文章目录
- 前言
- 一、slab分配器
- 1.1 简介
- 1.2 高速缓存描述符
- 1.3 架构图
- 二、相关结构体
- 2.1 struct array_cache
- 2.2 struct kmem_list3
- 2.3 struct slab
- 2.3.1 简介
- 2.3.2 OFF_SLAB
- 三、创建和释放slab
- 3.1 创建slab
- 3.1.1 kmem_getpages
- 3.1.2 alloc_slabmgmt
- 3.1.3 slab_map_pages
- 3.2 释放slab
- 四、分配和释放高速缓存
- 4.1 kmem_cache_create
- 4.2 kmem_cache_alloc
- 4.2.1 代码说明
- 4.2.2 cache_alloc_refill
- 4.2.3 总结分配过程
- 4.3 kmem_cache_free
- 五、slab着色
- 5.1 简介
- 5.2 slab 着色
- 六、cache_cache
- 参考资料
前言
页面分配器(伙伴系统算法)用于连续物理页面的分配,内核中可以使用这些函数来分配一大块连续的内存空间。然而只是有页面级的内存分配函数还不够,因为很多情况下我们需要分配比4 KB要小很多的物理地址空间,比如只有几十或者几百个字节,如果对这样的地址空间需求也分配一个完整的物理页,显然会对物理内存的使用造成巨大浪费。基于这一需求,Linux系统在物理页分配的基础上实现了对更小内存空间进行管理的slab、slob和slub分配器。slab是Linux内核最早推出的小内存分配方案,slub和slob分配器则是Linux 2.6内核开发期间新增的slab分配器的替代品,主要针对大型系统和嵌入式系统。
内核的其余部分无需关注底层选择使用了哪个分配器。所有分配器的前端接口都是相同的。
每个分配器都必须实现一组特定的函数,用于内存分配和缓存。
Linux 系统 目前对小内存空间基本都是采用的slub分配器,最近接触到centos6,centos6内核版本2.6.32,这个内核版本已经支持了slub分配器,但还是采用的slab分配器,那么本节将简单介绍下slab分配器。
slab分配器的基本思想是,先利用页面分配器分配出单个或者一组连续的物理页面,然后在此基础上将整块页面分割成多个相等的小内存单元,以满足小内存空间分配的需要。
[root@localhost ~]# uname -r
2.6.32-642.3.1.el6.x86_64
[root@localhost ~]# cat /boot/config-2.6.32-642.3.1.el6.x86_64 | grep SLAB
CONFIG_SLAB=y
CONFIG_SLABINFO=y
# CONFIG_DEBUG_SLAB is not set
[root@localhost ~]# cat /boot/config-2.6.32-642.3.1.el6.x86_64 | grep SLUB
# CONFIG_SLUB is not set
一、slab分配器
1.1 简介
在 Linux 内核中,SLAB 分配器是一种高效的内存分配器,它可以管理内核中的对象分配和释放。SLAB 分配器将内存划分为一组大小相等的块,被称为“slab”,每个 slab 包含相同数量的对象,这些对象的大小也是相同的。SLAB 分配器的主要优点包括高效、低内存碎片、可扩展性和高效的缓存管理等。
SLAB 分配器的优点包括:
(1)高效:slab分配器相比于伙伴系统算法分配连续的物理页,数据存储在伙伴系统直接提供的物理页中,那么其地址总是出现在2的幂次的整数倍附近(许多将页划分为更小块的其他分配方法,也有同样的特征)。这对CPU高速缓存的利用有负面影响,由于这种地址分布,使得某些缓存行过度使用,而其他的则几乎为空。多处理器系统可能会加剧这种不利情况,因为不同的内存地址可能在不同的总线上传输,上述情况会导致某些总线拥塞,而其他总线则几乎没有使用。slab分配器通过slab着色技术来充分利用CPU硬件高速缓存行。
调用伙伴系统的操作对系统的数据和指令高速缓存有相当的影响,更轻量级的slab分配器在可能的情况下减少了对伙伴系统的调用。
由于伙伴系统的分配是以物理页为单位的,其硬件高速缓存和TLB占用较大,这会导致不重要的数据驻留在CPU高速缓存中,而重要的数据则被置换到内存。
slab分配器以字节为单位,其硬件高速缓存和TLB占用较小,可以保证重要的数据驻留在CPU高速缓存中,即经常使用的内核对象保存在CPU硬件高速缓存中。
(2)低内存碎片:SLAB 分配器使用了对象池的概念,将内存按照对象大小分配,避免了内存碎片的产生,可以提高系统的稳定性和可靠性。
(3)可扩展性:SLAB 分配器支持动态增长和收缩内存池,可以根据实际需求来动态分配内存,从而避免了静态内存分配器的内存浪费问题。
(4)支持Per_CPU本地高速缓存组:SLAB 分配器支持 Per_CPU本地高速缓存组,可以将经常使用的对象缓存到同一个CPU的本地高速缓存中,从而提高系统的性能和响应速度。同样访问Per_CPU本地高速缓存组不需要获取额外的自旋锁,因为其他CPU不会访问这些Per_CPU本地高速缓存组,避免自旋锁的争用。
(5)缓存管理:SLAB 分配器支持缓存管理,可以根据缓存的大小和使用情况来调整缓存的大小,从而提高缓存的利用率和性能。
通过 /proc/slabinfo 文件查看 slab 高速缓存:
# cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedava
il>
task_struct 244 249 2672 3 2 : tunables 24 12 8 : slabdata 83 83 0
inode_cache 7002 7002 592 6 1 : tunables 54 27 8 : slabdata 1167 1167 0
ext4_inode_cache 2529 3052 1000 4 1 : tunables 54 27 8 : slabdata 763 763 0
filp 4916 5085 256 15 1 : tunables 120 60 8 : slabdata 339 339 0
可以用slabtop命令查看,slabtop命令是通过读取 /proc/slabinfo 文件:
# slabtop
Active / Total Objects (% used) : 1185520 / 1210786 (97.9%)
Active / Total Slabs (% used) : 16988 / 16988 (100.0%)
Active / Total Caches (% used) : 102 / 190 (53.7%)
Active / Total Size (% used) : 64487.24K / 68391.27K (94.3%)
Minimum / Average / Maximum Object : 0.02K / 0.06K / 4096.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
636336 636328 99% 0.02K 4419 144 17676K avtab_node
425600 424760 99% 0.03K 3800 112 15200K size-32
17160 11080 64% 0.19K 858 20 3432K dentry
16756 16063 95% 0.06K 284 59 1136K size-64
16589 11204 67% 0.07K 313 53 1252K selinux_inode_security
13395 13185 98% 0.20K 705 19 2820K vm_area_struct
11205 11204 99% 0.14K 415 27 1660K sysfs_dir_cache
10915 3253 29% 0.10K 295 37 1180K buffer_head
7392 7031 95% 0.05K 96 77 384K anon_vma_chain
6852 6809 99% 0.58K 1142 6 4568K inode_cache
5830 5779 99% 0.07K 110 53 440K Acpi-Operand
5628 5441 96% 0.05K 84 67 336K anon_vma
5085 4916 96% 0.25K 339 15 1356K filp
4710 4650 98% 0.12K 157 30 628K size-128
4692 4613 98% 0.04K 51 92 204K Acpi-Namespace
4186 3059 73% 0.55K 598 7 2392K radix_tree_node
3052 2523 82% 0.98K 763 4 3052K ext4_inode_cache
1880 1859 98% 0.19K 94 20 376K size-192
1336 1336 100% 0.50K 167 8 668K size-512
1095 1071 97% 0.25K 73 15 292K size-256
1020 1020 100% 1.00K 255 4 1020K size-1024
900 900 100% 0.69K 180 5 720K sock_inode_cache
826 506 61% 0.06K 14 59 56K avc_node
715 711 99% 0.77K 143 5 572K shmem_inode_cache
652 633 97% 2.00K 326 2 1304K size-2048
580 580 100% 0.88K 145 4 580K UNIX
511 500 97% 0.53K 73 7 292K idr_layer_cache
500 436 87% 0.19K 25 20 100K cred_jar
383 383 100% 4.00K 383 1 1532K size-4096
360 325 90% 0.25K 24 15 96K skbuff_head_cache
272 248 91% 0.11K 8 34 32K task_delay_info
270 270 100% 0.12K 9 30 36K pid
256 228 89% 0.12K 8 32 32K inotify_inode_mark_entry
249 244 97% 2.61K 83 3 664K task_struct
228 228 100% 0.64K 38 6 152K proc_inode_cache
202 4 1% 0.02K 1 202 4K jbd2_revoke_table
198 187 94% 0.81K 22 9 176K task_xstate
189 189 100% 32.12K 189 1 12096K kmem_cache
156 151 96% 2.06K 52 3 416K sighand_cache
154 154 100% 1.06K 22 7 176K signal_cache
144 5 3% 0.02K 1 144 4K fasync_cache
135 129 95% 0.81K 15 9 120K RAW
133 131 98% 1.06K 19 7 152K RAWv6
118 118 100% 0.06K 2 59 8K fs_cache
112 2 1% 0.03K 1 112 4K sd_ext_cdb
106 59 55% 0.07K 2 53 8K eventpoll_pwq
100 100 100% 1.38K 20 5 160K mm_struct
99 99 100% 0.69K 9 11 72K files_cache
96 81 84% 0.08K 2 48 8K blkdev_ioc
1.2 高速缓存描述符
slab分配器把对象放到告诉缓存中,每个高速缓存都是同种类型对象的”储备“,每个高速缓存由struct kmem_cache结构体表示。
struct kmem_cache {
/* 1) per-cpu data, touched during every alloc/free */
struct array_cache *array[NR_CPUS];
/* 2) Cache tunables. Protected by cache_chain_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int buffer_size;
u32 reciprocal_buffer_size;
/* 3) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
/* 4) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
gfp_t gfpflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *slabp_cache;
unsigned int slab_size;
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *obj);
/* 5) cache creation/removal */
const char *name;
struct list_head next;
......
