机器学习笔记之Transformer——Transformer模型架构基本介绍
- 引言
- 回顾:
- Transformer \text{Transformer} Transformer架构
- 关于架构的简单认识
- 多头注意力机制
- 包含掩码的多头注意力机制
- 基于位置信息的前馈神经网络
- 残差网络与层标准化操作
- 编码器的输出与信息传递
- 关于预测问题
引言
上一节介绍了自注意力机制的基本逻辑,并介绍了位置编码 ( Position Encoding ) (\text{Position Encoding}) (Position Encoding)。本节将介绍 Transformer \text{Transformer} Transformer的模型架构。
回顾:
简单理解: Seq2seq \text{Seq2seq} Seq2seq模型架构与自编码器
在
Seq2seq
\text{Seq2seq}
Seq2seq——基本介绍中提到,基于机器翻译任务的
Seq2seq
\text{Seq2seq}
Seq2seq结构主要包含两个部分:编码器
(
Encoder
)
(\text{Encoder})
(Encoder)与解码器
(
Decoder
)
(\text{Decoder})
(Decoder)。并且这两个部分分别使用独立的循环神经网络来实现输入序列与输出序列的序列长度不同的情况。

作为个人对编码器、解码器概念上的误区,在稀疏自编码器与变分自编码器中同样认识过编码器、解码器的概念。并且它们从原理上存在相似之处:
该部分属于个人理解,有不同见解的小伙伴欢迎交流讨论。
-
无论是稀疏自编码器还是变分自编码器,它们都是欠完备自编码器 ( Undercompleter AutoEncoder ) (\text{Undercompleter AutoEncoder}) (Undercompleter AutoEncoder)的一种改良——在不想单纯地将输入分布恒等映射到输出分布动机的基础上,希望隐变量 h h h能够学习到更多优质的特征信息;
同理,在 Seq2seq \text{Seq2seq} Seq2seq结构中,关于编码器的输出—— Context \text{Context} Context向量 C \mathcal C C,它本身就是一个固定大小的向量。虽然它的大小是单个时刻的序列信息,但实际上它包含了整个序列的序列信息。而在解码器中,有效的输入也仅有 C \mathcal C C,这是它们的相似之处。
无论是C \mathcal C C还是隐变量h h h,它们自身是‘不完整/缺失’的,但它们表示的序列信息是丰富的。
它们的不同之处也很明显:
- 基于欠完备自编码器的动机,在设计策略(损失函数) 的过程中,不仅对真实分布
x
x
x与重构分布
f
[
g
(
x
)
]
f[g(x)]
f[g(x)]进行约束,并且还对隐变量
h
h
h进行稀疏性角度的约束:
L [ x , g ( f ( x ) ) ] + Ω ( h ) h = f ( x ) \mathcal L[x,g(f(x))] + \Omega(h) \quad h = f(x) L[x,g(f(x))]+Ω(h)h=f(x)
无论是稀疏自编码器还是变分自编码器,它们都使用了 KL \text{KL} KL散度对 隐变量进行了约束:
其中ρ j ^ \hat {\rho_j} ρj^表示隐藏层第j j j个神经元输出h j h_j hj的期望结果。而ρ \rho ρ表示人为设置的关于h h h的‘先验信息’。
{ Sparse AutoEncoder : J S p a r s e ( W , b ) = L [ x , g ( f ( x ) ) ] + Ω ( h ) = J ( W , b ) + β ⋅ ∑ j = 1 K KL ( ρ ∣ ∣ ρ j ^ ) Variational AutoEncoder : J V A E = E Q ( h ∣ x ; ϕ ) [ log P ( x ∣ h ; θ ) ] − KL [ Q ( h ∣ x ; ϕ ) ∣ ∣ P ( h ) ] \begin{cases} \begin{aligned} \text{Sparse AutoEncoder : }\mathcal J_{Sparse}(\mathcal W,b) & = \mathcal L[x,g(f(x))] + \Omega(h) \\ & = \mathcal J(\mathcal W,b) + \beta \cdot \sum_{j=1}^{\mathcal K} \text{KL}(\rho ||\hat {\rho_j}) \\ \text{Variational AutoEncoder : }\mathcal J_{VAE} & = \mathbb E_{\mathcal Q(h \mid x;\phi)} \left[\log \mathcal P(x \mid h;\theta)\right] - \text{KL} [\mathcal Q(h \mid x;\phi) || \mathcal P(h)] \end{aligned} \end{cases} ⎩ ⎨ ⎧Sparse AutoEncoder : JSparse(W,b)Variational AutoEncoder : JVAE=L[x,g(f(x))]+Ω(h)=J(W,b)+β⋅j=1∑KKL(ρ∣∣ρj^)=EQ(h∣x;ϕ)[logP(x∣h;θ)]−KL[Q(h∣x;ϕ)∣∣P(h)]
