文章目录
- 1. 深度学习框架
- 1.1 概述
- 1.2 深度学习框架—关于组件
- 1.2.1 组件—张量
- 1.2.2 基于张量的各种操作
- 1.2.3 计算图
- 1.2.4 自动微分工具
- 1.2.5 拓展包
- 2. 主流深度学习框架
- 2.1 市面上主流框架
- 2.2 本土深度学习框架
- 2.3 深度学习框架的标准化--ONNX
- 3. Tensorflow
- 3.1 Tensorflow—基本用法
- 3.2 Tensorflow—构建图
- 3.3 Tensorflow—Tensor(张量)
- 3.4 Tensorflow—变量(Variables)
- 3.5 Tensorflow—fetch/feed
- 3.6 完整的tensorflow代码示例
- 3.7 拓展-Tensorflow--可视化工具TensorBoard
- 4. Pytorch
- 4.1 概述
- 4.2 Pytorch的优势
- 4.3 Pytorch-常用工具包
- 4.4 Pytorch-Tensor
- 4.5 Pytorch-自动求导
- 4.6 Pytorch-神经网络
- 4.7 Pytorch实现MNIST分类
- 5. 优化算法
- 5.1 SGD(随机梯度下降)
- 5.2 Momentum
- 5.3 拓展--RMSprop(Root Mean Square Prop)
- 5.4 拓展--RMSprop(Root Mean Square Prop)
- 5.5 拓展--Adam
1. 深度学习框架
1.1 概述
深度学习框架是用于构建和训练深度学习模型的软件库或工具,它可以提供清晰的、高级的编程接口以及预训练的模型,使得开发者更加容易地设计和实现深度学习模型。以下是一些常见的深度学习框架:
- TensorFlow: 由Google Brain团队开发的开源库,适合多种应用,并在硬件加速、分布式计算、生产部署等方面具有优势。
- PyTorch: 由Facebook的AI研究团队开发的开源库,对于研究者来说,它的动态计算图特性可以提供更高的灵活性。
- Keras: 可以视为TensorFlow的高级封装,更注重用户体验和易用性。
- Caffe/Caffe2: Caffe最初由Berkeley Vision and Learning Center (BVLC)开发,主要针对卷积神经网络和图像处理。Caffe2则是Facebook对其进行了改进和扩展。
- MXNet: 由Apache Software Foundation维护,支持多种编程语言,并且可以进行分布式计算。
- Microsoft Cognitive Toolkit (CNTK): 由微软开发,优势在于其对大型、分布式深度学习的支持。
应用优势:
- 深度学习框架的出现降低了入门的门槛,你不需要从复杂的神经网络开始编代码,你可以依据需要,使用已有的模型,模型的参数你自己训练得到,你也可以在已有模型的基础上增加自己的layer,或者是在顶端选择自己需要的分类器和优化算法(比如常用的梯度下降法)。
- 当然也正因如此,没有什么框架是完美的,就像一套积木里可能没有你需要的那一种积木,所以不同的框架适用的领域不完全一致。
- 总的来说深度学习框架提供了一系列的深度学习的组件(对于通用的算法,里面会有实现),当需要使用新的算法的时候就需要用户自己去定义,然后调用深度学习框架的函数接口使用用户自定义的新算法。
