摘要:
本文提到的在低损耗氮化硅平台上制造的紧凑片上光学卷积处理单元,可以展示出其大规模集成的能力。
深度学习的处理模式是我们在在自动驾驶环境目标分类、识别、跟踪等场合下不可或缺的重要一环。随着自动驾驶技术的不断演进,要求处理的复杂场景也越来越多,并且在驾驶功能安全下必须考虑的实时性约束下,人们强烈希望提高底层神经形态硬件的处理速度,同时降低其计算能耗。然而,即便是当前行业内最牛逼的芯片公司(如英伟达、高通这些)其目前的方案也主要是基于冯·诺依曼计算范式。这类范式中,数据采用“潮汐式传输”,这主要是因为在这些方案中,存储器和处理单元是分开的。数据交换速度和能耗之间存在固有的权衡。而受限在冯诺依曼架构下的芯片设计提升方式无非就是在现有的成熟架构及工艺下,当前依靠制程技术进步,增加晶体管密度提升算力、降低功耗已逐步趋于物理极限。可以说,目前的芯片处理方案在海量数据处理中面临着电频率和内存访问时间的限制。这就大大制约了自动驾驶系统高算力、大带宽、大存储的整体需求。
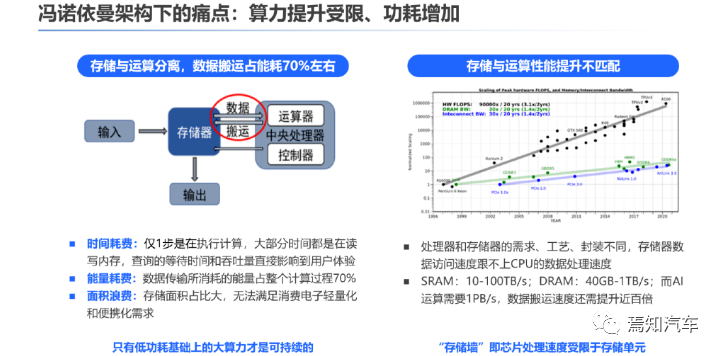
为了应对后摩尔时代AI推理芯片算力受限的问题,光学神经网络应运而生。光学卷积神经网络是一种利用光波作为载体进行信息处理的技术,具有大带宽、低延时、低功耗等优点,提供了一种“传输即计算,结构即功能”的计算架构,有望避免冯·诺依曼计算范式中存在的数据潮汐传输问题,对下阶段自动驾驶的发展起到了重要的推动作用。
近年来光计算在AI领域呈现高速的发展,具有广阔的应用前景。以Lightmatter和Lightelligence为代表的公司,推出了新型的硅光计算芯片,性能远超目前的AI算力芯片,据Lightmatter的数据,他们推出的Envise芯片的运行速度比英伟达的A100芯片快1.5到10倍。
光学神经网络ONN在效率方面与最先进的数字处理器相当,但在计算密度方面却显示出巨大的飞跃。从计算结果来看,ONN 在能耗和计算密度方面有至少两个数量级的提升潜力。然而,随着计算矩阵尺寸的扩大,元件数量、芯片尺寸和功耗呈二次方增加,这在很大程度上限制了最终光学计算方案的集成潜力,同时显着增加了光学计算方案的复杂性。
本文将针对中科院团队研制出的超高集成度光学卷积处理器在自动驾驶系统技术中的应用提升进行分析介绍。
1、光学卷积处理器使用非相干光卷积运算原理
