特殊类
1. 不能被拷贝的类
注意, 是不能被拷贝的类, 不是不能拷贝构造的类.
思路就是 了解什么时候 会以什么途径 发生拷贝, 然后将路堵死.
拷贝发生一般发生在 拷贝构造 和 赋值重载
所以, 只要把类的这两个成员函数堵死, 此类就不能拷贝了
-
C++98在C++11之前, 可以通过这种方法 设计不能拷贝的类:
class CopyBan { public: // ... CopyBan() {} private: CopyBan(const CopyBan&); CopyBan& operator=(const CopyBan&); //... };这个类, 将 拷贝构造函数 和 赋值重载函数 设置为
private, 并且只声明不实现.此时 这个类对象就无法被拷贝.
int main() { CopyBan cB1; CopyBan cB2(cB1); CopyBan cB3 = cB1; CopyBan cB4; cB4 = cB1; return 0; }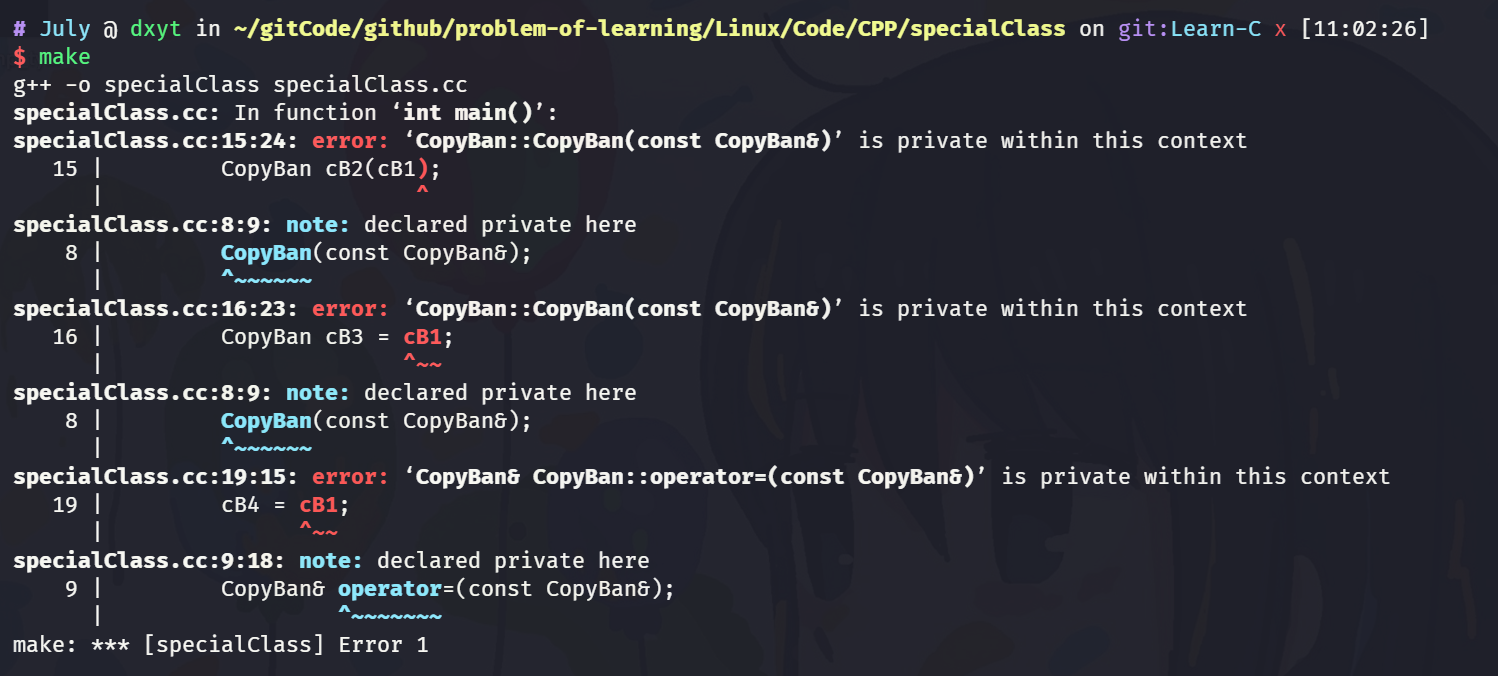
