文章目录
- C++异常
- C语言传统的错误处理方式
- C++错误处理方式
- 异常的使用方法
- 异常的使用规范
- 异常安全问题
- 异常规范
- 自定义异常体系
- STL中的异常体系
- 异常的优缺点
C++异常
C语言传统的错误处理方式
-
终止程序,如
assert直接断言报错,缺陷:非常麻烦,如果发生内存错误,除零错误会立即终止程序 -
返回错误码。缺陷:需要程序员自己去查渣哦对应的错误,如系统库的接口函数都是通过错误码放到errno中,需要程序员自己去读区错误码进行错误处理
-
C标准库中的setjmp和longjmp组合(不常用)
实际上C语言基本都是使用返回错误码来处理错误,部分情况下使用终止程序处理非常严重的错误
C++错误处理方式
C++可以使用异常来对错误进行处理,异常是面向对象语言常用的错误处理方式,当一个函数发现自己出现无法处理的错误的时候就可以抛出异常,让该函数的直接或间接调用者处理这个错误
- throw : 当程序出现错误,可以通过throw关键字抛出一个异常
- try : try块中防治当是可能抛出异常的代码,该代码块在执行时会进行异常错误检测,try块后面通常会多跟一个catch块
- catch : 如果try中发生错误,那么就会跳到对应的catch块执行对应的代码
try {
// 可能出错的代码
}
catch (ExceptionName e1) {
// catch 块1
}
catch (ExceptionName e2) {
// catch 块2
}
// 每一个catch块对应一种错误
不同的catch块对应一种不同的错误
异常的使用方法
异常抛出和捕获的匹配原则
1、异常是通过抛出对象引发的,该对象类型决定应该被哪一个catch模块捕获(有点像函数重载🤔️),如果抛出的异常对象没有被捕获,或是没有匹配类型的捕获,那么这个程序会终止报错
2、被选中的处理代码(catch块)时调用链中与该对象类型匹配且距离抛出异常位置最近的那个
3、抛出异常对象后,会生成一个异常对象的拷贝,因为抛出的异常对象可能是一个临时对象,所以会生成一个拷贝对象,这个拷贝对象的临时对象会在catch后被销毁(类似函数的传值返回)
4、catch(…)可以捕获任意类型的异常,但是捕获后无法知道异常错误是什么
5、实际上异常的抛出和捕获的匹配原则有一个例外,捕获和抛出的异常类型并不一定要完全匹配,可以抛出派生类对象,使用基类对象进行捕获,这个在实际生产中使用的很多
函数调用链中异常展开的匹配规则
1、当异常被抛出后,首先会检查throw是否在try块内部,如果在则查找匹配的catch语句,如果有匹配的,就跳到catch地方进行处理
2、如果当前函数栈没有匹配的catch则会退出当前的函数栈,返回上一个函数调用栈进行匹配catch。找到匹配的字句进行处理后,会沿着catch字句后面继续执行,不会再回到原来抛出异常的地方
3、如果到达main函数的栈仍然没有找到匹配的catch,则会终止程序
void func3() {
throw string("异常来了");
}
void func2() {
try{
func3();
} catch (const string& s) { // 捕获string类型的异常
cout << "func2 catch :" << s << endl;
throw int(1);
}
}
void func1() { func2(); }
int main() {
try{
func1();
} catch (const string& s) { // 用于捕获string类型的异常
cout << "出错啦 : " << s << endl;
} catch (...) { // 用于捕获非string类型的异常
cout << "出现未知错误" << endl;
}
cout << "main 函数结束了" << endl;
return 0;
}
可以看到func1,func2,func3依次被调用,在func3中抛出了一个异常,但是func3中并没有try块,也没有捕获程序,就会退回上一个函数调用栈(func)中查找,可以看到func3()是在try块中的,第一个步骤,检查throw是否在try内部成立,接下来查找匹配的throw字句
