专栏导读
🔥🔥本文已收录于专栏:《风格迁移之从入门到成功魔改》,欢迎免费订阅
此专栏用于带你从零基础学会什么是风格迁移,风格迁移有什么作用,传统做法和Cyclegan的原理,及其优缺点,以及最重要的CycleGAN的成功魔改(附代码)。1)环境部署搭建,资源配置
2)风格迁移传统做法,GAN,CycleGAN的原理及其优缺点。
3)代码详细解析
4)根据缺点进行全方面成功魔改的原理。
本文导读
🔥🔥本文的创新点部分,我将把我的整个项目过程所使用到的绝大多数trick以及创新部分进行开源。只有淋过雨的孩子才会懂得给别人打伞,所以我开源的目的很简单,希望可以帮助到有缘相遇的初学者快速了解并掌握该方向内容。有能力的同学可以进行二次改进创新。我的最终模型在定性和定量的评估中效果均有提升。后续代码将更新到GitHub上,如果对大家有帮助,希望可以得到您的免费star✨。本人万分感谢!!!
本文的结构图均为本人绘制,如有需可以评论区留言❤
五万字的文章创作不易,如有帮助劳烦免费点赞收藏一波,谢谢!
目录
一、生成对抗网路概述
二、CycleGAN模型
CycleGAN原理
CycleGAN的不足
三、CycleGAN源码解读
🔥🔥四、提出的全新模型SWLAGAN结构(创新点部分)
🔥生成器网络
自注意力机制
🔥可全局连接的残差网路(SA_Blocks)
🔥🔥生成器网络结构
🔥🔥判别器网络
🔥🔥损失函数部分
🔥🔥循环一致性损失LPIPS
🔥🔥对抗损失WGAN-GP
🔥🔥🔥SWLAGAN模型训练结构图
🔥🔥五、训练模型的Trick
🔥🔥🔥🔥六、成果展示
一、生成对抗网路概述
生成模型
生成模型在深度学习领域具有很强的可研究性,它的生成特性使它可以在很多领域得到应用,比如图像领域,语音处理领域,文字领域等。伴随着计算机硬件的不断地发展,计算机算力得到了质的提升,使生成模型从原来的不可能转为了现在的研究热点。生成模型在深度学习中可以用来对数据进行建模,其本质是为了能够学习数据的分布特征,使得生成的数据分布特征可以不断地靠近真实的数据分布特征。深度学习中包括监督学习、非监督学习和半监督学习。在高效率发展的大环境背景下,无监督学习的便利性使得它的地位直线上升。标记数据一直都是令研究学者头疼且费时费钱的事情,有的标签甚至都无法很好的获取。并且如果使用通过高级特征学习的模型来处理大多数的任务,可以防止过拟合的同时提高模型的能力,甚至对模型的泛化能力也有所增强;虽然有的任务是没有最终的具体形式,但其也可以在数据分布中找到千丝万缕的联系。比如在强化学习中采用无监督学习,不光可以提升模型对数据环境的预测能力,而且有些任务的结果还可以是多元化的,如果运用监督学习,输出的结果只能是单元性的,将会不符合要求。因此生成模型在无监督学习中担任了重要的角色。
GAN模型
GAN作为对抗生成网络的开拓者,其原理具有很强的代表性。GAN模型中有两个重要的网络结构分别为生成器网络和判别器网络,模型的训练过程是通过生成器和判别器的动态博弈实现的,在不断的对抗博弈后两个网络结构优化了自身的参数,最终求出数据分布散度的最大似然估计。生成器网络的作用是通过学习真实数据的分布,使生成的数据分布更趋近于真实数据分布,让判别器难以分辨数据分布的真假性。判别器网络的作用是判断输入的数据分布是生成器网络生成的数据分布还是真实数据分布进而打分。如果判断是真实数据分布则判别器输出为1,否则输出为0。判别器网络在训练的时候想尽办法将生成器网络生成的假数据分布低分,给真实数据分布高分,而生成器网络在训练的时候尽可能让自己生成的假数据分布在判别器网络那里可以得到高分。因此GAN模型在训练时生成器网络和判别器网络是交叉训练的,通过不断地对抗训练让生成器和判别器最终达到纳什平衡。此时的判别器网络将分不清生成器网络生成的数据分布是真实的还是假的。
此公式为GAN的目标函数,D表示判别器网络,G表示生成器网络,z表示输入给G的随机噪声,x表示真实数据,,
都表示为一个分布。D(x)表示真实数据在判别器中的分数,G(z)表示随机噪点通过生成器生成的图像。
表示
在x来自
分布时的期望。
表示
在x来自
分布时的期望。由目标函数可知GANa网络是分两步进行优化:
第一步是判别器(D)网络优化,D的目的是判别输入图像是真实的还是生成器生成的,当D训练的很好的时候:D(x)=1,D(G(z))=0,因此V(D,G)=0。但D不会立刻训练到最好,函数中又有log,因此V(D,G)<0。所以在训练D时,V(D,G)值越大代表D训练的越好。因此第一步的目标函数可以被定义为:
第二部是生成器(G)网络优化,G的目的是生成让判别器无法判别真假的图片,G的训练只与公式有关,当G生成让D无法判断真假的图片时,D(G(z))将趋向于1,1-D(G(z))将趋向于0,因此
趋向于无穷小。所以在训练G时,V(D,G)值越小代表G训练的越好。因此第二步的目标函数可以被定义为:
GAN的目标函数的最优解为,即D(x)= 1/2时。可通过反证法证明D的最优解公式,首先让G的参数不更新,D的最优解公式假设是
把该公式带入目标函数中得:
设D(x)为自变量y,使V(G,D)对y求导,找最大值。此时得到再把D(x)带入目标函数中得:
又通过KL散度公式推导,得到新的C(G)。
(KL散度公式:,其意义是指在已知p的情况下,需要多少个比特能把q表达出来。且KL散度一定是大于等于0,当等于0时,p==q)因此当
时,C(G)取得全局最小值。
GAN的训练过程,可见GAN伪代码图。

二、CycleGAN模型
CycleGAN原理
单一的GAN模型是无法实现风格迁移任务的,因为GAN是通过生成器和判别器不断动态对抗优化,使生成器学习到真实数据的特征分布。但其中存在一个致命问题,风格迁移的目的是想源域和目标域之间产生映射关系,即生成的图片在内容上与内容数据集的结构相似度高,风格上与风格数据集的结构相似度高。单一的GAN模型会出现映射组合的不确定性,导致只有目标域中的一张图片与源域产生了联系,即生成的图片永远都是同一张风格数据集中的某一张图片。因此CycleGAN模型继承了GAN的对抗训练的思想,以对偶的训练学习方式,实现了源域到目标域之间无需具有成对关系也能产生映射。使得CycleGAN具有不需要成对的数据集便可实现迁移功能的特性。由GAN模型的对抗训练转为循环对抗模式,模型由原来的一个G和一个D,转变为现在的两个生成器网络G和F,两个判别器网络和
,又增加了循环一致性的损失函数来约束生成的图片和真实图片的结构相似度。其对称式环状结构使其可以看作为双生成对抗网络,下图是CycleGAN的训练结构图:
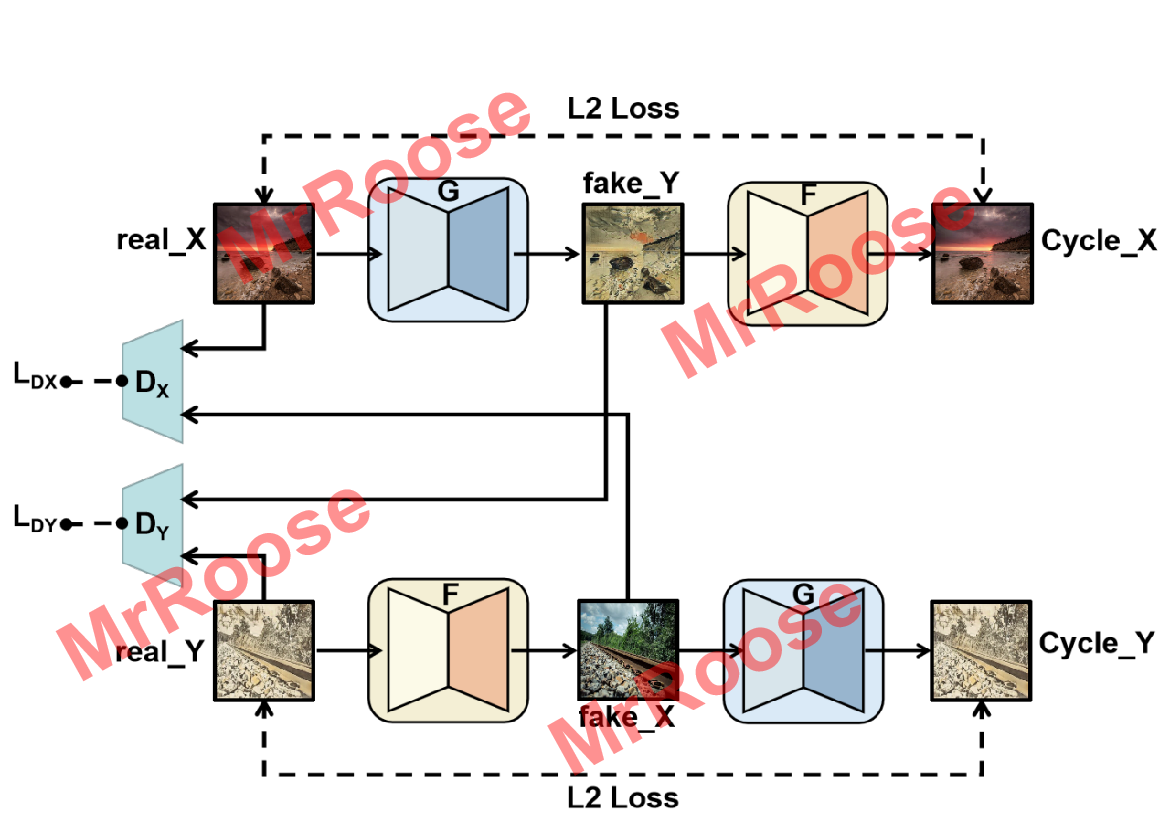
由于CycleGAN是对称结构。上部分结构,将X源域中的图片x通过G映射生成Y源域的图片,
将判别G(x)是真实数据分布还是生成数据分布。但以上只是GAN的结构。如果只运行GAN结构会导致生成的Y源域照片
因为有
的存在,使得G(x)完全和Y源域中的照片y一摸一样,从而失去了X源域中图片x的内容结构,导致迁移结果无效。因此使用到了循环一致性的思想,通过将生成的图片
经过F重新映射生成X源域中的图片
。为了防止出现生成图片
失去X源域图片的内容情况,通过将生成图片
与X源域图片x进行L2范数损失函数的计算,尽可能的让这两张图片相似,即
。下部分结构则是先将Y源域通过F映射生成X源域图片
,再经过G映射生成
,最终实现
。此时的映射关系G和F便可以实现风格迁移。
其中映射关系G的目标函数定义如下:
同理映射关系F的目标函数定义如下:
循环一致性损失函数是L2范数损失函数,也被称为最小平方误差。其损失函数定义为:
则CycleGAN的总损失函数为:
CycleGAN模型具有良好的通用性及创新性,作为风格迁移的无监督学习的开拓者,受到了很多研究者的关注,其优良的性能和扩展性成就了它是目前最具有研究价值的模型之一。
CycleGAN的不足
虽然CycleGAN不需要成对的数据集即不需要成对的目标风格源图像和源图像。但其也有着许多方面的不足可以改进。
首先对于生成器网络部分,虽然CycleGAN使用auto-encoder框架,进行下采样和上采样,在中间也使用了残差网络,想要更深层提取特征的同时防止网络退化。但其只能在局部进行单尺度提取特征,这限制了整体网络的学习能力。且上采样单纯使用反卷积,图片生成质量将会受到影响。
对于判别器部分,CycleGAN采用的是马尔科夫链PatchGAN的判别器结构。由于是基于卷积快结构,对于高频的模拟只能视野局限在局部窗口中。因此会大大降低学习效率。
对于目标函数部分,原始GAN的交叉熵损失函数中使用到的JS散度很难拉近生成数据的分布和真实数据的分布,LSGAN的最小二乘法通过将图片的分布尽可能拉到接近决策边界来缓解GAN训练模型的不稳定性和生成质量多样性不足的问题,但实际上问题依旧存在。
对于循环一致性损失部分,CycleGAN使用的是L2范数损失函数,其目的是想让生成图片与真实图片的结构相似度更高。而L2范数损失是逐像素比较相似度的,忽略了图像本身的结构。因此简单的L2范数损失函数很难完成所有的风格迁移工作。且有时候L2范数的结果会与人的感知审美出现违背情况。
三、CycleGAN源码解读
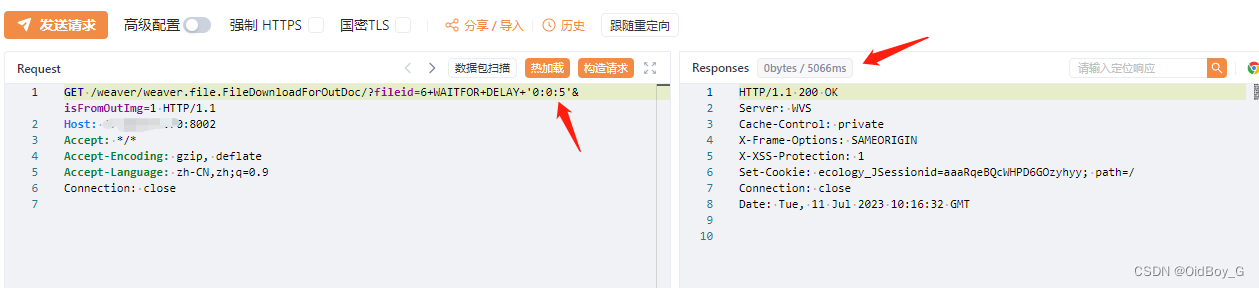
当我们阅读别人的源码的时候,需要使用debug,可以参考:Pycharm调试篇(详细)_MrRoose1的博客-CSDN博客
我们来看看这个代码构成
- opt = TrainOptions().parse() 继承baseoption并执行parse()方法
- BaseOptions的init()
- BaseOptions的parse()
- 在parse()里执行BaseOptions()的gather_options()方法, 这玩意大概意思是把base,train,model,data的参数(add_argument)都整合到一块
- TrainOption的initialize()方法
- BaseOption的initialize()方法,添加base的parser.add_argument
- 添加train的parser.add_argument
- models.get_option_setter() 用来追加和model有关的parser.add_argument
- find_model_using_name() 寻找这个模型有没有定义
- 本来这个函数也挺正常的,但是调试的时候importlib.import_module(model_filename),心里直接羊驼飞过!
