0 前言
DTS是数据传输平台(Data Transfer Platform的缩写)
随着得物App的用户流量增长,业务选择的数据库越来越多样化,异构数据源之间的数据同步需求也逐渐增多。为了控制成本并更好地支持业务发展,我们决定自建DTS平台。本文主要从技术选型、能力支持与演化的角度出发,分享了在DTS平台升级过程中获得的经验,并提供一些参考。
1 技术选型
DTS的主要目标是支持不同类型的数据源之间的数据交互,包括关系型数据库(RDBMS)、NoSQL数据库、OLAP等,同时整合了数据库配置管理、数据订阅、数据同步、数据迁移、DRC双活数据同步支持、数据巡检、监控报警、统一权限等多个模块,以构建安全、可扩展、高可用的数据架构平台。
1.1 能力对比

1.2 DTS 1.0 - 以 canal/otter/datax 作为执行引擎
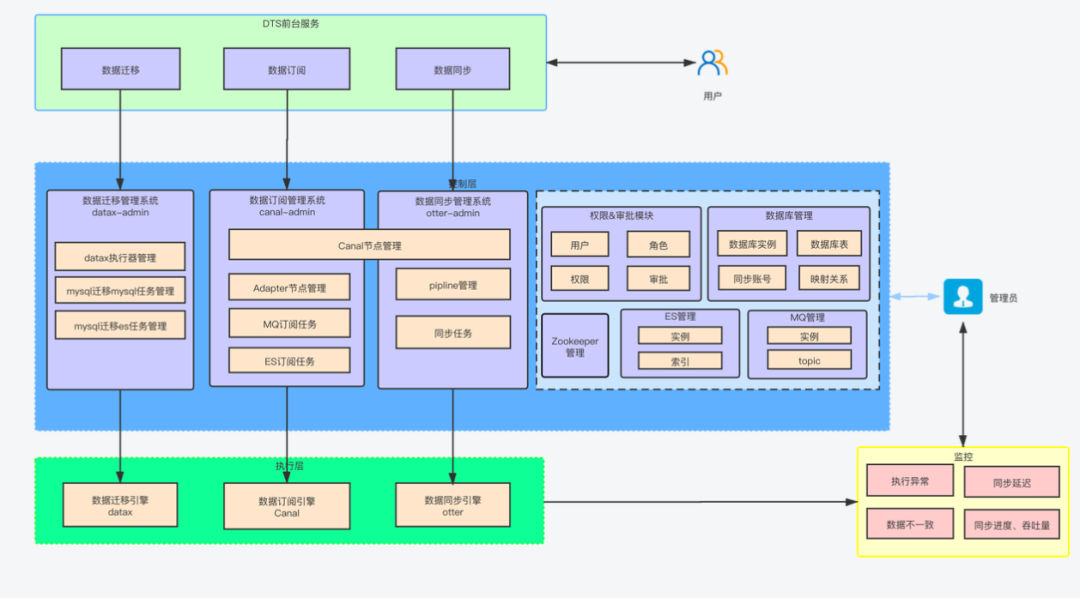
1.3 为什么要切换到Flink?
为了支持多种读端数据源和写端数据源,需要一个统一数据处理框架,以减少重复组件和提高开发效率。同时数据源类型和组件的维护难度与复杂度呈线性增长,现有的组件需要统一维护到一个项目中。
Canal和Otter等组件的社区活跃度低,很长时间没有得到维护更新。因此,需要选择一个新的、活跃的框架。此外,现有组件也无法有效支持全量+增量一体化的操作。
因此,使用一个统一的数据处理框架,能够同时支持多种读端数据源和写端数据源,以及全量+增量一体化的功能,是必要的。这样能够降低组件的维护难度和复杂度,提高开发效率。
通过DTS 2.0,我们希望将canal/otter/datax演化为一个任务执行框架+管理平台,能够为后续大量数据源迭代提速。
1.4 DTS 2.0 以Flink作为执行引擎
现有的开发流程:
- 统一的任务执行框架,集成flink并引入connectors根据配置组装出具体的DTS任务
- 维护并研发新的 connector
当我们需要支持新的数据源, 首先将数据源相关插件维护在connector中,接着在执行框架中引入需要的组件,其中存在大量的可复用的功能,这样就做到了connector及功能组件复用的效果。
2 DTS 现有能力
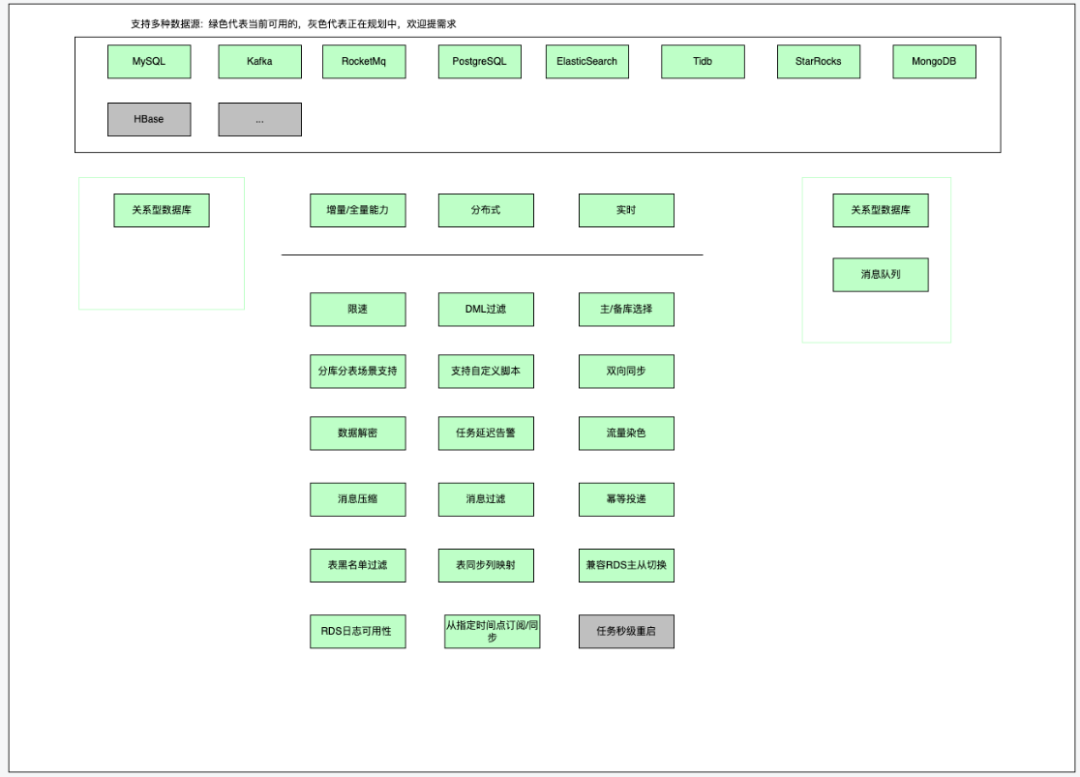
3 我们做了什么?
3.1 DTS Connectors框架 - 数据源支持提速
在Flink CDC基础上实现的全量/增量任务同步框架,基本的架构如下