1.2 深度学习框架—关于组件
大部分深度学习框架都包含以下五个核心组件:
- 张量(Tensor) 。这是深度学习框架的核心组件,因为它负责所有的数学运算。例如,TensorFlow中的张量(Tensor)和PyTorch中的张量(Tensor)。
- 基于张量的各种操作(Operation)
- 计算图(Computation Graph)
- 自动微分(Automatic Differentiation)工具
- BLAS、cuBLAS、cuDNN等拓展包
1.2.1 组件—张量
在深度学习中,我们通常将张量理解为一个多维数组。在这种情况下,张量提供了一种在任意维度上组织数据的方式。
下面是一些不同维度的张量的例子:
- 标量(0维张量):一个单独的数值,比如 7 或 3.14。
- 向量(1维张量):一个数值的一维数组,比如 [1, 2, 3, 4]。
- 矩阵(2维张量):一个数值的二维数组,可以理解为行和列,比如 [[1, 2, 3], [4, 5, 6], [7, 8, 9]]。
- 3维张量:一个数值的三维数组,比如 [[[1, 2, 3], [4, 5, 6], [7, 8, 9]], [[1, 2, 3], [4, 5, 6], [7, 8, 9]], [[1, 2, 3], [4, 5, 6], [7, 8, 9]]]。
在深度学习中,我们经常需要处理更高维度的张量。例如,一个彩色图像可以被表示为一个3维张量。其高和宽对应于图像的像素,而深度(通道数)对应于颜色通道(红,绿,蓝)。如果我们有一个图像批次(例如,用于训练卷积神经网络的一组图像),那么我们可以使用一个4维张量来表示这个批次,其中第一个维度表示图像的索引
1.2.2 基于张量的各种操作
这里的一系列操作包含的范围很宽,可以是简单的矩阵乘法,也可以是卷积、池化和LSTM等稍复杂的运算。而且各框架支持的张量操作通常也不尽相同。
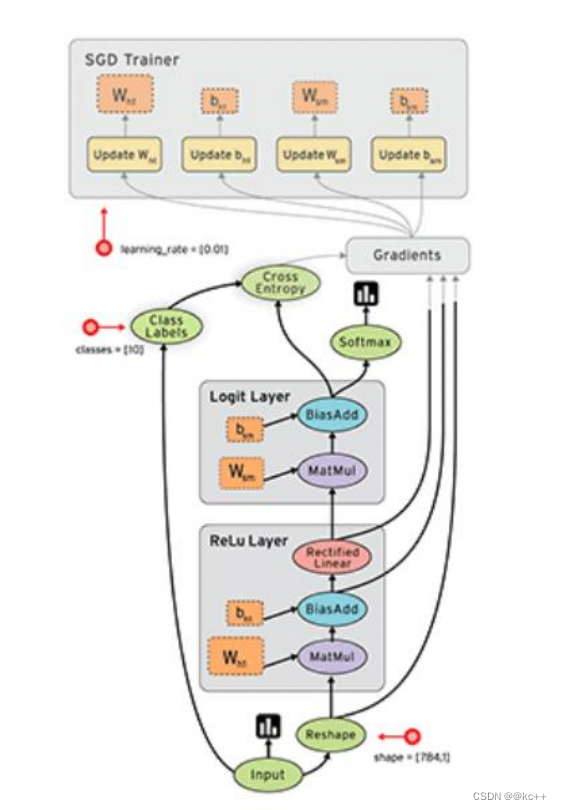
1.2.3 计算图
即流程图
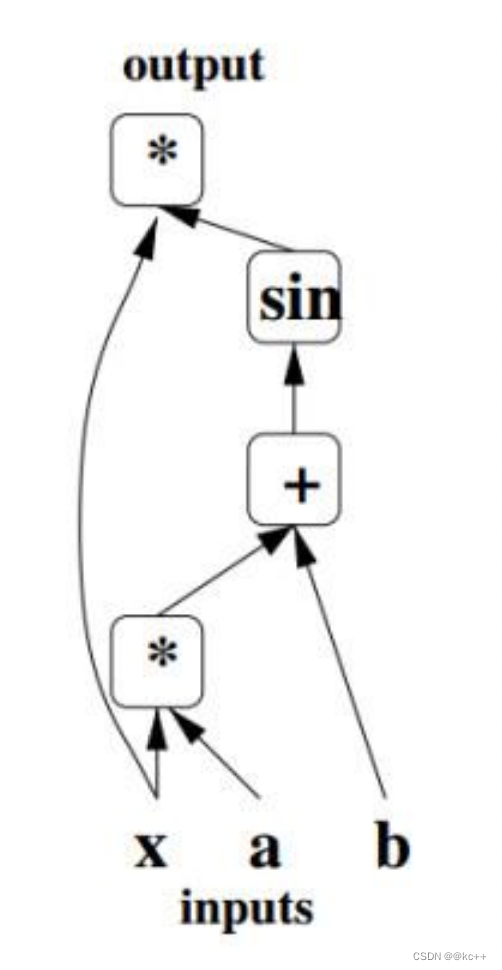
在tensorflow框架中,可以帮助我们将代码的计算图画出来
1.2.4 自动微分工具
用于训练深度学习模型的算法,通常需要进行大量的微分操作。自动微分库可以自动计算这些微分
1.2.5 拓展包
- 此前的大部分实现都是基于高级语言的(如Java、Python、Lua等),而即使是执行最简单的操作,高级语言也会比低级语言消耗更多的CPU周期,更何况是结构复杂的深度神经网络,因此运算缓慢就成了高级语言的一个天然的缺陷。
- 由于低级语言的最优化编程难度很高,而且大部分的基础操作其实也都有公开的最优解决方案,因此一个显著的加速手段就是利用现成的扩展包。
2. 主流深度学习框架
2.1 市面上主流框架
- TensorFlow
- Keras
- PyTorch
- MXNet
- Caffe
- Caffe2
- Theano
- FastAI
- CNTK
- Gluon
- Torch
- Deeplearning4j
- Chainer
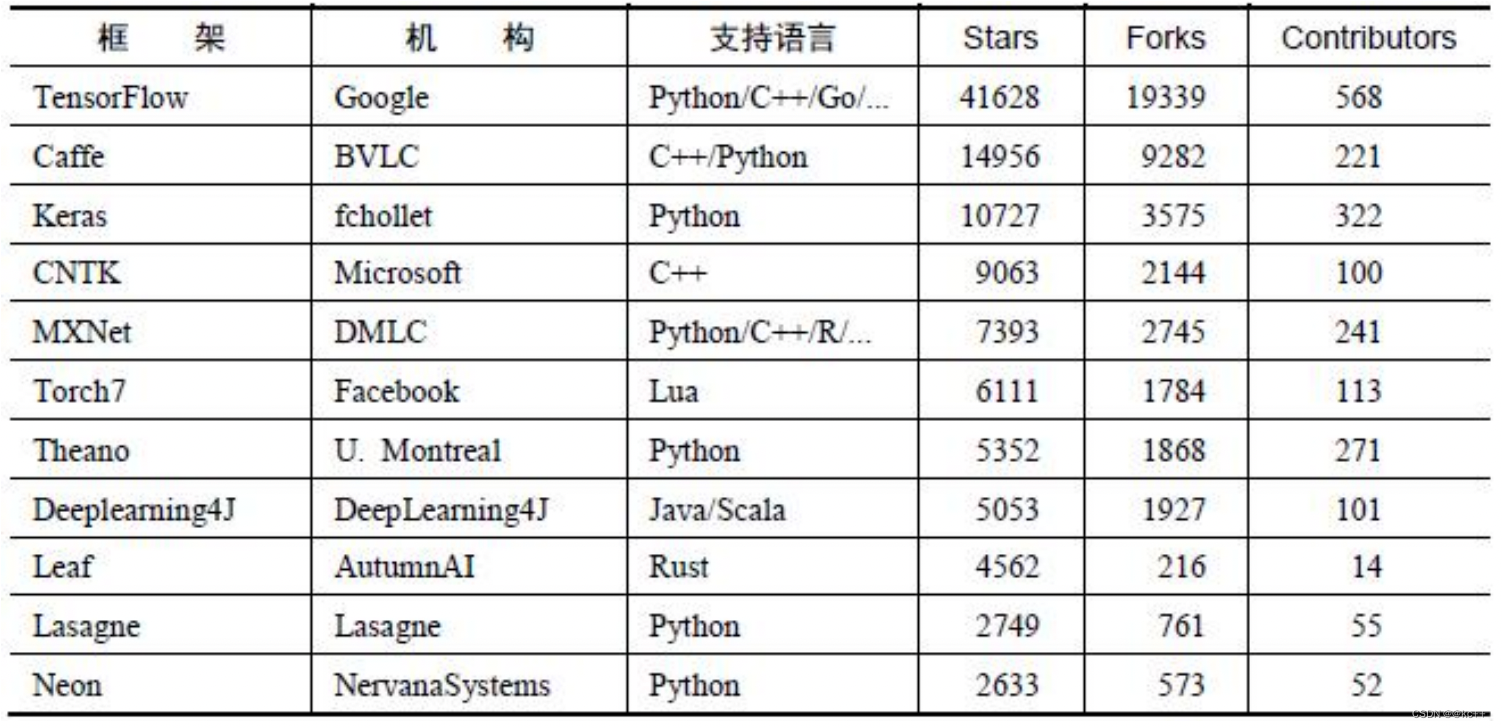