本文介绍了中科院在今年6月最新公布研发的一种集成在低损耗氮化硅(SiN)平台上的紧凑型片上非相干光学卷积处理单元(OCPU),这种处理器将以完全并行的方式提取各种特征图。OCPU 利用波分复用 (WDM) 技术和多模干涉耦合相结合,包括两个 4 × 4 多模干涉 (MMI) 单元和四个移相器 (PS) 作为最小元件数,可同时支持三个 2 × 2 个相关的实值核,这样可以确保在OCPU中可以以并行方式执行三组卷积计算。所提出的单元还可以仅通过调整四个 PS 来动态重新配置。尽管内核是相互关联的,但 OCPU 可以作为特定的卷积层工作。
所设计的OCPU的结构图如下图所示,其中包含两个4 × 4 多模干涉单元MMI和四个移相器PS。输入数据被编码为四个不相干光波,然后送入OCPU进行乘法累加(MAC)运算。OCPU作为并行的多个内核,可以同时实现多组卷积运算。每个输出端口被视为一个独立的内核,每个内核的元素数量等于输入端口的元素数量,这表明计算能力随着输入端口的数量而增加。此外,通过热光效应可以改变移相器PS 的电流,从而可以动态地重新配置内核。
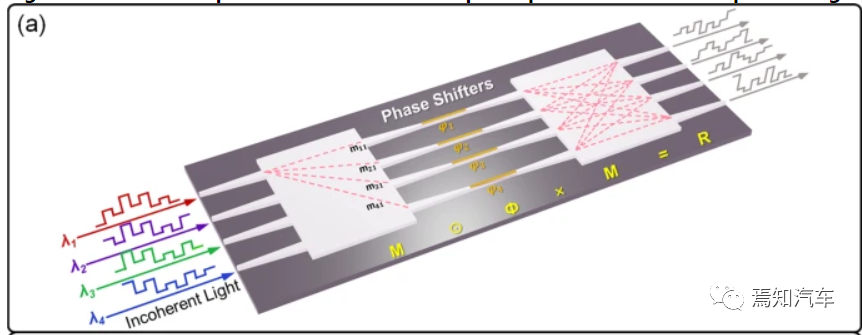
图1 OCPU 使用非相干光同时执行三组不同的卷积运算
如上图1所示,输入矢量I通过电光调制同时调制到具有相同初始幅度的四个非相干光波的幅度上。MMI 单元和 PS 数组的复值传输矩阵 M 和 Φ 分别写为:
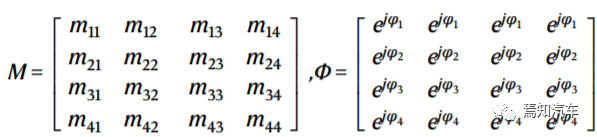
(1)
其中,M中的元素

表示连接输出端口 u 和输入端口 v 的 MMI 响应,Φ 的每一行是 PS 的附加相位。经过 OCPU 的传输和光电探测器 (PD) 的平方律检测后,OCPU 的完整传输矩阵可表示为:

(2)
其中,符号为⊙表示矩阵M和矩阵Φ之间对应位置元素的乘法,而符号×则表示两个矩阵的乘法。
当一个 4 × 1 向量 I 输入到 OCPU 时,OCPU 中进行向量矩阵乘法(VMM),运算结果推断为 O = R × I,其中 OCPU 的每个输出是输入向量I的卷积结果。因此,R的每一行都可以作为没有负值的卷积核。负值也可以通过将任意一个向量设置为地线并从其余三个向量中减去它来获得。以最后一个向量为地线,三个负值的核 Ad ∼Cd 重写为:
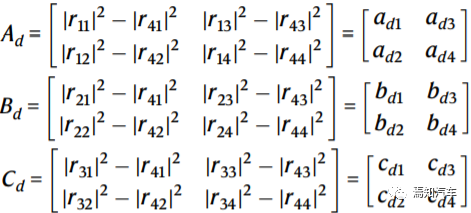
(3)
从方程式 (1) 和 (3) 中,动态重构核矩阵是通过利用热光效应调整 PS 来实现的。这是基于 PS 微型加热器中使用的驱动电流引起波导折射率的变化,从而使光波获得所需的额外相位。在等式中(2)中,ruv随光波形的相位变化,Ad、Bd和Cd随后随着阶段的变化而重建三个新的内核。
2、光学卷积处理器实例结构图
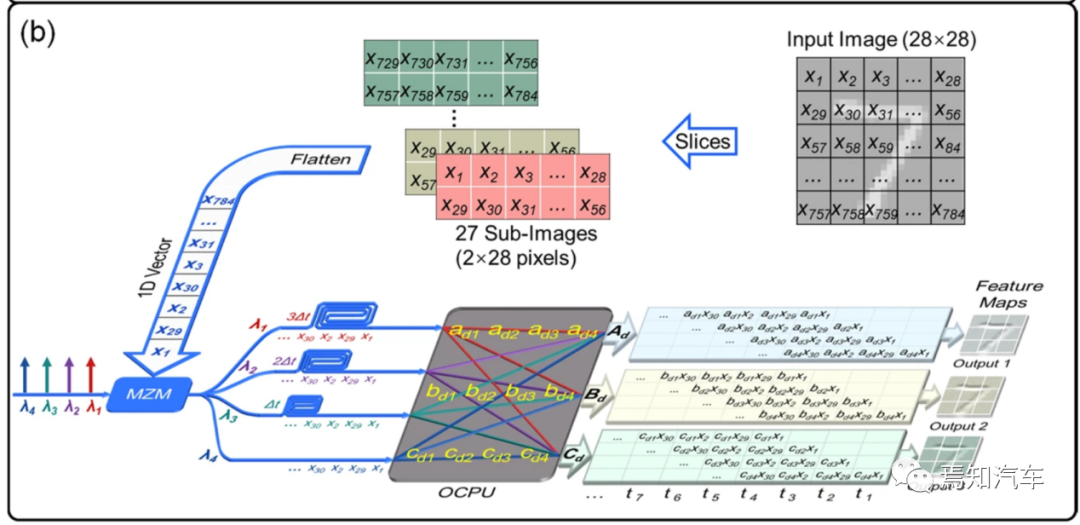
