CVPR 2023 | OVSeg: Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
- 论文:https://arxiv.org/abs/2210.04150
- 代码:https://github.com/facebookresearch/ov-seg

架构设计
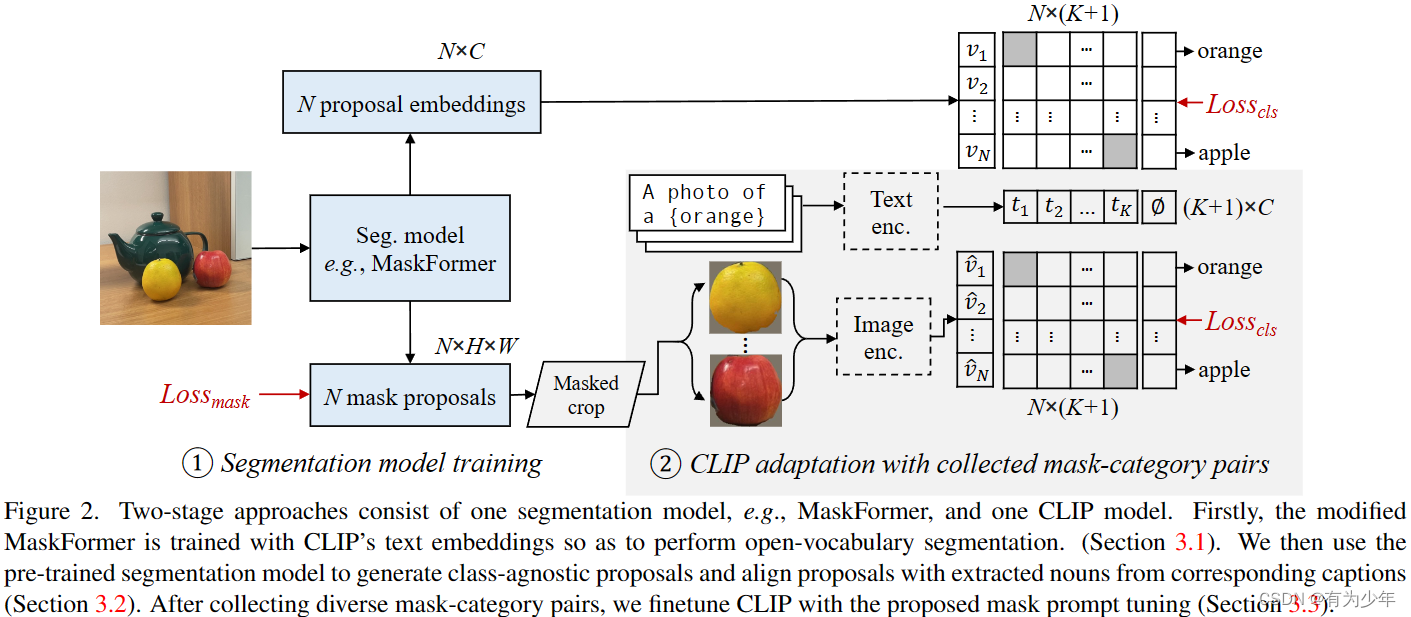
- 类别无关的 mask proposal generator:MaskFormer
- 手动微调以适应 masked image 的 CLIP:使用时被冻结。
解码设计
- 分类标签利用 prompt 模板和 CLIP 的 text encoder 生成 K K K个类别对应的文本嵌入 t k t_k tk。额外引入了一个“on object”类别,用于匹配那些没有合适的真值匹配的预测。并设置了一个可学习的嵌入 ∅ \emptyset ∅ 用于对应这一类别。
- MaskFormer 生成
N
N
N个 proposal embedding 和 N 个 mask proposal。
- proposal embedding v i v_i vi用于表征对应 mask proposal 的目标信息。