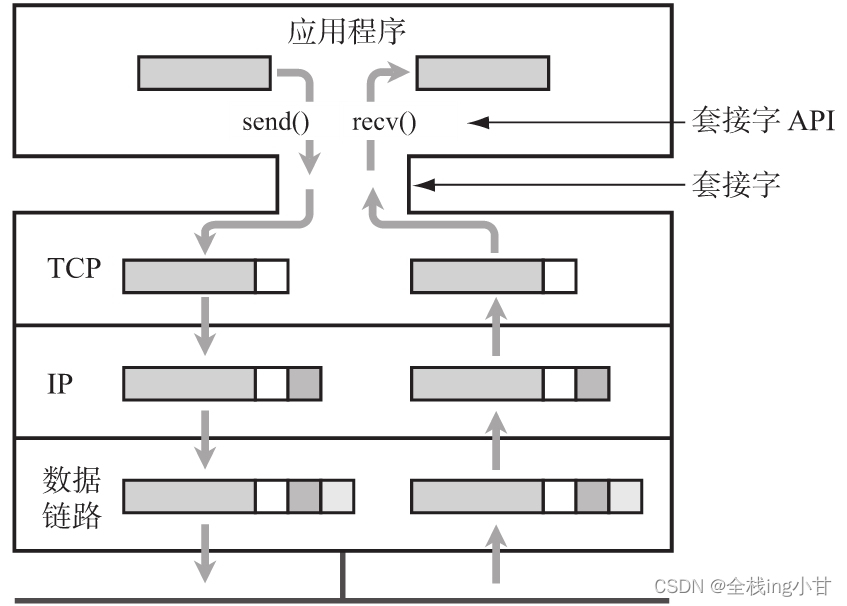
目录
写在前面:
下面开始进入正文,正文很长,先概述要点步骤,以防迷路。
先看最终结果(当前价格为2023-07-10收盘价)
1 下载股票基本信息、股票日数据
step one
step two
2 从股票日数据中提取股票月数据
3 从股票基本信息中提起股票代码和股票简称键值对
4 开始计算当前价格与历史最高价的纵向距离和横向距离
写在前面:
1 这里的底部是指距离历史最高价位置较远的股票,不能确定是底部,但可以暂时预设为底部去思考
2 “当前价格与历史最高价位置距离”在技术上怎么体现?我看网上有多种方式判断,本文取两个方法。
方法一:将历史最高价对折,再对折,再对折,。。。直到最靠近当前价格,对折次数越多表示距离越远
方法二:当前价格相当于历史最高价格的几分之几,就是(当前价格/历史最高价格)*100%,值越小表示距离越远
3 上面【2】中提到的“当前价格与历史最高价位置距离”本文定义为纵向距离;两个价格点位之间相隔的月份数文本定义为横向距离
4 本文提供的方法只是缩小寻找范围,并不代表着找出来的结果都有在可能的底部横盘
下面开始进入正文,正文很长,先概述要点步骤,以防迷路。
1 下载股票基本信息、股票日数据
2 从股票日数据中提取股票月数据
3 从股票基本信息中提起股票代码和股票简称键值对
4 开始计算当前价格与历史最高价的纵向距离和横向距离
先看最终结果(当前价格为2023-07-10收盘价)

最终结果字段说明
| 字段名 | 说明 |
| 上市至今月份数 | 股票上市时间越长,存在长时间底部横盘的可能性也比较大 |
| 最近一次最高价 | 这里强调“最近”是考虑可能出现多个时间点出现相同最高价的情况,这种情况取距离现在最近的这次最高价 |
| 最高价对应的月份 | 计算横向距离的起点位置 |
| 几折股票 | 定义看前文“写在前面”。算式:最高价除以当前价格的结果取2的对数 |
| 当前价格相对最高价格百分比 | 这个就容易理解了。算式:当前价格除以最高价乘以百分百 |
取结果中的“神州高铁”在同花顺中看下
 股票月线级别确实在底部横盘了一段时间
股票月线级别确实在底部横盘了一段时间
1 下载股票基本信息、股票日数据
1)本文数据来自“优矿”,之所以选择优矿的数据,是优矿给的股票日数据字段很全,包括换手率、滚动PE等,这些字段在做其他研究时可以直接取用。
2)这里建议下载优矿的未复权日数据,如果直接下载前复权,意味着以后每回都得从上市时间下载,如果是未复权数据,后续只要做增量下载就可以。未复权数据中有一个accumAdjFactor字段,这个字段是累积前复权因子,要计算前复权数据只要将未复权数据乘以accumAdjFactor就可以得到前复权数据。
3)优矿使用手机号注册,每天可以免费下载30M的数据。
4)本文使用到的股票数据字段,日期、开盘价、收盘价、最高价、最低价,为前复权数据,大家使用其他来源的数据只要确保有这5个字段就可以。
step one
打开优矿,注册后登录。
点击“研究数据”

点击右侧“展开详情”,然后“复制代码”

