GC 回收机制
这个可以帮助程序员自动释放内存
在 C语言中,malloc 需要手动 free,否则就会出现内存泄漏(光申请,不释放,内存用完了,程序也就完了)
Java 等后继编程语言,都采用了 GC 来解决上述问题,能够有限减少内存泄漏出现的概率。
内存的泄露是个比较纠结的问题:
申请的时机是明确的 => 使用到了必须申请;
释放的时机是模糊的 => 彻底不使用了才能释放
啥叫彻底不使用了:没有引用指向它
JVM 中的内存有好几个区,我们要释放的就是 堆 (new 出来的)
我们也来随手聊聊其他区的释放:
- 程序计数器,就是个单纯存地址的整数,不要了就直接随着线程一起销毁。
- 栈,也是随着线程一起销毁的,方法调用完毕,方法的局部变量自然随着出栈的操作销毁了。
- 元数据区/方法区,村的类对象,很少会“卸载”。
- 堆,是GC的主要目标,GC也是以对象为单位进行释放的(说是释放内存,本质就是释放对象)
GC 中主要分为两个阶段:
- 找,谁是垃圾
- 释放,将垃圾对象释放掉
上述两个阶段,主要是了解清楚垃圾回收的算法,这些算法 并不代表 JVM真实的实现方法,现在的JVM 在这些基本算法之上又做出了很多细节的调整和优化。
找,确认垃圾
什么是垃圾,后续不会再使用到的,就是垃圾,Java中使用一个对象,只能通过引用,如果一个对象没了引用就可以确定它是垃圾了。
Java中只是单纯的通过引用没有指向这个操作,来判定垃圾。