可以得到分类概率: p i , k = exp ( σ ( v i , t k ) / τ ) / ∑ k ( exp ( σ ( v i , t k ) / τ ) ) p_{i,k}=\exp(\sigma(v_i, t_k)/\tau)/\sum_k(\exp(\sigma(v_i, t_k)/\tau)) pi,k=exp(σ(vi,tk)/τ)/∑k(exp(σ(vi,tk)/τ))
- mask proposal 会用于从输入图像中提取目标。按照紧凑的方形区域提取 patch 后,利用 mask 置零背景像素,并放缩 patch 到 CLIP 的输入分辨率上。patch 送入 CLIP 的 visual encoder 提取图像表征。可以得到另一个分类概率: p ^ i , k = exp ( σ ( v ^ i , t k ) / τ ) / ∑ k ( exp ( σ ( v ^ i , t k ) / τ ) ) \hat{p}_{i,k}=\exp(\sigma(\hat{v}_i, t_k)/\tau)/\sum_k(\exp(\sigma(\hat{v}_i, t_k)/\tau)) p^i,k=exp(σ(v^i,tk)/τ)/∑k(exp(σ(v^i,tk)/τ))
- 最终预测的概率为二者的几何平均: p i , k 1 − λ ∗ p ^ i , k λ , λ ∈ [ 0 , 1 ] p_{i,k}^{1-\lambda} * \hat{p}_{i,k}^{\lambda}, \lambda \in [0, 1] pi,k1−λ∗p^i,kλ,λ∈[0,1]
