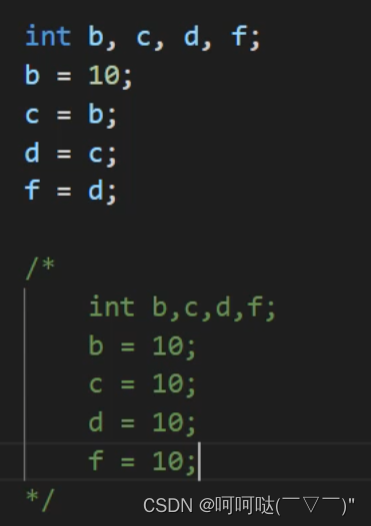
目录
一、引言
1.1 目的
1.2 意义
二、遗传算法介绍
2.1 遗传算法的基本思想
2.2 遗传算法与其他算法的主要区别
2.3 基于Java的遗传算法设计思想
三、遗传算法的具体实现
3.1 系统功能模块图和说明
3.2 代码和说明
3.2.1 初始化
3.2.2 选择运算
3.2.3 交叉运算
3.2.4 变异运算
3.2.5 主函数
四、系统测试
4.1 测试环境
4.2 测试步骤
4.3 系统运行结果
五、遗传算法总结
一、引言
一个程序员一生中可能会邂逅各种各样的算法,但总有那么几种,是作为一个程序员一定会遇见且大概率需要掌握的算法。今天就来聊聊这些十分重要的“必抓!”算法吧~,就比如说遗传算法啊
1.1 目的
主要用java语言实现了遗传算法,求x12 + x22的最大值。主要对于以往的参数范围是比较固定,因此打算做一个可以自定义设定参数范围,可以自主设置每一代群体的数量,一样可以设置迭代次数。
1.2 意义
可以探究遗传算法求最大值时参数范围及迭代次数和群体数量对于求最大值时造成影响的关系大小。
二、遗传算法介绍
2.1 遗传算法的基本思想
遗传算法(Genetic Algorithms, GA)是模拟达尔文生物进化论的自然选择,遗传学机理的生物进化过程的计算模型是一种通过模拟自然进化过程搜索最优解的方法。
一个种群则由经过基因(gene)编码(coding)的一定数目的个体(individual)组成。

遗传算法是从代表问题可能潜在解集的一个种群(population)开始的。
人类细胞有23对染色体(22对常染色体和一对性染色体),即每个细胞共有46个染色单体。
染色体作为遗传物质的主要载体,即多个基因的集合
染色体其内部表现(即基因型)是某种基因组合,它决定了个体形状的外部表现
如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的
初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解。
在每一代,根据问题域中个体的适应度大小挑选个体,并借助于自然遗传学的遗传算子进行组合交叉和变异,产生出代表新的解集的种群。
这个过程将导致种群像自然进化一样的后代种群比前代更加适应于环境,末代种群中的最优个体经过解码,可以作为问题近似最优解。
2.2 遗传算法与其他算法的主要区别
- 自组织、自适应和自学习性(智能性)
- 应用遗传算法求解问题时,在编码方案、适应度函数及遗传算子确定后,算法将利用进化过程中获得的信息自行组织搜索。由于基于自然的选择策略为“适者生存,不适应者被淘汰”,因而适应度大的个体具有较高的生存概率。适应度大的个体具有更适应环境的基因结构,再通过基因重组和基因突变等遗传操作,就可能产生更适应环境的后代。
- 遗传算法的本质并行性,遗传算法按并行方式搜索一个种群数目的点,而不是单点。它的并行性表现在两个方面:
一是遗传算法是内在并行的,即遗传算法本身非常适合大规模并行。最简单的并行方式是让几百甚至数千台计算机各自进行独立种群的演化计算,运行过程中甚至不进行任何通信,等到运算结束时才通信比较,选取最佳个体。
二是遗传算法的内含并行性。由于遗传算法采用种群的方式组织搜索,因而可同时搜索解空间内的多个区域,并相互交流信息。
使用这种搜索方式,虽然每次只执行与种群规模n成比例的计算。但实质上已进行了大约O(n3)次有效搜索,这就使遗传算法能以较少的计算获得较大的收益。
遗传算法不需要求导或其他辅助知识,而只需要影响搜索方向的目标函数和相应的适应度函数。
- 遗传算法强调概率转换规则,而不是确定的转换规则。
- 遗传算法可以更加直接地应用。
- 遗传算法对给定问题,可以产生许多的潜在解,最终选择可以由使用者确定
- 在某些特殊情况下,如多目标优化问题不止一个解存在,有一组最优解。
2.3 基于Java的遗传算法设计思想
首先应当分为两个类,一个类包含遗传算法所需的各种变量,比如说,x1,x2两个参数、迭代次数、群体数组、选择次数、所求出的最大解、群体适应度及其占比、参数群体的二进制字符串等等,这些都是在实现遗传算法时所需要用到的变量,因此我们应当把这些变量单独放出一个类中,当需要用到时,直接调用即可。