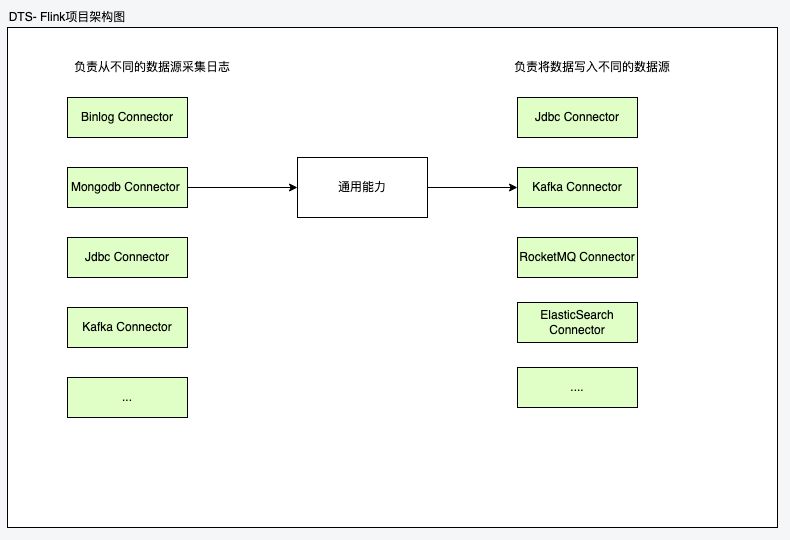
其中Connector中分别实现了Flink提供的SourceFunction和SinkFunction函数,分别负责从读端读取数据,往写端写入数据,因此一个Connector可同时存在于上游或者下游。
任务的启动流程:
a. 任务的Main函数如下所示, 根据如下的Json文件加载到对应的Connector中的SourceFactory或者SinkFactory来构造对应的DataStream。
DataStream是Flink中提供的数据流操作类
public class Main { public static void main(String[] args) throws Exception {
// 解析参数 ParameterTool parameterTool = ParameterTool.fromArgs(args); String[] parsedArgs = parseArgs(parameterTool);
Options options = new OptionParser(parsedArgs).getOptions(); options.setJobName(options.getJobName());
// 执行任务 StreamExecutionEnvironment environment = EnvFactory.createStreamExecutionEnvironment(options); exeJob(environment, options); }
任务Json配置:
{ "job":{ "content":{ "reader":{ "name":"binlogreader", "parameter":{ "accessKey":"", "binlogOssApiUrl":"", "delayBetweenRestartAttempts":2000, "fetchSize":1, "instanceId":"", "rdsPlatform":"", "restartAttempts":5, "secretKey":"", "serverTimezone":"", "splitSize":1024, "startupMode":"LATEST_OFFSET" } }, "writer":{ "name":"jdbcwriter", "parameter":{ "batchSize":10000, "concurrentWrite":true, ], "dryRun":false, "dumpCommitData":false, "errorRecord":0, "flushIntervalMills":30000, "poolSize":10, "retries":3, "smallBatchSize":200 } } },