需要设置为
private. 因为 如果设置为public, 那么函数实现是可以在类外完成的. 如果有人在类外实现了拷贝构造和赋值重载. 那么此类还是可以完成拷贝 -
C++11C++11 提出了
delete关键词的扩展用法, 在类的默认成员函数后加上= delete, 表示删除此默认成员函数.自然 就可以直接使用
= delete来堵死拷贝途径class CopyBan { public: // ... CopyBan() {} CopyBan(const CopyBan&) = delete; CopyBan& operator=(const CopyBan&) = delete; };即使设置为
public也可以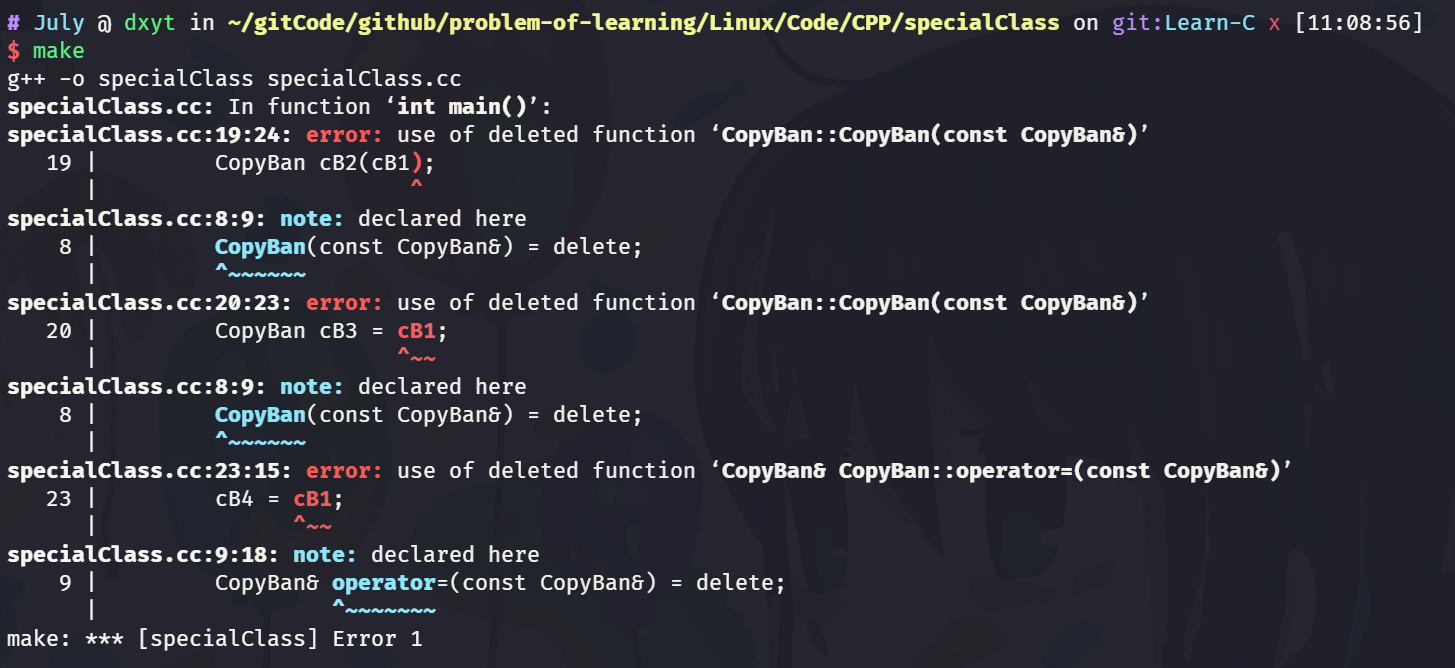
2. 只能在堆上创建的类
怎么设计只能在堆上创建的类?