特征图提取的卷积过程如下图所示,其中包括串行数据一维(1D)平坦化操作、光学核心表示和与OCPU的卷积操作。
首先,需要将二维(2D)图像矩阵压缩为一维向量。以28 × 28像素的“7”数字图像为例,28 × 28矩阵沿纵轴总共分为27个子矩阵切片,每个子图像有2 × 28个元素。然后,将27个子图像按列展平为子向量,通过连接子向量从头到尾形成1 × 1512向量。
编码视频数据X通过Mach-Zehnder调制器(MZM),其调制波长为λ1~λ4的非相干光波的幅度,并生成编码数据X的四个副本。然后,光波形被路由到一个波长的四个并行通道中每个通道之间都经历 Δτ 的时间延迟,等于调制信号fb波特率的倒数(即 Δτ = 1/fb )。四个时间波形在OCPU的输出端口处重新分配和重新组合。每个通道之间的正交性是由非相干光束来保证,使得不同的输入波形在OCPU中单独传播。随后,PD实现平方律检测并对四个非相干波长的功率求和。每个输出端口每个时隙的计算结果是向量X中相邻四个元素与2×2核矩阵Ad、Bd或Cd的卷积。
最后,移相器PD实现平方律检测并对四个非相干波长的功率求和。每个输出端口每个时隙的计算结果是向量中相邻四个元素与2 × 2核矩阵同时作用。
OCPU的结构图
如上所述OCPU能够同时执行多内核并行卷积运算。从上图中,每个输出端口作为1×4权重向量或2×2内核,并且在每个时隙执行4次MAC操作。因此,每个输出端口的计算速度等于每秒 4fb MAC 操作。因此,具有三个并行内核的 OCPU 的总计算速度为每秒 3×4fb = 12fb MAC 操作。一般来说,对于具有n个输入/输出端口的OCPU,总计算速度达到每秒n(n-1)fb 次MAC操作。值得注意的是,OCPU中形成的n-1 个内核之间存在一定的相关性,一个内核的重新配置不可避免地会导致与其他内核的重链接。
此外,OCPU的输出中可能包含一些无关紧要的值,需要按照卷积运算的原理将其消除以实现特征提取。保留卷积结果中有效元素的规则是,除了第一个值之外的偶数值对于每个子向量都是重要的。因此,对于第一个子向量,特征矩阵第一行的27个有效值可以表示为 [ y4 y6 ... y56] 。最后,将27行有效值以列格式重新排列,就可以形成27×27的特征矩阵,核滑动窗口为1。
3、光学卷积处理器在自动驾驶中的应用
实际上,这款超高集成度的光学卷积处理器的问世,标志着我国在光计算方面有了重大突破。那么,这款处理器还有哪些功能?它是否能够超过行业标杆芯片英伟达?依靠对前序光学卷积处理器的基础说明我们来分析下其在自动驾驶中到底将产生怎样助力。
