1. 函数功能
创建数据透视表,返回一个EXCEL形式的数据透视表。
2. 函数语法
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
3. 函数参数
| 参数 | 含义 |
|---|---|
| values | 可选参数,进行聚合运算的列或者列组成的列表,相当于EXCEL中放在【值】中的字段 |
| index | 放在数据透视表【行】上的列 |
| columns | 放在数据透视表【列】上的列 |
| aggfunc | 聚合函数,默认:mean |
| fill_value | 替换数据透视表中缺失值的值,默认无 |
| margins | 布尔值,是否显示行列总计,默认False(不显示) |
| dropna | 布尔值,不包含所有值均为空值的列 |
| margins_name | 字符串,默认All,总计的名称 |
| observed | 只针对Categoricals |
| sort | 布尔值,是否对结果排序,默认为True:排序 |
3.1 单行单列单个值做透视表
df = pd.read_csv('C:\\Users\\changyanhua\\Desktop\\cust1.csv',encoding='gbk')
print(df)
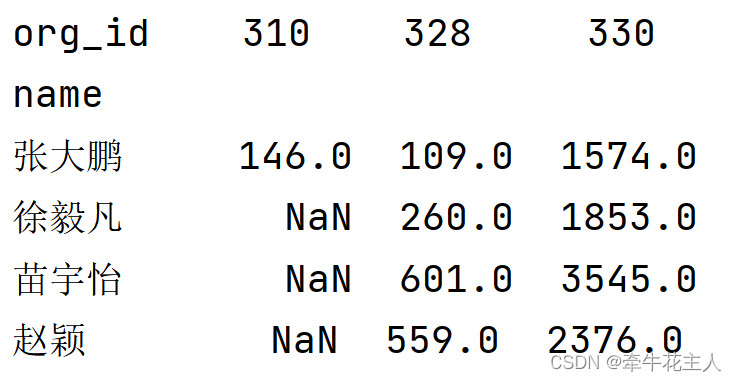
ts1 = df.pivot_table(values='payable', index='name',
columns='org_id', aggfunc=sum)
print(ts1)
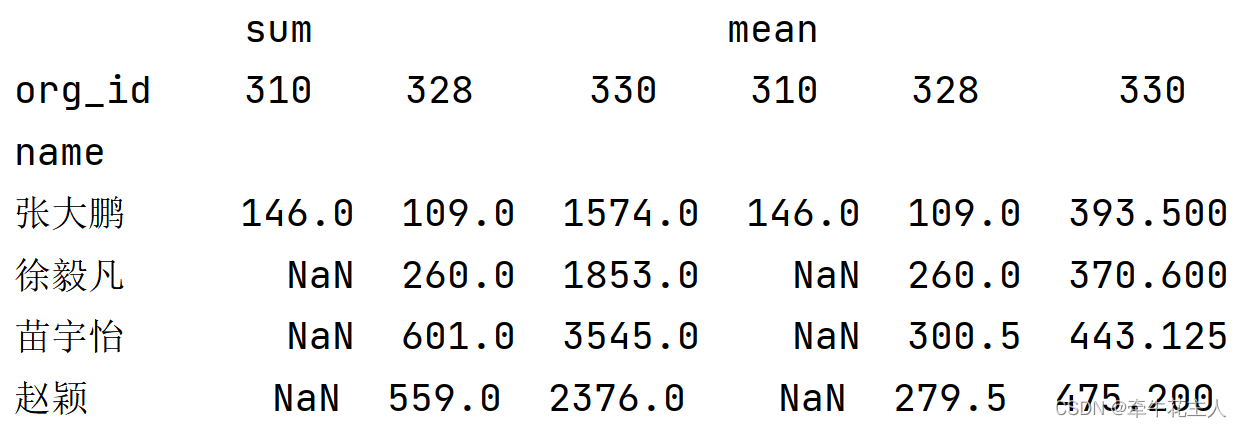
3.2 单行单列单个值同时进行两种及以上计算
运用函数时,python里面有的函数,可以直接使用函数名,若numpy中存在也可以加np,如:sum,但是python中没有的需要加上np.,比如mean。
ts1 = df.pivot_table(values='payable', index='name',
columns='org_id', aggfunc=[sum,np.mean])
print(ts1)
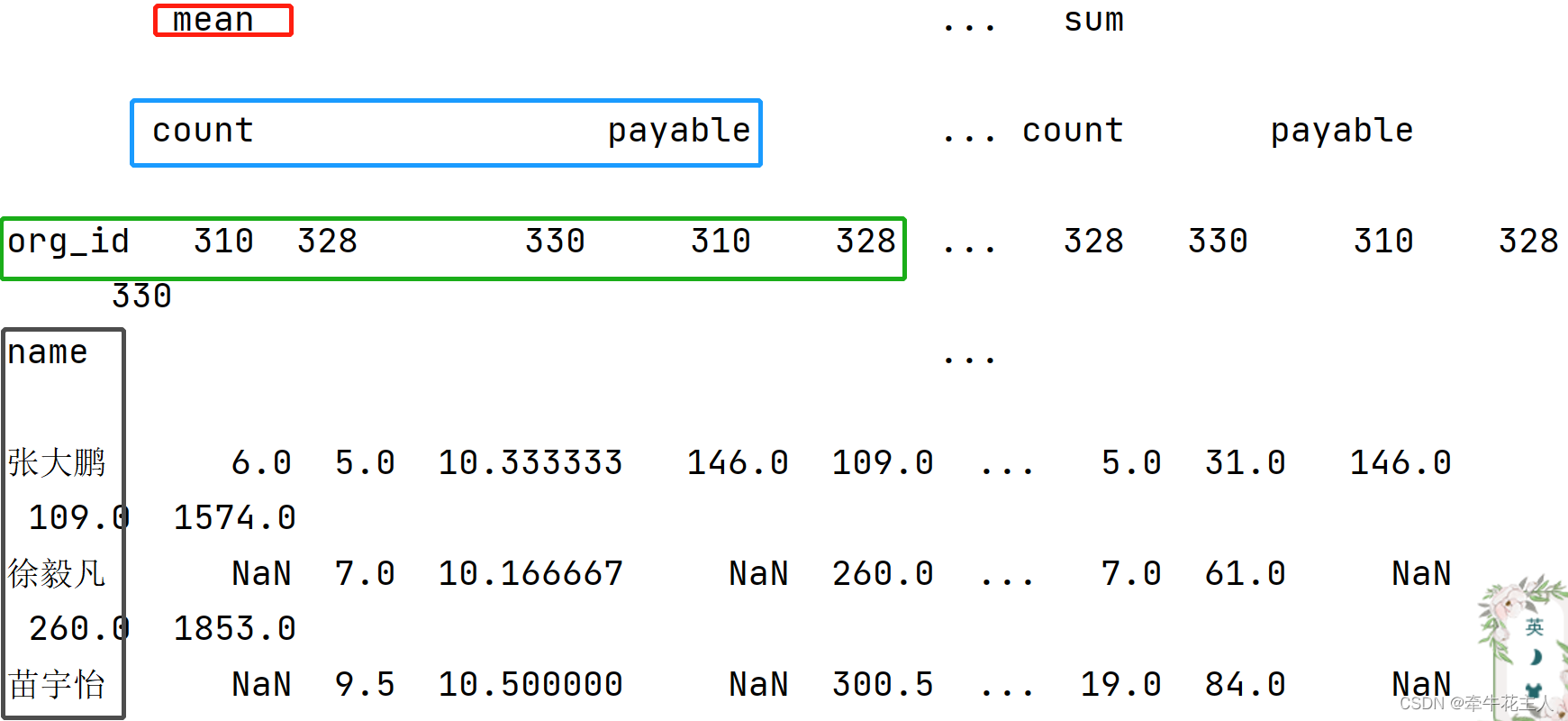
3.3 单行多列多个值进行聚合
此时会产生多层级索引,函数索引在第一层级,列为第二层级
ts1 = df.pivot_table(values=['payable','count'], index='name',
columns='org_id', aggfunc=[np.mean,sum])