只能在堆上创建, 也就是说 类的对象只能通过new创建.
而 一般情况下, 创建类 可以调用 构造函数 和 拷贝构造函数
怎么才能让对象只能通过new获得呢?
如果还需要保证实例化对象时语句的用法与创建普通对象一致. 那做不到.
只能在堆上创建, 那就针对创建对象就 只提供一个默认在堆上创建对象的接口, 并 把其他实例化对象的接口封死
实现如下:
class HeapOnly {
public:
static HeapOnly* CreateObj() {
return new HeapOnly;
}
HeapOnly(const HeapOnly&) = delete;
private:
// 构造函数私有
HeapOnly() {}
};
我们实现了一个static的成员函数CreateObj(), 会new一个HeapOnly对象并返回.
并且, 将 构造函数设置为私有, 还删除了拷贝构造函数, 使此类不能在外面调用构造函数实例化对象, 更不能拷贝构造.
int main() {
HeapOnly h1;
static HeapOnly h2;
HeapOnly* ph3 = new HeapOnly;
HeapOnly copy(*ph3);
return 0;
}
此时, 此类就不能再用传统的方式实例化了:
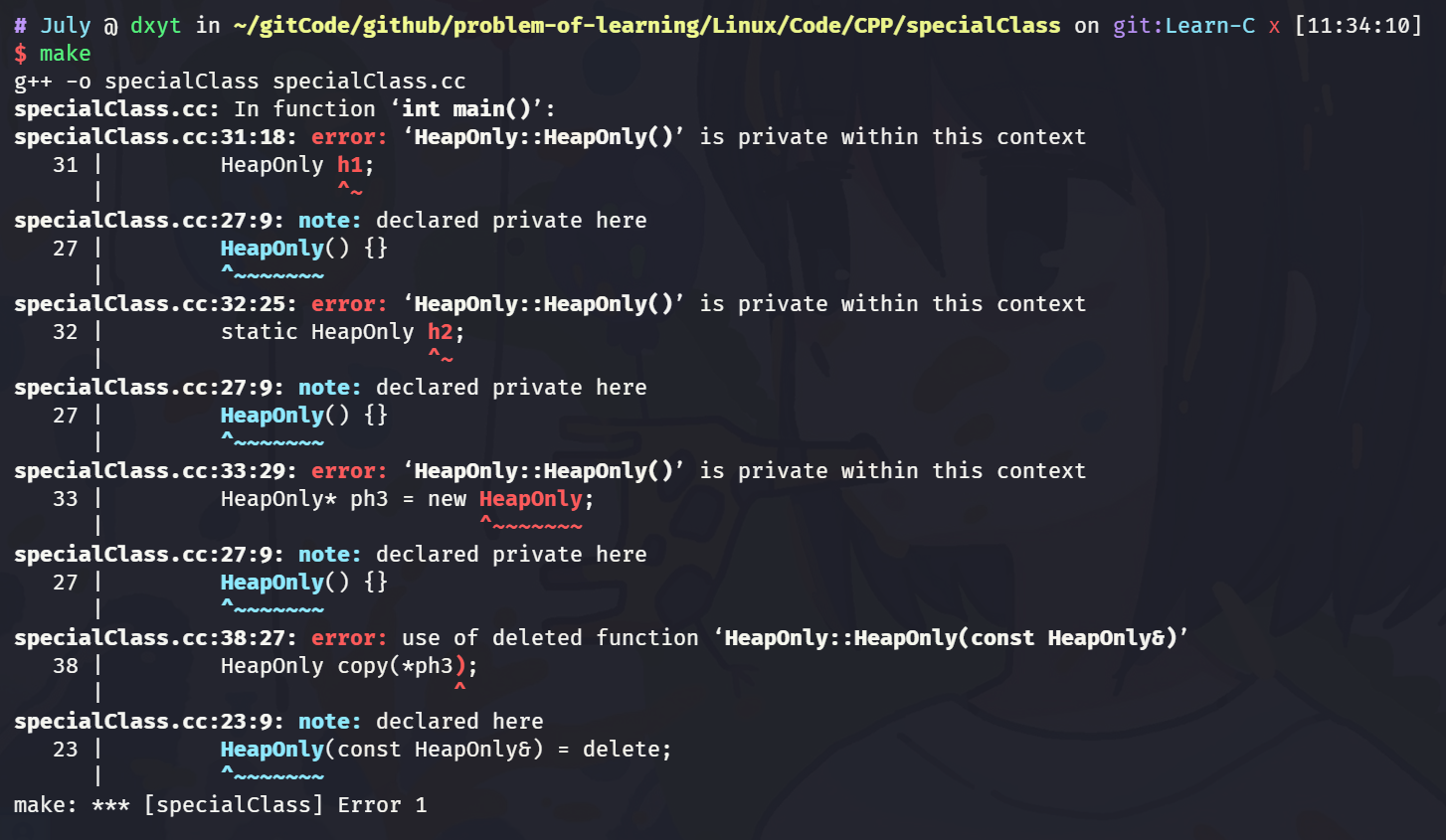