第二个类就是遗传算法的实现类,该类应当包含整个遗传算法所需要的各种方法。比如说,参数初始化函数,主要用来进行输入,确定参数的取值范围和迭代次数和群体数量这些都是需要我们去自定义输入的,还包括了计算适应度函数,计算每一个个体对应的适应度是多少,还有选择运算,根据每个个体的适应度进行选择,这里可以采取轮盘赌的方法去进行选择。还应当包括交叉算法,对选择后的个体进行交配,这里也应当是随机两两交配,更能体现达尔文的自然选择理论,交叉点也应当随机生成。最后变异算法必不可少,随机选择变异点进行变异,当然这里也应该存在不变异的情况,假设不变异的情况下变异点应当为-1。还应包括一下其他辅助方法,比如说十进制转化为二进制函数,二进制转化为十进制函数,选择运算结束之后需要进行重新布局的重新布局函数,打印群体及其二进制显示函数,判断是否找到最优解函数。
三、遗传算法的具体实现
3.1 系统功能模块图和说明
下图1是该算法的主要流程图。
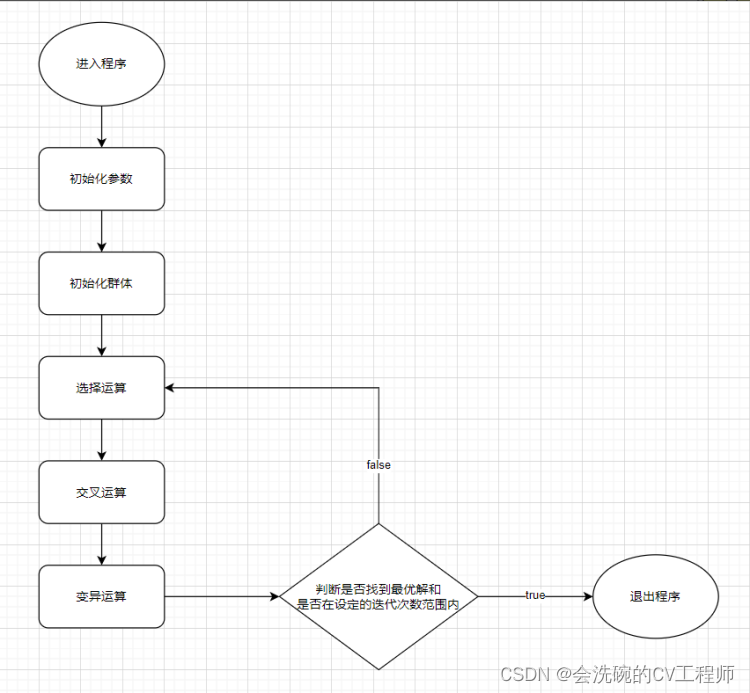
图 1 算法流程图
从算法流程图我们应该可以知道首先初始化参数,初始化参数完成之后,再根据输入的参数初始化群体,然后进行选择运算,对群体进行选择,然后进行交叉运算,随机生成交叉点,根据交叉点将个体两两随机分配进行交叉整合。最后再进行变异运算决定子代个体。如果没有找到最优解并且在迭代次数在设定的范围之内则重新进行选择,交叉,变异运算。
3.2 代码和说明
接下来详细解析系统流程图的每一个流程。
3.2.1 初始化
初始化分为两个初始化参数,下代码2很直观地显示了初始化的参数有,每一代的群体数量,两个参数的取值范围,还有迭代次数。
// 初始化参数最大值,群体
public static void xScan(){
// 输入参数范围
System.out.print("请输入每代的群体数量:");
xSize = scan.nextInt();
System.out.print("请输入X1的最大值:");
maxX1 = scan.nextInt();
System.out.print("请输入X2的最大值:");
maxX2 = scan.nextInt();
System.out.print("请输入迭代次数:");
iterations = scan.nextInt();
// 初始化群体
xx = new int[xSize][2];
strXX = new String[xSize];
}代码 2 参数初始化
代码3是群体初始化,群体初始化,这里我选择了十进制初始化,然后再计算每一个参数的二进制字符串的位数,这里主要是为了方便我控制台输出样式,与算法并无太大的关系。然后将群体转化成二进制字符串。
// 群体初始化
public static void initXX(){
System.out.println("-----随机初始化群体----");
for (int i=0;i<xSize;i++){
xx[i][0] = (int) (Math.random()*maxX1);
xx[i][1] = (int) (Math.random()*maxX2);
}
// 最大值的二进制字符串位数
countStrXSize();
// 群体二进制
strXXToBin();
// 打印群体
printXX();
}代码 3 群体初始化
3.2.2 选择运算
代码4是选择运算的主要代码,进行选择运算首先进行个体适应度计算及其占比情况,在每次进行选择之前都要重置个体被选择次数的数组,如果这里不重新创建的话,就会保留上一次的值,造成数据紊乱。这里我是根据轮盘赌法选择,比如说第一个个体占比30%,第二个个体占比70%,那么生成一个随机数,随机数小于或等于0.3的时候则第一个个体被选择,如果随机数的范围是大于0.3的话,则选择第二个个体。以此类推则完成了基于轮盘赌法的选择运算。
// 选择运算
public static void selectXX(){
System.out.println("----------进行选择运算----------");
// 先进行计算适应度及其占比情况
countSuitNum();
// 每次选择都要重置选择次数数组
selectTimes = new int[xSize];
// 轮盘赌法