print(ts1)
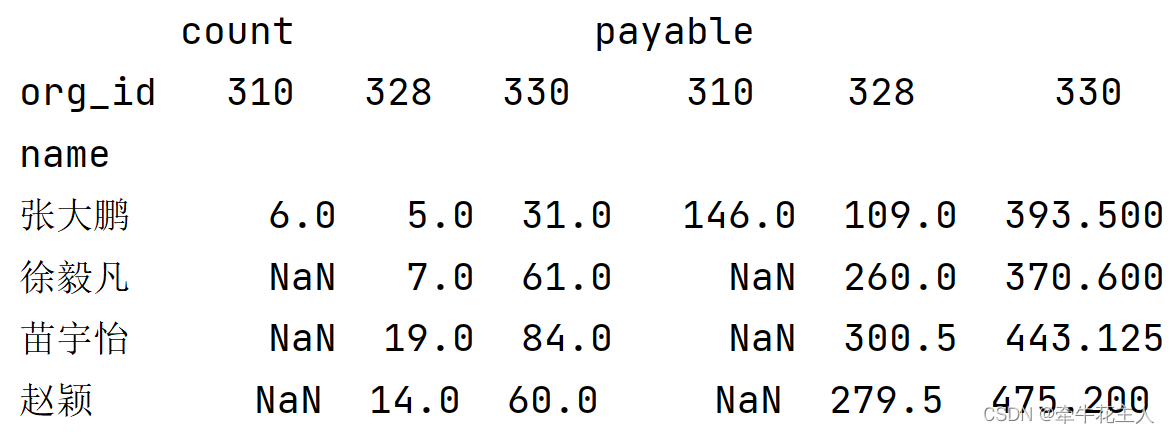
3.4 对不同的列进行不同的聚合计算
传入字典,指定不同列的不同聚合方式
ts1 = df.pivot_table(values=['payable','count'], index='name',
columns='org_id',
aggfunc={'payable':np.mean,'count':sum})
print(ts1)
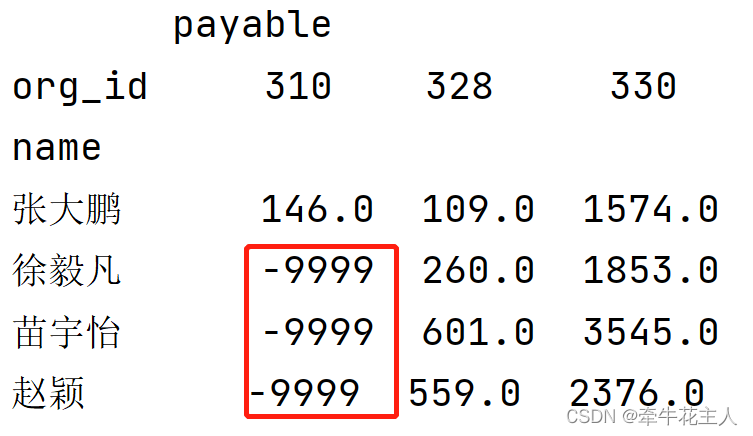
3.5 填充数据透视表中的缺失值
ts1 = df.pivot_table(values=['payable'], index='name',
columns='org_id',
aggfunc=sum,
fill_value='-9999')
print(ts1)
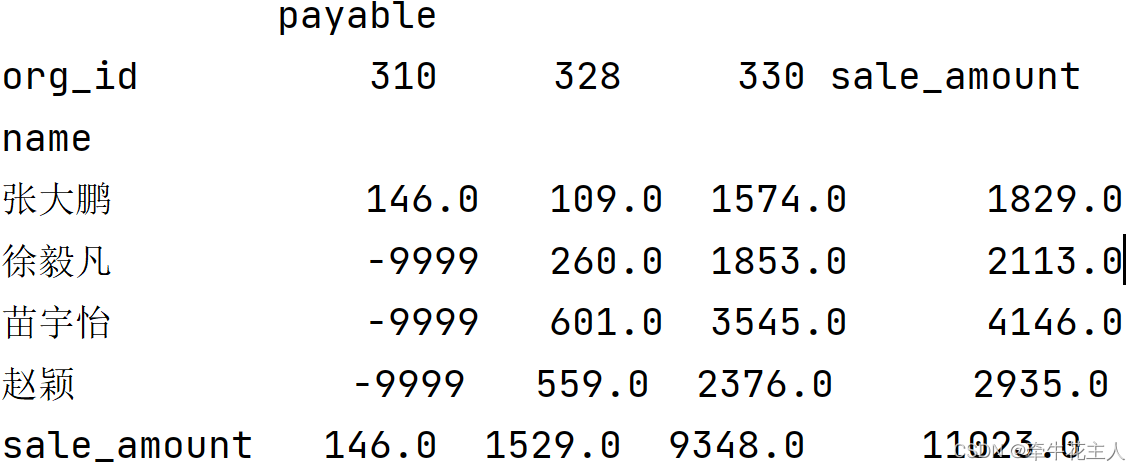
3.6 显示行列总计
ts1 = df.pivot_table(values=['payable'], index='name',
columns='org_id',
aggfunc=sum,