相反, Seq2seq \text{Seq2seq} Seq2seq的目标函数仅仅是一个对生成结果取均值的极大似然估计,它并没有单独对中间变量 C \mathcal C C直接构建策略进行约束:
arg max θ log P ( Y ∣ X ) = arg min θ − 1 N ∑ n = 1 N log P ( y n ∣ x n ) \mathop{\arg\max}\limits_{\theta} \log \mathcal P(\mathcal Y \mid \mathcal X) = \mathop{\arg\min}\limits_{\theta} -\frac{1}{N} \sum_{n=1}^N \log \mathcal P(y_n \mid x_n) θargmaxlogP(Y∣X)=θargmin−N1n=1∑NlogP(yn∣xn)
自注意力机制
自注意力机制 (Self-Attention) \text{(Self-Attention)} (Self-Attention)的核心包含两点:
- 使用缩放点积
(Scaled Dot-Product)
\text{(Scaled Dot-Product)}
(Scaled Dot-Product)的方式计算注意力分数
(
Attention Score
)
(\text{Attention Score})
(Attention Score):
a ( Q , K ) = [ Q K T d ] N × M { Q ∈ R N × d K ∈ R M × d a(\mathcal Q,\mathcal K) = \left[\frac{\mathcal Q\mathcal K^T}{\sqrt{d}}\right]_{N \times \mathcal M} \quad \begin{cases} \mathcal Q \in \mathbb R^{N \times d} \\ \mathcal K \in \mathbb R^{\mathcal M \times d} \end{cases} a(Q,K)=[dQKT]N×M{Q∈RN×dK∈RM×d
其中 N , M N,\mathcal M N,M分别表示序列 Q , K \mathcal Q,\mathcal K Q,K的长度,并且它们中的每一个元素均使用 d d d维特征进行表示。 - 在第
1
1
1点的基础上,自注意力机制将
Q
,
K
\mathcal Q,\mathcal K
Q,K设置成完全相同的事物。在后续的注意力映射中,被映射的信息
V
\mathcal V
V同样与
Q
,
K
\mathcal Q,\mathcal K
Q,K完全相同:
{ Q , K , V ⇒ X ∈ R T × d Y ∈ R T × d = Softmax { [ X X T d ] T × T } ⋅ [ X ] T × d \begin{cases} \mathcal Q,\mathcal K,\mathcal V \Rightarrow \mathcal X \in \mathbb R^{\mathcal T \times d} \\ \quad \\ \mathcal Y \in \mathbb R^{\mathcal T \times d} =\text{Softmax} \left\{\begin{aligned}\left[\frac{\mathcal X \mathcal X^T}{\sqrt{d}}\right]_{\mathcal T \times \mathcal T}\end{aligned}\right\} \cdot [\mathcal X]_{\mathcal T \times d} \end{cases} ⎩ ⎨ ⎧Q,K,V⇒X∈RT×dY∈RT×d=Softmax{[dXXT]T×T}⋅[X]T×d
通过上述的自注意力过程以及自注意力结果 Y \mathcal Y Y的格式,可以判断出:序列 X \mathcal X X内的每个元素分别与 X \mathcal X X的所有元素均计算了注意力分数,并将元素对应的分数结果累加并映射在了对应元素中。
我们不否认序列 X \mathcal X X中的每个元素都得到了它们对应的注意力信息;但同样存在另一个问题:序列 X \mathcal X X中某元素与所有元素(含自身)所产生的 T \mathcal T T个注意力分数之间是离散的;
我们在使用压缩点积计算注意力分数时,仅仅使用到了各元素对应的 d d d维表示;也就是说:如果对序列 X \mathcal X X中的元素打乱顺序,并不会影响注意力分数结果。但序列的顺序同样是序列的重要特征。例如:如果将一个文本句子打乱了词的顺序,该句子的语义信息会发生剧烈变化甚至丢失。但仅仅是自注意力机制感应不到这种变化。
在序列中添加位置编码
(Position Encoding)
\text{(Position Encoding)}