- 最终预测使用 MaskFormer 的融合模块来融合不同的 mask-wsie 预测。
其他设计
- 本文借鉴了不少来自 ZegFormer 的设计:
- 在 Mask 类别设置中,额外引入了一个“on object”类别,用于匹配那些没有合适的真值匹配的预测。并设置了一个可学习的嵌入用于对应这一类别。
- 使用了类似的两种分类概率计算方式和组合方式。

- Prompt Engineering:使用了来自 Open-vocabulary object detection via vision and language knowledge distillation 的 15 个 text prompt templates。对嵌入平均。
- 训练过程:先使用 COCO-Stuff 训练修改的 MaskFormer,在使用从 COCO-Captions 构造的数据集微调 CLIP。
实验发现
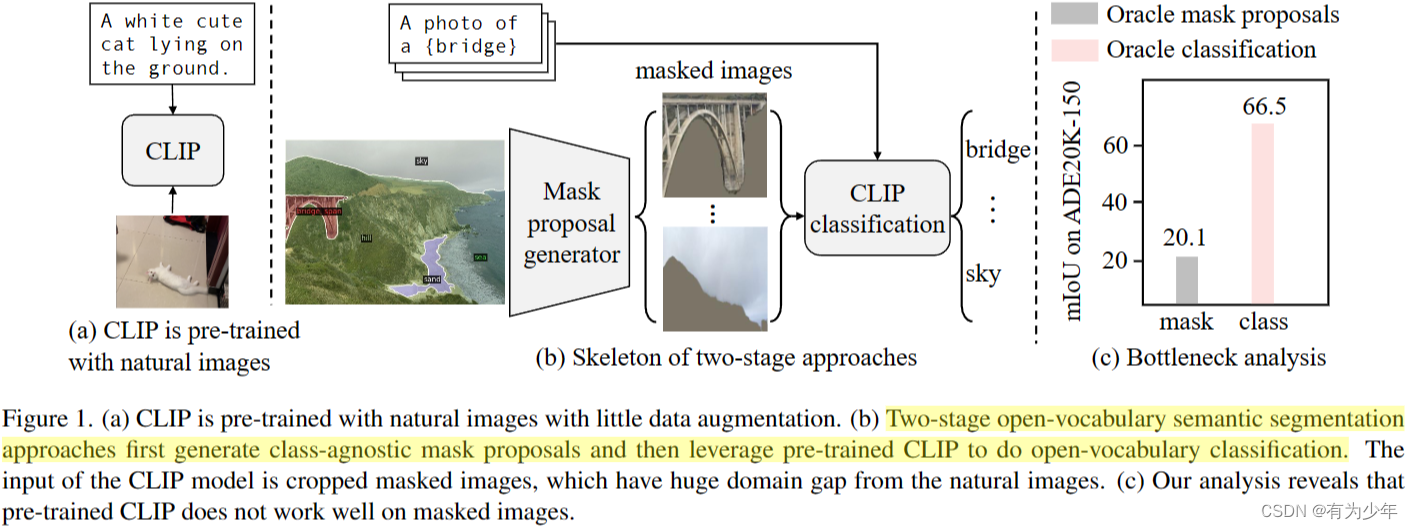
- 通过精心设计的实验对比发现,预训练的 CLIP 无法对 masked image 执行令人满意的分类,这是两阶段开放词汇分割模型的性能瓶颈。本文认为这是由于蒙面图像和 CLIP 的训练图像之间的显著域差距造成的。CLIP 在自然图像上进行预训练,并使用了最小的数据增强。而且 mask proposal 是从原始图像中裁剪和调整大小后得到的,这也进一步被不准确的分割 mask 破坏。所以 CLIP 需要进行特殊的微调。
