程序背景
我们在日常办公中经常会遇到去csv或者excel文件中去剪切自己需要的列,然后重新粘贴在新的文件中,但是这样的工作方式非常的耗时,且效率低下,那么是否有一种方法,只要我提供表头就可以快速将我需要的表头生成一个新的文件呢,这样就可以批量处理了
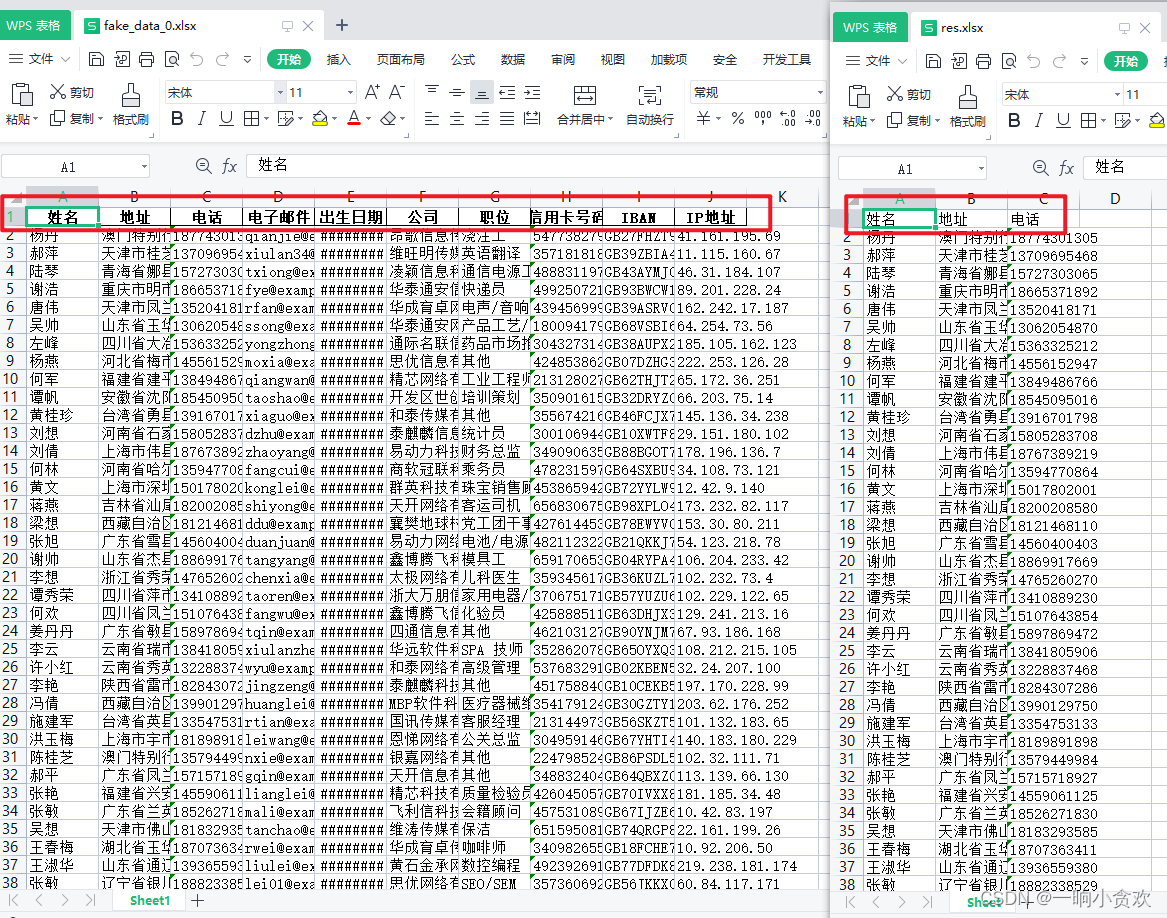
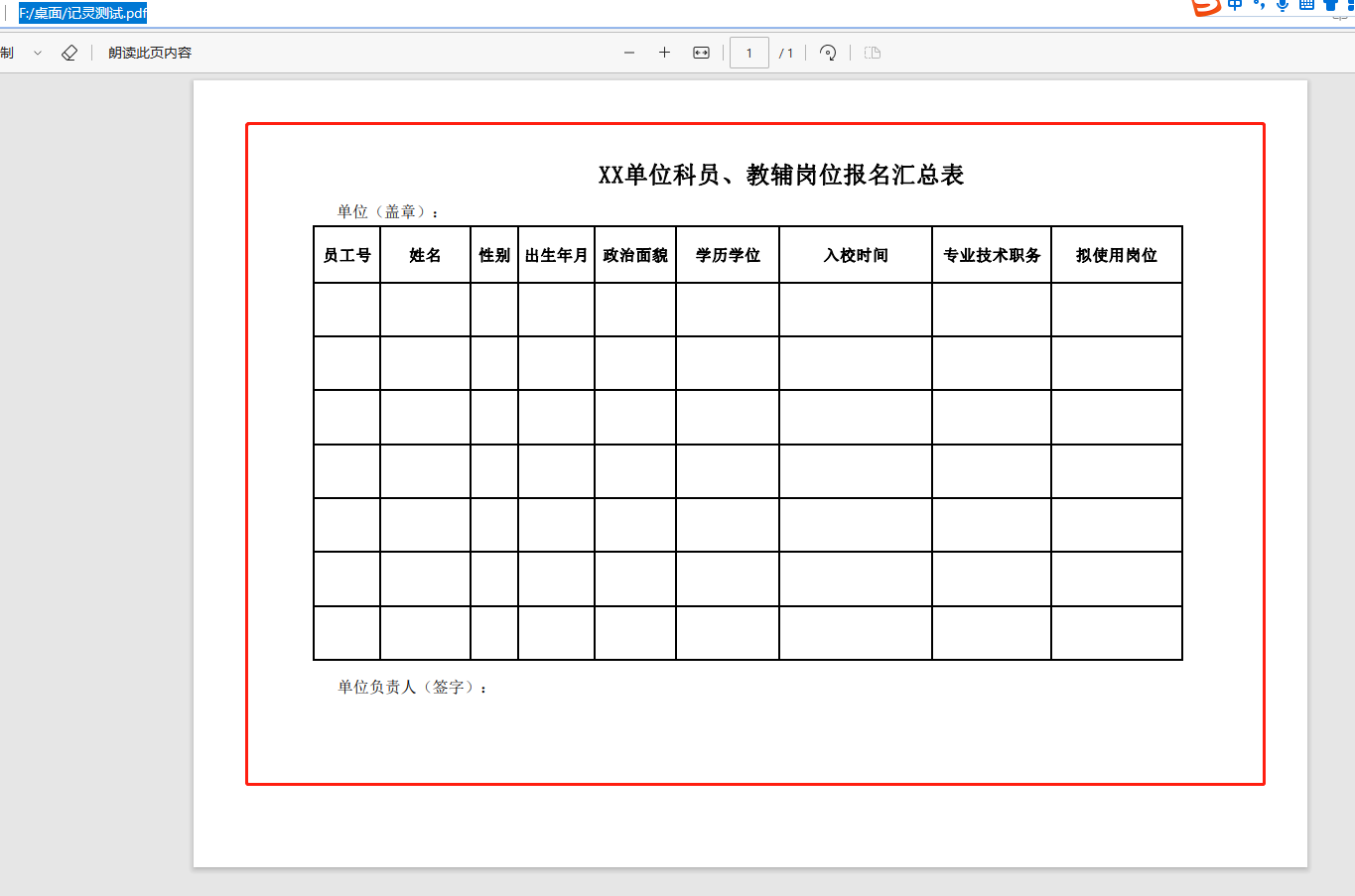
需求如图:
左边的原文件的表头太多,我只想要右边的表头文件,如果复制粘贴确实可以做到,但是如果文件量非常庞大的话,这是非常耗时的!!
那么今天我们利用python来实现,批量读取!
第 1 种 读取 xlsx的Excel文件
| 库 | 安装 |
|---|---|
| pandas | pip install pandas |
| openpyxl | pip install openpyxl |
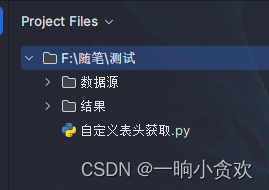
目录结构
文件夹—【数据源】:存放你的数据源(可多个
不限制数量)文件夹—【结果】:保存后的结果
代码1
注意1:head = [‘姓名’,‘地址’,‘电话’],这是你想获取的表头(
可乱序)
# -*- coding: utf-8 -*-
'''
@作者 :一晌小贪欢
'''
import os
import openpyxl
import pandas as pd
def read_excel():
# 表头
head = ['姓名','地址','电话']
for f in os.listdir("./数据源/"):
wb = openpyxl.Workbook()
ws = wb.active
ws.append(head)
row_1 = 0
indexs = []
reader = pd.read_excel("./数据源/"+os.listdir("./数据源/")[0],header=None)
for row in reader.values.tolist():
row_1 += 1
if row_1 == 1:
# print(row)
for h in head:
if h in row:
# print(h,row.index(h))
indexs.append(row.index(h))
continue
res_data = []
for i in range(len(head)):
res_data.append(row[indexs[i]])
ws.append(res_data)
print(res_data)
print(f"{f},已存储陈功!!")