- find_model_using_name() 寻找这个模型有没有定义
- TrainOption的initialize()方法
- 在parse()里执行BaseOptions()的gather_options()方法, 这玩意大概意思是把base,train,model,data的参数(add_argument)都整合到一块
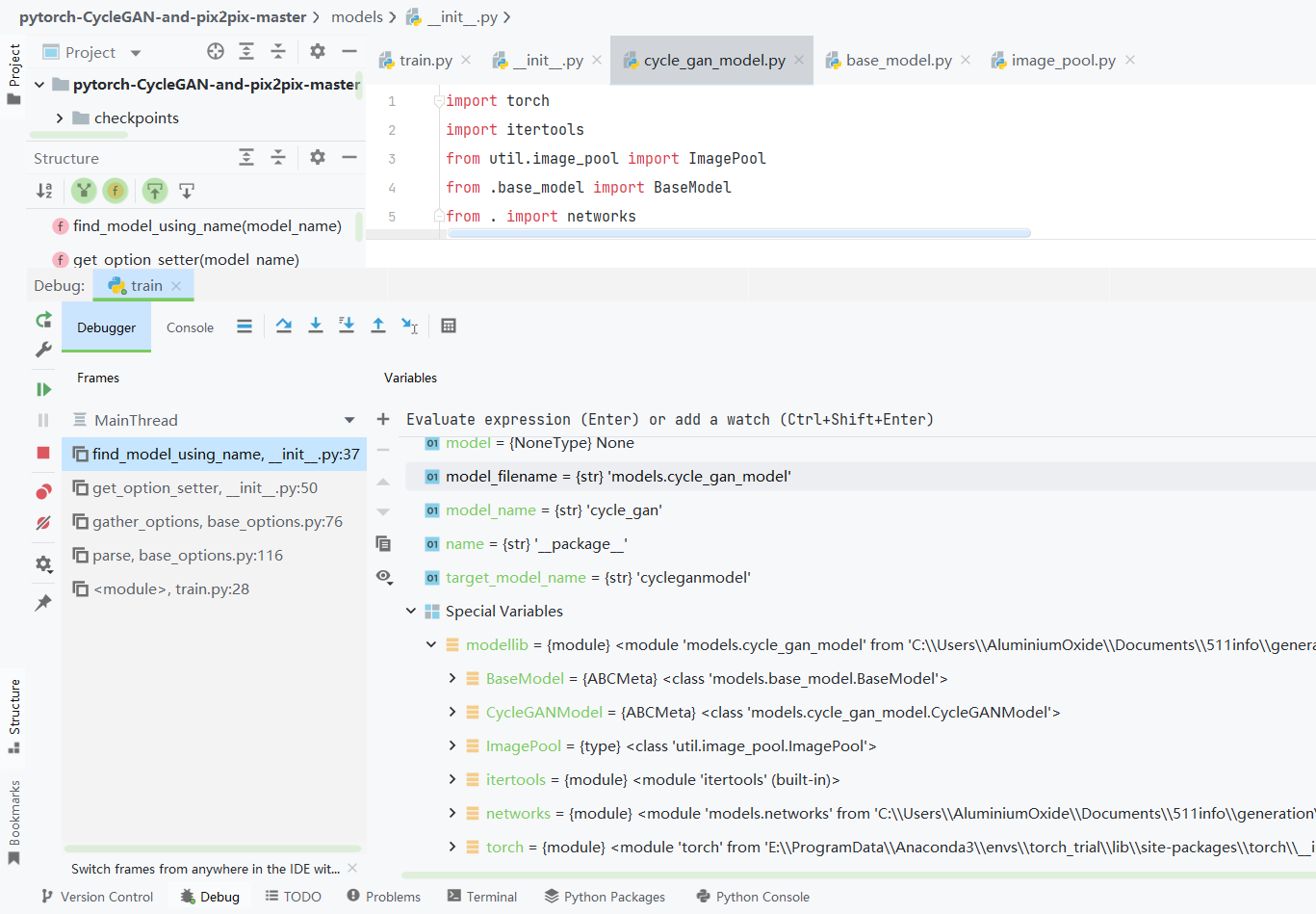
说下modellib = importlib.import_module(model_filename)
这个憨憨直接遍历model_filename模型文件里面所有用到的类!!!
然后把所有遍历到的模型名称输出到一个特殊变量 modellib 里
这也导致这个憨憨在使用的时候函数堆栈指针对塞进去一坨奇怪的东西,而且这玩意是在遍历项目的目录,导致step into my code在疯狂的跳新宝岛!!!
- opt = TrainOptions().parse()
- BaseOptions.parse()
- BaseOptions.gather_options()
- get_option_setter()
- find_model_using_name()
- 说完modellib = importlib.import_module(model_filename)咱们继续
- 寻找modellib里的模型名和target_model_name相等,并且是BaseModel子类的模型
- 把这个模型给个叫model的变量并返回
- 返回刚才找到模型的.modify_commandline_options方法 命名为 model_option_setter
- find_model_using_name()
- 执行刚才好不容易返回的model_option_setter ,添加model的parser.add_argument
- get_option_setter() 和模型的套路基本一致,只不过这次实在数据集的类里找
- find_dataset_using_name()
- 找到数据集的类
- find_dataset_using_name()
- dataset_option_setter,添加dataset的parser.add_argument
- get_option_setter()
- 返回一块包含所有参数的命名空间给opt
- BaseOptions.gather_options()
- 打印并再设置一些GPU的参数返回
- BaseOptions.parse()
- dataset = create_dataset(opt) 创建数据集
- CustomDatasetDataLoader() 喜闻乐见的dataloader
- find_dataset_using_name() ?!老兄你不对劲啊!!!
- 返回 dataset_class 并实例化这个类 # 好的,dataset已经成为你的对象了,现在你可以对她……
- make_dataset() 这玩意返回对应目录下所有图片的路径,并组成一个list
- get_transform() 关于图像的预处理,只不过这里封到函数里了
- 除了__init__(),下面的__getitem__()也建议看看,那里说的是后面取图象是怎么取的
- 并设置dataloader
- 用load_data()方法,把CustomDatasetDataLoader()传出去
- CustomDatasetDataLoader() 喜闻乐见的dataloader
- model = create_model(opt) 创建模型 类似数据集
- find_model_using_name() 我就喜欢你这种让我跳过的
- 实例化这个类 # 好的instance也变成对象了,现在…….
- 先BaseModel.init()
- 设置8个 loss_names
- 设置8个 visual_names
- 设置4个 model_names
- self.netG_A = networks.define_G() 定义netG 的模型
- get_norm_layer() 设置norm_layer
- 根据设置,选择 ResnetGenerator()
- 网络定义和forward基本都在这,对于现在只有一个res的样子
- 然后执行init_net()
- 设置GPU并使用init_weights()初始化参数
- self.netG_B = networks.define_G() 同上
- self.netD_A = networks.define_D() 定义netD 的模型
- get_norm_layer() 设置norm_layer
- 根据设置,选择 NLayerDiscriminator()
- 网络定义和forward基本都在这,对于现在只有一个res的样子
- init_net()同上
- self.netD_B = networks.define_D() 同上
- ImagePool() 很奇怪的东西 创建图像缓冲区以存储先前生成的图像
- 这个缓冲区储存由netG生成的图像 并可以用历史来更新鉴别器netD, 而不是由生成器netG直接生成
- 注意里面还有个query()方法
- # 3个损失函数
- criterionGAN = GANLoss() 根据设置选择的,并带一个判断是真值real还是生成值fake,分别计算
- criterionCycle = L1Loss()
- criterionIdt = L1Loss()
- # 2个优化器
- optimizer_G Adam() 使用chain把 netG_A 和 netG_B 的参数 混在一起
- optimizer_D Adam() 同上, 不过是netD_A 和 netD_B
- 然后分别把这俩优化器都放到optimizer里
- 打印相关信息直接返回
- model.setup(opt) 加载和打印网络,并设置学习率衰减策略schedule
- networks.get_scheduler(optimizer,opt)
- print_networks() 字面意思
- visualizer = Visualizer(opt) 调用visdom和创建页面数据,之前没开server的这里就该出问题了
- 里面在创建文件夹和log文件
- visualizer.reset() 字面意思 让self.saved = False 下次能更新
- for i, data in enumerate(dataset) 会执行dataset的__iter__()
- 这个data给出4*batchsize的数组
- A A图数组
- B B图数组
- A_path A图对应路径
- B_path B图对应路径
- 这个data给出4*batchsize的数组
- model.set_input(data) 设置哪面往哪面走
- real_A
- real_B
- image_paths 对应网络输入图片的路径
- model.optimize_parameters() 计算损失函数,获取梯度,更新网络权重
- # 首先是生成器的
- self.forward() 没啥好说的
- self.fake_B = self.netG_A(self.real_A) # G_A(A) → B
- self.rec_A = self.netG_B(self.fake_B) # G_B(G_A(A)) → A
- self.fake_A = self.netG_B(self.real_B) # G_B(B) → A
- self.rec_B = self.netG_A(self.fake_A) # G_A(G_B(B)) → B
- self.set_requires_grad([self.netD_A, self.netD_B], False) 冻结两个netD的梯度
- self.optimizer_G.zero_grad() netG的梯度清零
- self.backward_G() 反传计算loss
- 这里先计算了一下
self.idt_A = self.netG_A(self.real_B) # G_A(B) → B
self.idt_A = self.netG_A(self.real_B) # G_B(A) → A - loss_idt_A 是鉴别器A的测试损失 ||G_A(B) – B||
- loss_idt_B 是鉴别器B的测试损失 ||G_B(A) – A||
- loss_G_A 使用criterionGAN() 把 D_A(G_A(A)) 和opt扔进去, 生成的(1,1,30,30)和全1的(1,1,30,30)求MSEloss
- loss_G_B 使用criterionGAN() 把 D_B(G_B(B)) 和opt扔进去, 生成的(1,1,30,30)和全1的(1,1,30,30)求MSEloss
- loss_cycle_A 使用criterionCycle 说白了就是使用L1loss,即 || G_B(G_A(A)) – A||
- loss_cycle_B 使用criterionCycle 说白了就是使用L1loss,即 || G_A(G_B(B)) – B||
- loss_G = 上面六个loss求和,然后反向传播
- 这里先计算了一下
- self.optimizer_G.step() 更新两个G的权重
- # 然后是鉴别器的
- self.set_requires_grad([self.netD_A, self.netD_B], True) 解冻两个netD的梯度
- self.optimizer_D.zero_grad() netD的梯度清零
- self.backward_D_A()
- fake_B_pool.query(fake_B)取刚才G_A(B) → B的生成图像
- 设置 netD real fake 调用backward_D_basic(D_A, realB, fakeB)
- netD(real) 产生 (1,1,30,30)的输出
- loss_D_real 输出和(1,1,30,30)的全1求MSEloss
- netD(fake) 产生 (1,1,30,30)的输出
- loss_D_fake 输出和(1,1,30,30)的全0求MSEloss
- loss_D = (loss_D_real + loss_D_fake) * 0.5 然后反向传播
- self.backward_D_B()
- fake_A_pool.query(fake_A)取刚才G_B(A) → A的生成图像
- 设置 netD real fake 调用backward_D_basic(D_B, realA, fakeA)
- netD(real) 产生 (1,1,30,30)的输出
- loss_D_real 输出和(1,1,30,30)的全1求MSEloss
- netD(fake) 产生 (1,1,30,30)的输出
- loss_D_fake 输出和(1,1,30,30)的全0求MSEloss
- loss_D = (loss_D_real + loss_D_fake) * 0.5 然后反向传播
- self.optimizer_D.step() 更新两个D的权重,和G不同的一点是,DA和DB的loss大小是不一样的
# 后面这些,都是次要的
- # display images on visdom and save images to a HTML file
- visualizer.display_current_results()
- # print training losses and save logging information to the disk
- # cache our latest model every iterations
- # cache our model every epochs
- model.update_learning_rate() # 在每个epoch后根据学习率衰减策略更新学习率.