而是只能通过调用static成员函数CreateObj(), 创建在堆上的对象:
int main() {
HeapOnly* ph4 = HeapOnly::CreateObj();
HeapOnly* ph5 = HeapOnly::CreateObj();
delete ph4;
delete ph5;
return 0;
}
这段代码 就可以编译通过了:

只能在堆上创建的类, 还有一种实现方式, 就是 删除掉析构函数.
因为 在栈上或全局/静态存储区域上实例化的对象 会在超出作用域时自动调用析构函数自动销毁, 且无法通过 delete 关键字来手动销毁, 所以 删除析构函数 编译器就会禁止在栈上或静态区实例化对象.
3. 只能在栈上创建的类
只能在栈上创建, 也就表示不能使用new. 还有一个细节, 那就是也不能在静态区创建.
那么, 就只能按照上面 只能在堆上创建的类 的方法进行实现.
class StackOnly {
public:
static StackOnly CreateObj() {
return StackOnly();
}
StackOnly(const StackOnly&) = delete;
private:
// 构造函数私有
StackOnly() {}
};
这样此类, 就只能通过 调用static成员函数CreateObj()实例化对象.
传统的实例化方式都不再支持:
int main() {
StackOnly stO1;
StackOnly* stO2 = new StackOnly;
StackOnly stO3(stO1);
return 0;
}
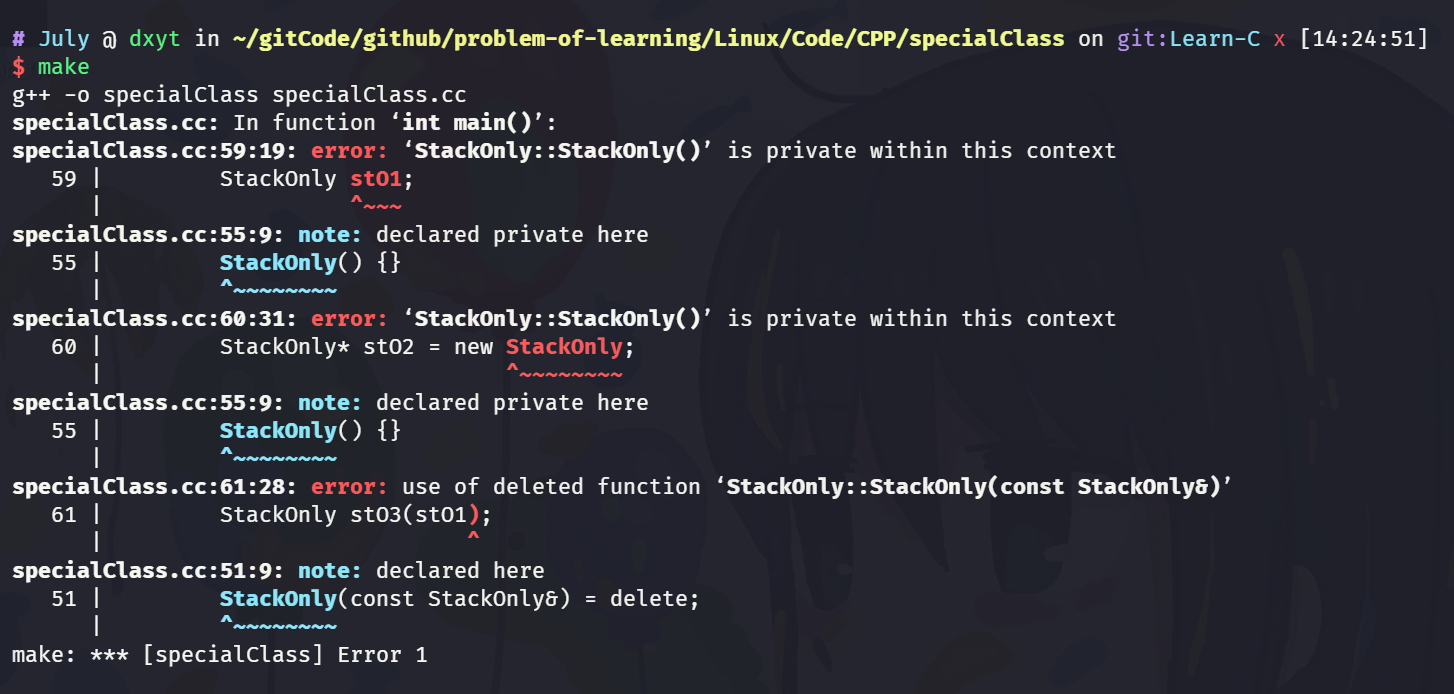
只能调用 创建接口:
int main() {
StackOnly stO1 = StackOnly::CreateObj();
StackOnly::CreateObj();
return 0;
}

其实这里有一些问题:
-
为什么要
delete掉拷贝构造函数?因为, 需要保证类对象只能创建在栈上. 如果不
delete掉拷贝构造函数, 就可能这样实例化对象:static StackOnly stO2(stO1);这样创建的话, 创建出来的对象会在静态区而不是栈区
所以, 需要
delete掉拷贝构造函数 -
CreateObj()是传值返回, 返回一个对象 不是应该需要调用拷贝构造函数吗? 拷贝构造函数不是删除了吗?正常返回一个对象是应该调用拷贝构造函数创建临时对象没错, 就像这样:
static StackOnly CreateObj() { StackOnly st; return st; }这样会尝试去调用拷贝构造, 然后发生错误:
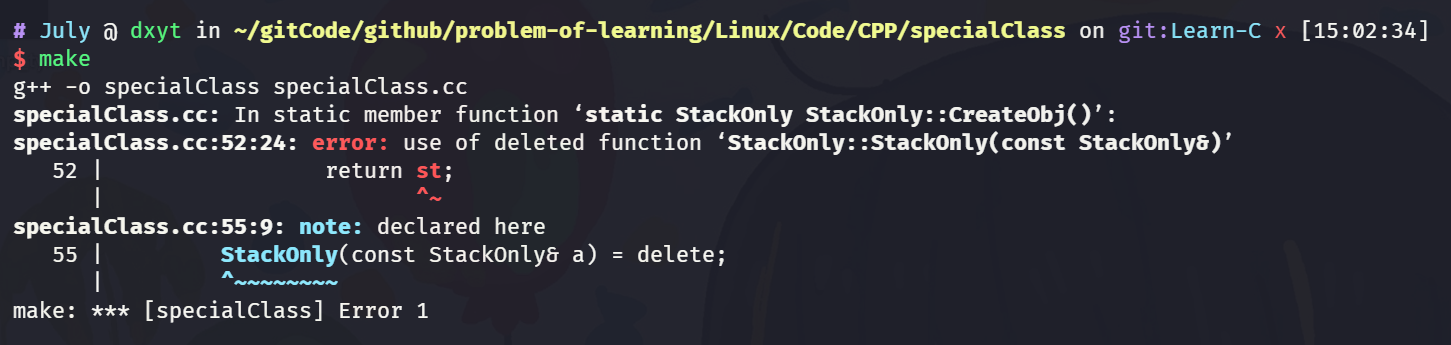
但是, 我们使用的
CreatObj()是这样返回的return StackOnly();调用构造函数构造匿名对象然后再传值返回. 这个过程
编译器会做一些优化的这个 构造+拷贝的过程, 会被优化为 构造. 所以 才能正常执行
谈到 只能在栈上创建的类, 还有人会想到 delete掉 类的operator new和operator delete专属重载函数.
因为禁掉之后, 此类就没有办法使用new创建对象了, 但是需要注意一点的是 禁掉了new的使用, 只是不让类对象创建在堆上, 而不是实现让类对象只能创建在栈上
比如, static StackOnly sto, 也没有使用new 但他 也没有在栈上创建, 而是在静态区
4. 不能继承的类
不能继承的类也很简单:
-
C++98
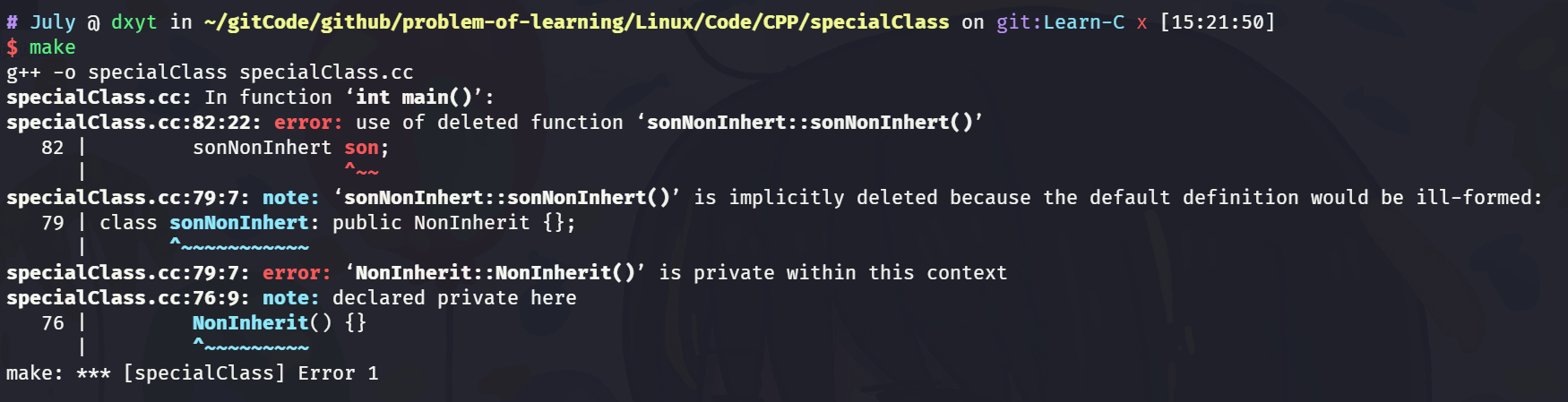
class NonInherit { public: static NonInherit GetInstance() { return NonInherit(); } private: NonInherit() {} };只将构造函数设置为
private就可以实现 子类无法实例化对象.也可以算是 不能被继承.