(Position Encoding)能够很好地解决该问题。通过相邻位置元素内同一维度的位置编码信息构成少量错位来使模型感知到元素的上下文关系:
详细介绍见上一节,其中
P
i
,
2
j
,
P
i
,
2
j
+
1
\mathcal P_{i,2j},\mathcal P_{i,2j+1}
Pi,2j,Pi,2j+1分别表示序列中第
i
i
i个元素内第
2
j
,
2
j
+
1
2j,2j+1
2j,2j+1个维度特征的表示。
{
P
i
,
2
j
=
sin
(
i
1000
0
2
j
d
)
P
i
,
2
j
+
1
=
cos
(
i
1000
0
2
j
d
)
\begin{cases} \begin{aligned} \mathcal P_{i,2j} & = \sin \left(\frac{i}{10000^{\frac{2j}{d}}}\right) \\ \mathcal P_{i,2j+1} & = \cos \left(\frac{i}{10000^{\frac{2j}{d}}}\right) \end{aligned} \end{cases}
⎩
⎨
⎧Pi,2jPi,2j+1=sin(10000d2ji)=cos(10000d2ji)
Transformer \text{Transformer} Transformer架构

关于架构的简单认识
关于 Transformer \text{Transformer} Transformer模型的第一印象,就是它依然是编码器——解码器架构。但是它与 Seq2seq \text{Seq2seq} Seq2seq的核心区别在于:
Seq2seq \text{Seq2seq} Seq2seq关于序列数据的处理在编码器、解码器中分别使用独立的循环神经网络来获取序列特征;而 Transformer \text{Transformer} Transformer仅通过自注意力加位置编码的方式从序列数据中提取序列特征。
以编码器结构为例。与神经网络类似,其内部包含若干个 Transformer \text{Transformer} Transformer块 ( Transformer Block ) (\text{Transformer Block}) (Transformer Block),每一个 Transformer \text{Transformer} Transformer块的输出作为下一个 Transformer \text{Transformer} Transformer块的输入。接下来将分别对编码器、解码器中的 Transformer \text{Transformer} Transformer块进行介绍,并观察它们的差异性。
多头注意力机制

关于多头注意力机制
(
Multi-Head Attention
)
(\text{Multi-Head Attention})
(Multi-Head Attention),它的逻辑是:并行执行自注意力机制若干次,从而得到不同版本的注意力结果。
这种基于基于相同输入,通过不同方式进行学习,并将各学习结果进行处理的思想,使得我们联想到了两个方法:
Bagging
\text{Bagging}
Bagging与卷积神经网络。
关于 Bagging \text{Bagging} Bagging,其核心思想是通过自助采样法 ( Bootstrapping Sampling ) (\text{Bootstrapping Sampling}) (Bootstrapping Sampling)对数据集合 D \mathcal D D进行 M \mathcal M M次独立采样得到相应的新集合 D i ( i = 1 , 2 , ⋯ , M ) \mathcal D_i(i=1,2,\cdots,\mathcal M) Di(i=1,2,⋯,M);针对每一个 D i \mathcal D_i Di使用独立的基学习器进行学习,并将所有基学习器学习的结果根据不同任务进行描述:
- 关于回归任务:对各基学习器的输出结果取均值操作。
- 关于分类任务:使用多数表决 ( Majority Voting ) (\text{Majority Voting}) (Majority Voting)的方式决定分类结果。
不否认各集合
D
i
\mathcal D_i
Di内的样本间存在差异,但它们描述的分布和
D
\mathcal D
D对应的真实分布相同;并且这种方式能够有效降低分布的预测方差。
仅从操作的角度观察,取均值/投票的方式将各基学习器学习到特征的差异性给‘抹平’了。
关于卷积神经网络,其核心思想是通过相互独立的卷积核对同一输入数据执行卷积操作。每一个卷积核都会得到关于输入数据的抽象信息。
每一个卷积核产生的抽象结果被称作一个‘通道’( Channel ) (\text{Channel}) (Channel);和Bagging \text{Bagging} Bagging方法类似,将若干个‘通道’的抽象信息使用‘池化’( Pooling ) (\text{Pooling}) (Pooling)的方式对各通道的特征进行归纳/筛选。无论是‘最大池化'还是‘平均池化’,依然没有保留差异信息。
并不是说没有保留差异信息就是缺陷,这需要根据具体任务具体分析。在序列信息的处理过程中,这种差异性是有必要的。我们需要更好地处理这种差异性。