- 微调 CLIP 时,如果使用具有闭集类别标签的分割数据(例如 171 类的 COCO-stuff)会破坏 CLIP 的对于开放词汇概念的泛化能力。为此本文使用了现有的 image-caption 数据集来构建微调过程从而获得了更好的性能。
- 剪裁图像但不屏蔽背景像素的设定会导致更差的性能。这可能是因为这些背景内容会干扰 CLIP 的分类能力。
- 模型的失败中,有一部分是因为语言定义类别的模糊性,有一部分的类别之间概念存在重叠。所以对于开放词汇分割模型设计一种更好的评估方式仍然是一个重要的主题。
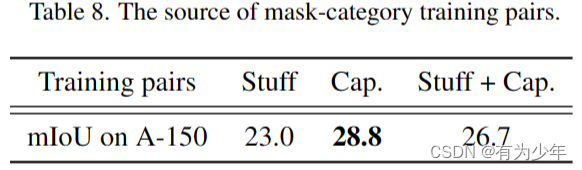
- 调整CLIP:将自行构造的伪标签注释与原本的真实数据注释组合后训练,性能反而不如仅使用伪标签注释的性能,但是也优于仅仅使用原始标注的效果。或许更好的组合比例可以获得性能提升。
CLIP 的微调
数据构造
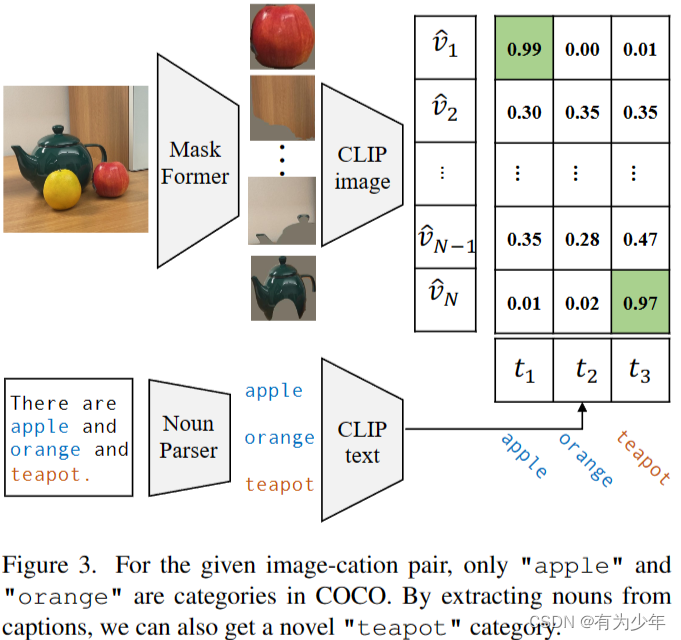
给定一个 image-caption 对,先提取标题中的名词,并使用预训练的分割模型生成类别无关的掩码区域建议。再使用预训练 CLIP 模型,为每个提取的名词分配最佳匹配提案。通过从 masked images 和新类别之间的这种弱监督对齐中学习,自适应的 CLIP 更好地保留了其对开放词汇分类的泛化能力。