for (int i=0;i<xSize;i++){
double per = Math.random();
for (int j=0;j<xSize;j++){
if(per<=xxSuitPoss[j]){
selectTimes[j] += 1;
break;
}
}
}
for (int i=0;i<selectTimes.length;i++){
xxSelectMap.put(i,selectTimes[i]);
System.out.println("个体编号:"+(i+1)+", ("+xx[i][0]+", "+xx[i][1]+")"+"\t适应度:"+xxSuitList.get(i)
+"\t占总数的百分比:"+String.format("%.2f",xxSuitMap.get(i).doubleValue())+"\t选择次数: "+xxSelectMap.get(i));
}
// 根据选择结果重新布局
refreshXX();
// 选择完更新二进制群体得十进制数
refreshXXTen();
}代码 4 选择运算
3.2.3 交叉运算
交叉算法的主要逻辑就是从个体数组索引随机生成一个不重复的数组,然后根据这个不重复数组首尾两两交配,达成一个伪随机两两交配的思想。然后将交配后的个体重新赋值回群体数组,这时候群体数组已经打乱,因此我们需要刷新十进制的群体数组。
// 交叉算法
public static void cross(){
System.out.println("---------进行交叉运算---------");
int ranArr[] = new int[xSize];
int arr[] = new int[xSize];
for(int i=0;i<xSize;i++){
arr[i] = i;
}
Random random = new Random();
for (int i=0;i<xSize;i++){
// 得到一个位置
int j = random.nextInt(xSize-i);
// 得到位置的数值
ranArr[i] = arr[j];
// 将最后一个未用的数字放到这里
arr[j] = arr[xSize-1-i];
}
for(int i=0;i<xSize/2;i++){
// 随机确定交叉点
int cross_x = (int) (Math.random()*(x1BinStrSize+x2BinStrSize));
System.out.print("配对情况:配对前:"+(ranArr[i]+1)+" = "+strXX[ranArr[i]]+" 和 "+(ranArr[xSize-1-i]+1)
+" = " + strXX[ranArr[xSize-1-i]]+"进行配对,交叉点:"+(cross_x+1)+"\t");
strXX[ranArr[i]] = strXX[ranArr[i]].replace("|","");
strXX[ranArr[xSize-1-i]] = strXX[ranArr[xSize-1-i]].replace("|","");
String str1 = strXX[ranArr[i]];
String str2 = strXX[ranArr[xSize-1-i]];
String str1_1,str1_2;
str1_1 = str1.substring(0,cross_x)+str2.substring(cross_x);
str1_2 = str2.substring(0,cross_x)+str1.substring(cross_x);
str1_1 = str1_1.substring(0,x1BinStrSize)+"|"+str1_1.substring(x1BinStrSize);
str1_2 = str1_2.substring(0,x1BinStrSize)+"|"+str1_2.substring(x1BinStrSize);
System.out.println("配对后:"+(ranArr[i]+1)+" = "+str1_1+", "+(ranArr[xSize-1-i]+1)+" = "+str1_2);
strXX[ranArr[i]] = str1_1;