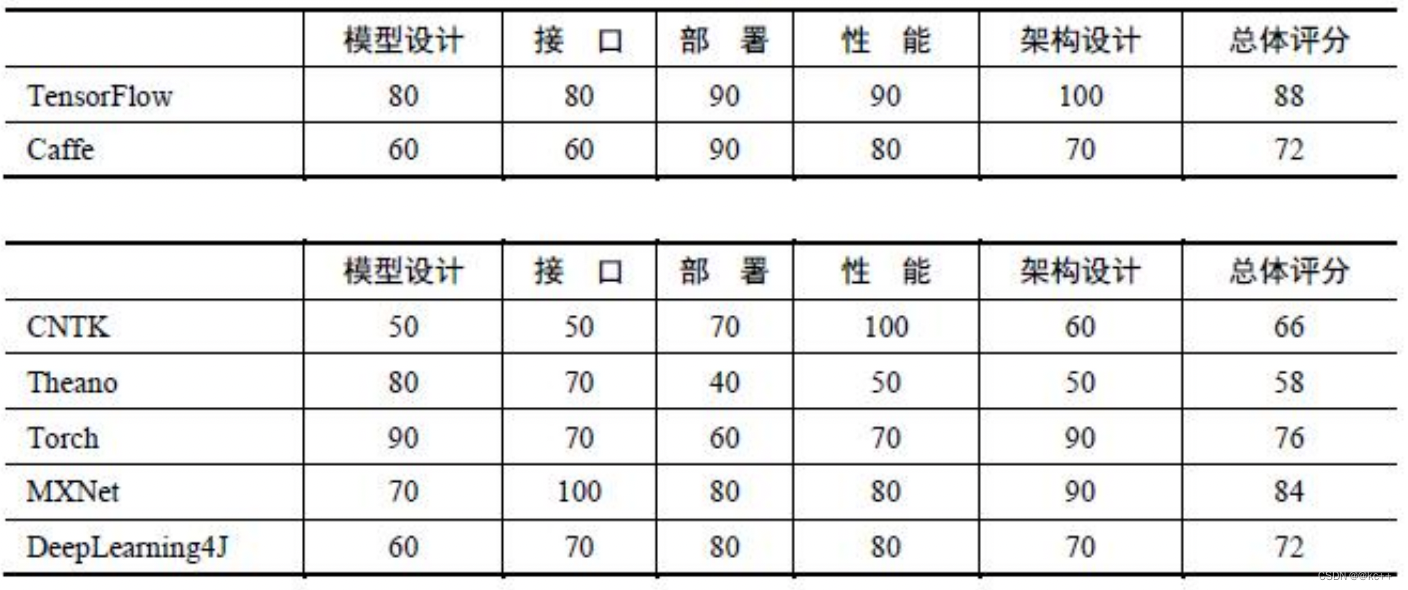
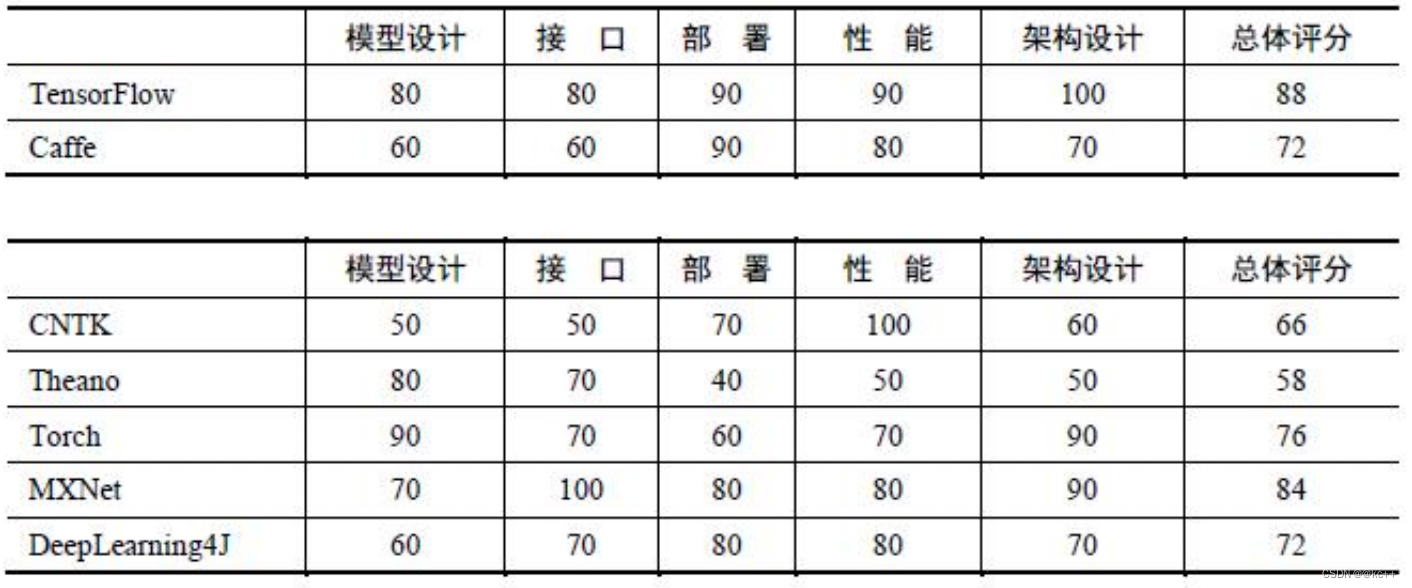
顶级深度学习框架四大阵营:
- TensorFlow,前端框架Keras,背后巨头Google;
- PyTorch,前端框架FastAI,背后巨头Facebook;
- MXNet,前端框架Gluon,背后巨头Amazon;
- Cognitive Toolkit (CNTK),前端框架Keras或Gluon,背后巨头Microsoft。
2.2 本土深度学习框架
- 华为MindSpore:支持端、边、云独立的和协同的统一训练和推理框架。2020年3月28日,正式开源
- 百度PaddlePaddle:PaddlePaddle 100% 都在Github上公开,没有内部版本。PaddlePaddle能够应用于自然语言处理、图像识别、推荐引擎等多个领域,其优势在于开放的多个领先的预训练中文模型。
- 阿里巴巴XDL (X-Deep Learning):阿里巴巴将把其应用于自身广告业务的算法框架XDL (X-Deep Learning)进行开源。XDL主要是针对特定应用场景如广告的深度学习问题的解决方案,是上层高级API 框架而不是底层框架。XDL需要采用桥接的方式配合使用 TensorFlow 和 MXNet 作为单节点的计算后端,XDL依赖于阿里提供特定的部署环境。
- 小米MACE:它针对移动芯片特性进行了大量优化,目前在小米手机上已广泛应用,如人像模式、 场景识别等。该框架采用与 Caffe2 类似的描述文件定义模型,因此它能非常便捷地部署移动端应用。 目前该框架为 TensorFlow 和 Caffe 模型提供转换工具,并且其它框架定义的模型很快也能得到支持。
2.3 深度学习框架的标准化–ONNX
- 开放神经网络交换(ONNX,“Open Neural Network Exchange”):
ONNX最初由微软和Facebook联合发布,后来亚马逊也加入进来,并发布了V1版本,宣布支持ONNX 的公司还有AMD、ARM、华为、 IBM、英特尔、Qualcomm等。 - ONNX是一个表示深度学习模型的开放格式。它使用户可以更轻松地在不同框架之间转移模型。例如,它允许用户构建一个PyTorch模型,然后使用MXNet运行该模型来进行推理。
3. Tensorflow
TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量 (tensor)。它灵活的架构可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或 GPU),服务器,移动设备等等。
3.1 Tensorflow—基本用法
- 使用图 (graph) 来表示计算任务.
- 在被称之为 会话 (Session) 的上下文 (context) 中执行图.
- 使用 tensor 表示数据.
- 通过 变量 (Variable) 维护状态.
- 使用 feed 和 fetch 可以为任意的操作(arbitrary operation)赋值或者从其中获取数据。
3.2 Tensorflow—构建图
- 创建源op:源op不需要任何输入。例如常量(constant)。源op的输出被传递给其他op做运算。
- 在会话(session)中启动图