然后查看func2内部的catch块类型(因为其是最近的),发现类型是匹配的,就捕获了这个异常,然后又抛出了一个int类型的异常,最终在main函数处被捕获。被捕获后继续执行后续代码
这个沿用调用链查找匹配catch字句的过程称为栈展开,实际过程中最后都要加上一个catch(…)捕获任意类型的异常,否则异常没有被捕获,程序就会被终止
异常的使用规范
有时候单个catch不能完全处理一个异常,在进行一些矫正处理后,希望将异常再交给更外层的调用链函数进行处理,比如最外层可能需要拿到异常进行日志信息的记录,这就要重新抛出异常递交给更上层的函数处理
void func2() {
throw string("这是个异常");
}
void func1() {
int* arr = new int[10];
func2();
delete[] arr;
}
int main() {
try {
func1();
} catch(const string& s) {
cout << "捕获字符串异常:" << s << endl;
} catch(...) {
cout << "捕获未知异常" << endl;
}
return 0;
}
可以看到这段代码有一点小问题,在函数func1中,使用new在堆上开辟了一块四十字节的空间,之后调用func2函数,func2函数抛出异常被main函数的catch块捕获,然后执行后续代码,main函数结束
可以看到,从始至终,我们在堆上开辟的arr空间并没有被delete,造成了内存泄漏
void func1() {
int* arr = new int[10];
try{
func2();
} catch (const string& s) {
delete[] arr;
cout << "func 2 get a 异常" << endl;
string func2_exception = "func2" + s;
throw string(func2_exception);
}
}
对代码进行简单修改,可以看到我们将delete[] arr的操作放在了func1函数的catch块中,成功对func1函数遗留下的问题进行处理,然后将异常再次抛出
如果这个异常需要加入这个函数的信息,我们可以重新构建异常信息,如果不需要我们可以直接一下结构进行抛出
try {
func2();
} catch (...) { // 捕获任意类型异常
delete[] arr;
throw; // 直接抛出让外层处理
}
异常安全问题
由抛异常导致的安全问题叫做异常安全问题,对于异常安全问题下面有几点建议
1、构造函数完成对象构造和初始化,最好不要在构造函数中抛出异常,否则可能导致对象不完整,没有完整出实话,析构函数同理
2、C++中异常经常会出现资源泄漏的问题,如在new和delete之间的代码抛出异常,导致内存泄漏,在lock和unlock之间抛出异常会导致死锁,C++中使用RALL的方式来解决该问题
异常规范
为了能让函数使用者知道某个函数会抛出哪一些异常,C++标准规定:
1、在函数后面接throw(type1, type2, …) 列出这个函数可能抛出的所有异常类型,便于检查理解
2、在函数后面接throw() 或 noexcept(C++11),标识该函数不会抛出异常
3、异常接口声明不是强制的
void func()1 throw(A, B, C, D); // 可能抛出A,B,C,D类型的异常
void func()2 throw(std::bad_alloc); //只会抛出bad_alloc类型的异常
void func()3 throw(); // 不会抛出异常
自定义异常体系
实际上很多公司都会自定义自己的异常体系进行规范异常处理
- 公司的项目一般会进行模块划分,不同程序猿小组完成不同模块,如果不对异常进行规范,那么负责外层捕获异常的程序猿就很难受了,内部函数抛出的异常类型千奇百怪,都要一一捕获。如果不进行统一很容易出现错误
- 实际开发场景中,都会定义一套集成的规范异常体系,先定义一个最基础的基异常类,所有人抛出的异常都必须是继承于该异常类的派生类,异常语法规定可以用基类捕获派生类对象,因此最外层只需要捕获基类就可以了
最基础的异常类至少包括错误编号和错误描述两个成员变量,甚至还可以包含当前函数栈帧的调用链等信息。该异常一般还会提供两个成员函数用于获取错误编号和错误描述