单纯的通过引用可能会照成 垃圾释放不及时,但这都是小事;就怕释放太快,将还有引用的对象释放掉,这是大事。
具体来说说,Java怎么样直到一个对象是否还有引用呢?
1. 引用计数
给对象安排一个而外的的空间,保存一个整数,表示该对象有几个引用
(事实上,Java并没有采用这个方案,反倒是 python和PHP采用了)
借助图片来看看:
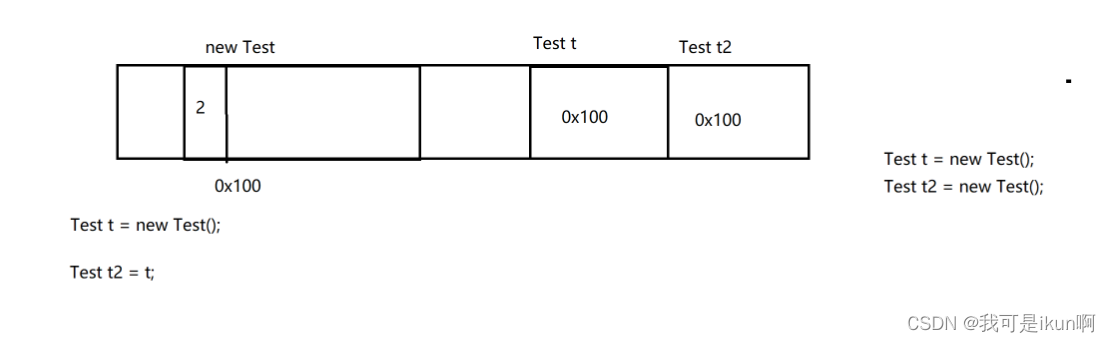
随着引用的增加,计数器就增加,引用的销毁计数器就销毁。
当,计数器为0,就认为没有了引用,于是就是垃圾了
每个计数器都开辟一个空间, 上述之开辟一个空间,是因为都是同一类型 Test,我要是有其他类型,例如Cat 那么还需要开辟一个空间。
因此,这种方法会出现两个问题:
- 对象类型过多,那么就会非常浪费空间
- 存在循环引用的情况,那么就会导致引用计数的判定的逻辑出错
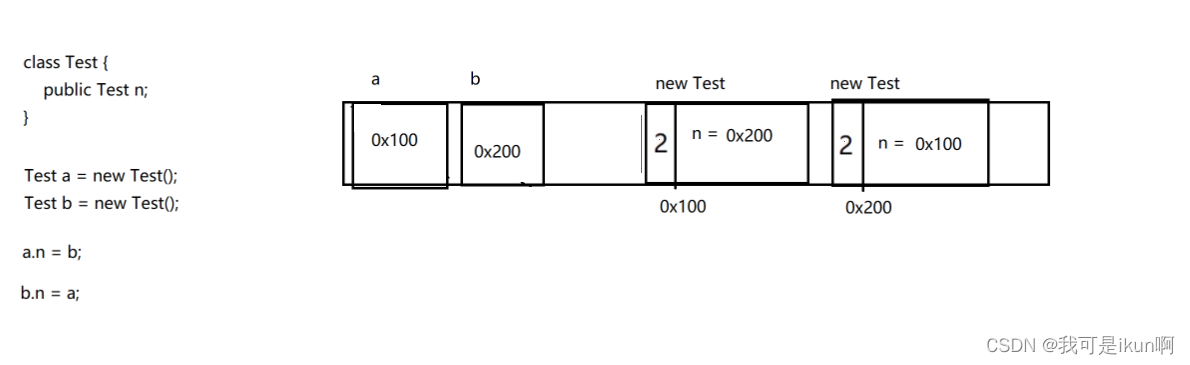
假设,由上述这个栗子,此时,a 和 b 销毁了,这个时候,两个对象的引用计数各自减 1 :
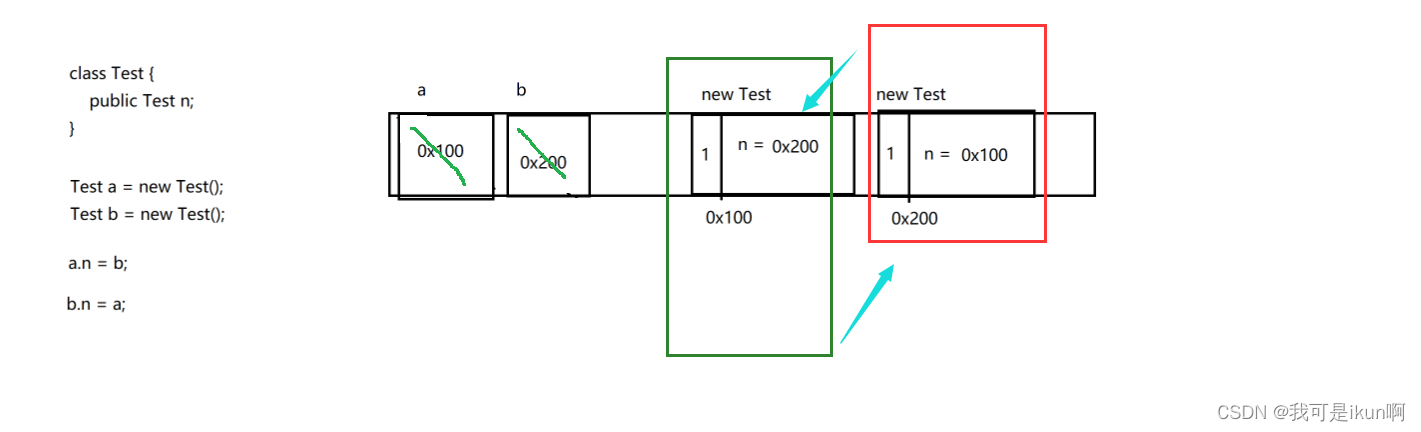 此时,这两个引用计数还在相互引用,并不是 0 ,所以不能作为垃圾,但是这个两个对象都不可以再使用 。
此时,这两个引用计数还在相互引用,并不是 0 ,所以不能作为垃圾,但是这个两个对象都不可以再使用 。