- 关闭session以释放资源
3.3 Tensorflow—Tensor(张量)
构建图的运算过程输出的结果是一个Tensor,主要由三个属性构成:Name、Shape和Type。
- Name代表的是张量的名字,也是张量的唯一标识符,我们可以在每个op上添加name属性来对节点进行命名,Name的值表示的是该张量来自于第几个输出结果(编号从0开始)
- Shape代表的是张量的维度。
- Type表示的是张量的类型,每个张量都会有唯一的类型。我们需要注意的是要保证参与运算的张量类型相一致,否则会出现类型不匹配的错误。
下面是一个简单的tensorflow运行的实例:
import tensorflow as tf
# TensorFlow Python 库有一个默认图 (default graph), op 构造器可以为其增加节点.
# 这个默认图对许多程序来说已经足够用了.
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点加到默认图中.
#
# 构造器的返回值代表该常量 op 的返回值.
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.
# 返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)
'''
默认图现在有三个节点, 两个 constant() op, 和一个matmul() op.
为了真正进行矩阵相乘运算, 并得到矩阵乘法的结果, 必须在会话里启动这个图.
启动图的第一步是创建一个 Session 对象, 如果无任何创建参数, 会话构造器将启动默认图.
'''
# 启动默认图.
sess = tf.Session()
# 调用 sess 的 'run()' 方法来执行矩阵乘法 op, 传入 'product' 作为该方法的参数.
# 'product' 代表了矩阵乘法 op 的输出, 传入它是向方法表明, 我们希望取回矩阵乘法 op 的输出.
#
# 整个执行过程是自动化的, 会话负责传递 op 所需的全部输入. op 通常是并发执行的.
#
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.
#
# 返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(product)
print(result)
# ==> [[ 12.]]
# 任务完成, 关闭会话.
sess.close()
'''
session对象在使用完后需要关闭以释放资源. 除了显式调用 close 外, 也可以使用 “with” 代码块来自动完成关闭动作.
with tf.Session() as sess:
result = sess.run([product])
print (result)
'''
也可以指定硬件运行代码:
'''
在实现上, TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU或 GPU).
一般你不需要显式指定使用 CPU 还是 GPU, TensorFlow 能自动检测.
如果检测到 GPU, TensorFlow 会尽可能地利用找到的第一个 GPU 来执行操作.