/*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/
struct kmem_list3 *nodelists[MAX_NUMNODES];
/*
* Do not add fields after nodelists[]
*/
};
(1)array 字段是指向数组缓存(包含了 free object 本地高速缓存)的指针,表示本地对象缓冲池,用于高效地分配和释放小对象,每个CPU都由一个该数据。
(2)batchcount、limit 和 shared 字段是缓存可调整的参数,用于控制缓存的行为。这些字段受 cache_chain_mutex 保护,cache_chain_mutex 是用于同步访问缓存链的互斥量。
batchcount:迁移对象的数目。当前CPU的本地对象缓冲池 array 为空的情况下,从共享对象缓存池或者 slabs_partial / slabs_free 列表的 slab中迁移到本地对象缓存池数量。
limit :表示 slab 描述符中的 free object 的最大数目。当本地缓存池的 free object 的数目大于 limit 时,就会主动释放 batchcount 个 free object ,便于内核回收和销毁 slab分配器。(如果接下来内核回收缓存,则释放的内存从slab返回到伙伴系统)
shared :共享对象缓存池。
(3)flags :是一个标志寄存器,定义缓存的全局性质。当前只有一个标志位。如果管理结构存储在slab外部,则置位CFLGS_OFF_SLAB。
(4) num :保存了可以放入slab的对象的最大数目。
(5)gfporder 和 gfpflags 字段用于使用 GFP 标志控制内存分配行为。
gfporder 表示一个 slab 分配占用 2gfporder个物理页面。
gfpflags 表示分配物理页面时的掩码,比如 GFP_DMA。
(6)colour、colour_off 和 slabp_cache 字段用于实现 slab 颜色和 off-slab slab。slab 着色是一种技术,用于通过确保缓存中的对象不分配在同一缓存行上来减少缓存行争用。在一个 slab 中的对象数量超过一定限制时,会使用 off-slab slab。
colour:该字段用于着色,指定了颜色的最大数目,slab缓存着色的范围,0 ~ colour。一个slab分配器有多少个不同的高速缓存行。
colour_off :slab中着色时的基本对齐偏移,一个着色区的长度。内核使用L1高速缓存行的长度作为偏移量。
/*
* The slab lists for all objects.
*/
struct kmem_list3 {
unsigned int colour_next; /* Per-node cache coloring */
};
与着色相关还有 struct kmem_list3 的 colour_next 字段。
colour_next:colour_next则是内核建立的下一个slab的颜色。
这3个colour成员包含了slab着色相关的所有数据:
colour_off是基本偏移量乘以颜色值获得的绝对偏移量。这也是用于NUMA计算机,UMA系统可以将colour_next保存在struct kmem_cache中。但将下一个颜色放置在特定于结点的结构中,可以对同一结点上添加的slab顺序着色,对本地的CPU高速缓存有好处。
实例——如果有5种可能的颜色(0, 1, 2, 3, 4),而偏移量单位是8字节,内核可以使用下列偏移
量值:0×8= 0,1×8 = 8,2×8 = 16,3×8 = 24,4×8 = 32字节。
这里在第五章节详细介绍。
备注:着色这个术语与颜色无关,只是表示slab中的对象需要移动的特定偏移量,以便使对象放置到不同的缓存行。
(7)slab_size 和 dflags 字段包含一个slab的大小和 slab 分配器的动态标志信息。
(8)ctor 字段是指向构造器函数的函数指针,用于在从缓存中分配对象时调用构造器函数。
(9)name 和 next 字段包含有关缓存的元数据,例如缓存的名称和指向缓存链中下一个缓存的指针。
(10)nodelists 字段是一个指向 kmem_list3 结构体的指针数组,用于在 NUMA 系统中跟踪每个节点上的可用 slab。该成员必须置于结构的末尾。尽管它在形式上总是有MAX_NUMNODES项,但在NUMA计算机上实际可用的结点数目可能会少一些。因而该数组需要的项数也会变少,内核在运行时对该结构分配比理论上更少的内存,就可以缩减该数组的项数。如果nodelists放置在该结构中间,就无法做到这一点。在UMA计算机上,这称不上问题,因为只有一个可用结点。在2.3章节详细描述该字段。
kmem_cache 结构体是 Linux 内核中 slab 内存分配器实现的核心部分,用于管理不同大小和类型的对象的内存分配和释放。它提供了可调整的缓存行为参数、高级功能(例如 slab 颜色和 off-slab slab)以及缓存的元数据。
1.3 架构图
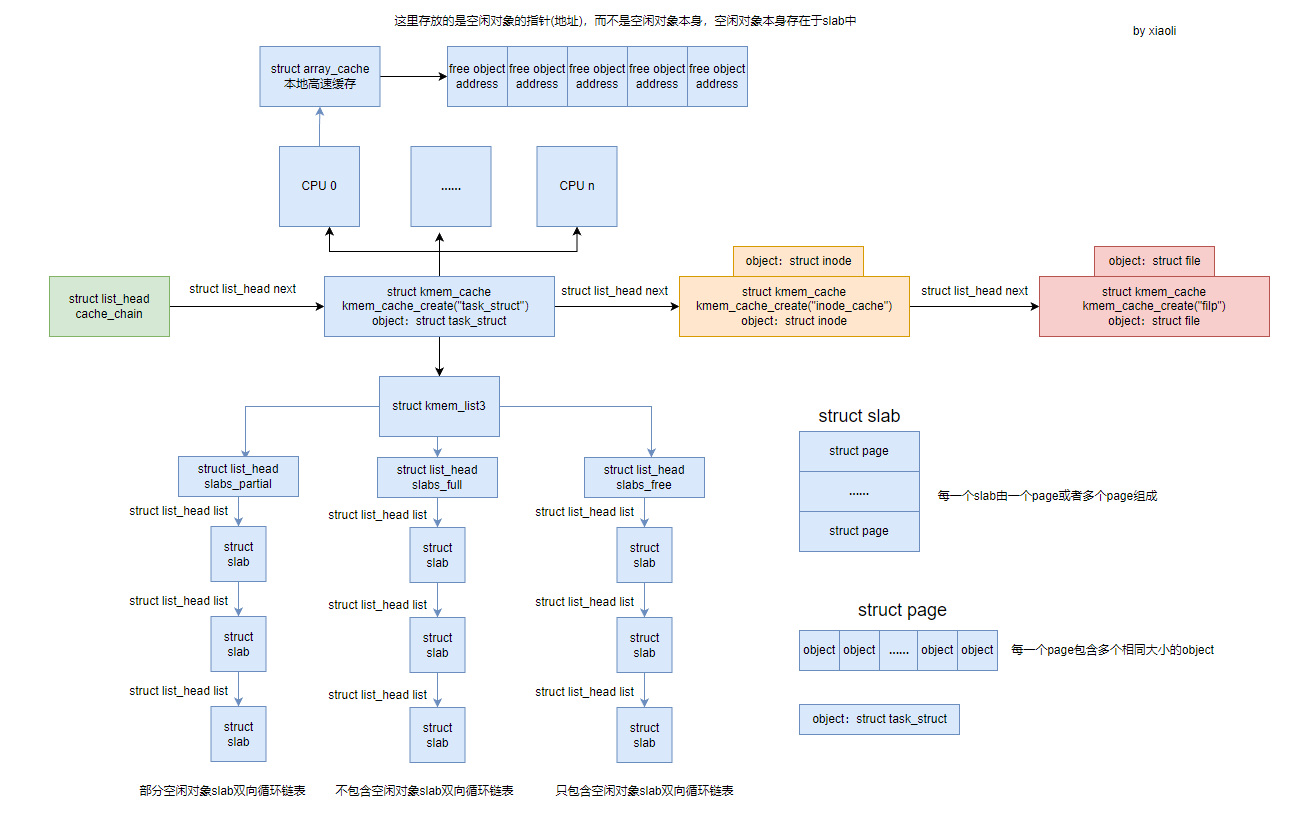
这里简单描述一下 object分配过程:首先从当前CPU的 struct array_cache 找可用的 free 内存对象,如果没有找到,在 struct kmem_list3 的 struct list_head slabs_partial 和 struct list_head slabs_free 的双向循环链表中找空闲的slab,将其填充到当前CPU的 struct array_cache中。填充后,然后获取struct array_cache的内存对象。如果仍然没有找到,则通过页框分配器(伙伴系统算法)获取一组连续的物理页创建一个新的 slab。
二、相关结构体
2.1 struct array_cache
/*
* struct array_cache
*
* Purpose:
* - LIFO ordering, to hand out cache-warm objects from _alloc
* - reduce the number of linked list operations
* - reduce spinlock operations
*
* The limit is stored in the per-cpu structure to reduce the data cache
* footprint.