-
C++11
C++11更简单了:
class NonInherit final {};只需要一个关键词, 就表示此类是最终的, 无法被继承:

5. 单例模式 - 只能创建一个实例对象的类
在介绍单例模式之前, 先解释一下什么是 设计模式
怎么理解设计模式呢? 设计模式 实际是一套被反复使用、多数人知晓的、经过分类的、代码设计经验的总结
使用设计模式有很多的优点:
首先就是 提供了一种标准化的思考方式, 可以帮助开发者更好地理解、分析和解决软件设计问题
设计模式还可以提高代码的可读性、可维护性和可扩展性, 使软件更易于维护和更新…
被人熟知的设计模式有 23种, 不过本篇文章只介绍一种: 单例模式
单例模式
那么, 究竟什么是单例模式呢?
一个类只能创建一个实例对象, 即单例模式. 该模式可以保证系统中(一个进程种)该类只有一个实例对象, 并提供一个访问它的全局访问点, 该实例对象被所有程序模块共享.
说白了, 单例模式也是一种特殊类: 只能创建一个实例对象的类
不过, 单例模式的实现 根据创建对象的实际不同 一般分为两种方式:
饿汉模式
饿汉模式, 是指 在进程启动时 就创建这唯一的一个实例对象(单例对象). 就像 一个饿极了的人看到食物就去吃一样.
那么, 该如何实现呢?
单例模式, 只能创建一个实例对象.
那么 首先就应该把构造函数设置为private的, 用来防止在外部调用构造函数实例化其他对象.
还要防止通过拷贝构造或者赋值重载创建新的对象.
class Singleton {
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
};
这样实现了禁止从外部创建新的对象.
为确保整个进程都可以访问到唯一的实例对象, 需要创建一个static成员变量来存储单例对象:
class Singleton {
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton _instance; // 声明
};
而且, 饿汉模式要求 在进程打开时就创建唯一的实例对象, 所以创建的操作需要在main函数外面实现:
class Singleton {
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton _instance; // 声明
};
Singleton Singleton::_instance;
为了使整个进程都可以访问到单例对象, 还需要提供一个static成员函数 用来获取单例对象:
class Singleton {
public:
static Singleton* getInstance() {
return &_instance;
}
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton _instance; // 声明
};
// 定义
Singleton* Singleton::_instance;
至此, 一个最简单的饿汉单例模式 就实现了.
介绍到这里, 可能最大的问题就是: static Singleton _instance; 这个静态的成员对象.
为什么可以在类内部定义一个此类的对象?
在内部定义一个此类的对象当然是不行的.
但是这里 用static修饰了, 那么 这个对象本质上就不是类成员的一部分, 而是一个静态的全局对象.
为什么不直接在类外定义, 而是需要现在类内声明一下?
因为 此类的构造函数是私有的, 只有在类内才可以调用. 所以 要把这个对象声明在类内, 这样就可以在类外定义对象.
那么这就是一个简单的饿汉的单例模式, 进程的任何地方, 都可以通过 SingleTon::getInstance() 获取单例对象:
#include <ostream>
class Singleton {
public:
static Singleton* getInstance() {
return &_instance;
}
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton _instance; // 声明
};
// 定义
Singleton Singleton::_instance;
void func1() {
std::cout << "func1" << std::endl;
Singleton* singleT4 = Singleton::getInstance();
Singleton* singleT5 = Singleton::getInstance();
std::cout << singleT4 << std::endl;
std::cout << singleT5 << std::endl;
}
int main() {
Singleton* singleT1 = Singleton::getInstance();
Singleton* singleT2 = Singleton::getInstance();
Singleton* singleT3 = Singleton::getInstance();
std::cout << singleT1 << std::endl;
std::cout << singleT2 << std::endl;
std::cout << singleT3 << std::endl;
func1();
return 0;
}

饿汉模式的单例对象, 是在进程没有进入到main函数时就已经创建了的.