2. 可达行分析
可达行分析将对象之间的引用关系,理解成了一棵树形结构,从一些特殊的起点出发,进行遍历,只要能遍历访问到的对象,就是“可达的“,其余”不可达“ 的就作为垃圾处理掉。
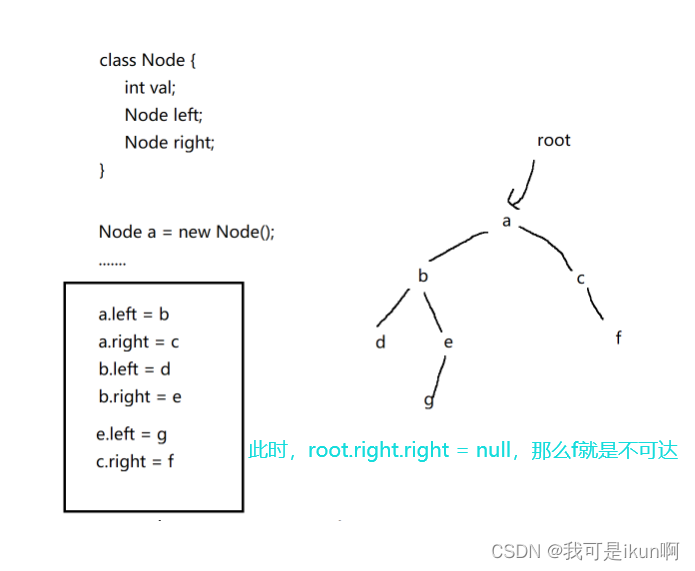
此时,通过 root 这个引用,就可以访问到整个树的任意结点,通过上述方式,root就能引用到所有结点。
如果这里的 e 突然为 null ,g是否就是不可达呢?
不对,既是e 为 null 了,还会存在其他指向指向g,g 任然是可达的。
可达性分析关键要点,进行上述遍历,需要有”起点“
- 栈上的局部变量(每个栈的每个局部变量,都是起点)
- 常量池中的引用的对象
- 方法区中,静态成员引用的对象
可达性分析,总的来说,就是从所有的 gcroots 的起点触发,看看该对象里又通过引用能访问哪些对象,顺腾摸瓜,把所有可以访问的对象都遍历一遍(遍历的同时把对象标记成为”可达“)
可达性分析,克服了引用计数的两个缺点,但是它也存在自身的问题
- 这个树有高度,搜易搜索会消耗更多的时间,因此某个对象成为垃圾,不一定能够第一时间发现,扫描会消耗时间
- 再进行可达性分析的时候,要顺着树进行搜索,一旦这个过程中,当前代码出现了变化,就更复杂了
因此,为了更准确的完成这个 扫描过程,还需要其他业务暂停工作(STW问题)