*
*/
struct array_cache {
unsigned int avail;
unsigned int limit;
unsigned int batchcount;
unsigned int touched;
spinlock_t lock;
void *entry[]; /*
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*/
};
array_cache 是一个数据结构,用于在 Linux 内核中实现 SLAB 分配器中的 per-CPU 缓存。它的成员包括:
(1)avail:表示缓存中可用对象的数量。当从缓存中分配对象时,avail 计数器会减少,当将对象放回缓存时,avail 计数器会增加。
(2)limit:表示缓存的最大容量。为了减少数据缓存的占用,每个 CPU 都有自己的 array_cache 结构体,limit 成员存储在每个结构体中。
(3)batchcount:表示每次从后端分配器中获取多少个对象。当缓存为空时,分配器会从后端分配器中获取一组新的对象,初始化它们,并将它们添加到缓存中。
(4)touched:用于跟踪自上次缓存清理以来访问的缓存条目数。当访问条目数超过一定阈值时,分配器会清除缓存以删除过期的条目。
(5)lock:是一个自旋锁,用于保护缓存以避免多个 CPU 之间的竞争。
(6)entry:是一个柔性数组成员,可以存储任何类型的对象指针。它定义为空数组,这样可以确保结构体的对齐方式。在定义 array_cache 实例时,entry 数组的大小是按照 limit 成员动态确定的。
array_cache 是 SLAB 分配器中的一个重要组成部分,它可以通过缓存一些热数据来提高分配器的性能,并且可以避免多个 CPU 之间的竞争。通过在每个 CPU 上缓存常用对象,可以减少分配器需要访问全局缓存的次数,从而显著提高性能。
为最好地利用CPU高速缓存,这些per-CPU指针是很重要的。在分配和释放对象时,采用后进先
出原理(LIFO,last in first out)。内核假定刚释放的对象仍然处于CPU高速缓存中,会尽快再次分配它(响应下一个分配请求)。仅当per-CPU缓存为空时,才会用slab中的空闲对象重新填充它们。
备注:array_cache结构体存放的是指向对象的指针,而不是对象本身。它的entry成员是一个指针数组,每个元素都指向一个对象。当从array_cache中分配对象时,分配器将返回指向对象的指针,而不是对象本身。类似地,当将对象放回到array_cache中时,分配器将存储对象的指针,而不是对象本身。
通过存储指向对象的指针,array_cache结构体可以避免在分配和释放对象时复制大量的数据。这可以提高分配器的性能,并减少内存使用量。它也可以避免在多个CPU之间共享对象时出现竞争,因为每个CPU都有自己的array_cache结构体,它们可以独立地缓存对象指针。
需要注意的是,array_cache结构体中的指针数组并不分配任何内存空间,它只是一个指针的集合。实际的对象内存是在SLAB分配器中分配并管理的。
2.2 struct kmem_list3
/*
* The slab lists for all objects.
*/
struct kmem_list3 {
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
spinlock_t list_lock;
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
};
(1)slabs_partial、slabs_full 和 slabs_free:这些成员是链表头,指向一个由 slab 结构体组成的链表。Slab 是一块连续的内存块,包含固定数量的对象。slabs_partial 链表包含一些但不是全部对象已分配的 slab,slabs_full 链表包含所有对象已分配的 slab,slabs_free 链表包含所有对象都未分配的 slab。
(2)free_objects 和 free_limit:这些成员用于跟踪 SLAB 分配器中可用的空闲对象数量,free_objects 表示当前空闲对象数量,free_limit 表示 SLAB 分配器中最多可以存储的空闲对象数量。当空闲对象数量超过限制时,分配器会回收未使用的内存以减少碎片。
(3)colour_next:这个成员用于实现多节点缓存颜色,这是一种减少多处理器系统中缓存冲突的技术。缓存颜色将对象映射到缓存行中,以最小化可能被不同 CPU 访问的对象之间的冲突。
(4)list_lock:这个成员是一个自旋锁,用于保护 slab 列表以避免多个 CPU 之间的竞争。
(5)shared 和 alien:这些成员用于在每个 CPU 上缓存常用的对象,并在多处理器系统中共享对象。shared 成员指向 per-CPU 缓存,alien 成员是指向其他节点缓存的指针数组。
(6)next_reap:这个成员用于跟踪下一次分配器清理未使用内存的时间。当分配器回收未使用的内存时,它将 slab 从 slabs_full 列表移动到 slabs_partial 列表中,以便可以重复使用。
(7)free_touched:这个成员用于跟踪自上次清理以来访问的空闲对象数量。当访问的空闲对象数量超过一定阈值时,分配器触发清理操作以回收未使用的内存。
kmem_list3 结构体用于管理对象分配和释放操作,并支持多处理器系统。通过使用链表来管理 slab 和在每个 CPU 上缓存常用的对象,它减少了分配器需要访问全局缓存的次数,从而提高了性能。colour_next、shared、alien、next_reap 和 free_touched 等成员则用于支持多节点系统、缓存颜色和清理未使用内存等高级特性。
2.3 struct slab
2.3.1 简介
typedef unsigned int kmem_bufctl_t;
/*
* struct slab
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into three list: fully used, partial, fully free slabs.