然后说一些前面可能描述不是特别详细的,PS:记住一点,D的目的是能区分出来这是生成的,G的目的是让生成的假图片和真的差不多,让D看不出来
| name | AB | discrimination |
| fake_B | → | G_A(A) => B |
| rec_A | → ← | G_B(G_A(A)) => A |
| fake_A | ← | G_B(B) => A |
| rec_B | ← → | G_A(G_B(B))=> B |
| idt_A | ↳ | G_A(B) => B |
| idt_B | ↲ | G_B(A) => A |
网络中生成图像的描述
| D | real | fake |
| D_B | real_A | fake_A |
| D_A | real_B | fake_B |
有关backward_D_basic的两次计算
其中real_A和real_B是数据集里作为输入的图像
| discrimination | ideal |
| D(real)=>(batchsize,1,30,30) | ones(batchsize,1,30,30) |
| D(fake)=>(batchsize,1,30,30) | zeros(batchsize,1,30,30) |
详细的解读一下各文件 :
1.train.py文件
21-25行不说了,都是导入一些基本的类。
第27行的意思是,如果这个脚本作为主脚本使用,那么就运行下方的东西。28行是先把TrainOption实例化成对象,然后用parse进行解析,这样形成一个结果,赋给opt,也就是说,opt解析出来的结果。29行是根据这个结果去创建数据集。30行获取数据集中样本的数量。31行不说了。
33行是创建模型。34行是根据opt创建合适的学习率调整策略、导入网络并打印。第35行是根据opt创建可视化实例。36行是训练迭代次数。
第38行是迭代过程的开始,opt.epoch_count是从哪个epoch开始,opt.n_epochs_decay是持续多少epoch。39-40行不说了,获取这个epoch开始的时间和本轮epoch导入数据的时间。41行是在本轮epoch当中的第几次迭代。42行是可视化机器的重置,保证在每个epoch里它至少有一次保存图片。43行是在每次epoch之前率先更新一下学习率。
第44行就是每个epoch内部的循环了,enumerate函数的作用是同时列出数据和下标,这个无需多说,注意这里的i是batch的编号,而data也不是一张图,而是一个batch的图。45行是本次iteration开始的时间。46-47行是说如果总迭代次数total_iters到了opt.print_freq的整倍数,就计算t_data,也就是本轮iteration开始的时刻到本轮epoch导入数据的时间已经过去了多久。49-50行指的是,一共多少个数据参与了训练以及本轮epoch里有多少数据参与了迭代。51行是把每一个数据解包,52行是参数优化,这些都是在model当中的basemodel.py当中定义的。
54-57行是数据可视化的部分,如果本轮epoch当中已经参与迭代的样本总数是opt.display_freq的整数倍,那么执行55-57行的操作。55行是返回一个叫save_result的布尔值,用于判定是否需要存出结果到html文件里。第56行是只有在着色任务中才有用,是展示图片的命令,其他的模型中compute_visuals函数只有一个命令,那就是pass。第57行则是存储到html文件里的命令,其中save_result就决定本行是否执行,可以参见util文件夹里的visualizer.py。
59-64行是打印的部分。如果本轮epoch当中已经参与迭代的样本总数是opt.print_freq的整数倍,那么执行60-64行的操作。第60行是获取当前的损失函数。第61行是计算每个图片所用的时间。第62行是输出当前的损失值,后面的参数含义大家可以点击util文件夹下的visuallizer.py去查看相应的函数。63-64行是损失值可视化的部分,如果window id of the web display这个值大于0,那么就利用plot_current_losses函数输出,参数的含义可以点击util文件夹下的visuallizer.py去查看相应的函数。
66-69行是保存权重文件的部分,如果本轮epoch当中已经参与迭代的样本总数是opt.save_latest_freq的整数倍,那么执行67-69行的操作。67行不说了,68行是设置保存后缀,69行是保存模型。
71行是重新获取时间。72-75行也是在保存模型,不过这次是在每个epoch结束的时候。
77行是输出,无需多言。
2. test.py文件
它将从’–checkpoints_dir’加载保存的模型,并将结果保存到’–results_dir’。它首先在给定opt选项的情况下创建模型和数据集。它将硬编码一些参数。然后,它对“–num_test”图像运行推断,并将结果保存到HTML文件中。
29-34行不用多说了,导入包。
36-39行是导入wandb包,可以帮我们记录超参数指标。
42-43行不说了,和上面的train.py有异曲同工之妙。45行,测试模式仅能使用单线程,至于哪一个线程,你可以去自己指定;46行,batch_size只能为1;47行是确定数据需不需要打乱;48行则是是否翻转;49行是放弃展示图片;50-52行不说了,上面的train.py里解释过是什么含义。
54-57行,没太看懂。不太熟悉wandb这个包的含义。
59-行,是在创建网站。60行是在确定地址。61-62行是要根据本轮迭代来确定网址的域名(整体)。63行不说了,就是打印一下结果。64行是确定网页的地址和标题(这块可能得在util文件夹里头找html.py)。68-69行是评估模式开启。
70-72行比较简单,不再重复。73-74行也比较容易理解,分别是解包数据、测试。75-78行可以参考注释,获取图像结果、获取图像路径,每隔5个图片打印一次。79行是保存图片到html中,参数的含义可以点击util文件夹下的visuallizer.py去查看相应的函数。最后80行,保存html。
3.根目录中的文件夹
之后,我们再来看看各个文件夹都是怎么回事。
3.1 docs文件夹
docs文件夹不多说了,里头是各种说明文档。
3.2 .git文件夹
.git文件夹也不多说了,这是用于分布式版本管理的工具,具体什么是git请自行百度。在我【教程搬运】的专栏下也有专门介绍git的博文。
3.3 data文件夹
data文件夹,里头是各种和数据加载、处理的模块。里头的__init__.py是一个接口文件,basedataset.py是一个基础文件(包含一些常见的转换功能,有点相当于公用的“基类”,不知道怎么描述了),template_dataset.py这是一个模板,相当于示例文件。其它的都是具体的数据集对应的文件了。
3.3.1 template_dataset.py
首先让我们聚焦一个模板文件,也就是template_dataset.py,在这里我们仅仅给出一些说明,读完之后觉得抽象也没关系,我们后面还有例子(3.3.2节之后),慢慢体会,慢慢读就可以了。
这个文件主要起到一个模板的作用,是一个参考,具体说明如下:
这个脚本可以被当做一个模板,被用于创建新的数据类型。如果说此时此刻的我们想建立一个新的数据类型dummy,就需要在这个根目录底下创建一个名叫dummy_dataset.py的文件,里面需要定义一个类,名叫DummyDataset,而这个类需要继承父类BaseDataset(当然这个类就在data文件夹中的base_dataset.py之中),在类DummyDataset这里面需要实现四个重要的功能,我们将在后面仔细分析。
创建完之后如何使用呢?可以通过–dataset_mode template来指定,但需要注意,你所创建的类名class TemplateDataset、在–data_mode后面所指定的template、文件名template_dataset.py这三者都要保持一致,在实际应用中把template换为你自己的数据集名。具体的命名规范在template_dataset.py这个脚本前面有表述。
好了,刚刚我们已经说明了这个模板函数的作用,下面让我们详细地说一下要实现的是个具体功能:
__len__函数,用于统计数据集里有多少数据,这无需多言,里面需要传入一个self参数,这显然是实例化之后的对象。返回值一般是len(self.A_path),括号内的内容是访问self的路径属性。
modify_commandline_options函数,用于添加针对这个数据集特定的选项,这个脚本里头只是一个样例。
__getitem__函数,这个函数将用来获取数据点,最后要返回的是数据和数据的路径,{‘data_A’: data_A, ‘data_B’: data_B, ‘path’: path},一切信息就都包含在这样一个字典里头。
__init__函数,注意到它需要传入两个参数,一个是self,另一个是opt,前者就是将类进行实例化出来的对象,不用管;后者是我们添加的选项,在options里头文件夹里头有一些BaseOption,我们的opt必须是其中的子集。然后先得继承一下BaseDataset.__init__这个方法,之后在此处要获取数据集的路径,并且还要对输入数据进行一定的预处理。
为了便于大家理解__init__函数,我列举了single_dataset.py这个脚本里的内容进行举例。
def __init__(self, opt):
"""Initialize this dataset class.
Parameters:
opt (Option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
# 调用BaseDataset.__init__方法,将创建好的对象self和你在训练命令里的opt传入。
BaseDataset.__init__(self, opt)
# 用opt.dataroot解析出数据路径,opt.max_dataset_size解析出最大允许数据集大小。
# make_dataset函数是用来制作数据集,返回值是一个图片组成的列表。
# 最后使用sorted函数对图片进行一下排序。
self.A_paths = sorted(make_dataset(opt.dataroot, opt.max_dataset_size))
# 这是对输入进行处理的部分。
input_nc = self.opt.output_nc if self.opt.direction == 'BtoA' else self.opt.input_nc
self.transform = get_transform(opt, grayscale=(input_nc == 1))
读完上面我写的,你可能一头雾水,没事,我们马上就利用示例来分析。
3.3.2 init.py
这个脚本主要是提供接口。里头分成两部分,第一部分有三个函数,第二部分是一个类,里头也有几个函数。
让我们先进入第一部分。
先来看第一个函数find_dataset_using_name,这个函数在这个脚本之外就再也没使用过,推测这个函数是用来按照数据集名称来寻找所对应的dataset类的。我们可以简单地把这个函数的功能理解为,给定一个数据集名,例如Single,我们将singledataset.py脚本中的SingleDataset这个类进行实例化,并返回。整个函数乍一看很难理解,其实不然。第一行dataset_filename = "data." + dataset_name + "_dataset"就是一个简单的拆解,便于第二行datasetlib = importlib.import_module(dataset_filename)进行导入,有人会好奇这第二行是在干什么,这一行是在动态导入对象,dataset_filename只不过就是一个索引而已,导入之后的结果是一个类实例化后的对象datasetlib。这时候小朋友们可能又要问我了,为什么是一个类实例化后的对象?因为你注意看左侧的data文件夹下,任何一个数据集(比如single)是不是都对应着一个脚本(例如:single_dataset.py),而这个脚本里是不是有一个类名字叫做SingleDataset。以后,凡导入这种类实例化后的对象,都是需要动态导入对象的。有些小朋友又会问了,为什么我们要导入这个类的对象,你不是要导入数据集么?很好,我们来看这个类是不是有__getitem__函数,你的数据都是这么被读入的,你可以理解为,数据集被存到这个类实例化后的对象里了。第三行定义一个变量并初始化dataset = None。第四行target_dataset_name = dataset_name.replace('_', '') + 'dataset',简单的文字编辑。第五行到第八行就要正式进入循环了,我们来看datasetlib.__dict__.items(),感兴趣的同学可以去查查__dict__是干什么的python中__dict__的作用是什么? 请参见__dict__的用法