- 这一过程首先使用预训练的 MaskFormer 提取 masked proposal,并从对应的图像 caption 中利用现成的语言解析器提取所有名词,将其看做潜在的类别。然后利用 CLIP 来为每个类别挑选最匹配的 mask proposal。
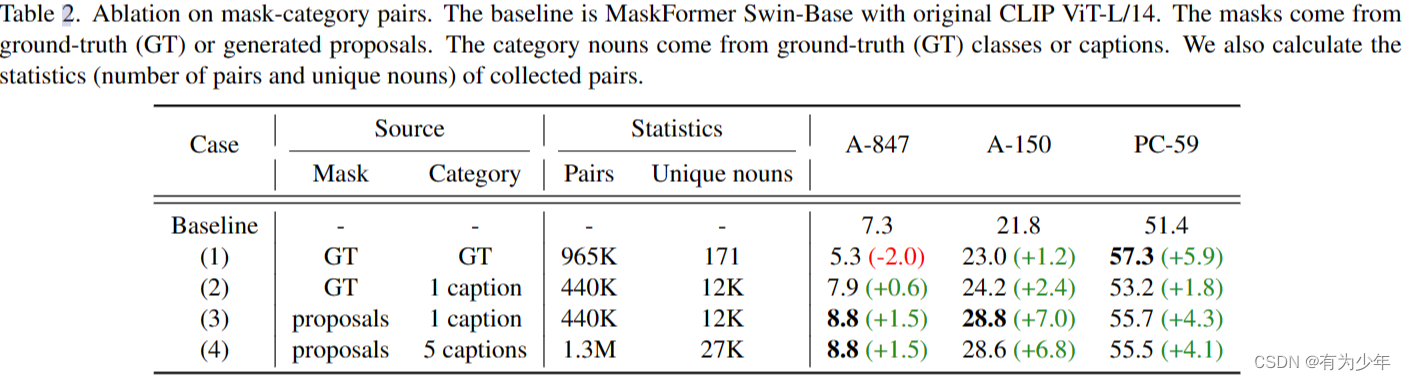
- 从 COCO-Captions 中,作者们测试了两个版本的数据:1)每个图像使用 5 个 caption 时,获得 1.3M 的 mask-category 对,包含 27K 个不重复的名词;2)每个图像使用 1 个 caption 时,获得 440K 对有着 12K 不重复名词的数据。实验中,后者获得了相对更好的表现,而且训练也更快。这些数据虽然具有噪声,但是信息的多样性展现出了相较于人工标签更好的性能。
Mask Prompt Tuning(MPT)
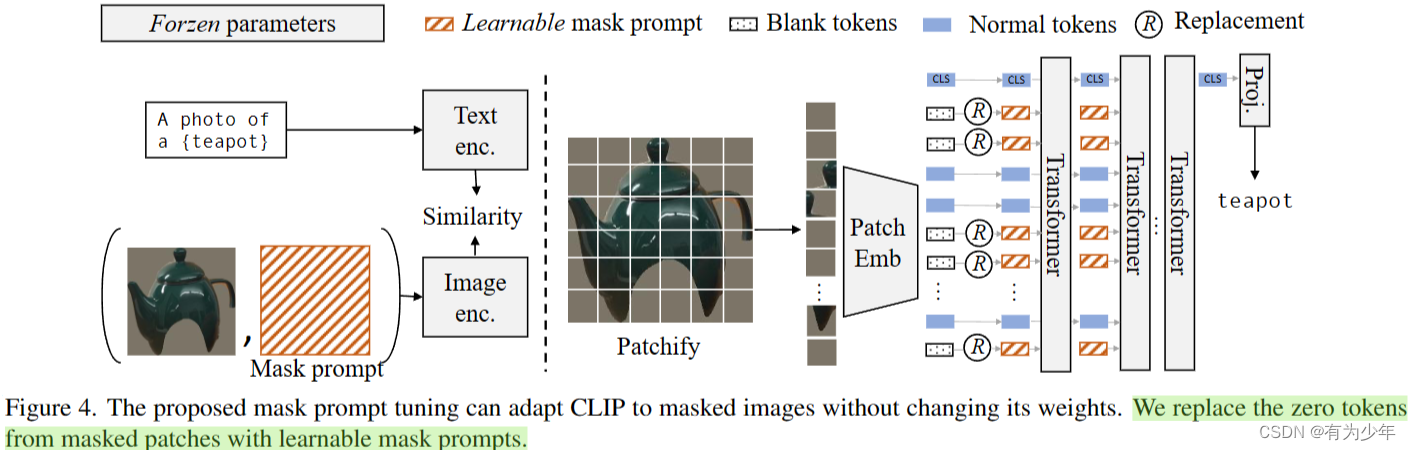
当 masked image 转化为 token 时,将“zero token”替换为可学习的 prompt token。微调过程中,要么只训练 prompt 并冻结 CLIP 权重,要么同时训练它们。文中发现,单独的 MPT 显著提高了 CLIP 在掩码图像上的性能。