*/
struct slab {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
unsigned short nodeid;
};
slab 结构体是 Linux 内核中 SLAB 分配器的一部分,用于管理对象的分配和释放。
struct slab结构用于管理一块连续的物理页面中内存对象的分配。

它的成员包括:
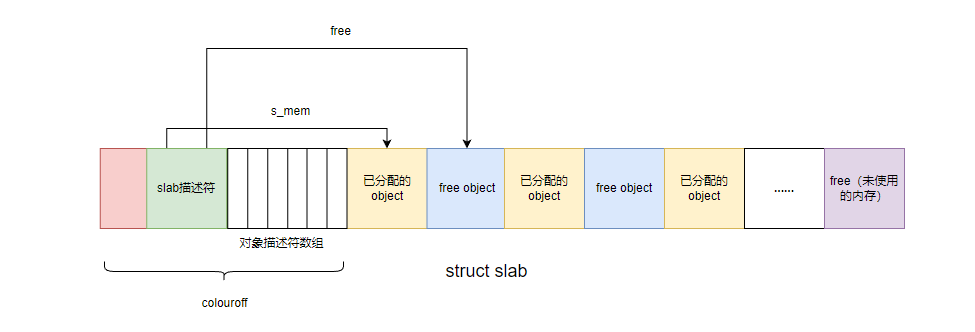
(1)list:用于将 slab 链接到完全使用、部分使用和完全空闲的 slab 列表中。
(2)colouroff:slab中第一个 object 对象的偏移,用于实现多节点缓存颜色,减少在多处理器系统中的缓存冲突。
(3)s_mem:slab中第一个 object 对象的地址,并通过移动指针来快速分配对象。
(4)inuse:表示 slab 中已经被分配的对象数量,即非 free 对象的个数。
(5)free:一个无符号的整数类型 kmem_bufctl_t,该slab第一个空闲对象的下标,用于指明 slab 中第一个空闲对象的 ,用于快速分配对象。每个slab头之后都是一个数组,数组项的数目与slab中对象的数目相同。内核利用该数组来查找下一个空闲对象的位置。数组项的数据类型为kmem_bufctl_t,该类型不过是普通的unsigned int通过typedef适当抽象的结果。
(6)nodeid:表示 slab 所在的节点 ID,用于在多节点系统中将 slab 分配到合适的节点上。
slab 结构体通过将 slab 链接到不同的列表中,可以方便地跟踪 slab 的使用情况,并优化对象的分配和释放。colouroff 成员用于实现多节点缓存颜色,以减少在多处理器系统中的缓存冲突。s_mem 指针指向 slab中第一个 object 对象的地址,并通过移动指针来快速分配对象。inuse 表示 slab 中已经被分配的对象数量,free 指向 slab 中第一个空闲对象的 kmem_bufctl_t 结构体,用于快速分配对象。nodeid 表示 slab 所在的节点 ID,用于在多节点系统中将 slab 分配到合适的节点上。
总的来说,slab 结构体是 Linux 内核中 SLAB 分配器的核心部分,通过链表和指针等技术来管理对象分配和释放,同时支持多节点系统和缓存颜色等高级特性。
如图所示:
2.3.2 OFF_SLAB
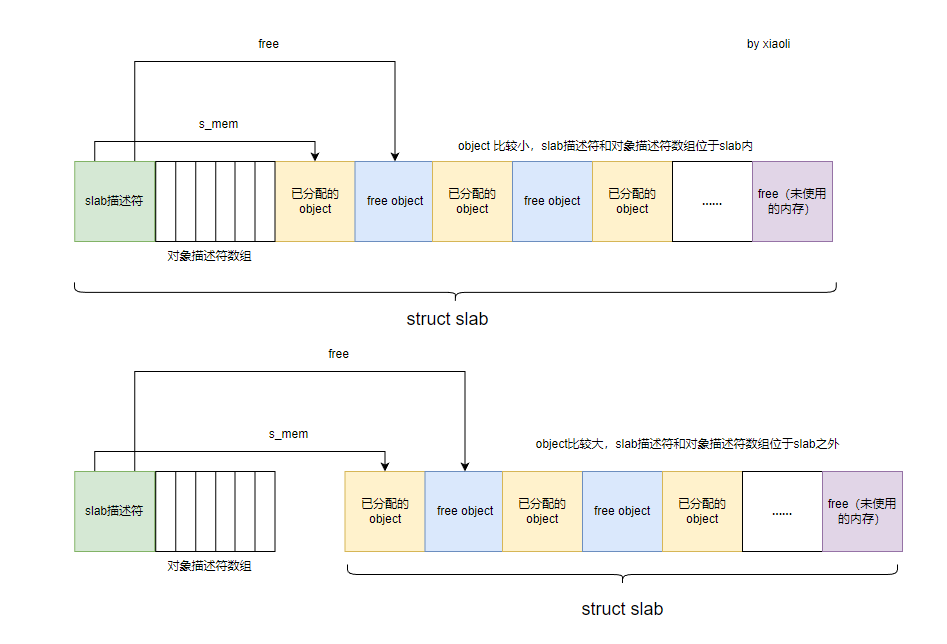
struct slab结构的实例存放位置有两种:一是将struct slab的实例放在物理页面首页的开始处;二是放在物理页面的外部。内核将从性能优化的角度出发来决定slab实例的存放位置,源码中的CFLGS_OFF_SLAB宏用于表示slab对象存放于外部。
OFF_SLAB()判断该 slab 描述符是否位于 slab 之外,如果是真则表示slab 描述符位于 slab 之外,否则slab 描述符位于 slab 中。
#define OFF_SLAB(x) ((x)->flags & CFLGS_OFF_SLAB)
struct kmem_cache *cachep;
OFF_SLAB(cachep);
struct kmem_cache {
......
unsigned int flags; /* constant flags */
......
}
如果 slab 描述符存在在 slab 的外部,那么高速缓存 struct kmem_cache 的 flags字段中的CFLGS_OFF_SLAB标志被置为1;否则被置为0。
在1.2 章节解释了该字段:flags是一个标志寄存器,定义缓存的全局性质。当前只有一个标志位。如果管理结构存储在slab外部,则置位CFLGS_OFF_SLAB。
对象长度比较大,那么最好将slab管理数据放置在slab之外(能够更好地填充实际对象)。确定是否将slab头存储在slab之上相对比较简单。如果对象长度大于页帧的1/8,则将slab管理数据存储在slab之外,否则存储在slab上。
在kmem_cache_create调用时显式设置CFLGS_OFF_SLAB,那么对较小的对象,也可以将slab头存储在slab之外。对于kmem_cache_create函数请参考4.1章节。
如下图所示:
三、创建和释放slab
3.1 创建slab
给高速缓存创建slab的时机:发起分配对象的申请,该高速缓存没有 free 的对象。此时便会创建新的 slab,比如 kmem_cache_alloc 函数,该函数 4.2 章节说明。
当调用kmem_cache_alloc 函数分配对象时,并且该该高速缓存没有 free 的对象就会调用 cache_grow 函数创建新的 slab。
cache_grow 函数函数如下所示:
/*
* Grow (by 1) the number of slabs within a cache. This is called by
* kmem_cache_alloc() when there are no active objs left in a cache.
*/
static int cache_grow(struct kmem_cache *cachep,
gfp_t flags, int nodeid, void *objp)
{
struct slab *slabp;
size_t offset;
gfp_t local_flags;
struct kmem_list3 *l3;
/*
* Be lazy and only check for valid flags here, keeping it out of the
* critical path in kmem_cache_alloc().
*/
BUG_ON(flags & GFP_SLAB_BUG_MASK);
local_flags = flags & (GFP_CONSTRAINT_MASK|GFP_RECLAIM_MASK);
/* Take the l3 list lock to change the colour_next on this node */
check_irq_off();
l3 = cachep->nodelists[nodeid];
spin_lock(&l3->list_lock);
/* Get colour for the slab, and cal the next value. */
offset = l3->colour_next;
l3->colour_next++;
if (l3->colour_next >= cachep->colour)
l3->colour_next = 0;
spin_unlock(&l3->list_lock);
offset *= cachep->colour_off;
if (local_flags & __GFP_WAIT)
local_irq_enable();
/*
* The test for missing atomic flag is performed here, rather than
* the more obvious place, simply to reduce the critical path length
* in kmem_cache_alloc(). If a caller is seriously mis-behaving they
* will eventually be caught here (where it matters).
*/
kmem_flagcheck(cachep, flags);
/*
* Get mem for the objs. Attempt to allocate a physical page from
* 'nodeid'.
*/
if (!objp)
objp = kmem_getpages(cachep, local_flags, nodeid);
if (!objp)
goto failed;
/* Get slab management. */
slabp = alloc_slabmgmt(cachep, objp, offset,
local_flags & ~GFP_CONSTRAINT_MASK, nodeid);
if (!slabp)
goto opps1;
slab_map_pages(cachep, slabp, objp);
cache_init_objs(cachep, slabp);
if (local_flags & __GFP_WAIT)
local_irq_disable();
check_irq_off();
spin_lock(&l3->list_lock);
/* Make slab active. */
list_add_tail(&slabp->list, &(l3->slabs_free));
STATS_INC_GROWN(cachep);
l3->free_objects += cachep->num;
spin_unlock(&l3->list_lock);
return 1;
opps1:
kmem_freepages(cachep, objp);
failed:
if (local_flags & __GFP_WAIT)
local_irq_disable();
return 0;
}
cache_grow() 函数是 kmem_cache_alloc() 函数的一个内部实现,用于在缓存中增加一个新的 slab 对象。
其中重点是 kmem_getpages 函数和 alloc_slabmgmt函数
3.1.1 kmem_getpages
kmem_getpages() 是 Linux 内核中用于从指定 NUMA 节点分配一组连续物理页面的函数。它通常在 cache_grow() 函数中使用,用于为新的 slab 对象分配物理页面。cache_grow() 函数是在 kmem_cache_alloc() 函数中没有可用对象时调用的,它负责为缓存分配新的 slab 并初始化其中的内存块。
kmem_getpages
-->alloc_pages_exact_node
-->__alloc_pages
-->__alloc_pages_nodemask
{
/* First allocation attempt */
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, nodemask, order,
zonelist, high_zoneidx, ALLOC_WMARK_LOW|ALLOC_CPUSET,
preferred_zone, migratetype);
if (unlikely(!page))
page = __alloc_pages_slowpath(gfp_mask, order,
zonelist, high_zoneidx, nodemask,
preferred_zone, migratetype);
}
该函数用于从指定的 NUMA 节点分配物理页面,使用伙伴系统算法,并返回页面的起始地址。它不需要持有缓存锁,因为它是在 cache_grow() 函数中被调用的,该函数已经持有了缓存锁。
函数的第一个参数 cachep 是指向 kmem_cache 结构体的指针,表示要从哪个缓存中分配页面。第二个参数 flags 是内存分配标志,可以包括 GFP_KERNEL、GFP_ATOMIC、__GFP_NOWARN、__GFP_HIGHMEM 等标志。第三个参数 nodeid 是 NUMA 节点的 ID。
函数内部首先会判断是否开启了 CONFIG_MMU 宏,如果没有,则需要在 flags 参数中设置 __GFP_COMP 标志,以便正确地计数高阶分配。然后,函数会将 cachep 中的 gfpflags 添加到 flags 参数中,并根据缓存的标志设置是否可回收标志。
接下来,函数调用 alloc_pages_exact_node() 函数从指定的 NUMA 节点中分配页面。该函数会尝试分配 cachep->gfporder 个连续页面,并返回一个指向页面起始地址的指针。如果分配失败,则返回 NULL。
如果分配成功,函数会将页面的数目 nr_pages 设置为 1 左移 gfporder。然后,它会根据缓存的标志设置页面状态,并将页面标记为 slab 页面。如果启用了 kmemcheck,则该函数会调用相应的 kmemcheck 函数来跟踪页面的使用情况。
最后,函数返回页面的起始虚拟地址。
return page_address(page);
总体来说,kmem_getpages() 函数是 Linux 内核中用于从指定 NUMA 节点分配物理页面的重要函数,它在缓存的生命周期内被频繁调用,以确保可靠和高效的内存分配。
3.1.2 alloc_slabmgmt
/*
* Get the memory for a slab management obj.