进入“开始研究” ,新建Notebook,并进入新建的Notebook

将刚刚复制的代码黏贴进去,做一点小修改,这就是基础的python了,这里不赘述,代码处理好后,点击右上角“运行”,运行完毕后,进入左侧竖条菜单中的“数据” ,就可以看到刚刚运行生成的文件
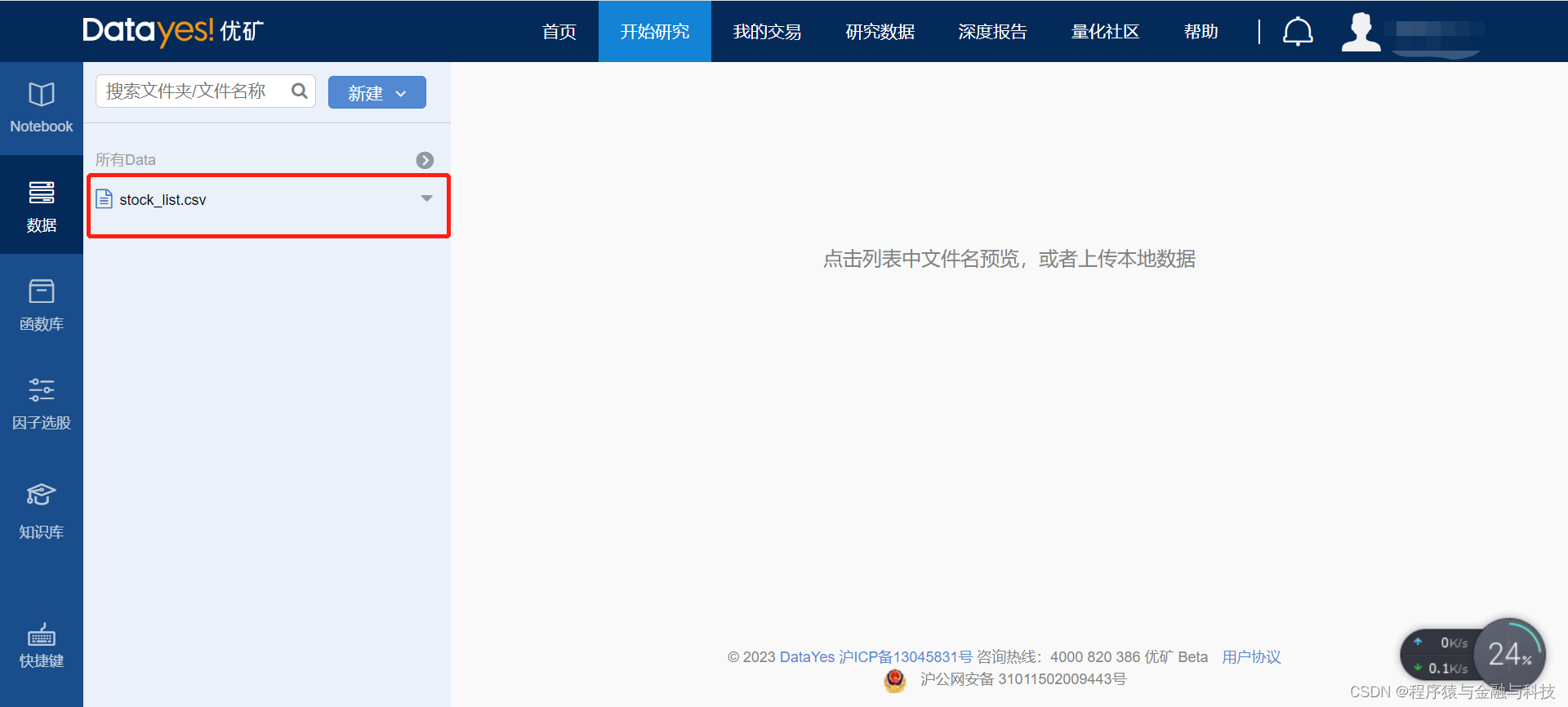
这个文件玖可以下载了。
股票日数据用以下这个代码,其余过程与上面获取股票基本数据一致,不再赘述。
注:由于优矿每天只能下载30M,每次生成的股票个数要控制下,超过30M没法下载

step two
下载后的股票日数据是多个股票集中在一个文件里,为方便后续处理,最好一个股票的日数据单独存储一个文件。
python处理:pandas读入文件生成DataFrame,对secID进行分组,每组单独存储为一个文件
# 000.csv是从优矿中下载的股票日数据文件
file_path = r'D:/000.csv'
# 用于存储单个股票日数据的目录
save_dir = r'E:/results/'
df = pd.read_csv(file_path,encoding='utf-8')
df['tradeDate'] = pd.to_datetime(df['tradeDate'])
df_group = df.groupby(by='secID')
for name,group in df_group:
ticker = name.split('.')[0]
group.to_csv(save_dir+ticker+'.csv',encoding='utf-8')
pass分解完后,就是股票的日数据都存储在单一文件里

