目录
前言:
1.插入数据
2.查询数据
2.1全列查询
2.2指定查询
2.3别名
2.4去重
2.5排序
2.6条件查询
2.7聚合查询
2.7.1group by语句
2.7.2havin语句
2.8联合查询
2.8.1内连接
2.8.2外连接
2.8.3自连接
2.8.4子查询
3.修改
4.删除
前言:
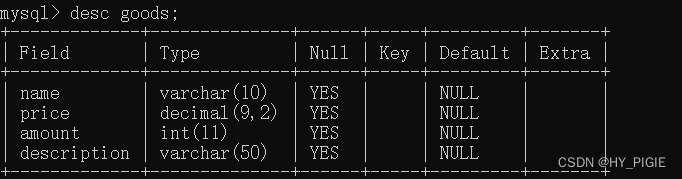
本次大多数使用案例中使用到的表格的结构为:
1.插入数据
insert into table_name (column1,column2......) valus(... , ... , ....),(... , ... , ....);
使用案例
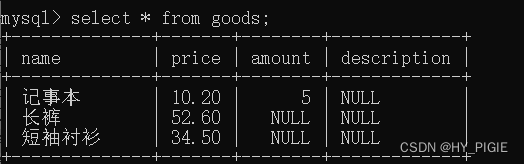
单行数据+全列插入(表中的每一个列都插入相应的数据)
insert into goods values ('记事本',10.2,5,null);
//本条语句往goods表中根据表中的每一个列,插入一行数据多行数据+指定列插入(选定表中的指定列进行插入)
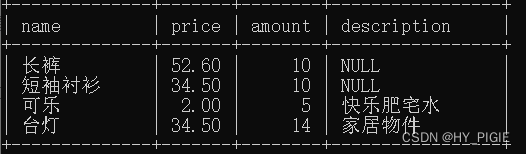
insert into goods (name,price) values ('长裤',52.6),('短袖衬衫',34.5);
//本条语句,只往goods表中的特定列(name,price)中,插入两行数据结果展示:
2.查询数据
2.1全列查询
select * from table_name;
全列查询,使用*代替表中的每一个列,即本语句可以查询出所查表中的所有数据
(在1.1的使用案例中,最后一张图有所展示)
2.2指定查询
select column1,column2,... from table_name;
指定查询,即只查询所需的表的特定列
使用示例
select name price from goods;
//本语句只查询goods表中的name列与price列,并按指定顺序展示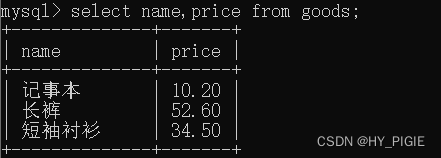
2.3别名
select column [as] alias_name [...] from table_name;
为查询结果中的列指定别名,表示返回的结果集中,以别名作为该列的名称
使用示例
select name as 物品名称,price as 价格 from goods;
//本语句中,查询goods表中的name列并命其别名为物品名称,price列命其别名为价格 
2.4去重
select distince .... ....
作用为:将查询出的某一列的数据进行去重操作
使用案例:
表内数据更新为如下

去重前:

去重后:

明显的可见,查询出的结果被进行了去重操作
2.5排序
select column... from table_name
order by cloumn [asc/desc]; //asc为升序排列,desc为降序排列,默认即不写时为asc
将查询出的数据根据某一列的数据进行升序/降序进行排列
使用示例
select name,price from goods
order by price;
//本语句为将goods表中查询出的name列与price列数据按price列数据升序进行排序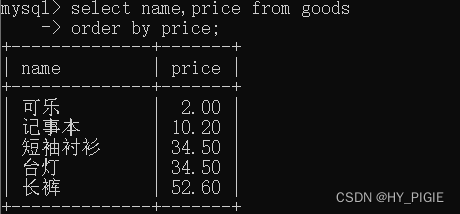
select name,price,amount from goods
order by price desc ,amount;
//查询name,price与amount数据,按price降序与amount升序进行展示
2.6条件查询
2.6.1比较运算符:
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字 符 |
逻辑运算符:
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
使用示例:
select name,price,amount from goods where price > 20 and amount > 3;
//本语句 查询goods表中name,price,amount的数据,且为price>20,amount>3的数据
select name,price,amount from goods where price between 30 and 60;
//本语句为,查询name,price与amount的数据,且满足price的范围在[30,60];- between 30 and 60 等价于 price >= 30 and price <= 60;

select name ,price from goods where price in (2,10.2,999);
//本语句查询goods表中name,price的数据,且满足price的数据在(2,10.2,999)集合中- in (2,10.2,999) 等价于 price = 2 or price = 10.2 or price = 999;

select name from goods where name like '%袖%';
//本语句使用模糊查询,查询name中含有'袖'的数据
select name from goods where name like '_袖_';
//本语句使用模糊查询,查询name中为'某袖某'的数据,即满足条件的数据为三个字,且袖在中间
//如,满足条件的可能为'长袖套'(三个字,且袖在中间)在模糊查询中'%'匹配多个字符,包括0个字符,而'_'严格的任意的1个字符