* For a slab cache when the slab descriptor is off-slab, slab descriptors
* always come from malloc_sizes caches. The slab descriptor cannot
* come from the same cache which is getting created because,
* when we are searching for an appropriate cache for these
* descriptors in kmem_cache_create, we search through the malloc_sizes array.
* If we are creating a malloc_sizes cache here it would not be visible to
* kmem_find_general_cachep till the initialization is complete.
* Hence we cannot have slabp_cache same as the original cache.
*/
static struct slab *alloc_slabmgmt(struct kmem_cache *cachep, void *objp,
int colour_off, gfp_t local_flags,
int nodeid)
{
struct slab *slabp;
if (OFF_SLAB(cachep)) {
/* Slab management obj is off-slab. */
slabp = kmem_cache_alloc_node(cachep->slabp_cache,
local_flags, nodeid);
/*
* If the first object in the slab is leaked (it's allocated
* but no one has a reference to it), we want to make sure
* kmemleak does not treat the ->s_mem pointer as a reference
* to the object. Otherwise we will not report the leak.
*/
kmemleak_scan_area(slabp, offsetof(struct slab, list),
sizeof(struct list_head), local_flags);
if (!slabp)
return NULL;
} else {
slabp = objp + colour_off;
colour_off += cachep->slab_size;
}
slabp->inuse = 0;
slabp->colouroff = colour_off;
slabp->s_mem = objp + colour_off;
slabp->nodeid = nodeid;
slabp->free = 0;
return slabp;
}
alloc_slabmgmt() 函数用于分配 slab 管理对象内存,该对象用于管理 slab 中对象的分配和释放。该函数接受多个参数,包括指向 kmem_cache 结构体的指针(cachep)、指向 slab 中第一个对象的指针(objp)、颜色偏移量(colour_off)、内存分配标志(local_flags)和节点 ID(nodeid)。
该函数首先检查 slab 描述符是否位于 slab 之外,这意味着 slab 描述符不存储在 slab 内部。在这种情况下,该函数将从 cachep->slabp_cache 缓存中分配 slab 管理对象内存。该缓存专门用于分配 slab 管理对象,用于管理 off-slab slab 描述符。函数还使用 kmemleak_scan_area() 函数对分配的 slab 管理对象执行内存泄漏检测。
如果 slab 描述符不位于 slab 之外,slab 描述符位于 slab 中,则该函数简单地将 slab 管理对象的地址计算为 objp + colour_off。
然后,该函数设置 slab 管理对象的属性,包括正在使用的对象数量(初始化为 0)、颜色偏移量、指向 slab 中第一个对象的指针、节点 ID 和 slab 中空闲对象的数量。
最后,该函数返回一个指向已分配的 slab 管理对象的指针。
3.1.3 slab_map_pages
/*
* Map pages beginning at addr to the given cache and slab. This is required
* for the slab allocator to be able to lookup the cache and slab of a
* virtual address for kfree, ksize, kmem_ptr_validate, and slab debugging.
*/
static void slab_map_pages(struct kmem_cache *cache, struct slab *slab,
void *addr)
{
int nr_pages;
struct page *page;
page = virt_to_page(addr);
nr_pages = 1;
if (likely(!PageCompound(page)))
nr_pages <<= cache->gfporder;
do {
page_set_cache(page, cache);
page_set_slab(page, slab);
page++;
} while (--nr_pages);
}
slab_map_pages() 函数是 Linux 内核中用于映射物理页面到 slab 的一个函数。
该函数用于将一个虚拟地址映射到给定的缓存和 slab,这是为了让 slab 分配器能够查找虚拟地址的缓存和 slab,以进行 kfree、ksize、kmem_ptr_validate 和 slab 调试等操作。
函数的第一个参数 cache 是指向 kmem_cache 结构体的指针,表示要映射到的缓存。第二个参数 slab 是指向 slab 结构体的指针,表示要映射到的 slab。第三个参数 addr 是要映射的虚拟地址。
函数内部首先将该虚拟地址转换为对应的物理页面,然后计算需要映射的页面数目。如果该页面不是一个复合页面(Compound Page),则将页面数目左移 cache->gfporder 位,以便正确计算页面数目。
接下来,函数使用 page_set_cache() 和 page_set_slab() 函数将所有页面映射到缓存和 slab,以便进行后续的分配和释放操作。其中,page_set_cache() 函数用于将页面的 PagePrivate 标志设置为缓存的地址,表示该页面属于该缓存;page_set_slab() 函数用于将页面的 PageSlab 标志设置为 slab 的地址,表示该页面属于该 slab。
最后,函数返回,完成页面映射操作。
3.2 释放slab
释放slab的场景:
(1)当高速缓存中有很多 free 对象时.
(2)被周期性调用的定时器函数确定是否有完全未使用的 slab 能被释放。
源码如下:
**
* slab_destroy - destroy and release all objects in a slab
* @cachep: cache pointer being destroyed
* @slabp: slab pointer being destroyed
*
* Destroy all the objs in a slab, and release the mem back to the system.
* Before calling the slab must have been unlinked from the cache. The
* cache-lock is not held/needed.
*/
static void slab_destroy(struct kmem_cache *cachep, struct slab *slabp)
{
void *addr = slabp->s_mem - slabp->colouroff;
slab_destroy_debugcheck(cachep, slabp);
if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU)) {
struct slab_rcu *slab_rcu;
slab_rcu = (struct slab_rcu *)slabp;
slab_rcu->cachep = cachep;
slab_rcu->addr = addr;
call_rcu(&slab_rcu->head, kmem_rcu_free);
} else {
kmem_freepages(cachep, addr);
if (OFF_SLAB(cachep))
kmem_cache_free(cachep->slabp_cache, slabp);
}
}
slab_destroy() 函数是 Linux 内核中用于销毁一个 slab 的函数之一。
该函数用于销毁一个 slab 中的所有对象,并将内存释放回系统。在调用该函数之前,必须将 slab 从缓存中取消链接。函数内部不需要持有/需要缓存锁。
函数的第一个参数 cachep 是指向 kmem_cache 结构体的指针,表示要销毁的缓存。第二个参数 slabp 是指向 slab 结构体的指针,表示要销毁的 slab。
函数首先计算 slab 的起始地址,通过slabp->s_mem - slabp->colouroff获取其起始地址addr。然后调用 slab_destroy_debugcheck() 函数进行调试检查,以确保 slab 可以安全地被销毁。如果缓存的标志包括 SLAB_DESTROY_BY_RCU,则将 slab_rcu 结构体强制转换为 slabp,并将其 cachep 和 addr 字段进行设置。接下来,函数使用 call_rcu() 函数将 slab_rcu 结构体加入到 RCU 等待队列中,以便在释放内存时进行 RCU 回调。如果缓存的标志不包括 SLAB_DESTROY_BY_RCU,则调用 kmem_freepages() 函数将分配给该 slab 的连续物理页面释放回伙伴管理系统。如果该slab 描述符不存储在 slab 内部,则调用 kmem_cache_free() 函数释放该 slab 的管理对象。
最后,函数返回,完成 slab 的销毁操作。
四、分配和释放高速缓存
4.1 kmem_cache_create
/**
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo to identify this cache.
* @size: The size of objects to be created in this cache.
* @align: The required alignment for the objects.
* @flags: SLAB flags
* @ctor: A constructor for the objects.
*
* Returns a ptr to the cache on success, NULL on failure.
* Cannot be called within a int, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache.