,__dict_也是一个魔法函数,可以把一个类当中定义的属性和方法都作为一个字典返回,而datasetlib.__dict__.items()其实就是方便这个循环遍历这个字典,有小朋友可能会问,为什么我们要遍历?我来告诉你,因为这个类里有很多的属性或方法形成的键值对,而我们需要的只有那些图片名称和图片组成的键值对,所以我们才要在这个循环中的if函数判断其键名name是不是我们所需要的类名,然后如果它同时也是BaseDataset的子集,就说明遍历过程中当前这个cls就是我们所需要的数据集所对应的类。把它读出来给dataset。第九行到第十行是报错信息,如果第九行的条件语句被触发了,那么第十行的raise就会自动执行错误信息,raise是Python一个常见的语法。最后,这个方法显然返回的是第十一行的dataset,return dataset。注意,这个地方的dataset其实还是一个类形成的实例化对象,千万不要认为里头只有图片。
来看第二个函数get_option_setter。这个函数返回的是一个静态方法,这个方法就负责对命令里的option进行编辑(而这些命令就是我们平时启动训练/测试脚本的时候所使用的那些命令),而这个方法就存在于dataset_class这个类里头,这个类又是怎么获取的呢?答案就在上面一个函数里。
再来看第三个函数create_dataset,这次要根据所给的option真正地制作一个数据集了(不再像第一个函数那样返回一个类),代码结构也很简单,一行实例化,一行调用load_data()方法,最后返回所需数据集。但是我们还没有看到CustomDatasetDataLoader这个类呀。别急,我们先继续往下。
来让我们进入第二部分,CustomDatasetDataLoader这个类。
先看看__init__函数吧,需要传入的参数一个是self,就是实例化之后的对象,另一个是opt,也就是各种选项。第一行是self的性质,也就是self.opt,这个就等于你传入的参数opt,第二行,代码是dataset_class = find_dataset_using_name(opt.dataset_mode),这是在做什么?右侧的函数返回值是一个实例化对象,也就是说dataset_class只是一个由相应的Dataset这个类实例化之后的对象(这一点从上面 find_dataset_using_name函数的解释就可窥知一二),然后转化成self.dataset,而self.dataset也是个实例化的对象,这个是要传入到torch.utils.data.DataLoader中的,而且你阅读一下torch.utils.data.DataLoader的使用方法就会发现,第一个参数一定是一个实例化之后的对象。torch.utils.data.DataLoader这个是一个非常常用的Pytorch导入数据之用的东西,具体的用法请参见torch.utils.data.DataLoader的用法,而在这个函数里头,第75-79行这几行代码不难理解,因此我不再赘述。
然后来看看load_data函数,这个没的说,就是读取数据,然后返回self其实也就是返回实例化之后的对象,也就是把数据集导出。
__len__函数就不说了,具体作用大家都懂。
__iter__函数的作用是生成一批数据(batch)并迭代。enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。yield的使用可以从这个链接yield的使用当中得到答案,它的作用是生成一个迭代(常见的迭代比如说斐波那契数列)。
总而言之,这个脚本就是围绕着create_dataset这样一个函数展开的,目的就是根据opt制作数据集,只是一个接口而已。
3.3.3 base_dataset.py
这个文件实现了一些基础的数据读取、转换功能。在BaseDataset类中,所有的函数基本都留空,这个是要根据具体的数据集来确定的,所以base_dataset.py里的这块是空的,可以在template_dataset.py查到每个函数对应的用法示例,而实际的应用就是single_dataset.py、colorizationo_dataset.py等文件里的用法。
我们来看看在BaseDataset类之后有什么函数。
get_params:前面的if语句是根据opt.preprocess去计算新的宽、高大小,而73、74行则是计算x,y,这是两个参数,用于表示图像截取的位置,random.randint(0, np.maximum(0, new_w - opt.crop_size))具体代表什么含义呢?我们不妨这么想,20×20的图片,我们要把它裁剪成10×10,那么裁剪的位置(左上角坐标)只能在左上方10×10的区域之内,要不然的话,被裁剪出的图片就无法成为10×10的图片了,这两行随机数生成就是干这个的;flip参数则是通过生成随机数的方式来计算翻转概率。这里我要多说一句,Transform是torchvision里用于图片预处理的中药模块,里头规定了很多歌变换,使用者经常通过Transform.Compose将其组合起来,如果我们需要的功能源代码里头不能实现,就需要自己定义函数,有关这部分内容可以参见Torchvision中Transform的使用。
get_transform:这个函数的作用即使把所有预处理的方案组合一下,形成一个list,这个list就记录着我们所有的预处理操作。我们来看看81行的几个参数:opt, params=None, grayscale=False, method=Image.BICUBIC, convert=True,opt不说了,就是指定的各个选项;params是上一个函数获取的,默认情况下是None;grayscale应该是是否进行灰度处理;method指的是放大图片的方法,Image.BICUBIC是双三次插值的意思。注意第83-84行,如果grayscale参数是Ture,就执行transforms.Grayscale(1),这个1指的是一个通道;85-87行是说,如果resize为True,则通过双三次插值把图片resize到指定大小;88-89行是等比调整大小,注意前面是elif而不是if,说明和前面的85-87行是有关联的;91-95行是关于裁剪的设定,先要判定params是不是None,如果不是,那就不能采用随机裁剪,而是指定裁剪左上角的点,并指定裁剪大小;97-98行的意思是,如果什么预处理操作都没有,那么就要通过人工调整把图片的宽、高数值调整成4的倍数;100-104行是翻转的相关操作;106-111行属于细微的调整,执行了两个操作,分别是张量化、标准化。最后将所有的变换操作compose到一起。
__make_power_2:这个函数就是要根据给定的方法(例如:双三次插值),将图片变成指定的大小。其中的round函数是一种四舍五入的方法。
__scale_width:这是用于调整大小的一个函数,不难读懂。
__crop:这是用于图片裁剪的一个函数,不难读懂。
__flip:图片左右反转,这个函数不用我说了吧。
__print_size_warning:这个函数只是用来打印一个警告,告诉人们所输入的图片不合乎要求,需要将宽高调整到4的倍数。
3.3.4 image_folder.py
这是一个和图片读取有关的脚本。1-16行不说了,很容易读懂,我们从后面说起。
is_image_file:这个脚本不说了,判定是否为图片。
make_dataset:这就是制作数据集的函数。assert函数就是先判断dir是否是一个路径,如果不是,输出后面的报错信息。os.walk是根据给定的路径dir进行遍历,该函数返回一个 [ 文件夹路径,文件夹名字,文件名 ] 的三元组序列。28-32行很简单,我就不解释了。
default_loader:这是一个默认的“读取器”。指定默认的读取路径,然后转换成RGB图像。这个函数是为后面做准备的。
ImageFolder:这是一个类。43行,根据root来制作数据集,imgs实际上是一个列表;44-46行是在必要的时候返回错误信息;48-52行我就不说了,很容易;54-55行,根据索引来寻找指定序号的图片,56行,根据你给定的loader(52行定义的)去加载图片,存入变量img里,57-58行是预处理,处理的方式在50行已经给定,59-62行就是返回而已,比较容易读懂;64-65行不说了,统计imgs列表的长度,就是想看看数据集的大小。
3.3.5 aligned_dataset.py
先插一句,为什么要准备对齐的数据,这是因为pix2pix模型要用这个。
aligned_dataset.py包含一个可以加载图像对的数据集类。它设置好了一个图像目录/path/to/data/train,其中包含 {A,B} 形式的图像对。在测试期间,您需要准备一个目录/path/to/data/test作为测试数据。那么如何准备对齐的数据集呢,方法在这里。您也可以参阅/pytorch-CycleGAN-and-pix2pix/datasets/combine_A_and_B.py这个脚本,它就是我们在准备对齐数据的时候需要执行的脚本。我们在这里权且先不提,后面还会再说。
让我们来逐个分析在Aligned_dataset类里面的3个函数。
__init__函数:典型的接口函数。14-20行没啥可说的,很简单。第21行是在获取数据的路径(只有路径,没有图片),第22行在3.3.4节中已经说的非常明确了,注意这一行的返回值应当是一个列表,列表由图像组成。第23行是为了确保裁剪大小小于图片本身的大小。第24-25行,如果转换方向是B→A,那模型的input应该是opt里的output,反之则结论相反,而模型的output也有类似的结论。
__getitem__函数:40-41行是单独读取一张图片,并将其转化为RGB,43行是获取图片的宽、高,44-45行是从AB这一张图中获取A和B,什么意思呢?就是对齐的两张图。48-54行是对于图片的预处理,56行是返回一个字典,无需多言。
__len__函数:不用我多说了吧。
3.3.6 unaligned_dataset.py
unaligned_dataset.py包含一个可以加载未对齐/未配对数据集的数据集类。我们可以使用数据集标志训练模型--dataroot /path/to/data。
依然是同样的三个函数,让我们来一一解读。
__init__函数:里面实现的各项功能和3.3.5节中的__init__函数是非常类似的。26-27行获取目录,29-30行生成图片列表,31-32行获取列表大小,33-35行判断转换方向,36-37行生成变换。
__getitem__函数:51-56行是获取图片索引的方式。57-61行是读取图片,并进行简单的预处理。63行就是返回了。
__len__函数:这个函数不用我说了吧。
3.3.7 single_dataset.py
single_dataset.py包含一个数据集类,可以加载由path指定的一组单个图像–dataroot /path/to/data。它只能用于使用模型选项为一侧生成CycleGAN结果-model test。
里面的三个函数完全就是前面3.3.6的翻版,我就不再一一赘述了。
3.3.8 colorization_dataset.py
colorization_dataset.py实现了一个数据集类,可以加载一组 RGB 的自然图像,并将 RGB 格式转换为Lab颜色空间中的 (L, ab) 对。基于 pix2pix 的着色模型 ( --model colorization) 需要它。
modify_commandline_options:这个函数的出现,意味着opt里头一些默认的选项要被修改了,因为对应着着色任务,所以输入维度是1(亮度),输出维度是2(也就是Lab颜色空间中的ab)。
__init__函数:接口函数。第41行的assert函数要注意一下,只有在括号内的内容为True方可执行,否则报错,而其它行基本都在之前遇到过,不再赘述。
__getitem__函数:56行是获取路径,57-59行是读图、转换、数组化,60-61行是从RGB颜色空间转换到Lab颜色空间并转化为张量;62-63行没太看懂,我推测是标准化,64行是返回值。这个函数的返回值A就是亮度,返回值B就是Lab颜色空间里的ab值。
__len__函数:不想说了。。。
3.4 imgs文件夹
这里是两个示例图片,也可以被用来存放效果图。
3.5 models文件夹