class MyException{
public:
MyException(int _err_id, const string& _err_msg)
: err_id(_err_id), err_msg(_err_msg)
{}
int GetErrid() const { return err_id; }
virtual string what() const { return err_msg; }
private:
int err_id; // 错误编号
string err_msg; // 错误描述
};
如果其他模块想要对异常类进行扩展,必须要继承这个基础的异常类,可以在派生类中按需添加成员变量,或者对继承的what函数进行重写,使其能告诉程序猿更多异常信息
class SqlException : public MyException {
public:
SqlException(int _err_id, const char* _err_msg, const char* _err_sql)
: MyException(_err_id, _err_msg)
, err_sql(_err_sql) {}
virtual string what(){
string msg = "CacheException: ";
msg += err_msg;
msg += "sql 语句:";
msg += err_sql;
return msg;
}
protected:
std::string err_sql;
};
注意一下:继承体系中成员变量一般都不用私有,不然在子类中不可见。基类Exception中的what函数可以定义成虚函数,方便自类重写,赋予其更强大的效果
STL中的异常体系
C++标准库中的异常也是一个基础的异常体系,其中exception就是异常基类,我们可以在程序中使用这些标准异常
int main() {
try {
vector<int> v(10, 5);
// 这里如果系统内存不够了就会抛异常
v.reserve(100000000000000);
// 这里越界也会抛异常
v.at(10) = 100;
} catch (const exception& e) {
cout << e.what() << endl; // std::bad_alloc
} catch (...) {
cout << "Unknow Exception" << endl;
}
return 0;
}
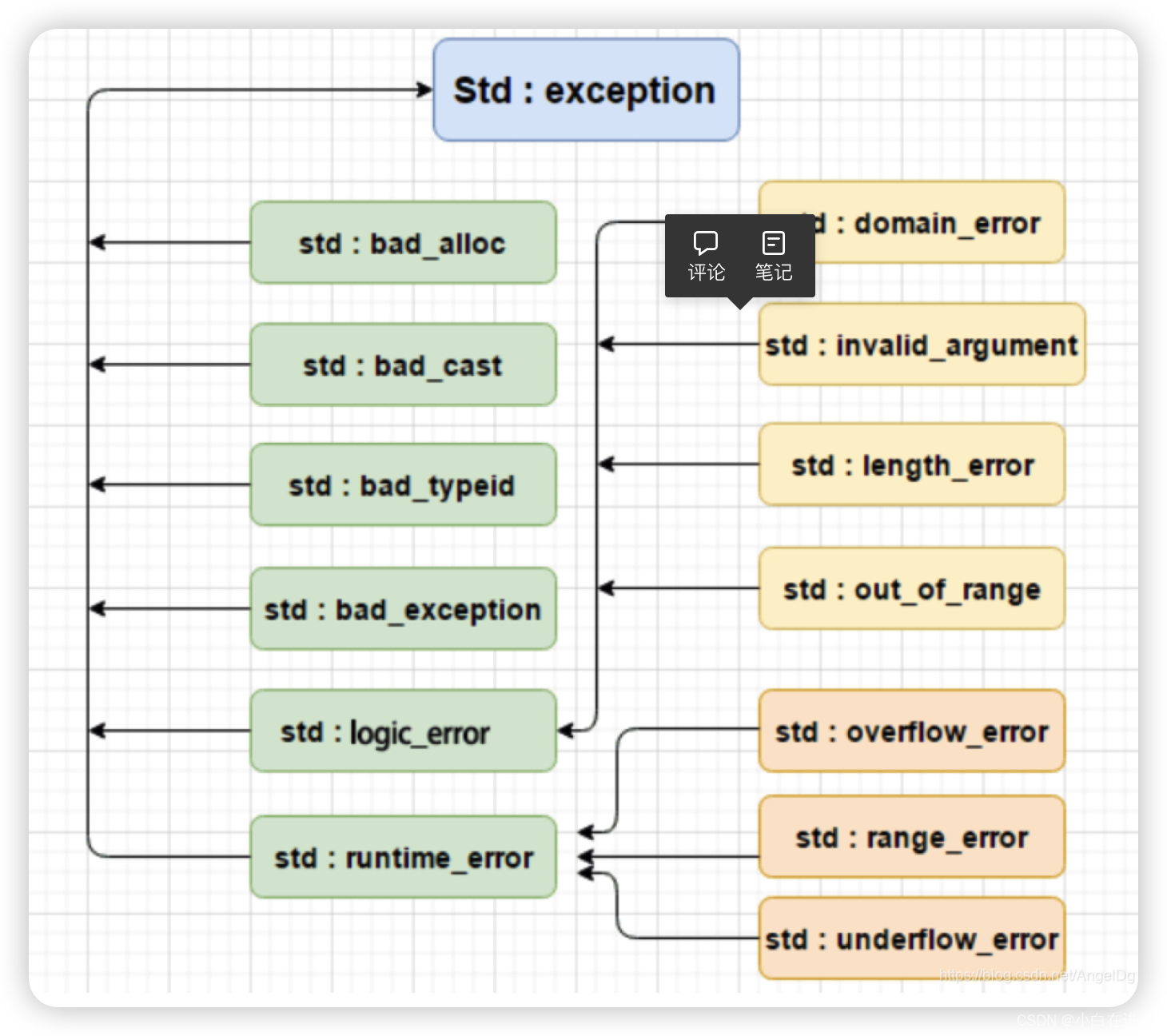
- exceptino类的what成员函数和西沟函数都定义成了虚函数,方便字类对其进行重写,从而达到多态的效果
- 日常开发我们也可以继承exception来实现我们自己的异常类,实际上公司都有自己的一套异常体系
异常的优缺点
C++异常的优点:
1、异常对象定义好了,相比于错误码的方式可以更加清晰准确的展示错误的各种信息,甚至可以包含堆栈调用信息,这样可以帮助更好的定位程序bug
2、返回错误码的传统方式有个很大的问题就是,在函数调用链中,深层的函数返回了错误,那么我们层层返回错误在最外层才可以拿到错误
3、很多第三方库也都包含异常,如boost、gtest、gmock等等常用的哭,那么我们使用它们也要用到异常
4、很多测试框架都使用异常,这样可以更好的使用单元测试等进行白盒测试
5、部分函数的使用异常更好处理,比如构造函数没有返回值,不方便使用错误码处理,比如T& operator这样的函数,如果pos越界了就只能使用异常或者终止程序,没有办法通过返回值表示错误
C++异常的缺点
1、异常会导致程序执行流乱跳,并且非常混乱,运行时出错抛异常就会乱跳。导致我们跟踪分析程序时会很困难
2、C++没有垃圾回收机制,资源需要自己管理,有了异常非常容易内存泄漏,出现死锁等异常安全问题
3、C++标准库的异常体系定义的不好,导致大家各自定义各自的异常体系,非常的混乱
4、异常尽量规范使用,否则后果不堪设想,随意抛异常,外层用户苦不堪言。所以异常规范有两点 一、抛出的异常都必须继承于一个基类 二、函数是否抛异常,抛什么异常需要使用throw(), noexcept的方式进行规范