如果你的系统里有多个 GPU, 那么 ID 最小的 GPU 会默认使用。
'''
#如果你想要手动指派设备, 你可以用 with tf.device 创建一个设备环境, 这个环境下的 operation 都统一运行在环境指定的设备上.
import tensorflow as tf
# 新建一个graph.
with tf.device('/cpu:0'):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b, name = "mul")
print("tesnor: ", c)
'''
如果你指定的设备不存在, 你会收到 InvalidArgumentError 错误提示。
可以在创建的 session 里把参数 allow_soft_placement 设置为 True, 这样 tensorFlow 会自动选择一个存在并且支持的设备来运行 operation.
'''
# 新建session with log_device_placement并设置为True.
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True))
# 运行这个op.
print (sess.run(c))
sess.close()
3.4 Tensorflow—变量(Variables)
变量Variables维护图执行过程中的状态信息.
通常会将一个统计模型中的参数表示为一组变量.
例如, 你可以将一个神经网络的权重作为某个变量存储在一个 tensor 中. 在训练过程中, 通过重复运行训练图, 更新这个 tensor.
import tensorflow as tf
# 创建一个变量, 初始化为标量 0.
state = tf.Variable(0, name="counter")
# 创建一个 op, 其作用是使 state 增加 1
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf.assign(state, new_value)
# 启动图后, 变量必须先经过`初始化` (init) op 初始化,
# 首先必须增加一个`初始化` op 到图中.
init_op = tf.global_variables_initializer()
# 启动图, 运行 op
with tf.Session() as sess:
# 运行 'init' op
sess.run(init_op)
# 打印 'state' 的初始值
print("state",sess.run(state))
# 运行 op, 更新 'state', 并打印 'state'
for _ in range(5):
sess.run(update)
print("update:",sess.run(state))
3.5 Tensorflow—fetch/feed
Fetch:为了取回操作的输出内容,可以使用session对象的run()调用执行图时,传入一些tensor,这些tensor会帮助你取回结果。
import tensorflow as tf
input1 = tf.constant(3.0)
input2 = tf.constant(2.0)
input3 = tf.constant(5.0)
intermed = tf.add(input2, input3)
mul = tf.multiply(input1, intermed)
with tf.Session() as sess:
result = sess.run([mul, intermed]) #需要获取的多个 tensor 值,在 op 的一次运行中一起获得(而不是逐个去获取 tensor)。
print(result)
Feed:使用一个tensor值临时替换一个操作的输出结果。可以提供feed数据作为run()调用的参数.
feed 只在调用它的方法内有效, 方法结束, feed 就会消失. 最常见的用例是将某些特殊的操作指定为 “feed” 操作, 标记的方法是使用 tf.placeholder() 为这些操作创建占位符。
import tensorflow as tf
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1, input2)
with tf.Session() as sess:
print(sess.run([output], feed_dict={input1:[7], input2:[2.]}))
# 输出:
# [array([ 14.], dtype=float32)]
placeholder是一个数据初始化的容器,它与变量最大的不同在于placeholder定义的是一个模板,这样我们就可以在session运行阶段,利用feed_dict的字典结构给placeholder填充具体的内容,而无需每次都提前定义好变量的值,大大提高了代码的利用率。
3.6 完整的tensorflow代码示例
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
#使用numpy生成200个随机点
x_data=np.linspace(-0.5,0.5,200)[:,np.newaxis]
noise=np.random.normal(0,0.02,x_data.shape)
y_data=np.square(x_data)+noise
#定义两个placeholder存放输入数据
x=tf.placeholder(tf.float32,[None,1])
y=tf.placeholder(tf.float32,[None,1])