所谓的 STW 也就是 stop the world ; 这个是可达性分析最最被诟病的问题,Java发展了这么多年,垃圾回收这个也在不断的更新优化,STW 这个问题,现在以及能够比较好的应对了,但是并不能完全消除,已经可以让 STW 的时间大大缩短了。
上述已经解决了理论的找垃圾了,接下来就是释放垃圾
释放”垃圾“对象
三种典型的 策略
1. 标记清除
"标记-清除"算法是最基础的收集算法。算法分为"标记"和"清除"两个阶段 : 首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象:
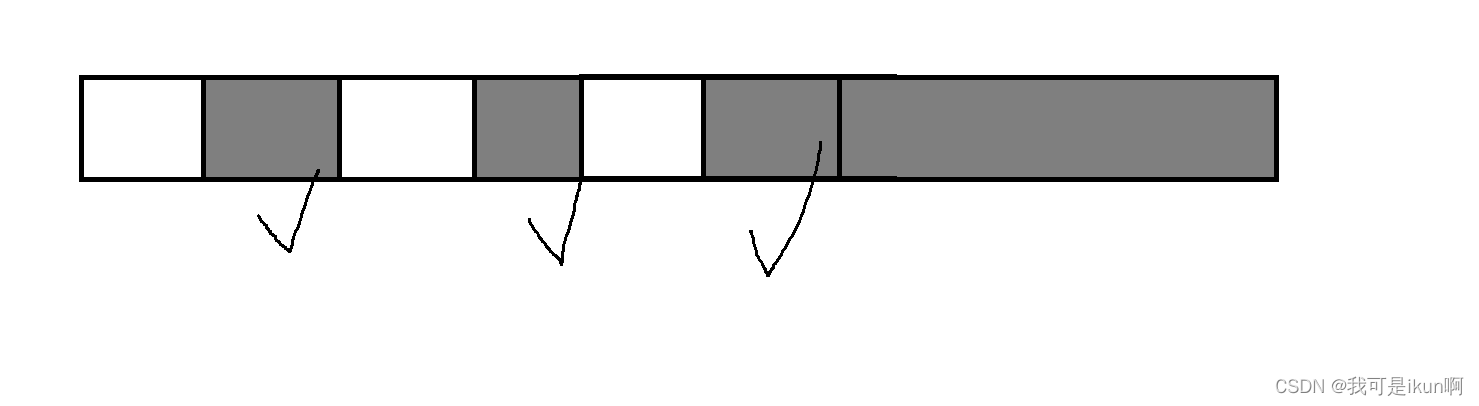
如图所示, 画了勾的就是我们需要释放的;
我们这块空间很难被重复利用,我们申请的”整块的连续的空间“现在这里空闲的空间都是离散的,有自己独立的空间。
总的空闲的空间 可能超过 1个 G,但是你想申请 500M 都不一定能够申请到(因为他们都是散的)。
"标记-清除"算法的不足主要有两个 :
- 效率问题 : 标记和清除这两个过程的效率都不高
- 空间问题 : 标记清除后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配较大对象时,无法找到足够连续内存而不得不提前触发另一次垃圾收集
2. 复制算法
我们把整个内存空间,分为两段,一次只使用一半:
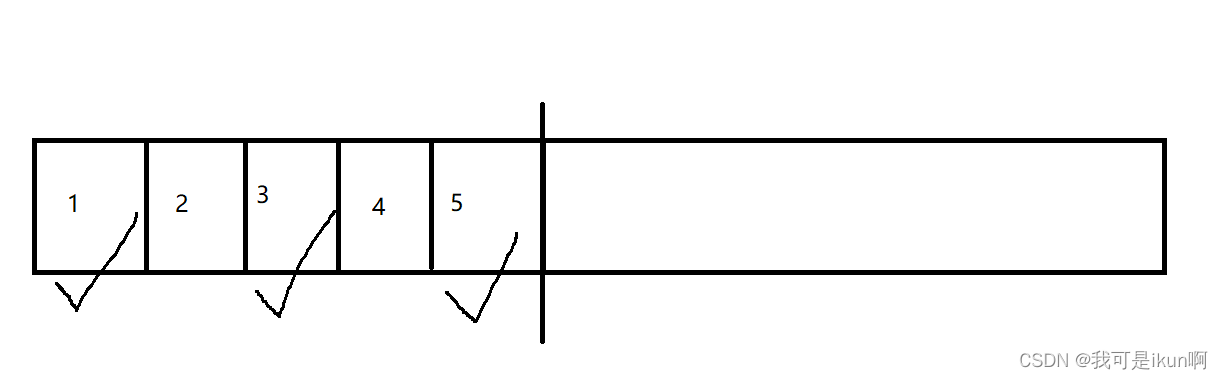
还是一样,花了勾的属于垃圾;
我们将不属于垃圾的复制到另一半空间中去,剩下的全部释放掉:

复制算法虽然解决了内存碎片的问题,但是也存在相关的缺点:
- 内存利用率低
- 如果当前的对象大部分都是要保留的,垃圾很少,此时复制成本很高
3. 标记整理
类似于顺序表删除中间的元素:
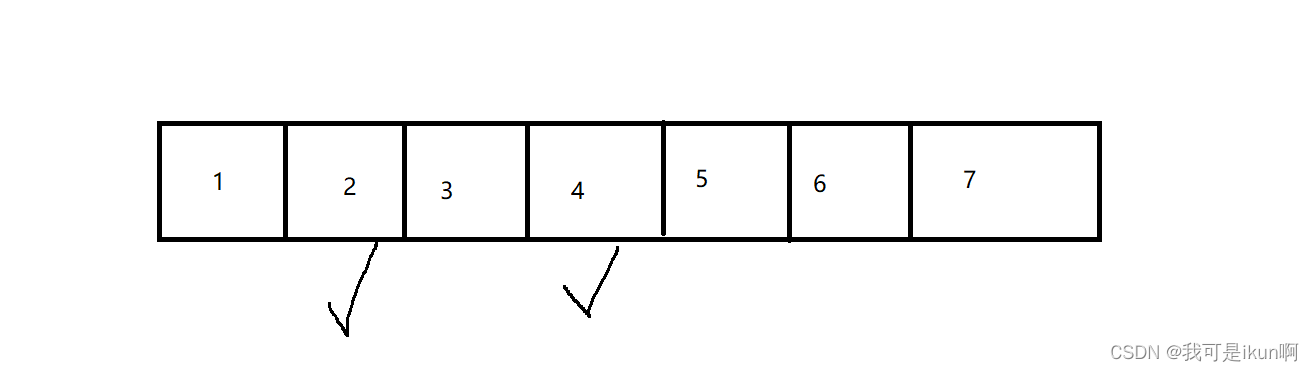
我们将 有效元素往前搬
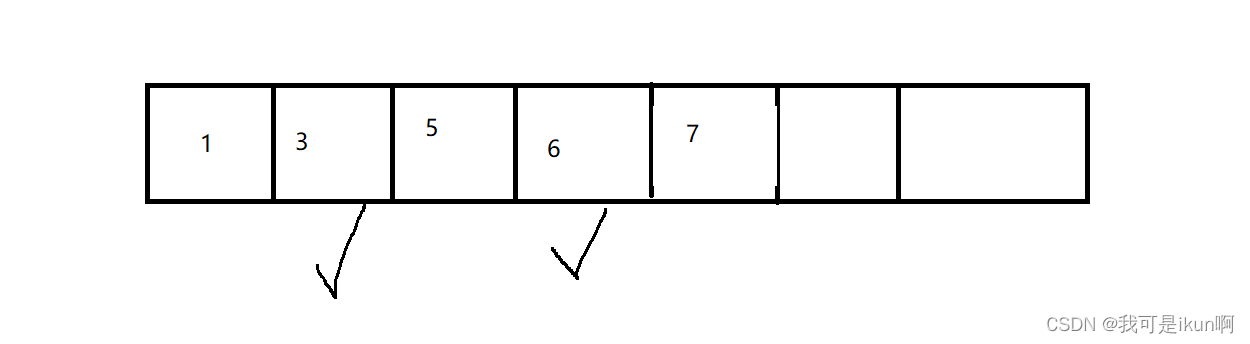
随后将搬运处的空间释放
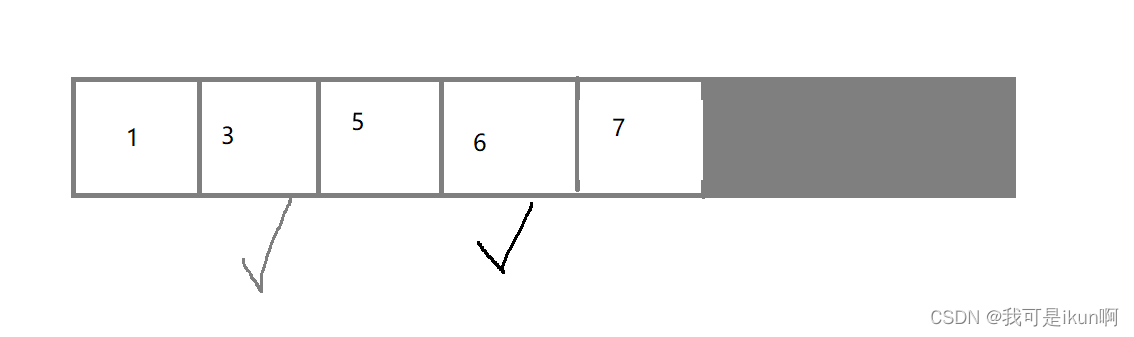 该算法虽然解决了内存碎片问题,但还存在一些问题:
该算法虽然解决了内存碎片问题,但还存在一些问题:
- 搬运的开销比较大
事实上, JVM 的实现思路,是上述集中的结合,针对不同情况下取长补短:
分代算法
基本思想:给每个对象设置”年龄“ ,这个概念,描述对象存在多久了,如果是一个对象刚刚诞生,认为是 0 岁,经过每一轮扫描(可达性分析),没被标记成垃圾,就长大一岁
通过描述年龄来表示对象存活时间
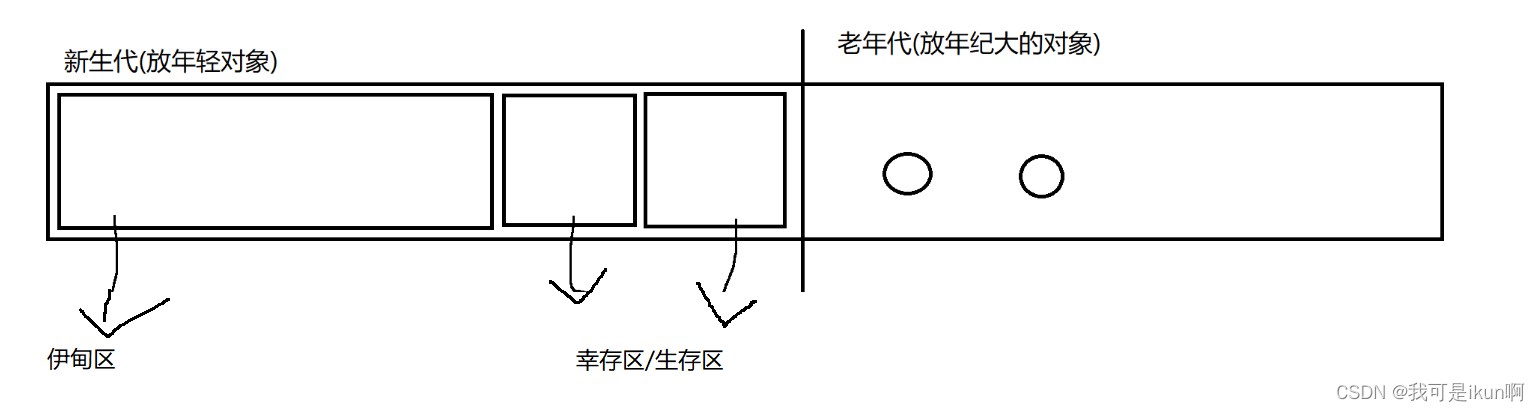
算法执行步骤:
- 1. 新创建的对象,放到伊甸区,当垃圾回收扫描到伊甸区之后,绝大部分对象都会在第一轮 GC 中被干掉
- 如果伊甸区的对象,熬过第一轮,通过复制算法,拷贝到生存区,生存去分为两半,一次只是用一半,垃圾回收扫描伊甸区的对象,也是发现垃圾就淘汰,不是垃圾就复制到另一半
- 当这个对象熬过多轮,年龄增长到一定程度,通过复制算法拷贝到老年代
- 进入老年代,年龄都挺大了,再消亡的概率小于前面的新生代,针对老年代的 gc 扫描概率小很多,如果发现老年代某个对象是垃圾,使用标记整理的方式清楚
- 特殊情况:某个对象很大,直接存放到老年代,因为这个对象搬运起来的开销很大,不适合多次搬运
这些都只是基本思想,具体的实现再这些基础之上,还做出了很多改进和优化;
Java的版本在变,垃圾回收器也会不断变化。
本篇的八股就到这里,校招应该不会考那么多八股文,一定要把这些背下来!!!!!


![[Error] invalid preprocessing directive #inclued问题解决](https://img-blog.csdnimg.cn/d328c9f84bc04f0fb7bf08592f17bb06.png)
![[QT编程系列-6]:C++图形用户界面编程,QT框架快速入门培训 - 3- QT窗体设计 - 自定义菜单栏](https://img-blog.csdnimg.cn/db2ac7ca1a2740c9aa5930fc4dde752c.png)