fill_value='-9999',margins=True)
print(ts1)
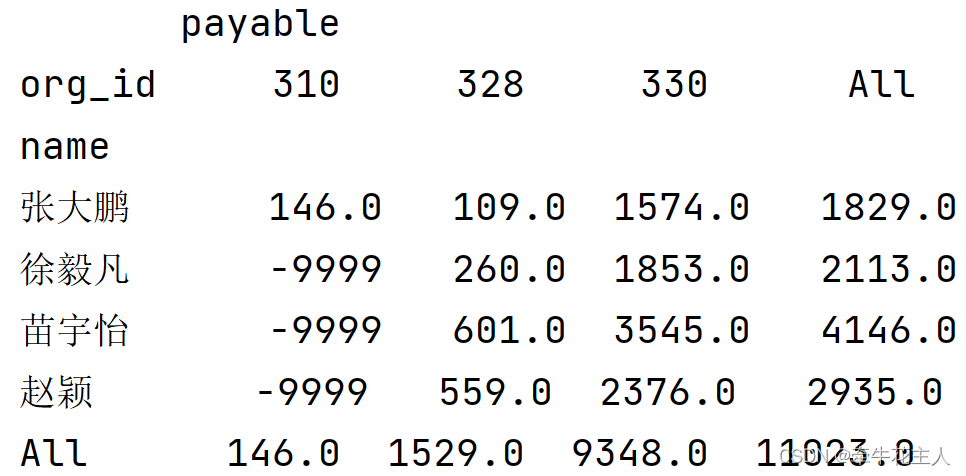
3.7 指定总计的行列名,默认为All
ts1 = df.pivot_table(values=['payable'], index='name',
columns='org_id',
aggfunc=sum, fill_value='-9999',
margins=True,margins_name='sale_amount')
print(ts1)
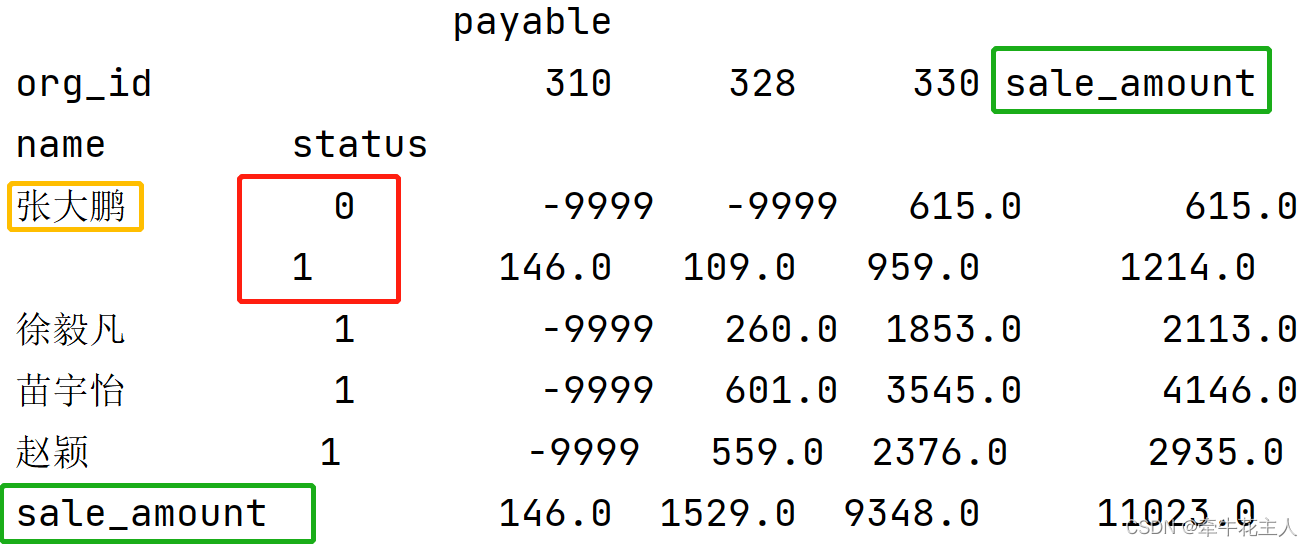
ts1 = df.pivot_table(values=['payable'], index=['name','status'],
columns='org_id',
aggfunc=sum, fill_value='-9999',
margins=True,margins_name='sale_amount')
print(ts1)












![LeetCode[11]盛水最多的容器](https://img-blog.csdnimg.cn/3f59d2051c474af787977fa034677259.png)