#定义神经网络中间层
Weights_L1=tf.Variable(tf.random_normal([1,10]))
biases_L1=tf.Variable(tf.zeros([1,10])) #加入偏置项
Wx_plus_b_L1=tf.matmul(x,Weights_L1)+biases_L1
L1=tf.nn.tanh(Wx_plus_b_L1) #加入激活函数
#定义神经网络输出层
Weights_L2=tf.Variable(tf.random_normal([10,1]))
biases_L2=tf.Variable(tf.zeros([1,1])) #加入偏置项
Wx_plus_b_L2=tf.matmul(L1,Weights_L2)+biases_L2
prediction=tf.nn.tanh(Wx_plus_b_L2) #加入激活函数
#定义损失函数(均方差函数)
loss=tf.reduce_mean(tf.square(y-prediction))
#定义反向传播算法(使用梯度下降算法训练)
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
with tf.Session() as sess:
#变量初始化
sess.run(tf.global_variables_initializer())
#训练2000次
for i in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
#获得预测值
prediction_value=sess.run(prediction,feed_dict={x:x_data})
#画图
plt.figure()
plt.scatter(x_data,y_data) #散点是真实值
plt.plot(x_data,prediction_value,'r-',lw=5) #曲线是预测值
plt.show()
3.7 拓展-Tensorflow–可视化工具TensorBoard
对大部分人而言,深度神经网络就像一个黑盒子,其内部的组织、结构、以及其训练过程很难理清 楚,这给深度神经网络原理的理解和工程化带来了很大的挑战。
为了解决这个问题,tensorboard应运而生。
Tensorboard是tensorflow内置的一个可视化工具,它通过将tensorflow程序输出的日志文件的信息可 视化使得tensorflow程序的理解、调试和优化更加简单高效。
Tensorboard的可视化依赖于tensorflow程序运行输出的日志文件,因而tensorboard和tensorflow程序 在不同的进程中运行。
import tensorflow as tf
# 定义一个计算图,实现两个向量的减法操作
# 定义两个输入,a为常量,b为变量
a=tf.constant([10.0, 20.0, 40.0], name='a')
b=tf.Variable(tf.random_uniform([3]), name='b')
output=tf.add_n([a,b], name='add')
# 生成一个具有写权限的日志文件操作对象,将当前命名空间的计算图写进日志中
writer=tf.summary.FileWriter('logs', tf.get_default_graph())
writer.close()
#启动tensorboard服务(在命令行启动)
#tensorboard --logdir logs
#启动tensorboard服务后,复制地址并在本地浏览器中打开,
生成一个具有写权限的日志文件操作对象,将当前命名空间的计算图写进日志中
writer=tf.summary.FileWriter(‘logs’, tf.get_default_graph())
writer.close()
启动tensorboard服务(在命令行启动)
tensorboard --logdir logs
启动tensorboard服务后,复制地址并在本地浏览器中打开,
4. Pytorch
4.1 概述
- Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。Torch 是一个经典的对多维矩阵数据进行操作的张量(tensor )库,在机器学习和其他数学密集型应用有广泛应用。
- Pytorch的计算图是动态的,可以根据计算需要实时改变计算图
- 由于Torch语言采用 Lua,导致在国内一直很小众,并逐渐被支持 Python 的 Tensorflow 抢走用户。作为经典机器学习库 Torch 的端口,PyTorch 为 Python 语言使用者提供了舒适的写代码选择。
这是一个基于Python的科学计算包,其旨在服务两类场合:
- 替代numpy发挥GPU潜能
- 一个提供了高度灵活性和效率的深度学习实验性平台
4.2 Pytorch的优势
- 简洁:
PyTorch的设计追求最少的封装,尽量避免重复造轮子。不像 TensorFlow 中充斥着session、graph、operation、 name_scope、variable、tensor、layer等全新的概念,PyTorch 的设计遵循tensor→variable(autograd)→nn.Module 三个由低到高的抽象层次,分别代表高维数组(张量)、自动求导(变量)和神经网络(层/模块),而且这三个 抽象之间联系紧密,可以同时进行修改和操作。 - 速度:
PyTorch 的灵活性不以速度为代价,在许多评测中,PyTorch 的速度表现胜过 TensorFlow和Keras 等框架。 - 易用:
PyTorch 是所有的框架中面向对象设计的最优雅的一个。PyTorch的面向对象的接口设计来源于Torch,而Torch的接口设计以灵活易用而著称,Keras作者最初就是受Torch的启发才开发了Keras。 - 活跃的社区:
PyTorch 提供了完整的文档,循序渐进的指南,作者亲自维护的论坛,供用户交流和求教问题。Facebook 人 工智能研究院对 PyTorch 提供了强力支持。
4.3 Pytorch-常用工具包
- torch :类似 NumPy 的张量库,支持GPU;
- torch.autograd :基于 type 的自动区别库,支持 torch 之中的所有可区分张量运行;
- torch.nn :为最大化灵活性而设计,与 autograd 深度整合的神经网络库;
- torch.optim:与 torch.nn 一起使用的优化包,包含 SGD、RMSProp、LBFGS、Adam 等标准优化 方式;
- torch.multiprocessing: python 多进程并发,进程之间 torch Tensors 的内存共享;
- torch.utils:数据载入器。具有训练器和其他便利功能;
- torch.legacy(.nn/.optim) :出于向后兼容性考虑,从 Torch 移植来的 legacy 代码;
特别注意:
通道问题:不同的视觉库对于图像读取的方式不一样,图像的通道也不一样:
opencv的默认imread就是HWC,Pytorch的Tensor为CHW,TensorFlow两者都支持。
4.4 Pytorch-Tensor
Torch 定义了七种 CPU tensor 类型和八种 GPU tensor 类型:

创建Tensor的常见接口:

Tensor对象的方法:

4.5 Pytorch-自动求导
tensor对象通过一系列的运算可以组成动态图,对于每个tensor对象,有下面几个变量控制求导的属性。

4.6 Pytorch-神经网络
理解pytorch的基础主要从以下三个方面
- Numpy风格的Tensor操作。pytorch中tensor提供的API参考了Numpy的设计。
- 变量自动求导。在一序列计算过程形成的计算图中,参与的变量可以方便的计算自己对目标函数的 梯度。
- 神经网络层与损失函数优化等高层封装。网络层的封装存在于torch.nn模块,损失函数由 torch.nn.functional模块提供,优化函数由torch.optim模块提供。
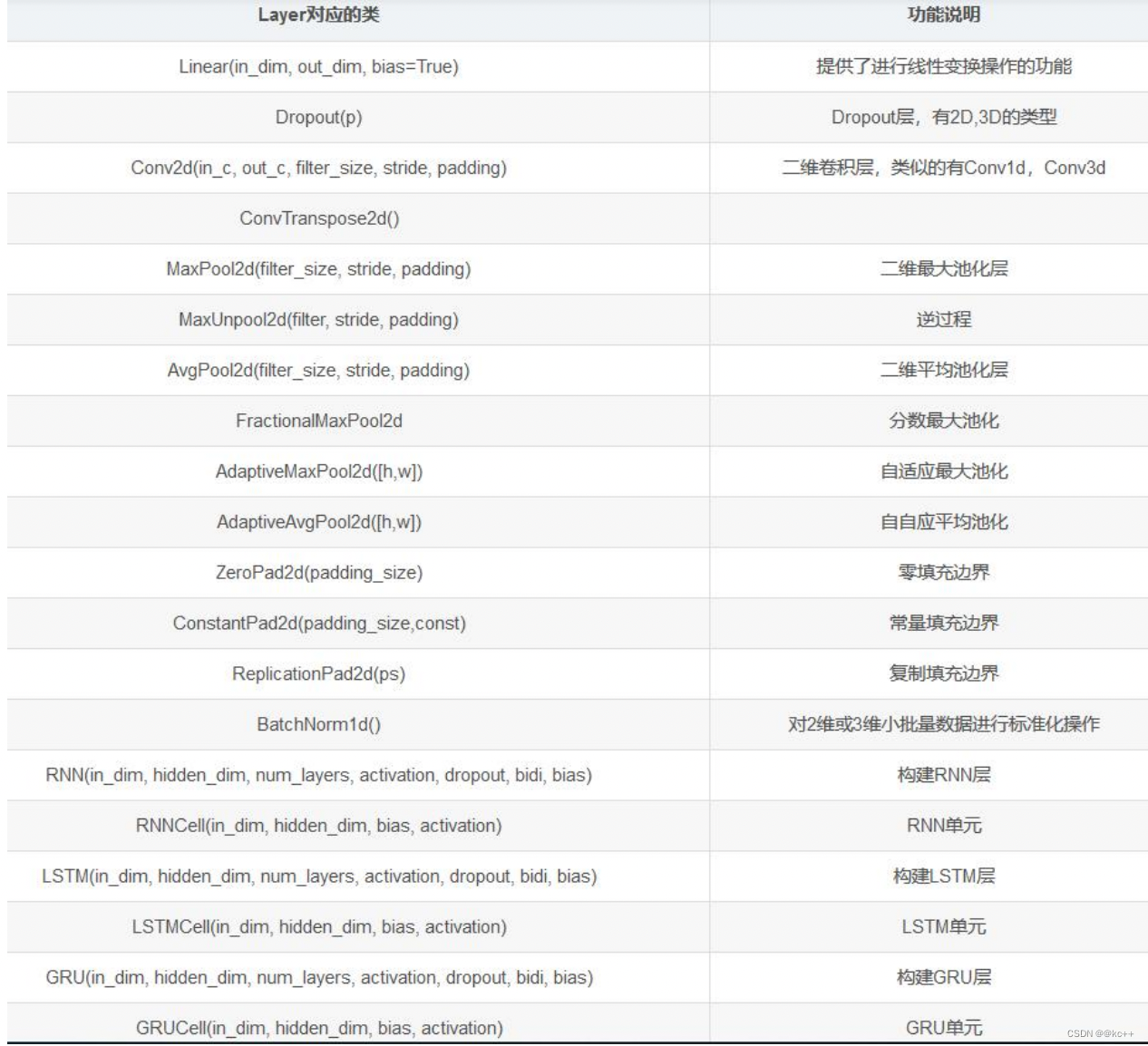
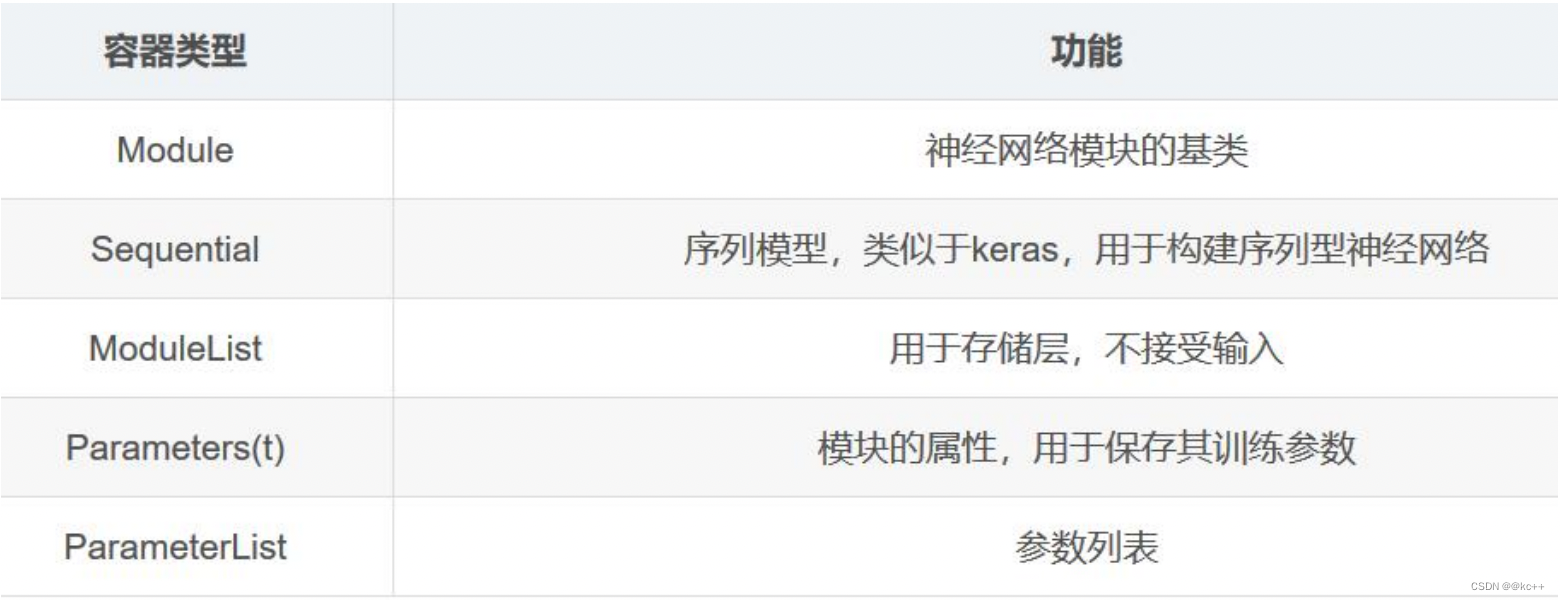
torch.nn模块提供了创建神经网络的基础构件,这些层都继承自Module类。
下面表格中列出了比较重要的神经网络层组件。
对应的在nn.functional模块中,提供这些层对应的函数实现。
通常对于可训练参数的层使用module,而对于不需要训练参数的层如softmax这些,可以使用functional中的函数
- torch.nn.Module提供了神经网络的基类,当实现神经网络时需要继承自此模块,并在初始化函 数中创建网络需要包含的层,并实现forward函数完成前向计算,网络的反向计算会由自动求 导机制处理。
- 通常将需要训练的层写在init函数中,将参数不需要训练的层在forward方法里调用对应的函数 来实现相应的层。
在pytorch中跑一个网络就只需要分三步:
- 写好网络;
- 编写数据的标签和路径索引;
- 把数据送到网络。
4.7 Pytorch实现MNIST分类
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
class Model:
def __init__(self, net, cost, optimist):
self.net = net
self.cost = self.create_cost(cost)
self.optimizer = self.create_optimizer(optimist)
pass
def create_cost(self, cost):
support_cost = {
'CROSS_ENTROPY': nn.CrossEntropyLoss(),
'MSE': nn.MSELoss()
}
return support_cost[cost]
def create_optimizer(self, optimist, **rests):
support_optim = {
'SGD': optim.SGD(self.net.parameters(), lr=0.1, **rests),
'ADAM': optim.Adam(self.net.parameters(), lr=0.01, **rests),
'RMSP':optim.RMSprop(self.net.parameters(), lr=0.001, **rests)
}
return support_optim[optimist]
def train(self, train_loader, epoches=3):
for epoch in range(epoches):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
self.optimizer.zero_grad()
# forward + backward + optimize
outputs = self.net(inputs)
loss = self.cost(outputs, labels)
loss.backward()
self.optimizer.step()
running_loss += loss.item()