对于城区自动驾驶领航系统而言,需要车端具备更强的感知和运算能力,因此更利好大算力芯片和激光雷达,传统 CNN 模型的原理是通过卷积层构造广义过滤器,从而对图像中的元素进行不断地筛选压缩。因此其感受域一定程度上取决于过滤器的大小和卷积层的数量。随着训练数据量的增长,CNN 模型的收益会呈现过饱和趋势。而Transformer 的网络结构在嫁接2D 图像和 3D 空间时借鉴了人脑的注意力(Attention)机制,在处理大量信息时能够只选择处理关键信息,以提升神经网络的效率,因此 Transformer 的饱和区间很大,更适宜于大规模数据训练的需求。
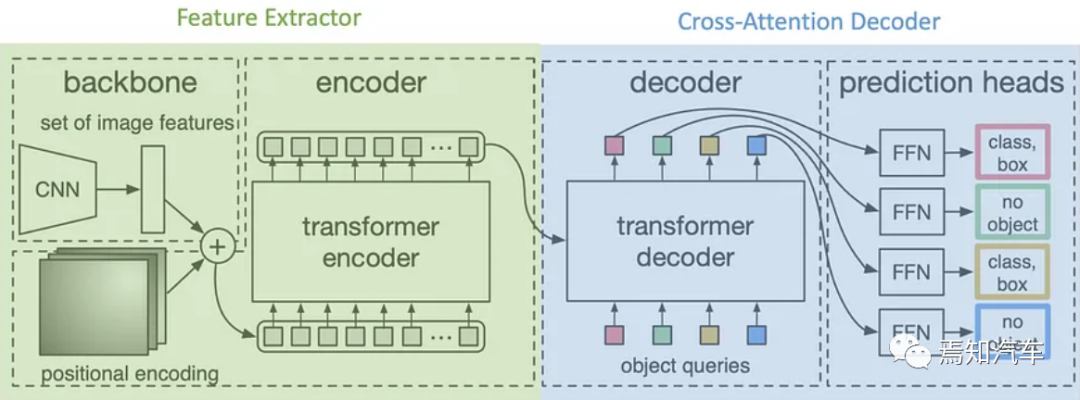
同时,相较于 CNN/RNN,Transformer 具有更强的并行计算能力,可加入时间序列矢量,其数据流特征有显著差别,浮点矢量矩阵乘法累加运算更适合采用 BF16 精度。Transformer 允许数据以并行的形式进行计算,且保留了数据的全局视角,而 CNN/RNN 的数据流只能以串行方式计算,不具备数据的全局记忆能力。因此,可以说Transformer 相比于传统 CNN,具备更强的序列建模能力和全局信息感知能力,已广泛用于自动驾驶视觉 2D 图像数据至 3D 空间的转化。
在“BEV + Transformer”趋势下,算法复杂度、数据规模以及模型参数均呈指数级提升,推动自动驾驶芯片向着大算力、新架构以及存算一体等方向演进。传统 AI 推理专用芯片大多针对 CNN/RNN,并行计算表现不佳,且普遍针对 INT8 精度,几乎不考虑浮点运算。因此想要更好适配 Transformer 算法,就需要将 AI 推理芯片从硬件层面进行完整的架构革新,加入专门针对 Transformer 的加速器,或使用更强的 CPU 算力来对数据整形,这对芯片架构、ASIC 研发能力,以及成本控制都提出了更高的要求。
面向这类计算存储需求,光学卷积处理器则是非常不错的选择。这里我们将以自动驾驶系统中典型的BEV+Transformer这类大型并行计算为基础介绍光学卷积处理器的有效应用将会产生怎样惊艳的计算结果。
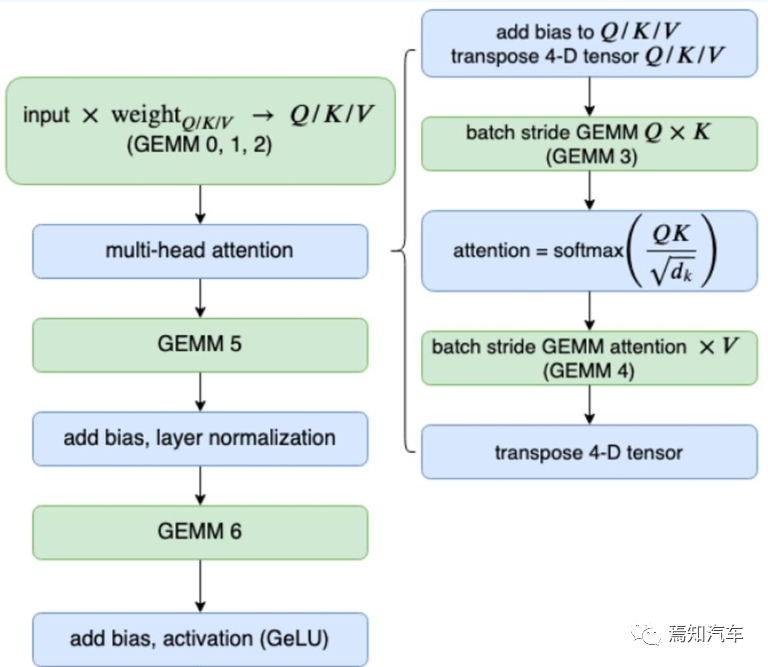
和大多数序列化模型一样,Transformer 的结构也是由编码器 Encoder 和 解码器Decoder 组成,Encoder 负责提取上下文特征,Decoder 负责解码。其主要核心模块包含 多头自注意力机制、编解码交叉注意力机制和前馈编码器。对整个 Batch 数据的处理方式能需要充分利用 GPU 强大的并行计算能力,而 Decoder 的逐个 Token 处理的特性(尤其是结合 Beam Search 等模块)均要求对其并行处理能力进行优化,尤其是需要避免重复计算和存储。