}}
b. 我们提供了两个抽象工厂类,SourceFactory, SinkFactory, 其中的createSource, createSink便是子工厂需要实现的方法,不同的数据源实现不同。
public abstract class SourceFactory<T> { public abstract DataStream<T> createSource();}public abstract class SinkFactory<T> { public abstract void createSink(DataStream<T> rowData) throws Exception;}
c. 接下来,我们只需要实现对应的子工厂方法就可以了
public class BinlogSourceFactory extends AbstractJdbcSourceFactory { @Override public DataStream<TableRowData> createSource() {
List<String> tables = this.binlogSourceConf.getConnection().getTable(); Set<String> databaseList = new HashSet<>(2);
// 使用对应的Connector构建DataStream }}
d. 通用能力函数:RateLimitFunction, BinlogPositionFunction 其中分别实现了对应的任务能力,例如限流,任务位点保存等。
public class RateLimiterMapFunction<T> extends RichMapFunction<T, T> {
private transient FlinkConnectorRateLimiter rateLimiter;
@Override public T map(T value) throws Exception { if (rateLimiterEnabled) { rateLimiter.acquire(1); } return value; }
当任务所需的函数都创建完成后,任务就真正开始运行了。
收益:
3.2 RDS日志获取
DTS通过提供增量和全量同步能力为业务提供数据同步功能,但在增量订阅/同步任务执行过程中,可能会遇到一些异常情况。其中,以下三种情况需要特别处理:
- Binlog可用性
云厂商的数据库实例本地binlog有效期8小时,过期部分进行OSS备份。MySQL业务高峰期或者DDL变产生大量的binlog, DTS任务尝试获取过期数据失败,任务因此中断。因此,DTS支持了本地binlog+OSS备份binlog的获取及切换,保障日志可用性。
- 数据库 实例主从切换
RDS经常会发生主备节点切换,在切换的过程中要保证数据不丢。由于切换前后两个数据库实例 Binlog 文件一般都是不一致的,此时任务位点记录方式是 BinlogPosition 模式,则在切换之后任务需要自动进行 Binlog 对齐操作,进而保证数据的完整性。将新数据实例上的位点查询时间戳提前1-2分钟即可。
- 读实例订阅支持
DTS任务binlog dump连接数过多造成主库压力及影响DDL变更,因此需要支持读库订阅。云厂商的读库不提供备份,在读库日志过期时需要切换到主库进行读取。
3.3 全量增量一体化功能
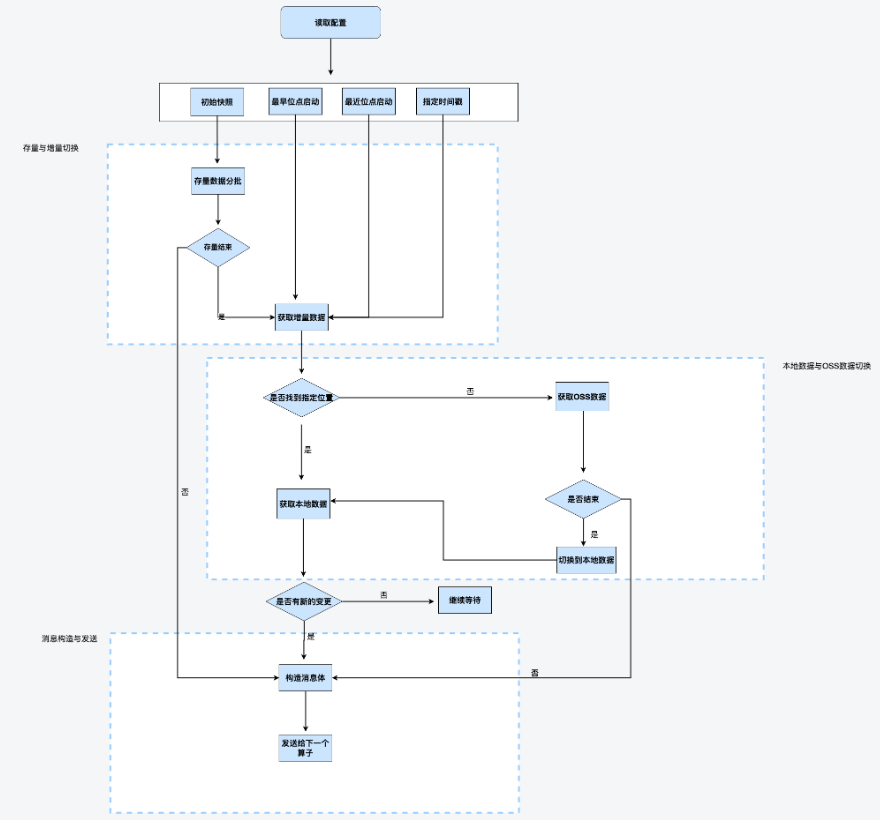
全量增量一体化是指先同步存量数据,待存量结束之后再开始同步增量数据。其中也加入了增量阶段的OSS备份日志获取。但存量阶段依然存在一些问题,需要进一步改造优化。
3.4 数据源接入- starrocks, postgres等
支持从mysql同步到starrocks和postgres, 在任务执行框架的基础上,只需要开发starrocks-connector, postgres connector支持对应的数据源即可。其中的其他能力,像多表同步、分库分表等场景都可以达到复用的效果。
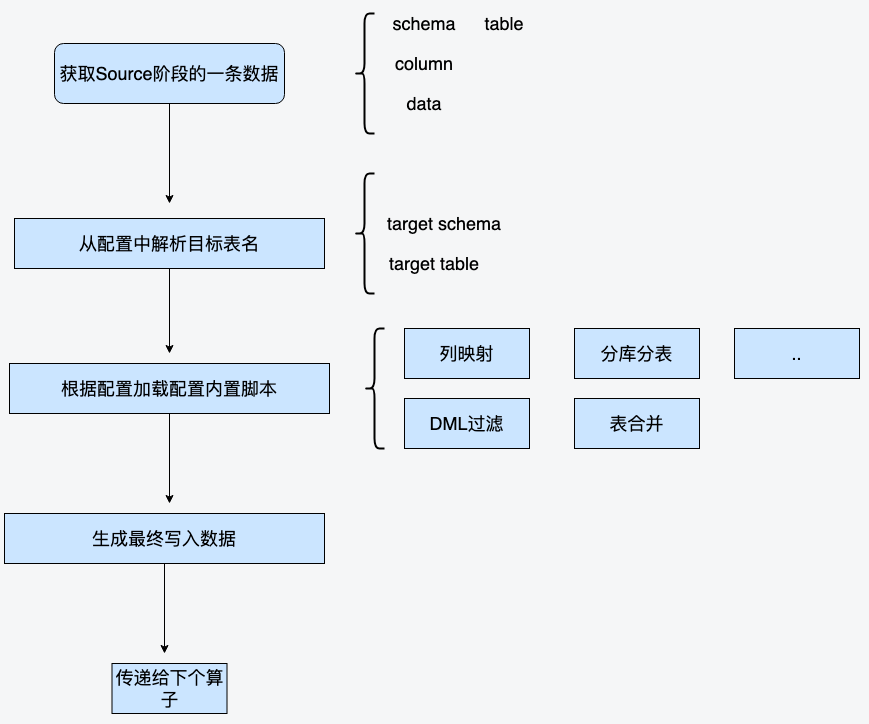
3.5 JBDC写入改造
脚本扩展和动态表名路由:
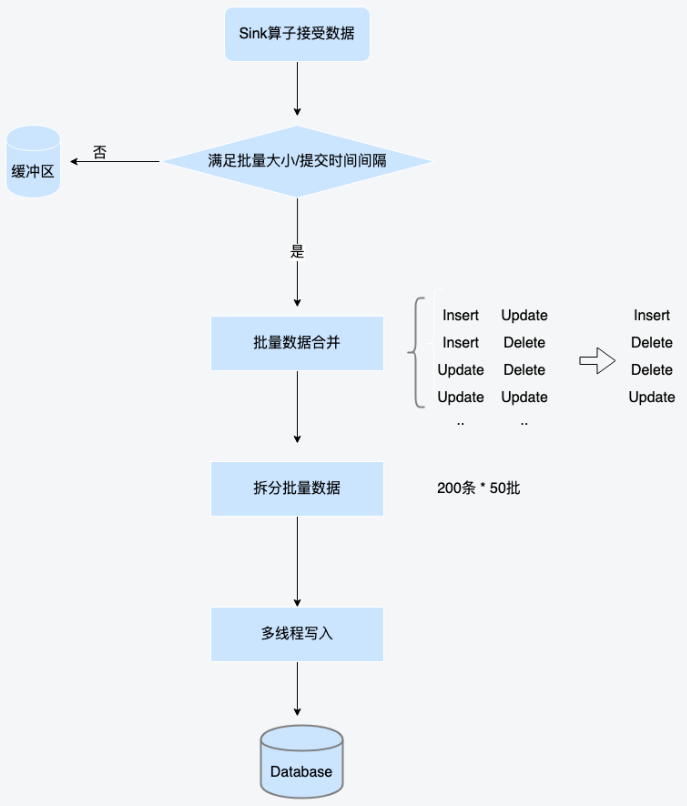
数据合并和多线程写入:
3.6 监控告警
DTS任务需要采集flink任务指标,主要包括任务延迟、各个算子阶段的写入速率,算子被压及使用率等。其中 任务延迟需要接入告警服务,于是我们选择了引入redis来缓存任务的延迟时间,再上报到告警服务来完成飞书的消息和电话告警。
4 最佳实践
4.1 0000-00-00 00:00:00时间戳的问题