模型目录包含与目标函数、优化和网络架构相关的模块。如果要添加一个名为的自定义模型类dummy,那么必须要添加一个名为的文件dummy_model.py并定义一个DummyModel类,这个类继承父类BaseModel。您需要实现四个功能:__init__初始化类(您需要先调用BaseModel.init(self, opt))、set_input(从数据集中解包数据并应用预处理)、forward(生成中间结果)、optimize_parameters(计算损失、梯度和更新网络权重),以及可选的modify_commandline_options(添加特定于模型的选项并设置默认选项)。现在您可以通过指定 flag 来使用模型类–model dummy。有关示例,请参见我们的模板模型类。下面我们详细解释每个文件。
3.5.1 init.py
_init_.py 实现了这个包与训练和测试脚本之间的接口。 train.py并在给定选项的情况下test.py调用from models import create_modelandmodel = create_model(opt)创建模型opt。您还需要调用model.setup(opt)以正确初始化模型。
find_model_using_name:这个函数是根据参数model_name去找对应的模型。第32行的model_filename是这个model所对应的文件名,比如说里头有cycle_gan_model,就对应着models.cycle_gan_model,这是便于import所采用的方法。第33行就不说了,动态导入该文件中的类和对应的名字,形成一个字典,字典的结构是{name,cls}。第34行是先把model置为None。第35行也只是调整格式。第36-39行是重点,逐个判断所导入的字典里头的键值对,其中的name是否和target_model_name一致,如果一致且是BaseModel的一个子集,那么model等于cls并被返回,否则报错。
get_option_setter:这个函数是根据模型名来找到对应的类,赋值给变量model_class,并把其中修改opt的选项返回。
create_model:这个模型主要是将model实例化,并返回对应的对象instance。
3.5.2 base_model.py
base_model.py为模型实现了一个抽象基类 ( ABC )。它还包括常用的辅助函数(例如 , setup, test, update_learning_rate, ) save_networks,load_networks以后可以在子类中使用。
我们来看看BaseModel这个类里包含了什么东西。
__init__函数:首先声明,如果您计划实现自己的类,在__init__函数里,必须要实现自己的初始化,怎么实现呢,要调用 <BaseModel.init(self, opt)>,举个例子:cycle_gan_model.py的第53行。接下来看看这个函数规定了什么属性:第32行的opt不说了;第33行表示的是使用的gpu对应的id;第34行可以传递的信息是本次是否是训练;第35行是在告知torch我们使用哪块GPU训练,还是使用CPU;第36行是数据保存路径;第37-38行:torch.backends.cudnn.benchmark这个东西是cuDNN的一个加速库,如果scale_width被执行,说明输入的图片很可能大小不一致,这将会妨碍神经网络的运算,关于详细的说明请点击这里;第39-43行,分别是损失函数、模型名称、想要可视化展示的图片、优化器、图片路径的列表;第44行我也没太明白。
modify_commandline_options函数:这个留空,具体问题具体分析。该函数是用于修改一些opt用的。
set_input函数:这个函数同样被留空,要针对具体情况具体分析。该函数是用于读取数据的,包含本身的数据和元数据信息。
forward函数:这个函数也被留空了,要针对具体情况具体分析。该函数用于生成中间信息。
optimize_parameters函数:留空函数,用来计算损失、梯度和更新网络权重。
setup函数:这个函数用来加载并打印网络结构,除此之外会创建好一个调度器。第84行是在判断是否是训练状态,如果是,则执行第85行的策略;第85行,首先定义了一个self.schedulers,这个东西是一个列表,用中括号括起来,for optimizer in self.optimizers指的是对于self.optimizers的每一个优化器,都要获取一下学习率更新的策略,怎么样才能获取呢?就是使用networks.get_scheduler(optimizer, opt)这个方法,注意到该方法源码就在networks.py的get_scheduler方法里头,我们下面的network.py的讲解里头会提到。第86-88行,如果self.isTrain这个标志不为真,或者只是继续训练(opt.continue_train为真),那么则要加载已有的网络,当然这块我也有个疑问,就是load_networks这个函数的输入明显应该是int类型(下面定义里头有注释),但为什么第88行其输入是一个字符串呢。不论如何,第89行都要根据opt.verbose是否为真打印一下网络。
eval函数:这是一个评估模式的函数,它将保证模型在测试阶段处于评估模式。对于self.model_names这个列表里头的每一个name(一个name就将对应一个model),第94行,如果name是字符串,那么可以使用getattr函数来判定self这个对象里是否有'net' + name这样一个属性,如果有,则把这个属性值赋给net变量,如果没有则报错,有关getattr()的用法请单击这里。当然,这里的属性值指的就是一个网络,也就是说net代表的是一个网络,所以第96行其实就是开启评估模式。
test函数:这是测试过程中前向传播的函数, with torch.no_grad()可以让节点不进行求梯度,从而节省了内存控件,测试的过程显然是不需要反向传播求梯度的,第105行是前向传播,第106行是计算visdom和HTML可视化的其他输出图像。
compute_visuals函数:这个函数我刚刚已经说过了,计算visdom和HTML可视化的其他输出图像。在train.py的第56行有用到这个函数,这是展示图片代码的一个组成部分。
get_image_paths函数:这个函数是获取图片所在的路径。
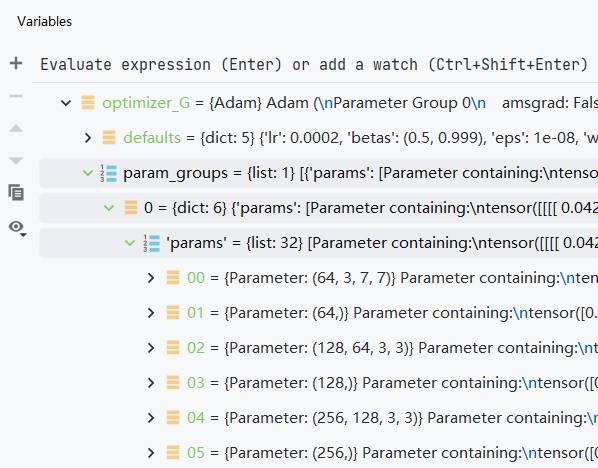
update_learning_rate函数:这个函数用来更新学习率。第118行是获取旧有的学习率,在Pytorch当中,optimizer.param_groups 是长度为2的list,其中的元素是2个字典,详情请单击这里查看,其中的optimizer.param_groups[0]是长度为6的字典,包括[‘amsgrad’, ‘params’, ‘lr’, ‘betas’, ‘weight_decay’, ‘eps’]这6个参数,所以说我们看到的optimizers[0].param_groups[0][‘lr’]就是optimizers[0]这个优化器的学习率。第119-123行其实就是更新学习率的主体部分,其本质是针对每一个self.schedulers这个列表里的元素,根据self.opt.lr_policy来安排一个学习率更新的方法,注意如果学习率更新策略是plateau,会和其它的有些不同,这种情况下第44行已经说了,self.metric=0,其它的只要正常按照step去更新学习率就可以了。关于scheduler.step()这个东西,可以看看这里,我们只需要知道,他是一个用于更新学习率的东西就可以了。第125行是获取现有学习率,第126行是打印学习率的变化。
get_current_visuals函数:用来返回可视化图像。第130行,visual_ret = OrderedDict()是实现对字典的元素排序,赋给visual_ret这个变量,对于self.visual_names列表里的每一个name,第133行都要获取它对应的属性,存入visual_ret这个字典中,和’name’组成一个键值对,最后字典visual_ret被返回。这里的属性可能指的是一张图片。
get_current_losses函数:获取当前的损失值。有人可能会好奇,为什么会有和诺损失函数呢?这是因为每一层所采用的损失函数很可能是不一样的。
save_networks函数:保存整个网络。第150-154行比较好理解,就是指定好保存路径,获取属性(网络)。第156行是在判断GPU是否可用,是够规定了使用gpu进行训练(通过gpu_ids来判断),显然通过这行我们可以知道,CPU和GPU模型的保存模式是完全不同的,在156-160行中,.state_dict()这个方法是用来提取网络中参数的,我们要保存模型,当然是为了保存参数,第158行的意思是说,使用GPU中的第0块进行训练。但为什么这块还要训练一遍我不太懂。
__patch_instance_norm_state_dict函数:这个函数我一直没太懂是什么意思,不过看里面的注释,好像是为了解决Pytorch版本低于0.4的不兼容问题,而我使用的Pytorch是1.10.2,自然没有理会这个函数。
load_networks函数:这是导入网络的函数。从第182行开始,对于self.model_names当中每一个name。第183行,如果这个name是字符串类型,那么就执行后面的操作。第184、185行就是字符串的拼接,获取导入的文件名load_filename和导入的路径load_path。第186行是找到属性的一个办法,回传的是一个属性,即:网络net。第187行,注意isinstance这个函数,它的结构是isinstance(object, classinfo),前者是对象名,后者是类名,也就是判断这个对象是否属于这个类,类似的前面的183行,isinstance(name, str),str也是一个class,所以这一行就是判断net是否属于torch.nn.DataParallel这个类,而torch.nn.DataParallel又是什么呢,它是用于多GPU并行计算的一个类,可以理解为如果属于torch.nn.DataParallel类,那么就需要使用多GPU。第188行,如果要使用多GPU,那每一个GPU上的net应该相当于原有net当中的module,也就是说使用nn.DataParallel后,事实上DataParallel也是一个Pytorch的nn.Module,那么你的模型和优化器都需要使用.module来得到实际的模型和优化器,这就是为什么会有第188行的代码,更多关于并行计算的内容请单击这里。第189行略过。第192行,torch.load这个函数可以加载模型,里头的参数一个是模型存放的路径,另一个是用于训练的装置map_location,当然啦,加载模型的实质是加载参数,这些参数就会被存储在state_dict这个字典之中。第193-194行,首先判断参数字典里是否包含元数据这样的属性,也就是第193行里的__metadata,如果有就删除(因为元数据是描述数据的数据,而我们加载网络参数的时候显然是不需要获取这些元数据的)。第197-198行同样也是兼容问题,所以我们也就没有理会。第199行就是将参数字典导入到我们的网络中了。综上所述,实际过程分成两步,第一步是将导入参数,第二部是将参数字典加载到net里。
print_networks函数:请注意208-210行这个结构出现过很多次了,应该注意记住。param.numel()的功能是返回param中元素的数量,所以说num_params是在统计所有参数的数量。第214-215行不说了,根据verbose判断是否要打印网络。216-217行也很容易理解。
set_requires_grad函数:第225-226行的意思是,如果net不是列表,要先把它列表化;后面的很好理解,把每一个参数是否需要计算梯度设置为您一开始给定的参数值。
3.5.3 template_model.py
这个脚本主要是用来做模板之用。该模块为用户提供了一个模板来实现自定义模型,可以指定“–model template”来使用此模型,类名应与文件名及其模型选项一致。文件名应该是_dataset.py,类名应该是Dataset.py。它实现了一个简单的基于回归损失的图像到图像的转换baseline。给定输入输出对(data_A,data_B),它学习可以最小化以下L1损失的网络netG,使得:
min_<netG> ||netG(data_A) - data_B||_1
modify_commandline_options函数:这个函数专门用来更改opt当中的选项,比如第35行就是把默认的dataset模式改成“对齐”。第36、37行就是在训练状态下,为它新加一个标签,即:lambda_regression,默认值是1.0,第39行不说了。