基于如上分析不难看出,要想利用好Transformer在自动驾驶中的高性能计算能力,需要从智驾芯片的算子、内存、精度等不同维度开展大量研究并进行不断优化。
1. 算子融合和重构
整体上,计算过程需要将多个神经网络层融合成一个卷积kernel ,这样可以很大程度上减小计算量和内存 IO。这样多层聚积成单核Kernel的方式会对直接矩阵运算核实现相对低效的算子,并完成无精度损失的重构。使其能高效利用 GPU 的计算单元或减小内存 IO 读写等。
以英伟达的芯片举例而言,针对 Multi-head Attention 这个关键模块,可以将其分解成 5 个 sub-kernel,最后使用一个 CUDA 函数封装实现,而需要说明的是,该5个Sub-kernel在CUDA函数中则是以串行的方式实现计算。如果切换为光学卷积处理器OCPU则能够同时执行多内核并行卷积运算(这里可以完全对等的把5个子函数进行并行计算)。而每个时隙执行的MAC操作数则与其并行模块数量相等。因此,具有5个并行内核的 OCPU 的总计算速度为每秒 5×4fb = 20fb MAC 操作。并且,一个端口的MAC操作的计算速度与内核中的元素数量成线性正比,并且OCPU的整体计算能力随着并行规模的增加呈二次方增长。
实践证明,如果采用光学卷积处理单元,计算前端用基于SiN的OCPU和电气全连接层共同构成CNN,可用于执行不同级数的分类运算,精度高达为92.17 %。
2、内存管理优化
传统的智驾芯片在应用过程中需要在内存管理上进行了大量优化工作。涉及到Transformer而言,需要分别预先分配单独的 GPU 内存。
整个内存优化方法包括:内存 Sharing、内存 Caching、内存 Pre-alloation。整个过程优化是为了节省 Encoder 在运行过程中所占用的内存,使得支持更大的Batch Size 输入数据。将 Decoder 的部分中间层输出在 GPU 内存上缓存起来,保留已经计算过的 Beam Search 路径。当需要更新路径的时候,不需要重复计算已经计算过的路径。此外,为了避免重复申请删除 GPU 内存所带来的巨大开销,设计根据服务所可能出现的最大 Batch Size 和序列长度对每个模块的内存进行预先分配。
光子器件由于其互连损耗低,可以克服电器件的带宽及内存交换损耗瓶颈,实现高达10THz的超高计算带宽。而基于光子器件构建的光学神经网络(ONN)则被认为是下一代神经形态硬件处理器的研究方向。在光学神经网络中,通过光传输数据的同时实现了数据处理,实际上实现了运算即存储,该过程中不再单独考虑内存管理对整个运算过程的资源消耗,从而有效避免了冯诺依曼计算范式中的数据潮汐式传输。因此,对于自动驾驶系统计算中要求的高速、大规模和高并行光学神经网络是非常优质的选择方向。