对于多任务场景,这是一个至关重要的属性,因为它与其他任务共享,所以无法更改 CLIP 的权重。可学习的 mask prompts 被用于替换那些整个都属于背景的 patch 所对应的 token,这里也同时借鉴了VPT(Visual Prompt Tuning)中的deep prompts的思想,在Transformer的更深层中加入了这样的prompt token。整个过程中文本编码器始终被冻结。
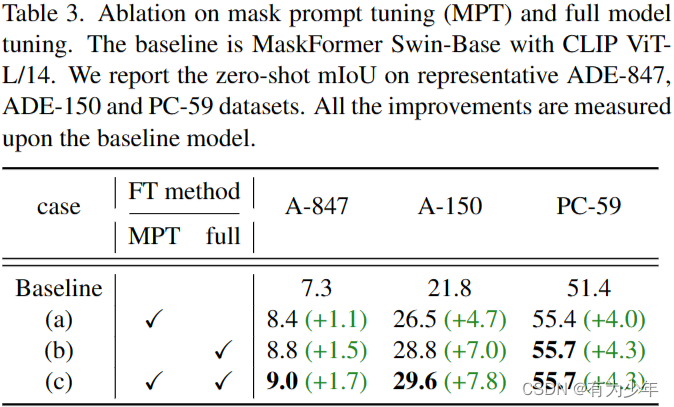
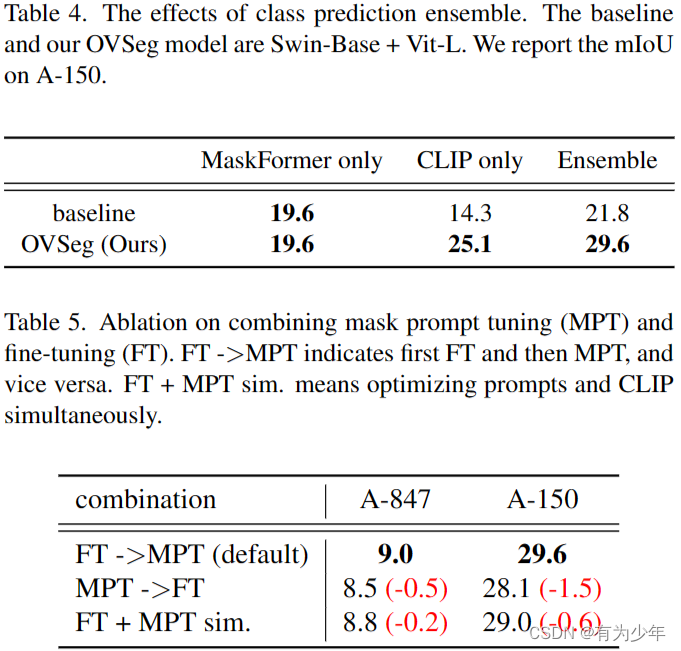
- 而对于微调后的 CLIP,再进行 MPT 可以进一步提升性能。
- 如果反过来,即先 MPT 后使用固定的 mask prompts 进行 CLIP 微调,或二者一起学习,即同时学习 mask prompts 并微调 CLIP,性能都会有下降。
实验对比
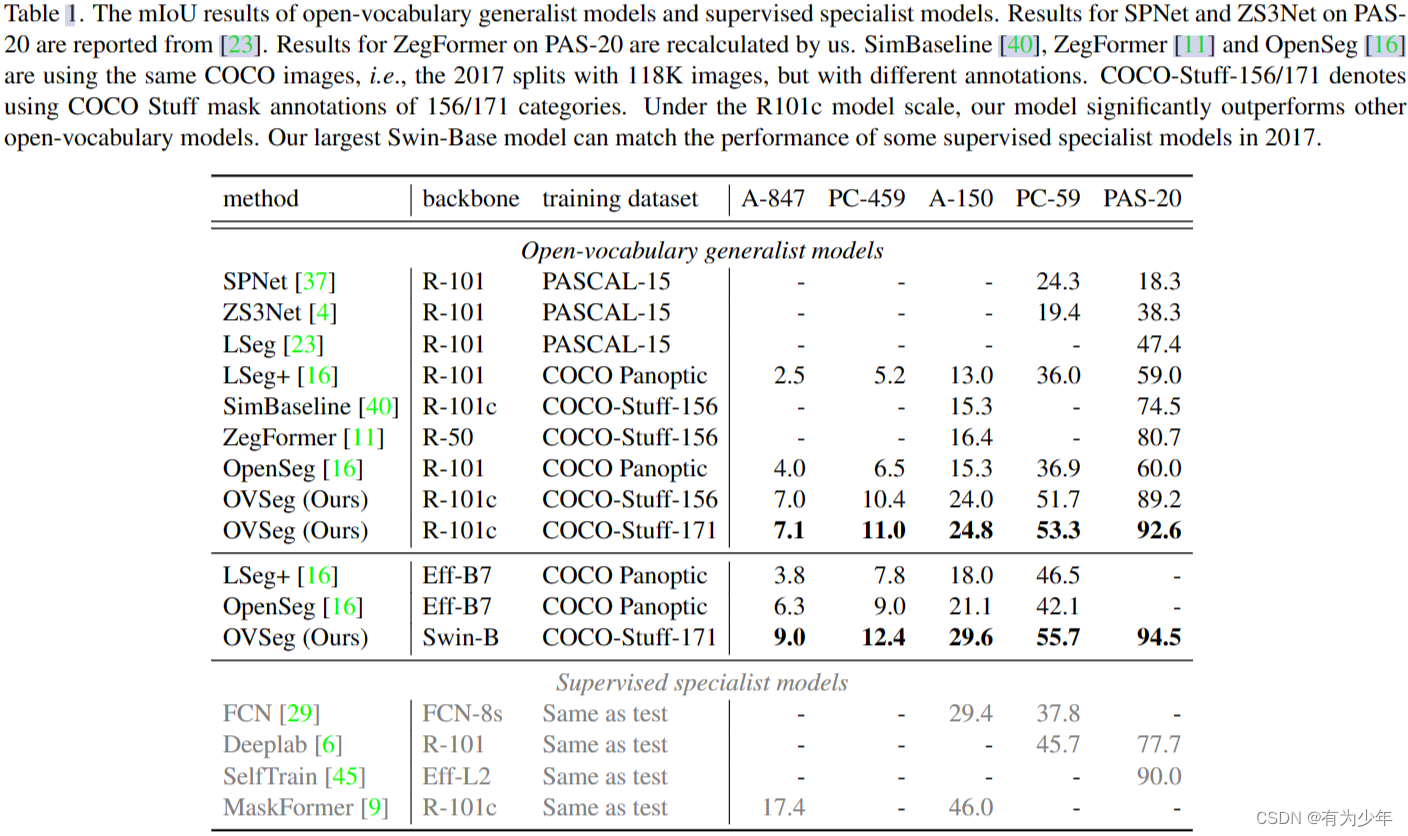




![常用数据分类算法原理介绍、优缺点分析与代码实现[LR/RF/DT/SVM/NavieBayes/GBDT/XGBoost/DNN/LightGBM等]](https://img-blog.csdnimg.cn/img_convert/efaea374885bff814a48b6cd39b6ac8e.png)