关于多头注意力机制的执行过程表示如下:
- 将添加位置编码的输入数据
X
\mathcal X
X通过独立的全连接层
(
Fully Connected Layer,FC
)
(\text{Fully Connected Layer,FC})
(Fully Connected Layer,FC)得到相应的特征信息
Q
,
K
,
V
\mathcal Q,\mathcal K,\mathcal V
Q,K,V:
{ Q = [ W Q ] T X + b Q K = [ W K ] T X + b K V = [ W V ] T X + b V \begin{cases} \mathcal Q = [\mathcal W_{\mathcal Q}]^T \mathcal X + b_{\mathcal Q} \\ \mathcal K = [\mathcal W_{\mathcal K}]^T \mathcal X + b_{\mathcal K} \\ \mathcal V = [\mathcal W_{\mathcal V}]^T \mathcal X + b_{\mathcal V} \end{cases} ⎩ ⎨ ⎧Q=[WQ]TX+bQK=[WK]TX+bKV=[WV]TX+bV - 这仅仅是一个自注意力机制内的特征表示,假设多头注意力机制中包含
M
\mathcal M
M个独立的自注意力机制,对应的特征信息表示如下:
每个特征信息对应的权重也均是相互独立的。
Q ( i ) , K ( i ) , V ( i ) ( i = 1 , 2 , ⋯ , M ) \mathcal Q^{(i)},\mathcal K^{(i)},\mathcal V^{(i)} \quad (i=1,2,\cdots,\mathcal M) Q(i),K(i),V(i)(i=1,2,⋯,M) - 每一个头执行各自的自注意力机制:
这里A ( i ) \mathcal A^{(i)} A(i)表示第i i i自注意力机制的输出特征。
{ a [ Q ( i ) , K ( i ) ] = Q ( i ) [ K ( i ) ] T d A ( i ) = Softmax { a [ Q ( i ) , K ( i ) ] } V ( i ) i = 1 , 2 , ⋯ , M \begin{cases} \begin{aligned} & a \left[\mathcal Q^{(i)},\mathcal K^{(i)}\right] = \frac{\mathcal Q^{(i)}[\mathcal K^{(i)}]^T}{\sqrt{d}} \\ & \mathcal A^{(i)} = \text{Softmax} \left\{ a \left[\mathcal Q^{(i)},\mathcal K^{(i)}\right]\right\}\mathcal V^{(i)} \end{aligned} \end{cases} \quad i=1,2,\cdots,\mathcal M ⎩ ⎨ ⎧a[Q(i),K(i)]=dQ(i)[K(i)]TA(i)=Softmax{a[Q(i),K(i)]}V(i)i=1,2,⋯,M - 将
M
\mathcal M
M个输出特征进行拼接
(
Concatenate
)
(\text{Concatenate})
(Concatenate),并再次使用全连接层进行特征表示:
和Bagging \text{Bagging} Bagging与卷积神经网络相比,这种Concatenate \text{Concatenate} Concatenate加全连接层的方式保留了各个自注意力机制产生的差异性信息。
{ A = Concat [ A ( 1 ) , A ( 2 ) , ⋯ , A ( M ) ] O = [ W A ] T A + b A \begin{cases} \mathcal A & = \text{Concat}\left[\mathcal A^{(1)},\mathcal A^{(2)},\cdots,\mathcal A^{(\mathcal M)}\right] \\ \mathcal O & = [\mathcal W_{\mathcal A}]^T \mathcal A + b_{\mathcal A} \end{cases} {AO=Concat[A(1),A(2),⋯,A(M)]=[WA]TA+bA
包含掩码的多头注意力机制
在解码器模块中,不仅包含多头注意力机制,并且还包含带掩码的多头注意力机制。带掩码操作的多头注意力机制的思想在于:
回顾
Seq2seq
\text{Seq2seq}
Seq2seq模型执行机器翻译任务的过程中,以包含注意力机制的模型为例,它的输入包含
3
3
3项信息:
y
(
t
)
=
G
[
y
(
t
−
1
)
,
C
t
,
h
D
(
t
−
1
)
]
y^{(t)} = \mathcal G \left[y^{(t-1)},\mathcal C_t,h_{\mathcal D}^{(t-1)}\right]
y(t)=G[y(t−1),Ct,hD(t−1)]
其中:
- y ( t − 1 ) y^{(t-1)} y(t−1)表示解码器 t − 1 t-1 t−1时刻的输出信息;