*
* @name must be valid until the cache is destroyed. This implies that
* the module calling this has to destroy the cache before getting unloaded.
* Note that kmem_cache_name() is not guaranteed to return the same pointer,
* therefore applications must manage it themselves.
*
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*/
struct kmem_cache *
kmem_cache_create (const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *))
{
......
}
其中,各参数的含义如下:
name:kmem_cache 对象的名称,用于标识该对象,长度不能超过 KNAME_MAX(32)个字符。
size:每个内存块的大小,以字节为单位。该值必须是 2 的次幂,并且不能小于 sizeof(void *)。
align:内存块的对齐方式,以字节为单位。该值必须是 2 的次幂,不能小于 sizeof(void *)。
flags:指定 kmem_cache 对象的行为标志(例如是否支持高速缓存、是否支持 SLAB 分配器等)。
ctor:指定一个构造函数,用于在分配内存块时初始化该内存块。
kmem_cache_create() 函数的返回值是一个指向新创建的 kmem_cache 对象的指针。
比如:
# define alloc_task_struct() kmem_cache_alloc(task_struct_cachep, GFP_KERNEL)
# define free_task_struct(tsk) kmem_cache_free(task_struct_cachep, (tsk))
static struct kmem_cache *task_struct_cachep;
/* create a slab on which task_structs can be allocated */
task_struct_cachep =
kmem_cache_create("task_struct", sizeof(struct task_struct),
ARCH_MIN_TASKALIGN, SLAB_PANIC | SLAB_NOTRACK, NULL);
4.2 kmem_cache_alloc
4.2.1 代码说明
/**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache. The flags are only relevant
* if the cache has no available objects.
*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *ret = __cache_alloc(cachep, flags, __builtin_return_address(0));
trace_kmem_cache_alloc(_RET_IP_, ret,
obj_size(cachep), cachep->buffer_size, flags);
return ret;
}
EXPORT_SYMBOL(kmem_cache_alloc);
kmem_cache_alloc最后调用____cache_alloc函数:
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *objp;
struct array_cache *ac;
check_irq_off();
ac = cpu_cache_get(cachep);
if (likely(ac->avail)) {
STATS_INC_ALLOCHIT(cachep);
ac->touched = 1;
objp = ac->entry[--ac->avail];
} else {
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep, flags);
}
/*
* To avoid a false negative, if an object that is in one of the
* per-CPU caches is leaked, we need to make sure kmemleak doesn't
* treat the array pointers as a reference to the object.
*/
kmemleak_erase(&ac->entry[ac->avail]);
return objp;
}
___cache_alloc(),是 kmem_cache_alloc() 函数的内部实现函数。该函数用于从指定的 kmem_cache 对象中分配一个内存块,并返回指向该内存块的指针。
该函数使用了以下参数:
(1)cachep:指向 kmem_cache 对象的指针。
(2)flags:指定内存分配的行为标志(例如内存分配的类型、内存分配的优先级等)。
该函数的实现过程如下:
(1)调用 cpu_cache_get() 函数获取当前 CPU 上的 array_cache 对象,该对象用于缓存内存块。
(2)如果 array_cache 中有可用的内存块,则从中分配一个内存块,并返回指向该内存块的指针。
(3)如果 array_cache 中没有可用的内存块,则调用 cache_alloc_refill() 函数从高速缓存(slabs_partial 和 slabs_free)中获取内存块,填充到 array_cache 中,并返回指向新分配的内存块的指针。
详细过程:
(1)在进入该函数之前,该函数假设调用者已经关闭了中断,以避免在分配内存块期间发生上下文切换。
(2)该函数首先调用 cpu_cache_get() 函数获取当前 CPU 上的 array_cache 对象,用于缓存内存块。该函数通过访问 per-CPU 变量来获取 array_cache,以避免不必要的锁竞争。
(3)如果 array_cache 中有可用的内存块,则直接返回最后一个内存块的指针,并将 array_cache 中可用内存块的数量减 1。此时,该内存块仍然在 array_cache 中,可以被多次分配使用,直到 array_cache 被重新填充或被销毁。
(4)如果 array_cache 中没有可用的内存块,则调用 cache_alloc_refill() 函数从高速缓存中获取内存块,并将这些内存块填充到 array_cache 中。填充后,该函数返回 array_cache 中的第一个内存块的指针,并将 array_cache 中可用内存块的数量设置为 array_cache 的大小减 1。
(5)在返回指针之前,该函数还调用 kmemleak_erase() 函数,将该内存块的地址从 kmemleak 缓存中移除,以避免误报内存泄漏。这是因为 kmemleak 缓存会记录内核中的所有分配和释放操作,并在内存泄漏检测期间使用这些信息来检测内存泄漏。
(6)该函数使用了 likely() 和 unlikely() 宏,以提高代码的效率。这些宏用于告诉编译器哪些分支是更可能发生的,以便编译器可以生成更有效的代码。
4.2.2 cache_alloc_refill
其中 cache_alloc_refill 比较重要:
static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags)
{
int batchcount;
struct kmem_list3 *l3;
struct array_cache *ac;
int node;
retry:
check_irq_off();
node = numa_node_id();
ac = cpu_cache_get(cachep);
batchcount = ac->batchcount;
if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {
/*
* If there was little recent activity on this cache, then
* perform only a partial refill. Otherwise we could generate
* refill bouncing.
*/
batchcount = BATCHREFILL_LIMIT;
}
l3 = cachep->nodelists[node];
BUG_ON(ac->avail > 0 || !l3);
spin_lock(&l3->list_lock);
/* See if we can refill from the shared array */
if (l3->shared && transfer_objects(ac, l3->shared, batchcount))
goto alloc_done;
while (batchcount > 0) {
struct list_head *entry;
struct slab *slabp;
/* Get slab alloc is to come from. */
entry = l3->slabs_partial.next;
if (entry == &l3->slabs_partial) {
l3->free_touched = 1;
entry = l3->slabs_free.next;
if (entry == &l3->slabs_free)
goto must_grow;
}
slabp = list_entry(entry, struct slab, list);
check_slabp(cachep, slabp);
check_spinlock_acquired(cachep);
/*
* The slab was either on partial or free list so
* there must be at least one object available for
* allocation.
*/
BUG_ON(slabp->inuse >= cachep->num);
while (slabp->inuse < cachep->num && batchcount--) {
STATS_INC_ALLOCED(cachep);
STATS_INC_ACTIVE(cachep);
STATS_SET_HIGH(cachep);
ac->entry[ac->avail++] = slab_get_obj(cachep, slabp,
node);
}
check_slabp(cachep, slabp);
/* move slabp to correct slabp list: */
list_del(&slabp->list);
if (slabp->free == BUFCTL_END)
list_add(&slabp->list, &l3->slabs_full);
else
list_add(&slabp->list, &l3->slabs_partial);
}
must_grow:
l3->free_objects -= ac->avail;
alloc_done:
spin_unlock(&l3->list_lock);
if (unlikely(!ac->avail)) {
int x;
x = cache_grow(cachep, flags | GFP_THISNODE, node, NULL);
/* cache_grow can reenable interrupts, then ac could change. */
ac = cpu_cache_get(cachep);
if (!x && ac->avail == 0) /* no objects in sight? abort */
return NULL;
if (!ac->avail) /* objects refilled by interrupt? */
goto retry;
}
ac->touched = 1;
return ac->entry[--ac->avail];
}
该函数用于从中心缓存中获取一些内存块,填充到当前 CPU 上的 array_cache 中,并返回指向新分配的内存块的指针。
该函数使用了以下参数:
(1)cachep:指向 kmem_cache 对象的指针。
(2)flags:指定内存分配的行为标志(例如内存分配的类型、内存分配的优先级等)。
该函数的实现过程如下:
(1)调用 cpu_cache_get() 函数获取当前 CPU 上的 array_cache 对象,该对象用于缓存内存块。
(2)检查 array_cache 的 batchcount 值,用于控制一次从中心缓存中获取多少内存块。如果 array_cache 最近没有被访问过,而且 batchcount 大于 BATCHREFILL_LIMIT(一个预定义的常量),则将 batchcount 设置为 BATCHREFILL_LIMIT。这是为了防止频繁地从中心缓存中获取内存块,导致不必要的缓存刷新。
(3)获取当前 NUMA 节点的 kmem_list3 对象,该对象维护了该节点上的 slab 分配器的状态信息。
(4)如果 kmem_list3 中有共享的 slab,则调用 transfer_objects() 函数将一些内存块从共享的 slab 中转移到当前 CPU 的 array_cache 中,以提高效率。
(5)如果无法从共享的 slab 中获取内存块,则从 kmem_list3 的 slabs_partial/slabs_free 列表中获取 slab,并将其中的内存块填充到 array_cache 中。具体地,该函数会遍历 slabs_partial/slabs_free 列表,找到第一个有可用内存块的 slab,然后将所有可用内存块从该 slab 中分配到 array_cache 中。
(6)如果所有的 partial/slack_free slab 都被用完了,则调用 cache_grow() 函数扩展缓存池,以获取更多的内存块。如果 cache_grow() 函数返回 0,则表示无法分配内存块,该函数返回 NULL。否则,该函数会重新获取当前 CPU 上的 array_cache 对象,并检查其中是否有可用的内存块。
(7)在返回指针之前,该函数将 array_cache 的 touched 标志设置为 1,表示最近有活动发生在该 array_cache 上。
4.2.3 总结分配过程
(1)
从当前CPU的 struct array_cache 找可用的 free 内存对象:
struct array_cache *ac;
objp = ac->entry[--ac->avail];
(2)
cache_alloc_refill
{
struct kmem_list3 *l3;
l3->slabs_partial;
l3->slabs_free;
}
先从slabs_partial 中找 free slab,如果没有再从 slabs_free 中获取free slab。
找到后填充到当前CPU的 struct array_cache,然后返回:
return ac->entry[--ac->avail];
(3)
如果在slabs_partial 和 slabs_free 没有找到,调用cache_grow给高速缓存分配一个新的 slab。
cache_grow调用kmem_getpages从伙伴系统申请连续的内存,然后调用 alloc_slabmgmt 新建一个 slab。
cache_grow()
{
/*
* Get mem for the objs. Attempt to allocate a physical page from
* 'nodeid'.