strXX[ranArr[xSize-1-i]] = str1_2;
}
// 刷新十进制群体
refreshXXTen();
System.out.println("交叉后个体");
printXX();
}
代码 5 交叉算法
3.2.4 变异运算
代码6主要描述了变异运算的逻辑代码,首先对循环对每一个个体进行变异,至于变异,书上的是都会选择变异,而我这里仔细研读了达尔文的自然选择理论之后,认为是否变异也应当是随机的,不应该每一个子代都会发生变异。因此有0.5的概率不发生变异,变异点应当置-1。这里的逻辑是随机生成一个随机数,该随机数的范围是二进制显示个体字符串的长度的两倍,如果随机数小于个体二进制字符串长度的话,则在该随机数的点位上进行变异,也就是取反操作。0变1,1变0。如果随机数的数值大于个体二进制字符串的长度则不进行变异,变异点置-1。然后将得到的字符串重新赋值到群体二进制字符串数组里。因为群体二进制字符串数组发生改变,这里我们应当还要进行更新十进制数组。并且变异运算结束后,说明一代变异算法结束,代数+1。下图6则是变异算法的逻辑代码
// 变异算法
public static void variation(){
System.out.println("---------进行变异运算---------");
for (int i=0;i<xSize;i++){
// 随机选择变异点,当大于字符串范围时不进行变异
int var = (int) (Math.random()*(2*(x1BinStrSize+x2BinStrSize-1)))+1;
System.out.print("个体编号:"+(i+1)+"\t"+strXX[i]);
strXX[i] = strXX[i].replace("|","");
char [] strX = strXX[i].toCharArray();
if(var < strX.length) {
if (strX[var - 1] == '0') {
strX[var - 1] = '1';
} else {
strX[var - 1] = '0';
}
}
else{
var = -1;
}
strXX[i] = new String(strX);
strXX[i] = strXX[i].substring(0,x1BinStrSize)+"|"+strXX[i].substring(x1BinStrSize);
System.out.println("\t变异点:"+var+"\t变异结果:"+strXX[i]);
}
times++;
// 更新群体十进制数组
refreshXXTen();
System.out.println("\n---------------------第"+times+"代群体情况---------------------");
printXX();
}
代码 6 变异算法
3.2.5 主函数
根据上面的运算,及系统流程图,我们应该可以了解了遗传算法的一整个运算流程,首先初始化参数,然后初始化群体,然后进入选择运算,交叉运算,变异运算,最后判断是否找到最优解及是否大于设定的迭代范围,如果都没有,则重新进入选择运算,以此类推,主函数逻辑代码实现如下d代码7
public static void main(String[] args) {
// 初始化参数
xScan();
System.out.println("---------------------第"+times+"代群体情况---------------------");
// 初始化群体
initXX();
do {
// 选择运算
selectXX();
// 交叉运算
cross();
// 变异运算
variation();
}
while (!checkResult() && times<iterations);
}代码 7 主函数
四、系统测试
4.1 测试环境
Dell Inspiron 5509 Win10电脑,IntelliJ IDEA 2021.1 x64编译器。
4.2 测试步骤
首先来确定测试用例,测试用例应当包括,群体数量,参数取值范围,迭代次数。测试用例表如下:
表 1 测试用例
| 名称 | 群体数量 | x1的最大值 | x2的最大值 | 迭代次数 | 应当获得最优解 |