- C t \mathcal C_t Ct表示解码器 t t t时刻与编码器所有时刻输出的注意力信息;
- h D ( t − 1 ) h_{\mathcal D}^{(t-1)} hD(t−1)表示解码器 t − 1 t-1 t−1时刻产生的序列信息;
很明显,对当前时刻的预测信息与当前时刻的信息以及后续时刻信息之间没有关联关系。
虽然在
Transformer
\text{Transformer}
Transformer的解码器中不会像
Seq2seq
\text{Seq2seq}
Seq2seq一样一个时刻仅预测一个元素,而是所有时刻结果全部输出。但在预测过程中与
Seq2seq
\text{Seq2seq}
Seq2seq同理:解码器对序列中一个元素进行预测时,不应该考虑当前时刻以及后续时刻元素信息。
以未来时刻信息作为条件下,对未来信息进行预测。这是不合理的。
这种操作在 Transformer \text{Transformer} Transformer中使用掩码 ( Mask ) (\text{Mask}) (Mask)的方式进行表示:如果对序列数据 X \mathcal X X中的第 i i i个元素 x i x_i xi进行预测时,就将其看作是预测该序列中的最后一个元素,而后续的 x i + 1 , x i + 2 , ⋯ x_{i+1},x_{i+2},\cdots xi+1,xi+2,⋯等等被 Mask \text{Mask} Mask掉。
基于位置信息的前馈神经网络
从多头注意力机制中输出的数据格式表示为:
[
BatchSize,SeqLength,Dimension
]
[\text{BatchSize,SeqLength,Dimension}]
[BatchSize,SeqLength,Dimension]。其中
BatchSize
\text{BatchSize}
BatchSize表示批次内样本数量;
SeqLength
\text{SeqLength}
SeqLength表示序列长度;
Dimension
\text{Dimension}
Dimension表示输出序列信息中各元素的向量表示维数。
其中
Dimension
\text{Dimension}
Dimension是由多头注意力机制累积下来的维数结果。
需要注意的是:不同序列的 SeqLength \text{SeqLength} SeqLength存在差异。这个差异是输入序列自身的性质,与模型自身无关。理论上认为:模型可以处理任意长度的序列信息,因而不能将序列长度这个参数作为模型的参数。
基于位置信息的前馈神经网络 ( Position-wise FeedForward Network ) (\text{Position-wise FeedForward Network}) (Position-wise FeedForward Network)自身就是一组全连接层。而它的主要作用是对注意力机制的输出特征进行非线性变换。由于上面的要求,这个非线性变换作用的对象并不是一个序列,而是序列中的每一个元素。
该网络由两个线性计算层和一个
ReLU
\text{ReLU}
ReLU激活函数构成:
{
O
~
1
=
x
W
1
+
b
1
O
1
=
ReLU
(
O
~
1
)
=
max
(
0
,
O
~
1
)
O
2
=
O
1
W
2
+
b
2
\begin{cases} \widetilde{\mathcal O}_1 = x \mathcal W_1 + b_1 \\ \mathcal O_1 = \text{ReLU}(\widetilde{\mathcal O}_1) = \max(0,\widetilde{\mathcal O}_1)\\ \mathcal O_2 = \mathcal O_1 \mathcal W_2 + b_2 \end{cases}
⎩
⎨
⎧O
1=xW1+b1O1=ReLU(O
1)=max(0,O
1)O2=O1W2+b2
其中
W
1
∈
R
Dimension
×
d
F
F
N
;
W
2
∈
R
d
F
F
N
×
Dimension
\mathcal W_1 \in \mathbb R^{\text{Dimension} \times d_{FFN}};\mathcal W_2 \in \mathbb R^{d_{FFN} \times \text{Dimension}}
W1∈RDimension×dFFN;W2∈RdFFN×Dimension,其中
d
F
F
N
d_{FFN}
dFFN表示前馈神经网络中隐藏层的维数大小。很明显:无论是
W
1
,
W
2
\mathcal W_1,\mathcal W_2
W1,W2还是
b
1
,
b
2
b_1,b_2
b1,b2,它们的维数信息与序列长度
SeqLength
\text{SeqLength}
SeqLength没有任何关系。只要关于元素的模型参数学习好了,
SeqLength
\text{SeqLength}
SeqLength无论长短都可以进行训练。
终上,我们要将非线性变换的关注点在于序列中的每一个元素,并且消除
SeqLength
\text{SeqLength}