2 从股票日数据中提取股票月数据
月数据开盘价 等于 该月第一个交易日的开盘价
月数据收盘价 等于 该月最后一个交易的收盘价
月数据最高价 等于 该月所有交易日中的最高价
月数据最低价 等于 该月所有交易日中的最低价
python处理:pandas逐一读入日数据,逐一对每个股票进行月度抽样,月度抽样后其实就是对日数据按照月份进行分组,取每组最后一行的收盘价即为月数据收盘价,取每组第一行开盘价即为月数据开盘价,取该组最高价字段的最大值即为月数据最高价,取该组最低价字段的最小值即为月数据最低价。
daily_path = r'E:/daily/'
month_path = r'E:/month/'
file_list = os.listdir(daily_path)
for file_one in file_list:
ticker = file_one.split('.')[0]
print(ticker)
file_path = daily_path + file_one
df = pd.read_csv(file_path,encoding='utf-8')
df = df.loc[df['openPrice']>0].copy()
df['o_date'] = pd.to_datetime(df['tradeDate'])
df['d_close'] = df['closePrice']*df['accumAdjFactor']
df['d_open'] = df['openPrice']*df['accumAdjFactor']
df['d_high'] = df['highestPrice']*df['accumAdjFactor']
df['d_low'] = df['lowestPrice']*df['accumAdjFactor']
month_group = df.resample('M',on='o_date')
month_df = month_group.last()
month_df['endDate'] = month_df.index.get_level_values('o_date')
month_df['open'] = month_group.first()['d_open']
month_df['low'] = month_group.min()['d_low']
month_df['high'] = month_group.max()['d_high']
month_df.rename(columns={'endDate':'date','d_close':'close'},inplace=True)
month_df = month_df.loc[:,['date','close','open','high','low']].copy()
month_df.to_csv(month_path + ticker + '.csv',encoding='utf-8')
pass执行完后,得到月度级别数据
3 从股票基本信息中提起股票代码和股票简称键值对
这一步主要是为了好识别,毕竟股票代码都是数字没有股票简称直接。
file_path = r'E:/stock_list.csv'
df = pd.read_csv(file_path,encoding='utf-8')
df = df.loc[df['listStatusCD']=='L'].copy()
ticker_list = df['secID'].values.tolist()
name_list = df['secShortName'].values.tolist()
ticker_name_json = {}
for i,item in enumerate(ticker_list):
ticker00 = item.split('.')[0]
name = name_list[i]
ticker_name_json[ticker00] = name
with open(r'E:/ticker_name.json','w',encoding='utf-8') as fw:
json.dump(ticker_name_json,fw)4 开始计算当前价格与历史最高价的纵向距离和横向距离
逐一对每个股票的月数据进行计算,然后将结果存储到一个excel文件中
with open(r'E:/ticker_name.json','r',encoding='utf-8') as fr:
ticker_name_map = json.load(fr)
pre_dir = r'E:/month/'
file_list = os.listdir(pre_dir)
results_list = []
for file_item in file_list:
ticker = file_item.split('.')[0]
if ticker_name_map.get(ticker) is None:
continue
print(ticker)
name = ticker_name_map[ticker]
df = pd.read_csv(pre_dir + file_item,encoding='utf-8')
df = df.loc[:,['date','close','open','high','low']].copy()
df.reset_index(inplace=True)
df['i_row'] = range(len(df))
month_number = len(df)
start_month = df.iloc[0]['date']
end_month = df.iloc[-1]['date']
current_price = df.iloc[-1]['close']
max_price = df['high'].max()
df00 = df.loc[df['high']==max_price].copy()
max_date = df00.iloc[-1]['date']
zhe_number = math.log(max_price/current_price,2)
zhe_number = round(zhe_number,4)
baifenbi_number = round(current_price/max_price,4)*100
max_row = df00.iloc[-1]['i_row']
results_list.append({
'ticker':ticker,
'name':name,
'month_number':month_number,
'start_month':start_month,
'end_month':end_month,
'max_price':max_price,
'max_month':max_date,
'current_price':current_price,
'zhe_number':zhe_number,
'baifenbi_number':baifenbi_number,
'dur_month_number':month_number-max_row
})
pass
df_result = pd.DataFrame(results_list)
df_result.to_excel(r'E:/zhe_r.xlsx',engine='openpyxl',encoding='utf-8')
pass得到的结果就可以根据自己的需要筛选,本文这里做了一个粗浅的筛选,将ST股票剔除,取纵向距离上对折次数大于等于2次的股票列表
df = pd.read_excel(r'E:/zhe_r.xlsx',engine='openpyxl',converters={'ticker':str})
df = df.loc[(df['name'].str.contains('ST')==False) & (df['zhe_number']>=2)].copy()
df.to_excel(r'E:/zhe_r00.xlsx',engine='openpyxl')这个结果就是前文展示的结果。
本文只是做了粗浅的筛选,如果要更进一步缩小范围,可以在现有基础上再精进,后续得闲再往下继续。










![JavaCV实现byte[]转RTMP流](https://img-blog.csdnimg.cn/65180d3ea55d4ce199393ec80a644024.png)