__init__函数:第51行,对Basemodel通过Basemodel这个类里的__init__函数进行初始化。第53行是指定你想要输出的损失函数名称(把所有的名称存放在这个列表里),程序将会调用base_model.get_current_losse来返回损失函数值并存储。第55行是在调用一个函数去存储,这些图片的保存是通过base_model.get_current_visuals来实现的。第58行是指定需要存储/调用的模型的名字,通过base_model.save_networks和base_model.load_networks来实现,你可以使用opt.isTrain去控制训练和测试模式,这二者往往是不同的。第60行是在定义生成器G,在同一级目录的network里有一个define_G的函数,我们在这里就是调用了这个函数,需要传入的参数包括输入、输出、最后一个卷积层里有多少filter、网络名、使用哪块GPU去训练。第61行,是判断语句,无需多言,注意self.isTrain是在base_model.py里定义的。第64行是定义一个损失函数,把这个损失函数赋值给self.criterionLoss。第67、68行是在定义一个优化器,并把优化器存入优化器列表里,这里我们选用了Adam优化器,具体的公式请参见这里。
set_input函数:这个函数是专门用来设定输入的,第78行是一个判断语句,方向是否是AtoB。第79-80行是读取数据之用,并把它们送入self.device这个装置里,第81行是找到输入图片的路径。
forward函数:第85行就是一个前向输出。
backward函数:这是反向传播。第91行,criterionLoss就是L1损失,后面再去算一个回归损失。self.loss_G.backward()就是计算梯度,并且实现反向传播。
optimize_parameters函数:96-99行注释已经说得很明确了。
3.5.4 network.py
第1-5行是导入一些基础的包。前两行比较简单,第三行的作用是让我们可以使用torch.nn.init进行初始化参数,第四行这个包是一个针对函数进行操作的函数,第五行是导入优化器。
下面介绍Identity这个类。
里面只有一个forward函数,这个函数比较好理解。
下面介绍get_norm_layer这个函数。
这个函数的作用是得出“标准化层”。传入的参数只有norm_type,也就是标准化的方式,这个里头有三种办法,第一种是batch,第二种是instance,第三种是不操作,最后是报错信息,并返回norm_layer.这里就要简单来说说几种归一化方式了,比较详细的介绍可以参考这里,一个图片分成3个通道,于是就有了H×W×C这样的维度,而B张图片加起来就形成了一个batch,这样就变成了,首先是BatchNorm,这种方式会让某个batch中所有的图片位于(c,h,w)这个位置的像素进行标准化,InstanceNorm这种方式对在某张图片的某一个channel内H×W的全体像素做归一化,在这里补充一下Layernorm是什么,这其实是对一张图片的不同通道的同一位置的像素最归一化。只有BatchNorm需要仿射变换以及追踪统计信息。
下面介绍get_scheduler这个函数。
这个函数是用来获取学习率更新策略的。具体每种策略都是怎么回事可以自行查找,不是太难理解。
下面介绍init_weights这个函数。
这个函数用来初始化网络的权重用的。传入参数是初始化的类型和增益的大小。传入的参数m是一个类,79是要获取类名,第80行的意思是如果m包含属性weight且name里有conv或是Linear,则执行下面的操作,注意.find函数的用法。 81-90行是各种权值初始化的方法,不再赘述。91-92行是一个偏差值的指定,相当于y=wx+b里头的b。93-95行则是指BatchNorm2d的情况(输入为2d)。97-98行就是应用。
下面介绍init_net函数。
这个函数将通过调用刚刚的init_weights函数来实现权值初始化,返回一个net。
下面介绍define_G函数。
这个函数用来定义生成器。需要的传参在122-133行详细地说过了。同时我们有两类网络备选,分别是UNet-128/256和Resnet6/9.第146行,设定net的初始值是None(即:什么都没有),第147行是获取标准化层(比如:BatchNorm2d等),后面对类进行实例化的时候会用到。149-160行这个想要读懂并不困难,就是实例化,我们会在后面的文章里介绍那些类。
下面介绍define_D函数。
这个函数用来定义判别器,和刚刚的define_G函数有异曲同工之妙。165-175行详细解释了每个参数的含义,此处不再赘述。177-190行是对网络的各种介绍。192-193行和146-147行是完全一样的。195-203行也是在实例化,我们将在后面对这些类一一揭晓。
GANLoss类
这个类是用来创建不同的GAN对象的,按照注释内所说的,他把“创建与输入大小相同的目标标签张量”这一任务抽象化了。换言之这是用来创建标签用的。
__init__函数:这个函数主要是定义损失函数。需要传入的参数包括gan的模式、目标真值、目标非真值。227行是初始化,228-229行是在保存一些不会更新的模型参数,关于register_buffer函数的用法请参考这里。230行是指定新属性。231-238行是根据gan模式来定义损失,234行的含义请点击这里。
get_target_tensor函数:创建与input大小相同的标志向量。传入参数注释里有明确介绍。第255行就是把target_tensor这个tensor转换成和prediction一样的大小。
__call__函数:这个函数并不难理解,就是计算损失而已。这也是这个类的基本功能。
cal_gradient_penalty函数。
计算梯度惩罚损失,用于WGAN-GP论文,和CycleGAN关系不大。280-291行详细解释了传入参数的含义。由于该函数和CycleGAN关系不大, 我们权且略过。
类ResnetGenerator:
这个类是用来定义残差结构的。
__init__函数:322-332行着重介绍了每个参数的含义。333行是为了防止不合理的数据添加的报错信息。334行是继承。335-338行没太看懂,感兴趣的同学可以看这里,不过大概是确定是否使用bias。340-343行是模型结构的第一部分,其中nn.ReflectionPad2d()的用法请点击这里,这一行指的是在图片上下左右都填充3行;nn.Conv2d是卷积,详细用法看这里;然后是342、343行的标准化、ReLU激活。345行是定义降采样次数,346-350行是模型的扩张。352行就是看一下目前的图片有几个通道(不出意外应该是4倍ngf),353-355行是加入残差块,357-364行执行了两次上采样过程。365-367行是填充、卷积和tanh函数激活,369行将模型确定。
forward函数:这是车头车尾的前向传播。
类ResnetBlock:
这是用来定义残差块结构的。
__init__函数:387行是继承,388行是后面的build_conv_block函数,具体参数会在下一个函数里解释。
build_conv_block函数:391-401行已经把参数的含义揭示了一遍。402行为初始化一个空列表,403-411行都是去进行填充。413行添加新的卷积层、批归一化、ReLU函数。414-415行是随机丢弃一部分神经元,417-426行是把之前的操作又搞了一次,只不过这次没有ReLU激活和dropout。428行是把模型组合起来。430-433行是前向传播的过程。
类UnetGenerator:
这个是用来定义UNet生成器结构的。
__init__函数:440-451行解释说明了参数的含义。452行是继承,454-461都是在定义Unet的结构,大体来说是这样的。
forward函数:前向传播。
类UnetSkipConnectionBlock:
这个类用于定义UNet里面的小结构。
__init__函数:476-487行是已有参数的说明。488行是继承。489行是判断是否为最外侧的一行。490-493行也是决定是否使用偏移。494-495行就是对中间的层采取的措施,在这样的层里,input_nc一开始是None,我们把input_nc和输出的outer_nc设为相等,因为一个Unet子结构是不改变图片通道数量的。见下图。496-499行是下采样过程中的卷积层、激活函数、归一化。500-501行是上采样过程中的归一化、激活函数。503-522行根据三种情况来确定上采样过程中的模型。524-527行是上面的第三种情况里才会调用,总的结构是不难理解的。
forward函数:531-535行是前向传播,这个无需多解释,注意torch.cat是合并的意思,第二个参数是1,说明是横向合并。
类NLayerDiscriminator
这个类是用来创建判别器的。
__init__函数:这个是初始化。542-549行都是参数的定义。550行是继承。551-554行是针对偏移量做出决定。556-558行是在对模型进行组装,形成模型的第一步。559-568行是第二步,也就是逐步增加filter的个数,当然,第二步这个模块的数量和n_layers这个参数是密切相关的。570-576行是第三步,578行是第四步,579行是组装模型。
forward函数:581-583行是前向传播。
类PixelDiscriminator:
__init__函数:590-596行是在介绍参数的含义。597行是继承。598-601行是判断是否需要偏移量。603-609行是网络的定义,总的来说没什么难度。611行是给self.net赋值。
forward函数:613行-615行是前向传播。
至此,network.py长达616行的脚本解读完毕。
3.5.5 cycle_gan_model.py
第2行的itertool是一个Python提供的迭代工具箱,第3行image_pool.py实现了一个存储先前生成的图像的图像缓冲区。这个缓冲区使我们能够使用生成图像的历史而不是最新生成器生成的图像来更新鉴别器。后面就是CycleGANModel这个类,第12-15行有非常明确的概述,dataset模式要使用“非对齐、未配对”,它会使用带有9个残差块的生成器网络结构,并使用PatchGAN这样的判别器结构,以及一个最小方根的GANs对象(就是说损失函数使用LSGAN,平方损失),我们来逐个分析其中的函数。
modify_commandline_options函数:这个就不说了,基本就是option。第39行默认不使用dropout,第40-43行,是指定上面几个损失函数项的权值,45行不说了。
__init__函数:第55行是损失函数列表,里头有几种损失函数’D_A’, ‘G_A’, ‘cycle_A’, ‘idt_A’, ‘D_B’, ‘G_B’, ‘cycle_B’, ‘idt_B’,其中'D_A'和'D_B两个判别器的损失,'G_A'和'G_B'是两个生成器的损失,上面这四项在公式(1)及公式(1)的变体里边都有体现;'cycle_A'和'cycle_B'这两个是循环一致性损失,见公式(2);'idt_A'和'idt_B'是公式(5)里出现的,针对图片→照片任务的损失项。第56-61行指的是要展示/保存的图片,57行是真实的A、经cyclegan转化出的B、经cyclegan重建的A,第58行则是换成B;第59、60行是针对着色任务开辟出来的两项;第63行没什么可说的,就是组合而已。第65-68行是模型的组合情况,就是有哪些模型会被使用。第73-76行没啥可说的,是定义生成器的地方,define_G这里面的参数是什么意思,在1.2.5.4节中有介绍。第79-82行更是类似,生成判别器的地方,define_D这里面的参数是什么意思,在1.2.5.4节中有介绍。第84行跳过,85-86行指的是,如果有“图片→照片”的任务,那么应该保证输入图片和输出图片的尺寸一致,否则报错;87-88行是给训练过程中制作一个imagepool,用于存储历史图片,fakeApool和fakeBpool分别是“BtoA”和“AtoB”情况下的imagepool。第90行是根据你选择的gan模式(opt.gan_mode)确定一个模型,并将其输送到self.device里,剩下两个损失完全都采用了L1损失函数。第94-95行是设定优化器,注意其中的itertools.chain是迭代,也就是把里面所有的参数组合起来,每轮训练过后一起迭代,lr和betas可以自己去查Adam优化器的相关知识,不再赘述;第96-97行是把设定好的优化器加在既有的self.optimizers列表里,这个列表来自basemodel.py。
set_input函数:这个函数和此前的basemodel.py非常像,不再赘述,也很容易看懂。