SeqLength这个维度对模型的影响,因此执行过程表示如下:
其具体做法可看作是将所有文本序列‘全部首尾连接在一起,构成一个‘超长序列’。这个思路与
Word2vec
\text{Word2vec}
Word2vec系列模型的假设存在相似之处。
-
将 Multi-Head Attention \text{Multi-Head Attention} Multi-Head Attention部分的输出格式由 3 3 3维格式: [ BatchSize,SeqLength,Dimension ] [\text{BatchSize,SeqLength,Dimension}] [BatchSize,SeqLength,Dimension]修改为 2 2 2维格式: [ BatchSize * SeqLength,Dimension ] [\text{BatchSize * SeqLength,Dimension}] [BatchSize * SeqLength,Dimension];
这个操作本身就是为了‘模糊’掉SeqLength \text{SeqLength} SeqLength这个维度在前馈神经网络中的作用。但在PyTorch \text{PyTorch} PyTorch中,这个操作都不需要做。因为PyTorch \text{PyTorch} PyTorch中的nn.Linear() \text{nn.Linear()} nn.Linear()只会将最后一个维度作为特征维度。 -
将修改后特征作为前馈神经网络的输入,并得到对应的输出结果格式: [ BatchSize * SeqLength,Dimension ] \left[\text{BatchSize * SeqLength,Dimension}\right] [BatchSize * SeqLength,Dimension];
基于上述W 1 , W 2 \mathcal W_1,\mathcal W_2 W1,W2格式的描述,输出格式结果不会发生变化。 -
最后将输出结果格式由 [ BatchSize * SeqLength,Dimension ] [\text{BatchSize * SeqLength,Dimension}] [BatchSize * SeqLength,Dimension]还原回原始格式 [ BatchSize,SeqLength,Dimension ] [\text{BatchSize,SeqLength,Dimension}] [BatchSize,SeqLength,Dimension]。
残差网络与层标准化操作
关于残差网络 ( Residual Network ) (\text{Residual Network}) (Residual Network)这里不再赘述,详见传送门。
在执行神经网络的反向传播过程中,随着 Transformer Block \text{Transformer Block} Transformer Block块的增多(神经网络的深度增加),导致注意力层或者全连接神经网络层中的权重信息不可避免地会出现特征空间偏移的情况。因而我们需要对特征进行归一化操作,从而增加模型的收敛速度。
但批标准化
(
Batch Normalization,BN
)
(\text{Batch Normalization,BN})
(Batch Normalization,BN)并不适合用在序列长度可能存在差异的自然语言处理任务中,因而使用层标准化的方式执行归一化操作。层标准化的核心思路在于:在同一
Batch
\text{Batch}
Batch内的各样本之间独立同分布:
关于层标准化传送门
- 关于层标准化的具体操作表示如下:
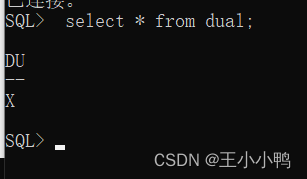
分别使用torch,手动(manual)分别实现Layer Normalization \text{Layer Normalization} Layer Normalization,结果相同。
import numpy as np
from torch import nn as nn
import torch
def LayerNormTest(mode):
arr1 = np.arange(1, 26).reshape(5,5,1)
arr2 = np.arange(11, 36).reshape(5,5,1)
arr3 = np.arange(31, 56).reshape(5,5,1)
arr = torch.tensor(np.concatenate([arr1,arr2,arr3],axis=2)).float()
arr = torch.permute(arr,(2,0,1)).unsqueeze(0)
assert mode in ["torch","manual"]
if mode == "torch":
Norm = nn.LayerNorm([3,5,5])
arrNorm = Norm(arr)
else:
U = arr.mean()
S = (arr - U).pow(2).mean()
arrNorm = (arr - U) / torch.sqrt(S + 1e-5)
return arrNorm
if __name__ == '__main__':