声明在类域中的 静态的用来存储单例对象的对象, 还可以以指针的形式声明和定义:
class Singleton { public: static Singleton* getInstance() { return _instance; } private: Singleton() {} Singleton(const Singleton&) = delete; Singleton& operator=(const Singleton&) = delete; static Singleton* _instance; // 声明 }; // 定义 Singleton* Singleton::_instance = new Singleton;不过, 对应的
getInstance()的返回值也需要变化一下.
懒汉模式
饿汉模式, 是指 在进程启动时 就创建单例对象
那么懒汉模式呢?
我们已经知道了, 单例模式需要在类域内声明一个static类对象或类指针对象来存储单例对象, 还需要一个static成员函数getInstance()来获取单例对象
那么, 懒汉模式, 是指 在首次执行getInstance()函数时, 才创建单例对象
懒汉模式的实现 与 饿汉模式的实现思路大致相同, 只有创建实例单例对象的时机不同:
class Singleton {
public:
static Singleton* getInstance() {
if (_instance == nullptr) {
_instance = new Singleton();
}
return _instance;
}
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton* _instance; // 声明
};
// 定义
Singleton* Singleton::_instance = nullptr;
与饿汉 唯一的区别好像就是, 在调用getInstance()时才实例化单例对象.
使用指针类型存储单例对象时, 此时的单例对象是new出来的, new出来的对象必须调用delete才会调用析构函数. 不然进程结束 操作系统会直接释放掉整个进程所使用的内存.
而某些需求是需要单例对象析构时实现的, 如果不使用delete 来调用单例对象的析构函数, 需求就无法完成.
所以, 可以 以RAII思想实现一个内嵌的垃圾回收机制:
class Singleton {
public:
static Singleton* getInstance() {
if (_instance == nullptr) {
_instance = new Singleton();
}
return _instance;
}
class CGarbo {
public:
// CGarbo的析构函数会 delete 单例对象
// 然后会调用 Singleton的析构函数, 完成需求
~CGarbo(){
if (_instance)
delete _instance;
}
};
// 定义一个静态成员变量,程序结束时,系统会自动调用它的析构函数从而释放单例对象
static CGarbo Garbo;
private:
Singleton() {}
~Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton* _instance; // 声明
};
// 定义
Singleton* Singleton::_instance = nullptr;
CGarbo Singleton::Garbo;
饿汉与懒汉模式 合适场景
饿汉模式:
适合场景: 如果单例对象 在多线程高并发环境下频繁使用, 性能要求较高, 那么使用饿汉模式可以避免资源竞争, 提高响应速度
不适合场景: 如果单例对象的构造十分耗时 或者 占用很多资源, 比如: 加载插件、初始化网络连接、读取文件等等. 如果这时还用饿汉模式 在程序一开始就进行初始化, 就会导致程序启动时非常的缓慢. 并且, 如果存在多个饿汉式单例模式, 那么单例对象的实例化顺序就会不确定
懒汉模式:
上面 饿汉模式的不适合场景, 就是懒汉模式的适合场景.
适合场景: 如果单例对象的构造十分耗时 或者 占用很多资源, 也没有必要在程序启动时就全部加载, 那就可以使用懒汉模式(延迟加载)更好. 如果有多个懒汉式单例模式, 也可以控制单例对象的实例化顺序.
不适合场景: 但是, 多线程高并发的场景下, 懒汉模式有一个问题就是 可能多线程会同时getInstance(), 如果同时整个进程的第一次执行, 那么可能会造成数据混乱, 所以 实际的 getInstance()实现中 需要加锁.
如果加了锁, 就可能在多线程高并发场景下产生资源竞争, 影响效率. 这算是饿汉模式的小问题.