forward函数:前向传播,非常容易理解,不再赘述。
backward_D_basic函数:第130-135行是用于判别器计算损失的,131、134行就不说了,利用netD去进行判别,得到预测值pred_real和pred_fake,然后再根据这两个值去分别计算损失loss_D_real和loss_D_fake,并且在137行将其combine成为loss_D。138、139行就纯粹是反向传播和返回值了。
backward_D_A函数:第143行是把self.fake_B_pool这个imagepool通过query这个函数拆成单张图片,例如:fake_B。第144行self.loss_D_A是利用上一个函数计算损失值。这个损失值代表的就是从A到B这个风格的转换,所造成的真实B和生成B的区别。
backward_D_B函数:和上面的backward_D_A函数很接近。
backward_G函数:153-155行是权重的计算。156-166行代码的理解并不困难,这是在“图片→照片”任务中会使用的损失,公式可能有点难以理解,不过和原论文5.2节里的东西是完全一致的。168-178行则是简单的损失函数定义并反向传播,没有什么难点。
optimize_parameters函数:这个函数的注释也已经很友善了。有一点不太明白,更新生成器的权重,不需要判别器,但更新判别其权重,却需要生成器?
3.5.6 pix2pix_model.py
该任务和我们的CycleGAN任务暂时无关,是pix2pix里的任务,我们暂时不谈。
3.5.7 colorazation_model.py
该任务和我们的CycleGAN任务暂时无关,是pix2pix里的任务,我们暂时不谈。
3.6 option文件夹
这个文件夹里的4个文件都是用来规定训练命令里的选项之用。init.py是一个接口类型的文件,没有什么用。base_option.py是一些基础性的选项,它还实现了一些辅助功能,例如解析、打印和保存选项。它还收集modify_commandline_options数据集类和模型类的函数中定义的附加选项;而剩下两个文件则分别对应着训练时、测试时的一些选项,原脚本已经把里面的参数解释的明明白白了。
🔥🔥四、提出的全新模型SWLAGAN结构(创新点部分)
🔥生成器网络
自注意力机制
自注意力机制在自然语言处理领域被广泛应用,他可以将输入到全连接神经网络中的多个词语建立语义联系。比如在神经网络中输入多个大小不一的向量,向量之间具有关联,自注意力机制便可以完成多数神经网络都难以实现的向量之间建立关联工作,自注意力机制的算法下图所示。
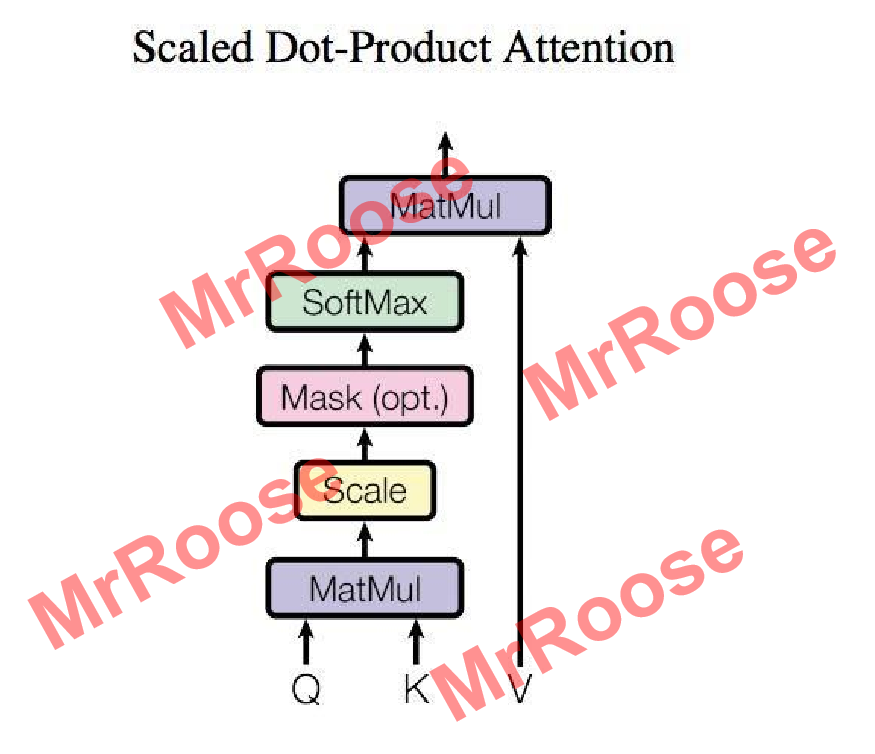
算法流程如下:图中Q,K,V均是由一组词语表示的输入矩阵X经过线性变化得到,Q和K负责建立词语之间的语义关联,通过自注意力的核心算法计算出表现语义关联的距离矩阵。将距离矩阵和矩阵V进行矩阵相乘得到了具有全局关联的输出矩阵。
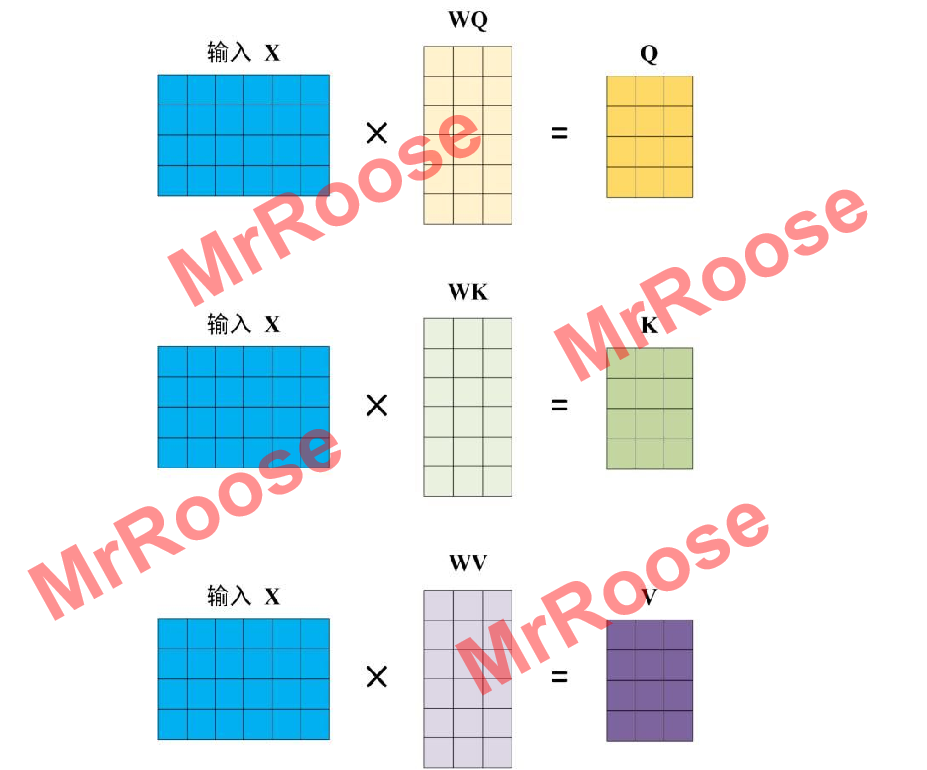
Q,K,V矩阵大小则是由输入矩阵X(X,Q,K,V各行都代表一个词语)经过线性变换而决定的,线性变换矩阵分别为WQ,WK,WV。Q,K,V计算过程图如下图所示。
再计算出矩阵Q,K,V后通过公式得到输出,计算公式如下:
其中是矩阵Q,K的矩阵列数。
通过公式建立词语之间的语义关联,即距离矩阵。其中
的作用是防止Q和K各行内积后,数值过大,而影响语义关联性。Softmax的作用是计算得到每一个词语对应其他词语的关联系数。经过softmax得到的距离矩阵中第i行代表词语i对其他所有词语的关联系数。最后将距离矩阵与V作矩阵相乘得到具有全局关联的输出矩阵。
🔥🔥🔥以下是创新部分的自注意力机制搭建代码:
class Self_Attention(nn.Module):
def __init__(self, in_dim, activation):
super(Self_Attention, self).__init__()
self.chanel_in = in_dim
self.activation = activation
## 下面的query_conv,key_conv,value_conv即对应Wg,Wf,Wh
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1) # 即得到C^ X C
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1) # 即得到C^ X C
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1) # 即得到C X C
self.gamma = nn.Parameter(torch.zeros(1)) # 这里即是计算最终输出的时候的伽马值,初始化为0
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
m_batchsize, C, width, height = x.size()
## 下面的proj_query,proj_key都是C^ X C X C X N= C^ X N
proj_query = self.query_conv(x).view(m_batchsize, -1, width * height).permute(0, 2, 1) # B X CX(N),permute即为转置
proj_key = self.key_conv(x).view(m_batchsize, -1, width * height) # B X C x (*W*H)
energy = torch.bmm(proj_query, proj_key) # transpose check,进行点乘操作
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize, -1, width * height) # B X C X N
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, width, height)
out = self.gamma * out + x
return out🔥可全局连接的残差网路(SA_Blocks)
本人提出的残差网络结构将自注意力机制中全局链接的特性与残差网络可以防止网络退化的特性完美结合。改进了原始残差网络被局限在小窗口提取特征的缺陷,增大了特征提取的全局视野的同时,也增加了多尺度不变的特性。SA_Blocks网络结构图如下所示:
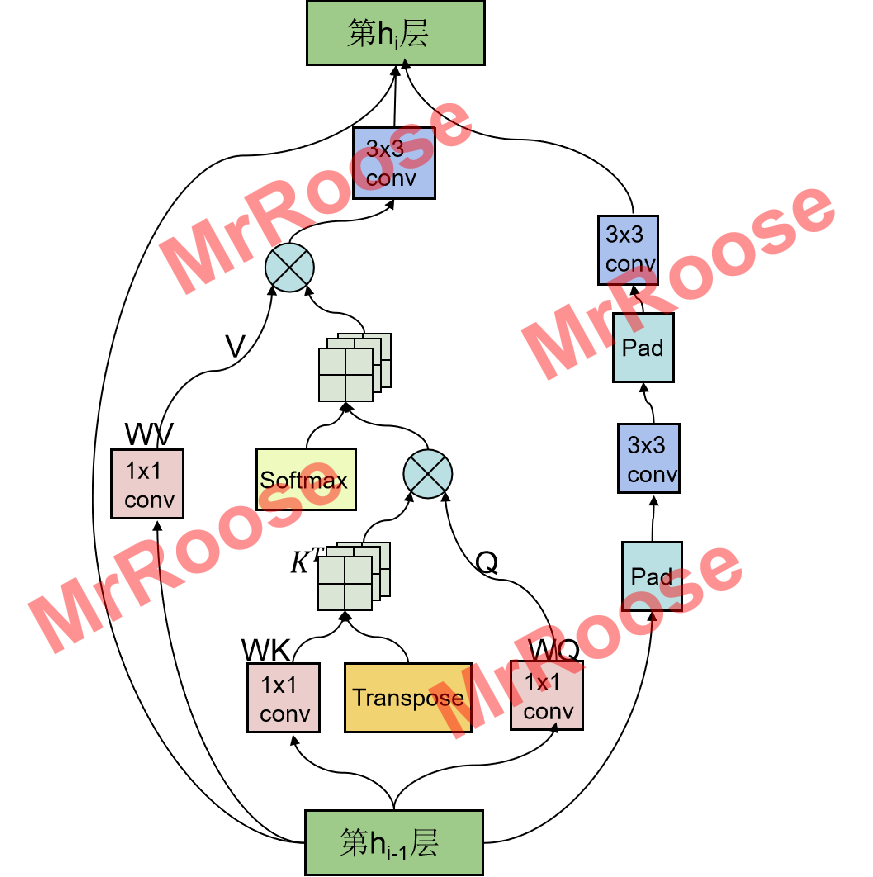
SA_Blocks网络结构在继承了原有残差网络的两个3x3卷积层(Conv)外,又增加了一个自注意力层(SEAT),其工作原理是将特征图X(,C为通道数,H为高度,W为宽度)分别通过三个1×1卷积层,得到特征图Q,K,V,其中Q,K的通道数减半,V保持不变(
,
)。由于自注意力机制公式中具有矩阵计算,因此将Q,K,V进行特征转换(
,
,
)。将转换后的Q和K的转置进行特征矩阵相乘,得到了不同通道之间像素点的关联矩阵β(
)。将关联矩阵β归一化后与V进行特征矩阵相乘,得到具有全局连接的特征图X’,为了增加多尺度空间表达能力,又将X’通过一个3×3卷积层得到输出特征图Y,其表达式为:
🔥🔥🔥以下是创新部分的SA_Blocks网络搭建代码:
class SEA_ResnetBlock_1(nn.Module):
def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias):
super(SEA_ResnetBlock_1, self).__init__()
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias)
self.self_attention=Self_Attention(dim,'relu')
def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias):
conv_block = []
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim), nn.ReLU(True)]
if use_dropout:
conv_block += [nn.Dropout(0.5)]
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim)]
return nn.Sequential(*conv_block)
def forward(self, x):
out = self.self_attention(x) + self.conv_block(x)+x # add skip connections
return out🔥🔥生成器网络结构
生成器模型采用Auto-Encoder+Skip-connection的网络结构,残差网络模块摒弃了原始残差网络结构,使用本文提出的SA_Blocks结构,其特有的全局连接性弥补了原始残差只能局部提取特征的不足,让模型不仅可以在全局上提取特征还具有了多尺度不变性,使生成的图片质量得到提升,SWLAGAN的生成器网络结构图如下图所示。
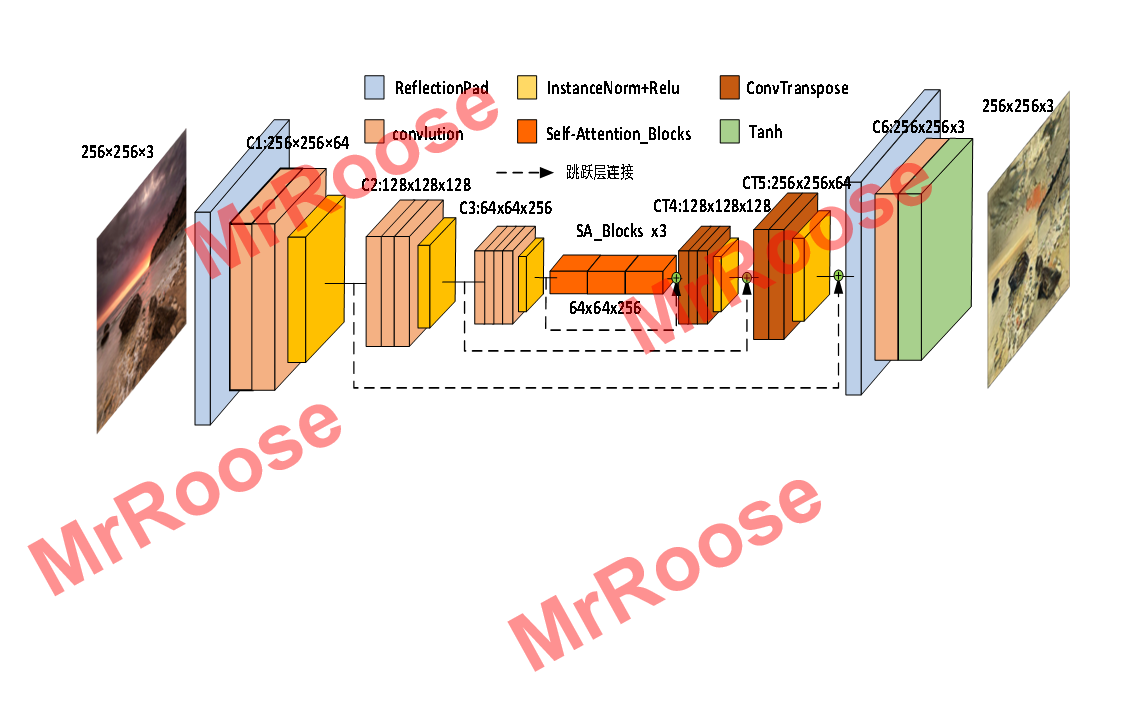
其中蓝色模块是镜像填充层,将对图片四周填充三个像素矩阵的镜像内容;Ci:W×H×C表示目前是第i层卷积,通过该层卷积输出特征图的宽度为W,高度为H,通道数为C;粉色模块是卷积核大小为3,步长为2的卷积操作。褐色模块是卷积核大小为3,步长为1/2的反卷积操作,用来将卷积后的特征图发大。橙色模块是3个连续的SA_Blocks结构,让提取的特征具有全局视野。黄色模块是IN层,将特征图标准化,防止过拟合;虚线部分是将模型中卷积后得到的低级特征与同分辨率下的高级特征进行融合,使模型中各层的特征信息利用率得到提升。
🔥🔥🔥以下是创新部分的生成器构建代码:
class Unet_SEA_ResnetGenerator(nn.Module):
def __init__(self, input_nc, output_nc, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False, n_blocks=6, padding_type='reflect'):
assert(n_blocks >= 0)
super(Unet_SEA_ResnetGenerator, self).__init__()
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
self.pad=nn.ReflectionPad2d(3)
self.Down_conv1=nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias)#下采样第一层
self.conv_norm=norm_layer(input_nc)
self.relu=nn.ReLU(True)
self.Down_conv2=nn.Conv2d(ngf , ngf * 2, kernel_size=3, stride=2, padding=1, bias=use_bias) #下采样第二层
self.SA=Self_Attention_no_connect(ngf*2,'relu')
self.Down_conv3=nn.Conv2d(ngf*2 , ngf * 4, kernel_size=3, stride=2, padding=1, bias=use_bias) #下采样第三层
self.Sa_block_3=SEA_Block_3(ngf * 4, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout,use_bias=use_bias)
self.Sa_resnetblock_1=SEA_ResnetBlock_1(ngf * 4, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout,use_bias=use_bias)
self.resnet=ResnetBlock(ngf * 4, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)
self.Up_conv1=nn.ConvTranspose2d(ngf * 4*2, ngf * 2 , kernel_size=3, stride=2,padding=1, output_padding=1,bias=use_bias)
