react16之后,react引入了fiber架构,那么它究竟是什么,如何实现的呢?下面就让笔者带你掰扯掰扯,如有错误,欢迎指正
目录
渲染过程
react15
react16
为什么要引入fiber
不可中断原因
fiber详解
是什么
为什么使用链表这种数据结构
结构
具体过程
1.调度阶段(schedule)
2.协调阶段(reconclie)
两颗fiberTree
workInprogressTree的构建
3.渲染阶段(commit)
渲染过程
想要深入了解fiber,我们就要先弄清楚react页面渲染的大致流程。
当调用render(初次渲染页面)或者setState(数据更新导致页面重新渲染)时候,会引发页面的渲染。
react15
react15把页面渲染分为了两个阶段:
1.协调/调和阶段(reconclie):在这个阶段 React 会更新数据生成新的 虚拟Dom树,然后通过Diff算法,递归整个(注意是整个!)虚拟Dom树找出需要更新的节点,放到更新队列中去,得到新的更新队列。该过程不可中断。
2.渲染阶段(commit):这个阶段 React 会遍历更新队列,将其所有的变更一次性更新到Dom上。
简单来说,一个负责找,另一个负责改。
react16
react16引入了fiber的概念,此时的页面渲染可以分为三个阶段:
1.调度阶段(schedule):调度任务的优先级,高优先级的先进入协调阶段。
2.协调阶段(reconclie):找出变化的节点,从不可中断的递归变成了可中断的循环过程,内部采用了fiber架构,react16就是把之前的stack reconlie(直到执行栈被执行空才会停止)重构成了fiber reconclie(可中断)。
3.渲染阶段(commit):将变更一次性更新到真实Dom上。
为什么要引入fiber
上面我们将react15和react16页面渲染的大致流程进行了讲解,我们会发现,最直观的差异就是:寻找变化节点的过程由不可中断变成了可以中断。
为什么要这样做呢?
浏览器js引擎和页面渲染引擎是在同一个渲染线程之内,两者是互斥关系。
当前有新的数据更新时候,我们需要递归整个虚拟Dom树,找出变动节点,如果其中dom节点过多,那么这个过程时间消耗的会很长,并且无法中断,所以会导致其他事件影响滞后,造成卡顿。
react15及之前版本:当有节点发生变动,会递归对比虚拟dom,找出变动节点,之后同步更新他们。这种遍历是递归调用,执行栈会越来越深,而且不能中断,中断后就不能恢复了。递归如果非常深,就会十分卡顿。
不可中断原因
react15中协调阶段不可中断原因:
简单来说,我们的Vnode(虚拟节点)中只存有子节点(childrenNode)的信息,如果我们打断了,是找不到它的父亲和兄弟节点的,所以就又得重头开始找。
fiber详解
是什么
fiber:直译 纤维,意在指比线程Thread更细小的执行粒度。
从整体上看,fiber就是把原本不可中断的协调过程碎片化,化整为零,每次执行完一个小任务,都会让出线程,给其他任务执行的机会。
从本质上看,fiber实际上是一种数据结构:特殊的链表。每个节点都是一个 fiberNode。一个 fiberNode包括了 child(第一个子节点)、sibling(兄弟节点)、return(父节点)等属性(解决了react15Vnode中只有子节点信息,信息不足导致无法中断的问题)。
react 会先把 vdom 转换成 fiber,再去进行 reconcile,这样就是可打断的了。
为什么使用链表这种数据结构
一句话总结就是:空间换时间。
相较于原来react15中虚拟Dom的顺序结构数据格式,好处:
1.操作更高效:调整指针指向即可。
2.有更多的信息:可以根据当前节点找到父节点、子节点、兄弟节点。
缺点:占用更多空间
结构
简单来说,fiberNode是虚拟dom节点经过处理之后生成的。fiberTree则是由fiberNode组成的。
fiber 节点结构如下:
{
type: any, // 对于类组件,它指向构造函数;对于DOM元素,它指定HTML tag
key: null | string, // 唯一标识符
stateNode: any, // 保存对组件的类实例,DOM节点或与fiber节点关联的其他React元素类型的引用
child: Fiber | null, // 大儿子
sibling: Fiber | null, // 下一个兄弟
return: Fiber | null, // 父节点