a1 = LayerNormTest(mode="torch")
a2 = LayerNormTest(mode="manual")
print(a1)
print("---" * 30)
print(a2)
- 可以观察到,它的均值结果
U、方差结果S均是一个标量;也就是说: LayerNorm \text{LayerNorm} LayerNorm基于整个 Batch \text{Batch} Batch内所有元素执行的均值与方差操作。而这种做法的底层逻辑是:它将该 Batch \text{Batch} Batch内的各样本看作成一个独立的数据集来执行标准化。根据 Batch \text{Batch} Batch的定义, Batch \text{Batch} Batch自身就是训练集随机采样产生的一个子集,因而各个 Batch \text{Batch} Batch的分布是相似的,并且理论上都趋近于样本真实分布。
print(U)
tensor(26.3333)
print(S)
tensor(207.5555)
编码器的输出与信息传递
回归上图:
-
其中左侧虚线框中描述的 Transformer \text{Transformer} Transformer模块是一个编码器 ( Encoder ) (\text{Encoder}) (Encoder)模块;图中仅仅画了一个,但实际上,和深度神经网络相同,可以通过叠加编码器模块,使其增加编码器的神经网络深度;从而最终得到一个类似于 Seq2seq \text{Seq2seq} Seq2seq模型中 Context \text{Context} Context向量 C \mathcal C C作用的编码器输出:

-
而右侧虚线框中描述的 Transformer \text{Transformer} Transformer模块是一个解码器 ( Decoder ) (\text{Decoder}) (Decoder)模块;与编码器部分相似,它同样可以通过叠加解码器模块来增加解码器的神经网络深度。
但与 Seq2seq \text{Seq2seq} Seq2seq模型不同的是: Transformer \text{Transformer} Transformer块自身并不是一个类似于 RNN \text{RNN} RNN的循环结构,因此不同于 Seq2seq \text{Seq2seq} Seq2seq解码器仅将 Context \text{Context} Context向量 C \mathcal C C作为初始时刻的隐藏层输入, Transformer \text{Transformer} Transformer的解码器部分需要每一个解码器模块均需要编码器输出结果作为输入;并且是作为 Multi-Head Attention \text{Multi-Head Attention} Multi-Head Attention的 Query \text{Query} Query与 Key \text{Key} Key的输入;

并且要求编码器与解码器中 Transformer \text{Transformer} Transformer块的数量是相等的。
这里有一点不太理解,因为Encoder \text{Encoder} Encoder内的Transformer \text{Transformer} Transformer块在执行隐藏层状态的运算中,并没有与Decoder \text{Decoder} Decoder中对应位置的Transformer \text{Transformer} Transformer块之间存在关联关系,感觉只和Encoder Output \text{Encoder Output} Encoder Output有关系,也有可能上面的图画错了,欢迎小伙伴们一起讨论。 -
并且编码器的输出作为每一个解码器 Transformer \text{Transformer} Transformer模块中多头注意力机制的 Key,Value \text{Key,Value} Key,Value;而 Query \text{Query} Query来自于目标序列(解码器自身的输入)。
关于预测问题
关于预测问题,我们早在动态模型的推断任务中就介绍过这个概念。已知前
t
t
t个观测值,预测第
t
+
1
t+1
t+1个预测值的后验分布:
P
(
o
t
+
1
∣
o
1
,
o
2
,
⋯
,
o
t
)
\mathcal P(o_{t+1} \mid o_1,o_2,\cdots,o_t)
P(ot+1∣o1,o2,⋯,ot)
而关于
Transformer
\text{Transformer}
Transformer的预测任务中,前
t
t
t个观测值也是通过预测得到的。在解码器模块的自注意力机制对于
t
+
1
t+1
t+1时刻信息的预测过程中,首先会使用前
t
t
t个预测结果分别作为
Key,Values
\text{Key,Values}
Key,Values;而第
t
t
t个值作为
Query
\text{Query}
Query来参与多头注意力机制的计算过程。
相关参考:
Transformer 、Reformer知识点整理
nn.LayerNorm的实现及原理