wb.save("./结果/res.xlsx")
read_excel()
## 第 2 种 读取 csv文件(都是内置库)
代码2:
注意1:head = [‘姓名’,‘地址’,‘电话’],这是你想获取的表头(
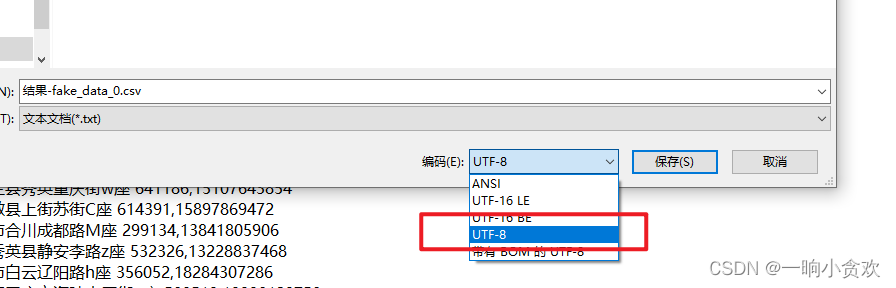
可乱序)注意2:注意数据源csv的编码方式,encoding=‘utf-8’,如果不是utf-8,可将csv文件用记事本打开,然后另存,另存的时候点击下面的编码——先择——UTF-8(如下图)
# -*- coding: utf-8 -*-
'''
@作者 :一晌小贪欢
'''
import csv
import os
def read_csv():
# 表头
head = ['姓名', '地址','电话']
for f in os.listdir("./数据源/"):
# 打开 CSV 文件
with open("./结果/" + '结果-' + f.split('.')[0] + '.csv', 'w', newline='', encoding='utf-8') as csv_w:
csv_w = csv.writer(csv_w)
csv_w.writerow(head)
with open("./数据源/" + f, newline='', encoding='utf-8') as csvfile:
# 读取 CSV 文件内容
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
# 遍历 CSV 文件中的每一行数据
row_1 = 0
indexs = []
for row in reader:
row_1 += 1
if row_1 == 1:
# print(row)
for h in head:
if h in row:
# print(h,row.index(h))
indexs.append(row.index(h))
continue
res_data = []
for i in range(len(head)):
res_data.append(row[indexs[i]])
csv_w.writerow(res_data)
print(f"{f},已存储陈功!!")
read_csv()
进阶版(csv版)(可筛选每一列的内容),这里我换了一个数据源
注意1:head = [‘承运商’, ‘店铺名称’,‘交易平台’,‘订单类型’,‘平台付款时间’],这里依旧便是表头
lie_list:这个列表中的小列表与表头相匹配,如我的小列表[‘SF’,‘shunfeng’],表示:head中【‘承运商’】我只要选取为:‘SF’,以及‘‘shunfeng’’的,然后以此类推
如下代码
if res_data[0] in lie_list[0] and
res_data[1] not in lie_list[1] and
res_data[2] in lie_list[2] and
res_data[3] in lie_list[3] and
res_data[4] not in lie_list[4]:上述代码只要你在lie_list中的小列表为空,你就在对应的索引下 加个not ,如上述代码中的第二条以及第五条,表示,我要选取【‘店铺名称’】中所有的数据 以及 选取【‘平台付款时间’】中所有的数据,依次类推
import csv
import os
def read_csv():
# 表头
head = ['承运商', '店铺名称','交易平台','订单类型','平台付款时间']
lie_list = [
['SF','shunfeng'], # 第一个表头的内容
[],# 第2个表头的内容
['JD'], # 第3个表头的内容
['销售出库'],
[],
]
for f in os.listdir("./数据源(CSV)/"):
# 打开 CSV 文件
with open("./结果/" + '结果-' + f.split('.')[0] + '.csv', 'w', newline='', encoding='utf-8') as csv_w:
csv_w = csv.writer(csv_w)
csv_w.writerow(head)
with open("./数据源(CSV)/" + f, newline='', encoding='utf-8') as csvfile:
# 读取 CSV 文件内容
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
# 遍历 CSV 文件中的每一行数据
row_1 = 0
indexs = []
for row in reader:
row_1 += 1
if row_1 == 1:
# print(row)
for h in head:
if h in row:
# print(h,row.index(h))
indexs.append(row.index(h))
continue
res_data = []
for i in range(len(head)):
res_data.append(row[indexs[i]])
# res_data = [row[indexs[0]], row[indexs[1]],row[indexs[2]]]
if res_data[0] in lie_list[0] and \
res_data[1] not in lie_list[1] and \
res_data[2] in lie_list[2] and \
res_data[3] in lie_list[3] and \
res_data[4] not in lie_list[4]:
# print(res_data)
# print(list(enumerate(row)))
csv_w.writerow(res_data)
print(f"{f},已存储陈功!!")
read_csv()









![JavaCV实现byte[]转RTMP流](https://img-blog.csdnimg.cn/65180d3ea55d4ce199393ec80a644024.png)