if i % 100 == 0:
print('[epoch %d, %.2f%%] loss: %.3f' %
(epoch + 1, (i + 1)*1./len(train_loader), running_loss / 100))
running_loss = 0.0
print('Finished Training')
def evaluate(self, test_loader):
print('Evaluating ...')
correct = 0
total = 0
with torch.no_grad(): # no grad when test and predict
for data in test_loader:
images, labels = data
outputs = self.net(images)
predicted = torch.argmax(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))
def mnist_load_data():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0,], [1,])])
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32,
shuffle=True, num_workers=2)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=32,shuffle=True, num_workers=2)
return trainloader, testloader
class MnistNet(torch.nn.Module):
def __init__(self):
super(MnistNet, self).__init__()
self.fc1 = torch.nn.Linear(28*28, 512)
self.fc2 = torch.nn.Linear(512, 512)
self.fc3 = torch.nn.Linear(512, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.softmax(self.fc3(x), dim=1)
return x
if __name__ == '__main__':
# train for mnist
net = MnistNet()
model = Model(net, 'CROSS_ENTROPY', 'RMSP')
train_loader, test_loader = mnist_load_data()
model.train(train_loader)
model.evaluate(test_loader)
5. 优化算法
深度学习的优化算法主要有GD,SGD,Momentum,RMSProp和Adam算法,还有诸如Adagrad算法, 不过大同小异,理解了前面几个,后面的也就引刃而解了。

5.1 SGD(随机梯度下降)
SGD 又称 online 的梯度下降, 每次估计梯度的时候, 只选用一个或几个batch训练样本。
当训练数据过大时,用BGD可能造成内存不够用,那么就可以用SGD了。深度学习使用的训练 集一般都比较大(几十万~几十亿)。而BGD算法,每走一步(更新模型参数),为了计算 original-loss上的梯度,就需要遍历整个数据集,这显然效率是很低的。而SGD算法,每次随 机选择一个mini-batch去计算梯度,每走一步只需要遍历一个minibatch(一~几百)的数据。
5.2 Momentum
通常情况我们在训练深度神经网络的时候把数据拆解成一小批一小批地进行训练,这就是我们常用的 mini-batch SGD训练算法,然而虽然这种算法能够带来很好的训练速度,但是在到达最优点的时候并 不能够总是真正到达最优点,而是在最优点附近徘徊。
另一个缺点就是这种算法需要我们挑选一个合适的学习率,当我们采用小的学习率的时候,会导致网 络在训练的时候收敛太慢;当我们采用大的学习率的时候,会导致在训练过程中优化的幅度跳过函数 的范围,也就是可能跳过最优点。
我们所希望的仅仅是网络在优化的时候网络的损失函数有一个很好的收敛速度,同时又不至于摆动幅 度太大。
Momentum(拓展)

5.3 拓展–RMSprop(Root Mean Square Prop)
在Momentum优化算法中,虽然初步解决了优化中摆动幅度大的问题。所谓的摆动幅度就是在优 化中经过更新之后参数的变化范围。
如下图所示,蓝色的为Momentum优化算法所走的路线,绿色的为RMSProp优化算法所走的路线。

5.4 拓展–RMSprop(Root Mean Square Prop)

5.5 拓展–Adam
有了上面两种优化算法,一种可以使用类似于物理中的动量来累积梯度,另一种可以使得收敛速度更 快同时使得波动的幅度更小
那么将两种算法结合起来所取得的表现一定会更好。Adam(Adaptive Moment Estimation)算法是将 Momentum算法和RMSProp算法结合起来使用的一种算法,我们所使用的参数基本和上面的一致,在 训练的最开始我们需要初始化梯度的累积量和平方累积量。
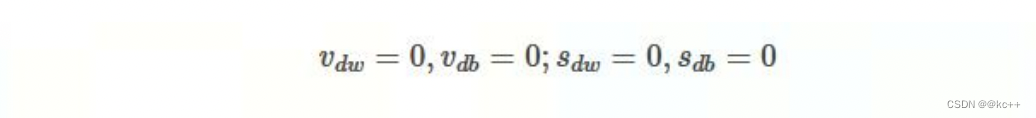














![[工具推荐] LICEcap 动图gif录制工具 轻量/开源/免费](https://img-blog.csdnimg.cn/5f739b3970424fb2884d64e6a78d6b24.png)