*/
kmem_getpages()
/* Get slab management. */
struct slab *slabp;
slabp = alloc_slabmgmt();
}
4.3 kmem_cache_free
/**
* kmem_cache_free - Deallocate an object
* @cachep: The cache the allocation was from.
* @objp: The previously allocated object.
*
* Free an object which was previously allocated from this
* cache.
*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
{
unsigned long flags;
local_irq_save(flags);
debug_check_no_locks_freed(objp, obj_size(cachep));
if (!(cachep->flags & SLAB_DEBUG_OBJECTS))
debug_check_no_obj_freed(objp, obj_size(cachep));
__cache_free(cachep, objp);
local_irq_restore(flags);
trace_kmem_cache_free(_RET_IP_, objp);
}
EXPORT_SYMBOL(kmem_cache_free);
kmem_cache_free用于将之前由 kmem_cache_alloc() 分配的内存块释放回内存池。
其中,cachep 是指向 kmem_cache 对象的指针,objp 是指向要释放的内存块的指针。
释放过程在__cache_free函数中:
/*
* Release an obj back to its cache. If the obj has a constructed state, it must
* be in this state _before_ it is released. Called with disabled ints.
*/
static inline void __cache_free(struct kmem_cache *cachep, void *objp)
{
struct array_cache *ac = cpu_cache_get(cachep);
check_irq_off();
kmemleak_free_recursive(objp, cachep->flags);
objp = cache_free_debugcheck(cachep, objp, __builtin_return_address(0));
kmemcheck_slab_free(cachep, objp, obj_size(cachep));
/*
* Skip calling cache_free_alien() when the platform is not numa.
* This will avoid cache misses that happen while accessing slabp (which
* is per page memory reference) to get nodeid. Instead use a global
* variable to skip the call, which is mostly likely to be present in
* the cache.
*/
if (nr_online_nodes > 1 && cache_free_alien(cachep, objp))
return;
if (likely(ac->avail < ac->limit)) {
STATS_INC_FREEHIT(cachep);
ac->entry[ac->avail++] = objp;
return;
} else {
STATS_INC_FREEMISS(cachep);
cache_flusharray(cachep, ac);
ac->entry[ac->avail++] = objp;
}
}
是 kmem_cache_free() 函数的内部实现函数之一。该函数用于将之前由 kmem_cache_alloc() 分配的内存块释放回内存池,并将内存块添加到当前 CPU 上的 array_cache 中。
该函数使用了以下参数:
(1)cachep:指向 kmem_cache 对象的指针。
(2)objp:指向要释放的内存块的指针。
该函数的实现过程如下:
(1)调用 check_irq_off() 宏来检查中断是否已关闭,以确保在释放内存块时不会发生上下文切换。这是因为中断可以调度其他进程,并且在释放内存块时可能会导致竞争条件。
(2)调用 kmemleak_free_recursive() 函数来递归地释放内存块。该函数用于检测内存泄漏,并在内存块被释放时记录泄漏信息。
(3)调用 cache_free_debugcheck() 函数来检查内存块是否已被释放或重复释放。该函数用于调试和检测内存管理错误。
(4)调用 kmemcheck_slab_free() 函数来标记内存块已被释放。该函数用于检测内存越界和使用未初始化的内存。
(5)调用 cache_free_alien() 函数来检查内存块是否应该被返回到中心缓存。该函数用于处理 NUMA 系统中的内存分配。
(6)如果当前 CPU 上的 array_cache 有可用的空间,则将内存块添加到 array_cache 中,并增加 array_cache 的 avail 值。如果添加成功,则返回。
(7)如果当前 CPU 上的 array_cache 没有可用的空间,则调用 cache_flusharray() 函数将 array_cache 中的内存块回收到中心缓存中,并将内存块添加到 array_cache 中。然后,增加 array_cache 的 avail 值,并返回。
其中 cache_flusharray 函数比较重要:
static void cache_flusharray(struct kmem_cache *cachep, struct array_cache *ac)
{
int batchcount;
struct kmem_list3 *l3;
int node = numa_node_id();
batchcount = ac->batchcount;
#if DEBUG
BUG_ON(!batchcount || batchcount > ac->avail);
#endif
check_irq_off();
l3 = cachep->nodelists[node];
spin_lock(&l3->list_lock);
if (l3->shared) {
struct array_cache *shared_array = l3->shared;
int max = shared_array->limit - shared_array->avail;
if (max) {
if (batchcount > max)
batchcount = max;
memcpy(&(shared_array->entry[shared_array->avail]),
ac->entry, sizeof(void *) * batchcount);
shared_array->avail += batchcount;
goto free_done;
}
}
free_block(cachep, ac->entry, batchcount, node);
free_done:
spin_unlock(&l3->list_lock);
ac->avail -= batchcount;
memmove(ac->entry, &(ac->entry[batchcount]), sizeof(void *)*ac->avail);
}
以下是cache_flusharray函数的详细分析:
(1)首先,获取array_cache中的batchcount值,并检查其是否为有效值。batchcount表示要释放的内存块的数量。
(2)调用check_irq_off()宏来检查中断是否已关闭,以确保在释放内存块时不会发生上下文切换。这是因为中断可以调度其他进程,并且在释放内存块时可能会导致竞争条件。
(3)获取当前CPU所在的NUMA节点的ID。
(4)获取NUMA节点的kmem_list3对象,并使用spin_lock()函数锁定kmem_list3的list_lock成员以保证原子性。
(5)如果kmem_list3已经共享了array_cache,则将内存块添加到共享的array_cache中。如果共享的array_cache已满,则跳转到第9步。
(6)获取共享的array_cache的可用空间的最大值,并将batchcount值与该最大值进行比较,以确保不会超过可用空间的最大值。
(7)将内存块从当前CPU的array_cache中复制到共享的array_cache中,并更新共享的array_cache的avail值。
(8)跳转到第10步。
(9)如果kmem_list3尚未共享array_cache或共享的array_cache已满,则调用free_block()函数将内存块添加到kmem_list3中。该函数会在kmem_list3中查找未满的slab,并将内存块添加到该slab中。如果找不到未满的slab,则会调用new_slab()函数创建一个新的slab。free_block()函数还会更新kmem_list3的free_slabs成员,并将slab添加到对应的slab_chain中。
解锁kmem_list3的list_lock成员,减少array_cache的avail值,然后将剩余的内存块复制到array_cache的开头。
其中free_block函数:
/*
* Caller needs to acquire correct kmem_list's list_lock
*/
static void free_block(struct kmem_cache *cachep, void **objpp, int nr_objects,
int node)
{
int i;
struct kmem_list3 *l3;
for (i = 0; i < nr_objects; i++) {
void *objp = objpp[i];
struct slab *slabp;
slabp = virt_to_slab(objp);
l3 = cachep->nodelists[node];
list_del(&slabp->list);
check_spinlock_acquired_node(cachep, node);
check_slabp(cachep, slabp);
slab_put_obj(cachep, slabp, objp, node);
STATS_DEC_ACTIVE(cachep);
l3->free_objects++;
check_slabp(cachep, slabp);
/* fixup slab chains */
if (slabp->inuse == 0) {
if (l3->free_objects > l3->free_limit) {
l3->free_objects -= cachep->num;
/* No need to drop any previously held
* lock here, even if we have a off-slab slab
* descriptor it is guaranteed to come from
* a different cache, refer to comments before
* alloc_slabmgmt.