| 测试用例1 | 10 | 127 | 63 | 100 | 20098 |
| 测试用例2 | 10 | 127 | 63 | 200 | 20098 |
| 测试用例3 | 20 | 127 | 63 | 100 | 20098 |
| 测试用例4 | 50 | 127 | 63 | 100 | 20098 |
| 测试用例5 | 10 | 127 | 127 | 100 | 32258 |
| 测试用例6 | 10 | 63 | 127 | 100 | 20098 |
| 测试用例7 | 10 | 127 | 127 | 100 | 32258 |
| 测试用例8 | 10 | 127 | 63 | 100 | 20098 |
测试用例1和2是用来测试迭代次数对获得最优解的影响
测试用例3和4是用来测试群体对获得最优解的影响
测试用例5和6是用来测试参数x1对获得最优解的影响
测试用例7和8是用来测试参数x2对获得最优解的影响
4.3 系统运行结果
测试结果应当包含获得的最优解,实际最优解,是否提前获得最优解,获得最优解的代数
表 2 测试结果
| 测试用例结果 | 获得的最优解 | 实际最优解 | 是否提前获得最优解 | 获得最优解的代数 |
| 测试用例1 | 19729 | 20098 | 否 | 100 |
| 测试用例2 | 19973 | 20098 | 否 | 200 |
| 测试用例3 | 20098 | 20098 | 是 | 30 |
| 测试用例4 | 20098 | 20098 | 是 | 5 |
| 测试用例5 | 32005 | 32258 | 否 | 100 |
| 测试用例6 | 20098 | 20098 | 是 | 31 |
| 测试用例7 | 32005 | 32258 | 否 | 100 |
| 测试用例8 | 20098 | 20098 | 是 | 51 |
根据根据测试用例1和2的运行结果结果我们可以知道迭代次数多的时候,得到的最优解会更接近实际最优解;根据测试用例3和4的运行结果我们可以知道当群体数量更多的时候,可以更早获得最优解;综合测试用例5和6和测试用例7和8的运行结果我们可以知道当参数范围比较小的时候更容易获得最优解。
五、遗传算法总结
遗传算法是一种基于生物进化原理的优化算法,通过模拟生物进化过程中的遗传、变异和选择等机制,寻找最优解。它被广泛应用于各个领域的问题求解,如工程设计、组合优化、机器学习等。
遗传算法的应用场景包括但不限于:
优化问题:遗传算法能够有效地解决复杂的优化问题,如旅行商问题、背包问题等。它能够在搜索空间中进行全局搜索,找到近似最优解。
设计问题:遗传算法可以用于设计优化,如电路设计、结构设计等。通过对设计参数进行编码和演化,可以得到满足要求的设计方案。
机器学习:遗传算法可以作为一种优化方法用于机器学习算法的参数优化,如神经网络的权重优化、支持向量机的参数选择等。
调度问题:遗传算法可以用于调度问题的求解,如任务调度、车辆路径规划等。通过对调度方案进行编码和演化,可以得到最优的调度策略。
掌握遗传算法的种类和知识点对程序员来说至关重要。以下是一些程序员需要掌握的关键知识点:
遗传算法的基本原理:了解遗传算法的基本概念和运行原理,包括编码方式、适应度函数、选择、交叉和变异等操作。
编码方式:了解如何将问题的解空间映射到遗传算法的编码空间,选择合适的编码方式对问题进行建模。
适应度函数:设计适应度函数来评估个体的优劣程度,以指导遗传算法的搜索过程。
选择算子:了解不同的选择算子,如轮盘赌选择、锦标赛选择等,以及它们之间的优缺点。
交叉算子:学习如何通过交叉操作来生成新的个体,以增加种群的多样性和搜索空间的覆盖度。
变异算子:了解如何通过变异操作来引入新的基因信息,以避免陷入局部最优解。
参数设置和调优:掌握如何设置遗传算法的参数,并通过实验和调优找到合适的参数值,以提高算法的性能。
并行与分布式遗传算法:了解如何利用并行和分布式计算的方法来加速遗传算法的执行效率。
鼓励程序员积极学习和深入研究遗传算法领域。遗传算法作为一种强大的优化工具,在实际问题中发挥着重要的作用。通过学习和研究,程序员可以将遗传算法应用到自己的工作中,提高问题求解的效率和质量。此外,深入研究遗传算法还可以探索其改进和扩展,为解决更加复杂的问题提供新的思路和方法。