MySQL的时间戳允许为0000-00-00 00:00:00, 在Flink任务中通常会被转换为null, 导致写入下游数据源失败, 因此需要做特殊标记对于不同的数据源做不同的转化保证写入的正切行。
4.2 Flink CDC 任务 serverId唯一性
Flink CDC source 会伪装成 MySQL slave节点,为了保证数据的准确性,每个slave必须拥有唯一的serverId来标记该slave的唯一性。因此在flink cdc的任务中我们为每一个任务分配了一个唯一的serverId区间(范围区间是为了支持多并行度)。
4.3 Flink任务数据序列化瓶颈
在flink任务中使用DataStreamAPI并使用比较复杂的数据结构进行传输时,算子之间的序列化成本较高,两个方向,一是建立更为高效的数据结构进行传输,二是开启flink对象复用,并尽可能减少不同并行度之间的数据传输。
5 未来演进
DTS作为一个数据同步平台主要功能是尽可能提供高效的数据源同步功能,助力于多变的业务场景。
5.1 基于Flink SQL的ETL任务管理
流式数据处理除了现有的DataStream API还存在SQL的形式,SQL作为一种通用的语言,对于数据相关的业务同学极大的降低了学习成本。而通过Flink SQL可以做到的ETL流式数据加工也能解决一些复杂业务场景的处理逻辑,将业务逻辑转化为DAG的流式处理图,通过拖拽的方式也能方便使用,FLINK SQL的演进方向能够和现有的Flink DataStream API互补。
应用场景:ETL强大的流式数据转换处理能力大幅提升数据集成效率,也能建实时报表体系,提高分析效率,同时也可以应用于一些实时大屏的场景。
5.2 统一技术栈
将现有的DTS能力都迁移到Flink平台上,保持统一的技术栈,能够极大的降低维护成本。现有遗留的双向同步、数据比对等能力需要做进一步的改造和迁移,符合整体技术收敛的趋势。
6 总结
本文主要分享了以下几个方面:Flink相比现有的技术栈带来的收益,切换到Flink以后的迭代方向及架构功能上的变更、带来新的问题如何解决,以及未来的一些迭代方向,希望能让大家有所收获。
*文/风子
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!






![[微信小程序] movable-view 可移动视图容器 - 范围问题](https://img-blog.csdnimg.cn/b8e4ec3de8a04dc192b476193e23e03b.gif)