*/
slab_destroy(cachep, slabp);
} else {
list_add(&slabp->list, &l3->slabs_free);
}
} else {
/* Unconditionally move a slab to the end of the
* partial list on free - maximum time for the
* other objects to be freed, too.
*/
list_add_tail(&slabp->list, &l3->slabs_partial);
}
}
}
该函数是 kmem_cache_free() 函数的内部实现之一,用于将一组内存块添加到 kmem_cache 的空闲列表中。以下是该函数的详细分析:
(1)首先,遍历内存块数组,对每个内存块执行以下操作:
(2)获取内存块所在的 slab 对象。
(3)获取 kmem_cache 对象的 nodelists 数组中对应 NUMA 节点的 kmem_list3 对象。
(4)使用 list_del() 函数从 slab 对象在用列表中删除该 slab 对象。
(5)使用 check_spinlock_acquired_node() 函数检查当前进程是否已经获得 kmem_list3 的 list_lock 锁。
(6)使用 check_slabp() 函数检查 slab 对象的一些状态是否符合预期。
(7)调用 slab_put_obj() 函数将内存块放回到 slab 中。
(8)使用 STATS_DEC_ACTIVE() 宏将 kmem_cache 的 active_slabs 成员的值减一。
(9)将 kmem_list3 的 free_objects 成员加一。
(10)再次使用 check_slabp() 函数检查 slab 对象的一些状态是否符合预期。
(11)如果该 slab 对象中的内存块全部都已经被释放,则执行以下操作:
(12) 如果 kmem_list3 的 free_objects 成员超过了 free_limit 值,则调用 slab_destroy() 函数销毁该 slab 对象。 slab_destroy() 函数请参考 3.2 章节。
(13)否则,将该 slab 对象添加到 kmem_list3 的 slabs_free 列表中。
(14)如果该 slab 对象中的内存块还有剩余,则将该 slab 对象添加到 kmem_list3 的 slabs_partial 列表的末尾。
五、slab着色
5.1 简介
(1)
Slab 着色(slab coloring)是一种用于改善 Linux 内核中 Slab 分配器性能的技术。它的目的是充分利用CPU硬件高速缓存,由于CPU的硬件高速缓存由多个缓存行(cache line)组成,Slab 着色目的也就是为了充分利用其他的高速缓存行。
一个slab(或者说一个kmem_cache)中对象的大小都是一样的,多个对象被映射到同一个缓存行(cache line),这样会导致在CPU的同一个硬件高速缓存行来回传送相同的对象,这样其他的硬件高速缓存行并未得到充分的利用,Slab 着色让CPU的硬件高速缓存的缓存行都得到充分的利用,提高系统性能。
Slab 着色通过将对象分散到多个 slab 中来充分利用CPU硬件高速缓存的缓存行。它使用一种称为“颜色”的技术,该技术将 slab 分成若干个颜色组,每个颜色组包含一组 slab,且相邻颜色组中的 slab 具有不同的偏移量。对象被分配到与其所在颜色组相同的 slab 中,这样就可以将对象分散到不同的 slab 中,从而充分利用CPU硬件高速缓存的缓存行。
简单点来说slab着色就是让每一个slab分配器对应不同数量的高速缓存行,让不同的slab分配器上同一个相对位置slab对象的起始地址在高速缓存中相互错开,从而充分利用CPU硬件高速缓存的缓存行。
(2)
通过slab着色(slab coloring),slab分配器能够均匀地分布对象,以实现均匀的缓存利用。
5.2 slab 着色
(1)
着色前 slab 的布局(这里省略了slab描述后面的对象描述符数组):
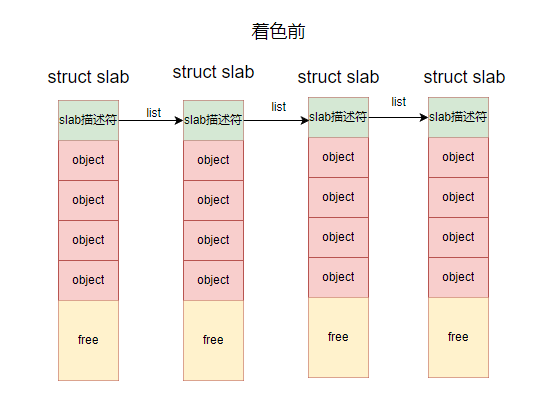
一个slab的大小 : slab描述符的大小(加上对象描述符数组的大小) + object 的 数目 * object 的大小 + free 的大小。
free 是slab 内未用的字节(没有分配给对象的字节)。
着色区就是使用的是 free 这一部分的字节。
(2)
着色后的布局(这里省略了slab描述后面的对象描述符数组):

着色允许内存分配把 object 对象展开在不同的线性地址之中,具有不同颜色的 slab 把 slab 的第一个对象放在不同的内层单元,而且满足对其约束,这样就能充分利用CPU的硬件高速缓存行。
比如上图中不同slab的第一个object对象的相对地址就没有对齐。
着色的本质是是把 slab 中的 一个 free 空间从末尾移动到最前面。
只有当 free 足够大的时候着色才气作用。
其中 colouroff 是 slab 中的字段:
struct slab {
unsigned long colouroff;
};
colouroff 表示 slab 中第一个对象的偏移。
colouroff的大小由高速缓存中 colour_off 和 colour_next 计算得到。
struct kmem_cache {
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
};
/*
* The slab lists for all objects.
*/
struct kmem_list3 {
unsigned int colour_next; /* Per-node cache coloring */
};
static int cache_grow(struct kmem_cache *cachep,
gfp_t flags, int nodeid, void *objp)
{
......
/* Take the l3 list lock to change the colour_next on this node */
check_irq_off();
l3 = cachep->nodelists[nodeid];
spin_lock(&l3->list_lock);
/* Get colour for the slab, and cal the next value. */
offset = l3->colour_next;
l3->colour_next++;
if (l3->colour_next >= cachep->colour)
l3->colour_next = 0;
spin_unlock(&l3->list_lock);
offset *= cachep->colour_off;
.....
}
简单点即:
colouroff = colour_off * colour_next + sizeof(struct slab) + num*sizeof(kmem_bufctl_t)
其中num是一个slab中 object 对象的个数。
六、cache_cache
对于每一个slab分配器,都需要一个struct kmem_cache实例,那么,在slab系统尚未完全建立起来时,kmem_cache实例所在的空间从哪里分配呢,答案是系统在初始化期间提供了一个特殊的slab分配器cache_cache,专门用来分配struct kmem_cache空间。
因为cache_cache在slab系统还未完备时就被创造了出来,所以这个struct kmem_cache结构采用了静态内存分配的方法。如下所示:
/* internal cache of cache description objs */
static struct kmem_cache cache_cache = {
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.shared = 1,
.buffer_size = sizeof(struct kmem_cache),
.name = "kmem_cache",
};
[root@localhost ~]# cat /proc/kallsyms | grep '\<cache_cache\>'
ffffffff81ad5920 d cache_cache
[root@localhost ~]# cat /proc/slabinfo | grep '\<kmem_cache\>'
kmem_cache 189 189 32896 1 16 : tunables 8 4 0 : slabdata 189 189 0
这个最早的kmem_cache的名字"kmem_cache",告诉我们它所领衔的slab分配器专门用来分配struct kmem_cache这样的内存对象,.buffer_size =sizeof(struct kmem_cache)则为这个论断提供了进一步的佐证。因为系统在初始化cache_cache时伙伴系统已经完备,所以如果采用把struct slab放在页面内部的方式,这个slab分配器就可以工作了。
参考资料
Linux 2.6.32
深入理解 Linux 内核
深入 Linux 内核架构
深入Linux设备驱动程序内核机制
奔跑吧 Linux 内核
https://www.cnblogs.com/tolimit/p/4566189.html
https://www.kernel.org/doc/gorman/html/understand/understand011.html
https://zhuanlan.zhihu.com/p/105582468
![常用数据分类算法原理介绍、优缺点分析与代码实现[LR/RF/DT/SVM/NavieBayes/GBDT/XGBoost/DNN/LightGBM等]](https://img-blog.csdnimg.cn/img_convert/efaea374885bff814a48b6cd39b6ac8e.png)






![[分布式] zookeeper集群与kafka集群](https://img-blog.csdnimg.cn/a47d8395b480496498dfd5d56a6bbf84.png)
![[NGINX] NGINX下载、安装编译、启动检查停止命令](https://img-blog.csdnimg.cn/49f84cde53304a75ad26254f10fc06a8.png)