select name ,amount from goods where amount is null;
//查询amount为空的数据
select name ,amount from goods where amount is not null;
//查询amount不为空的数据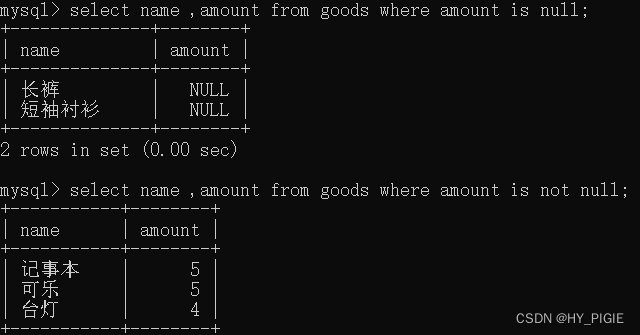
select * from goods limit 2 offset 0;
//本语句为查询goods的所有数据,并使用分页查询,每一页只有2行数据,并展示第1页
select * from goods limit 2 offset 2;
//使用分页查询,每一页只有2行数据,并展示第2页
select * from goods limit 2 offset 4;
//使用分页查询,每一页只有2行数据,并展示第3页 
2.7聚合查询
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
使用示例:
select count(name) from goods;
//本语句计算goods表中的name列有多少行数据 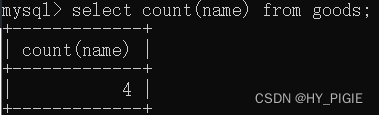
select sum(amount) from goods;
//本语句计算goods表中的amount列中的数据总数 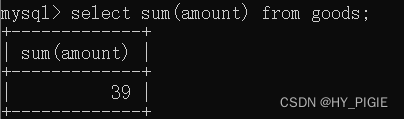
select avg(price) from goods;
//本语句查询goods表中的price列的数据的均值 
select max(price) from goods;
//本语句查询goods表中的price的数据的最大值
2.7.1group by语句
select column1, sum(column2), .. from table group by column1,column3;
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
使用示例:
本次group by与having举例使用的表如下,
select role,avg(salary) from emp group by role;
//本语句查询emp表中,先按role列分组再求出每一个role的平均salary数据 
2.7.2havin语句
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where 语句,而需要用having
使用示例:
本示例使用的表格与2.8中的相同
select role,avg(salary) from emp group by role having avg(salary)<= 2500;
//本语句查询emp表,每一个职业平均salary小于等于2500的数据
2.8联合查询
本次联合查询所用到的表格
book表:

borrow表:
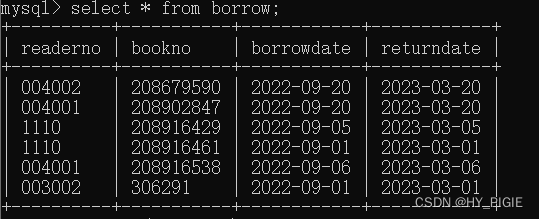
reader表:

2.8.1内连接
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
所查询到的数据为,在两个表中,满足条件的数据.
使用示例:
想要知道每一个学生接了什么书,从一个表中不能直接得知,就需要通过内连接进行查询.
select reader.readerno,readername,book.bookno,book.bookname
from reader ,book,borrow
where borrow.readerno = reader.readerno and borrow.bookno = book.bookno;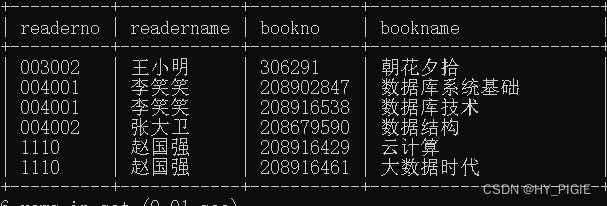
2.8.2外连接
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
左连接
查询的是每一个同学的借书情况,就算同学不借书,也会完整的展示reader表
select reader.readerno,readername,book.bookno,bookname
from reader left join borrow on reader.readerno = borrow.readerno
left join book on book.bookno = borrow.bookno; 
右连接
查询的是每一本书的被借情况,就算书没有被借也会完整的展示book表
select reader.readerno,readername,book.bookno,bookname
from reader right join borrow on reader.readerno = borrow.readerno
right join book on book.bookno = borrow.bookno; 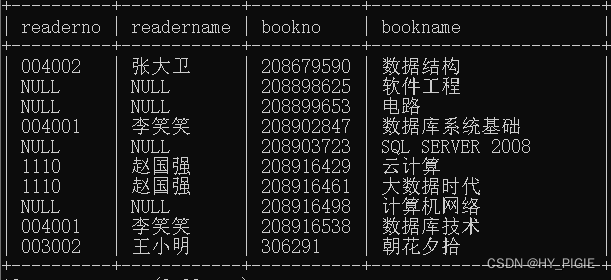
2.8.3自连接
自连接是指在同一张表连接自身进行查询,当我们要比较的数据在不同行但同一列的情况时,我们可以考虑自连接来查询
使用示例:

查询score表中course_id = 3的score > course_id = 1的score的student
select * from score as s1,score as s2
where s1.student_id = s2.student_id and
s1.course_id = 1 and
s2.course_id = 3 and
s1.score < s2.score;
2.8.4子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
使用示例:
查询与王小明同一群体的借书情况(即查询学生中有多少人借了多少书)
select reader.readerno,readername
from borrow,reader
where borrow.readerno = reader.readerno and
readertype = (select readertype from reader where readername = '王小明');
3.修改
update table_name set colmun1 = value1,colmun2 = value2 [where...] [order by...] [limit...]
将某个表中的某条数据更新为
使用示例:
update goods set amount = 10 order by amount limit 3;
//本语句将goods表中amount中升序排列的前3行数据的amoun更新为10; 
4.删除
delete from table_name [where...] [order by...] [limit...];
delete from goods where name = '记事本';
//本语句在goods表中删除一行name为'记事本'的数据