3、通用矩阵乘法GEMM 配置优化
Transformer 架构中有很多线性层采用通用矩阵乘加法Cublas GEMM 来实现,最典型的就是卷积运算。Cublas GEMM 有很多不同的实现方案,在矩阵相乘速度和误差上各不相同,因此需要根据不同的矩阵相乘维度定位出最后的 GEMM 的配置参数,在误差可控的情况下获得最快运算速度。由于 GEMM 维度取决于输入数据的 Batch Size 和序列长度,实际应用中可以扫描出可能出现的不同 Batch Size 和序列长度所对应的所有 GEMM 矩阵相乘的配置参数,存入查找表中,在实际应用的时候依据输入数据的 Batch Size 和序列长度加载最优的配置参数。
实际上,这种Batch Size的切片模式和上文提到的光学卷积处理模式不谋而合。光学卷积网络要求首先输入图像切片到多个子图像,并将这些子图像展平为一维 (1D) 向量,最后利用三个2×2相关实值核(其由两个多模干扰单元和四个移相器组成)进行有效的并行卷积计算。尽管卷积核是相互关联的,但数据库中所存储的匹配训练图像可以执行不同级数的分类运算。这样的设计相对于计算规模的线性可扩展性将有望转化为大规模集成计算,整个运算过程将得到很好的简化。
4、写在最后
深度学习在极其重视以视觉检测为主的高阶自动驾驶中的重要性早已经不言而喻。而其中,大量乘加运算的卷积计算作为一种简单的线性平移不变运算,被广泛应用于图像处理的各个领域,其衍生出的卷积神经网络更是在人工智能领域中大放异彩。卷积神经网络(CNN)则是深度学习的一个重要类别,常用于图像识别,可大大降低网络复杂度并可实现高精度预测。
光计算已被证明可以显着提高处理速度和能源效率。然而,大多数现有的光学计算方案很难扩展,因为光学元件的数量通常随计算矩阵大小呈二次方增加。本文提到的在低损耗氮化硅平台上制造的紧凑片上光学卷积处理单元,可以展示出其大规模集成的能力。此外,中科院最新研发的光学卷积处理器OCPU中的组件随着计算矩阵的大小线性增长(N个输入维度N个单位),为OCPU的片上实现提供了坚实的潜力,具有更强的计算能力、更高的处理速度和更低的功耗,非常适用于下一代高阶智能驾驶计算平台要求。
作者 | Jessie
出品 | 焉知










![[工具推荐] LICEcap 动图gif录制工具 轻量/开源/免费](https://img-blog.csdnimg.cn/5f739b3970424fb2884d64e6a78d6b24.png)