tag: WorkTag, // 定义fiber操作的类型, 详见https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactWorkTags.js
nextEffect: Fiber | null, // 指向下一个节点的指针
updateQueue: mixed, // 用于状态更新,回调函数,DOM更新的队列
memoizedState: any, // 用于创建输出的fiber状态
pendingProps: any, // 已从React元素中的新数据更新,并且需要应用于子组件或DOM元素的props
memoizedProps: any, // 在前一次渲染期间用于创建输出的props
// 还有很多,就不一一展示了
}
具体过程
1.调度阶段(schedule)
在这个阶段,会给每个任务一个优先级,具体点就是在创建或者更新 FiberNode 的时候,通过算法给每个任务分配一个到期时间(expirationTime)。在每个任务执行的时候除了判断剩余时间,如果当前处理节点已经过期,那么无论现在是否有空闲时间都必须执行该任务。过期时间的大小还代表着任务的优先级。
2.协调阶段(reconclie)
将原本react15调和阶段(reconclie)不可停止的大任务按照拆分成了若干小任务,一个任务对应一个节点。
两颗fiberTree
react中会存在两个fiberTree:
- 一个叫做workInprogressTree,指的是当前正在执行更新的fiberTree,在我们初次渲染/执行setState更新状态后,都会构建一个新的fiberTree,我们把它叫做workInprogressTree。
- 还有一棵fiber树叫做currentFiberTree,表示上次构建好的fiberTree。
在workInprogressTree构建的过程中,会和currentFiberTree进行diff比较(diff在这个阶段发生),把需要变动的fiberNode打上effectTag标记(记录操作的类型),之后收集到effectList中,最终生成一条副作用链effectList(具体作用见下文)
当更新完成以后,使用 workInprogressTree替换掉 currentFiberTree,作为下一次更新的currentFiberTree。
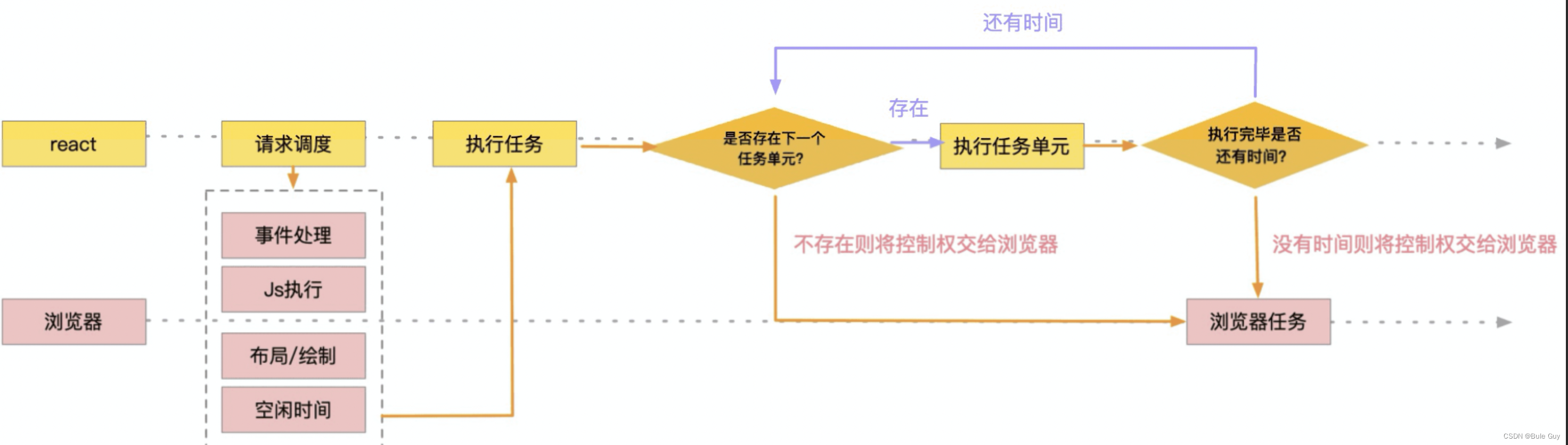
workInprogressTree的构建
workInprogressTree的构建实际上就是循环的执行任务和创建下一个任务。
在每次任务执行完毕之后,都会检查还有没有空闲时间,如果没有就把控制权交给浏览器,让浏览器干更重要的事,自己先暂时挂起来,如此循环往复(见下图)
我们常说的diff就发生在workInprogressTree构建的过程之中:
通过比较用于构建workInprogressTree中fiber节点的Vnode和currentFiberTree中的fiberNode,来决定如何为workInprogressTree创建fiberNode。
在workInprogressTree构建的过程中,生成fiber节点的方式有三种:
- 克隆(浅拷贝) currentFiber node,意味着原来的 dom 节点可以复用,只需要更新 dom 节点的属性,或者移动 dom 节点;
- 新建一个 fiberNode,意味着需要新增加一个 dom 节点;
- 直接复用 currentFiberTree的Node,表示对应的 dom 节点完全不用做任何处理;
3.渲染阶段(commit)
我们执行完协调阶段之后,就该执行渲染阶段了,就需要把变更更新到真实的dom上。
那么我们需要再遍历整个fiberTree去检查所有的effectTag吗?
不需要,此时我们的effectList就派上用场了,我们在协调阶段所有标记了effectTag的节点都会在effectLIst里面,我们只需要直接遍历它,然后根据对应的effectTag来执行对应的Dom操作就行了。
参考文章:
React Fiber很难?六个问题助你理解 React Fiber
对 React 实现原理的理解
走进React Fiber的世界



![buu-Reverse-[2019红帽杯]childRE](https://img-blog.csdnimg.cn/e1f0b735c2b94487b7d2752bdca005fd.png)