self.Up_conv2=nn.ConvTranspose2d(ngf * 2*2, ngf, kernel_size=3, stride=2,padding=1, output_padding=1,bias=use_bias)
self.Up_conv3=nn.Conv2d(ngf*2, output_nc, kernel_size=7, padding=0)
self.tan=nn.Tanh()
def forward(self, x):
x1=self.relu(self.conv_norm(self.Down_conv1(self.pad(x))))
x2=self.relu(self.conv_norm(self.Down_conv2(x1)))
x3=self.relu(self.conv_norm(self.Down_conv3(x2)))
x4=self.resnet(x3)
x=torch.cat([x4,x3],1)
x=self.relu(self.conv_norm(self.Up_conv1(x)))
x=torch.cat([x,x2],1)
x=self.relu(self.conv_norm(self.Up_conv2(x)))
x=torch.cat([x,x1],1)
x=self.tan(self.Up_conv3(self.pad(x)))
return x🔥🔥判别器网络
判别器网络,使用Auto-Encoder的网络结构代替原始结构,其核心优势在于判别器的训练不再受到生成器的约束,可以先训练判别器,通过判别器的优化来刺激生成器的训练。进而解决了原始模型会产生的训练不平衡问题,SWLAGAN的判别器网络结构图如下图所示。

判别器在上采样过程中使用扩充加卷积操作来代替反卷积。其中黄色模块表示卷积层,卷积核大小为w,d=(a,b)表示特征图的通道数从a变化为b。Full connected表示全连接层。Subsampling表示平均池化操作。NN Upsampling表示临近点填充层,将图片的四周填充图片对应位置的像素内容。
新判别器可以不受生成器的约束而提前训练,并且还可以带动生成器训练的原理为:假设现在有三张图片,一张是输入x,一张是经过D编码解码后的图片D(x),还有一张是先经过G生成,又经过D编码解码后得到的图片D(G(y))。随着网络的训练,G和D逐渐达到纳什平衡,即,D是通过真实数据分布训练,导致D(x)分布会无限接近x分布,即
。通过极限的思想可得
。此时的x分布将无限接近G(y)分布,此时G便学习到了y源分布到x源分布的映射关系,G和D达到纳什平衡。
🔥🔥🔥以下是创新部分的判别器构建代码:
class Discriminator(nn.Module):
def __init__(self,input_nc,ndf=64,n_layers=3, norm_layer=nn.BatchNorm2d):
super(Discriminator,self).__init__()
# 256 x 256
self.conv1 = nn.Sequential(nn.Conv2d(input_nc,ndf,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
conv_block(ndf,ndf))
# 128 x 128
self.conv2 = conv_block(ndf, ndf*2)
# 64 x 64
self.conv3 = conv_block(ndf*2, ndf*3)
# 32 x 32
self.conv4 = conv_block(ndf*3, ndf*4)
# 16 x 16
self.conv5=conv_block(ndf*4,ndf*5)
# 8 x 8
self.conv6 = nn.Sequential(nn.Conv2d(ndf*5,ndf*5,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(ndf*5,ndf*5,kernel_size=3,stride=1,padding=1),
nn.ELU(True))
self.embed1 = nn.Linear(ndf*5*8*8, 64)
self.embed2 = nn.Linear(64, ndf*8*8)
# 8 x 8
self.deconv1 = deconv_block(ndf, ndf)
# 16 x 16
self.deconv2 = deconv_block(ndf, ndf)
# 32 x 32
self.deconv3 = deconv_block(ndf, ndf)
# 64 x 64
self.deconv4 = deconv_block(ndf, ndf)
# 128 x 128
self.deconv5 = deconv_block(ndf, ndf)
# 256 x 256
self.deconv6 = nn.Sequential(nn.Conv2d(ndf,ndf,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(ndf,ndf,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(ndf, input_nc, kernel_size=3, stride=1, padding=1),
nn.Tanh())
self.ndf = ndf
def forward(self,x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out=self.conv6(out)
out = out.view(out.size(0), self.ndf*5 * 8 * 8)
out = self.embed1(out)
out = self.embed2(out)
out = out.view(out.size(0), self.ndf, 8, 8)
out = self.deconv1(out)
out = self.deconv2(out)
out = self.deconv3(out)
out = self.deconv4(out)
out = self.deconv5(out)
out = self.deconv6(out)
return out🔥🔥损失函数部分
🔥🔥循环一致性损失LPIPS
对于我们人类来说,评估两张图片的感知相似度是一件极其简单的事情,但其中的原理却极其复杂。以前很多学者喜欢使用L2范数,PSNR,SSIM等感知指标函数来复现人类感知图片这种行为。直到LPIPS的出现打破了这种现状,其在无监督模型上学习到的特征在模型低层次感知相似性上比L2范数等损失函数要强很多,在2018年PIRM感知图像超分辨率挑战赛中众多学者联合比较了各损失函数的性能,通过把多个感知模型的计算结果与真实结果进行拟合画线,得到了8张对比图如下图所示。
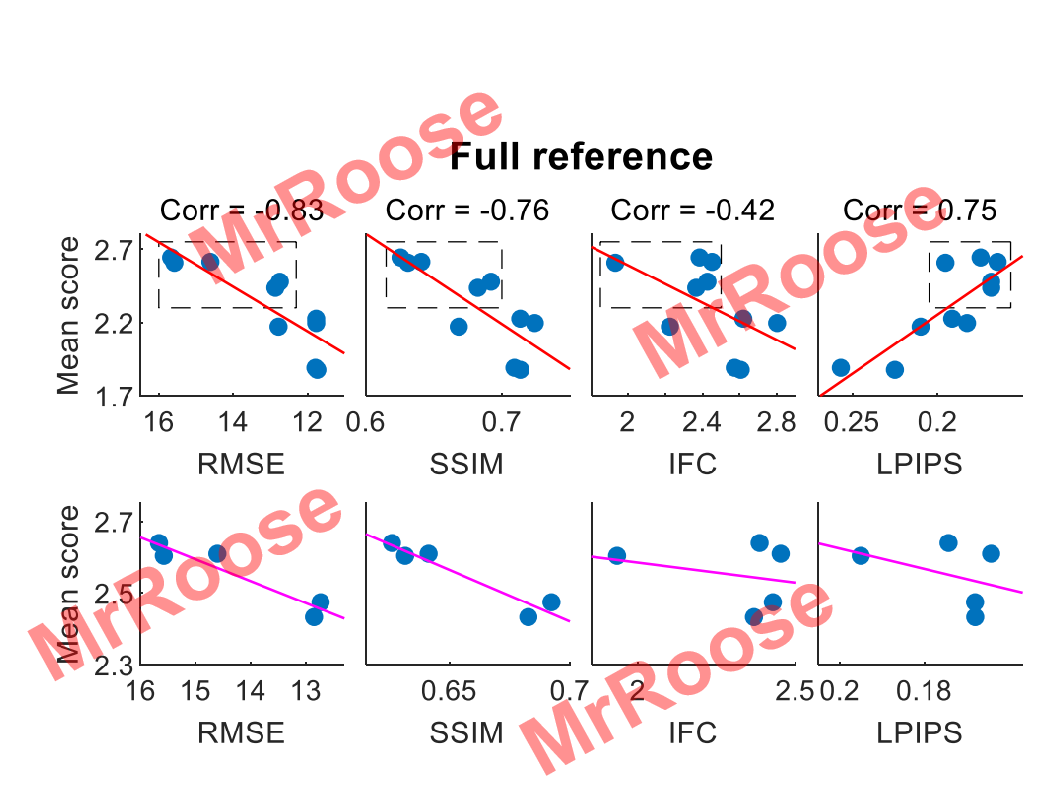
图中Corr代表模型评估的分数和人的主观审美的相似度。其范围在[-1,1],越接近1代表越接近人的主观审美。从图可知,只有LPIPS的评估是正相关,其余都是负相关,所以在感知相似度函数中LPIPS的计算误差是最小的。LPIPS网络结构图如下图所示。
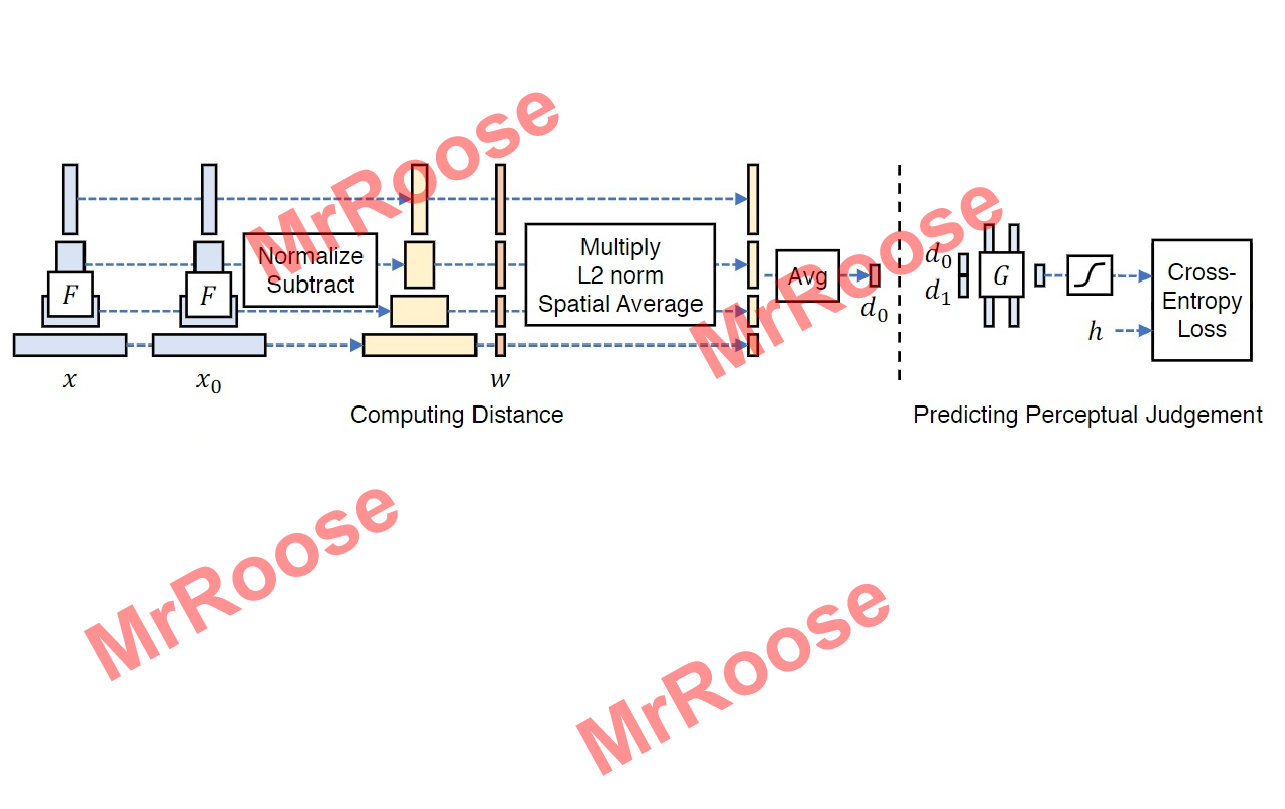
基本原理是将真实图片x与待测图片x0分别带入网络F中进行特征提取,在不同的通道中计算x和x0的特征之间的距离;在不同的卷积层中(这里举例为L层)提取特征堆栈,将不同的通道中特征堆栈进行归一化,此时的结果记为,又通过向量
进行缩放激活通道,使用L2范数计算的距离,并在空间中求平均值,在通道上求和计算出d0。公式如下所示:
其中等同于通过余弦距离公式计算的结果。最后把d0和真实的d1传到含有两个32个通道的RELU全连接层、一个单通道全连接层和一个sigmoid层的模型中训练,其相似性损失函数为:
🔥🔥🔥以下是创新部分的循环一致损失函数LPIPS的构建代码:
self.criterionCycle=lpips.LPIPS(net='alex').to(self.device)
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * 2
self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * 2🔥🔥对抗损失WGAN-GP
Wasserstein距离也叫做Earth-Mover(推土机)距离,其公式如下:
其中代表两种数据分布,并且都是
中的任何一个边缘分布。当r属于联合分布时,真实数据x和生成数据y将从r中采样,
代表真实数据和生成数据的误差,因此当x和y属于所有联合分布时,求得
的期望下界值便是Wasserstein距离。
Lipschitz连续是指在一个连续函数f中,存在一个常数K,且K≥0。使得定义域内任意的x1和x2都满足不等式。且K称为f的Lipschitz常数。
WGAN的目标函数便是基于Wasserstein距离得来的。由于Wasserstein距离公式中有因此无法直接求导,经证明,可将上式转换为下述公式:
又使用参数w定义函数来重新定义公式,近似的公式如下:
可以通过训练含有参数w的神经网络来表示,随着训练次数不不断增加,网络拟合能力增强,最终网络会拟合出
的情况。又防止K值多大而控制网络的所有参数w在[-c,c]之间,使得输入数据x的偏导数
也可以被控制在固定范围内,使模型梯度变化相对稳定。由于Lipschitz连续的条件得到了满足,此时Wasserstein距离便可以用下面公式近似表示:
同GAN原理一样,WGAN中的生成器也是MIN~G,判别器也是MAX~D。所以WGAN的生成器公式如下:
WGAN的判别器公式如下:
如果只进行权重裁剪(c的赋值)会出现两个问题。第一个问题是,神经网络的参数被控制在某个范围内,从而会使全权重分布严重不均,会出现很多极端的参数值。如下图所示,如果权重都集中徘徊在0.01和-0.01两个点,神经网络拟合的能力将会被削弱。
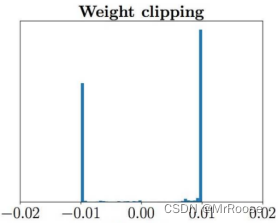
第二个问题在于模型会产生很强的梯度爆炸或者梯度消失,如果权重裁剪过小会出现梯度消失,过大则又会出现梯度爆炸,这两种情况都会导致网络训练极不稳定。
为了解决这些问题,WGAN-GP在原有WGAN的基础上增加梯度惩罚机制,在满足Lipschitz连续条件的同时,通过对梯度变化的约束,使梯度和K之间建立起联系,下面是限制判别器的梯度不能大于K的公式:
随着判别器的判别能力增强,其梯度也会增加,训练结束后,梯度会无限接近K,因此公式可以优化为:
将K=1的梯度惩罚机制与WGAN的损失加权求和得到WGAN-GP的损失函数:
又结合CycleGAN的双生成对抗网络原理,建立两个生成对抗损失,一个是通过G实现X源域转为Y源域的损失公式:
另一个是通过F实现Y源域转为X源域的损失公式:
因此总的对抗损失公式为:
SWLAGAN的总体损失函数为:
🔥🔥🔥以下是创新部分的对抗损失函数的构建代码:
def gradient_penalty(self,netD,real,fake):
BATCH_SIZE,C,H,W=real.shape
epsilon = torch.rand((BATCH_SIZE,1,1,1)).repeat(1,C,H,W).to(self.device)
interpolated_images=real*epsilon*fake*(1-epsilon)
mixed_scores=netD(interpolated_images)
gradient=torch.autograd.grad(
inputs=interpolated_images,
outputs=mixed_scores,
grad_outputs=torch.ones_like(mixed_scores),
create_graph=True,
retain_graph=True,
)[0]
gradient=gradient.view(gradient.shape[0],-1)
gradient_penalty=((gradient.norm(2,dim=1)-1)**2).mean()
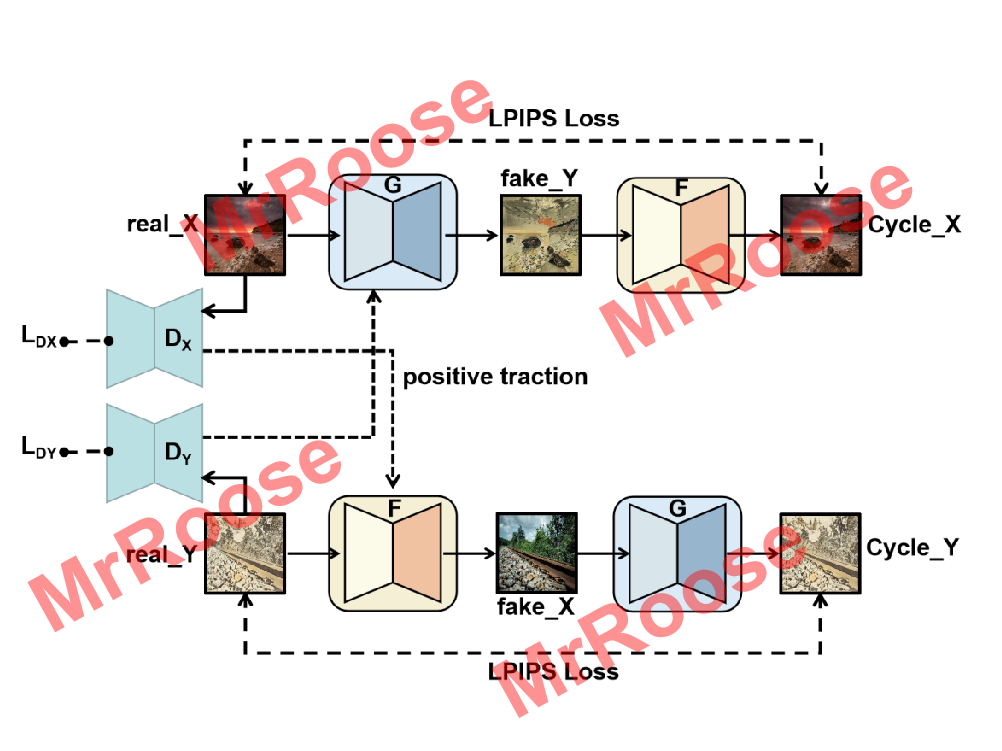
return gradient_penalty🔥🔥🔥SWLAGAN模型训练结构图
🔥🔥五、训练模型的Trick
Trick1:Label平滑
如果有两个目标label:Real=1 和 Fake=0,那么对于每个新样本,如果是real,那么把label替换为0.7~1.2之间的随机值;如果样本是fake,那么把label替换为0.0~0.3之间的随机值。
在models/networks.py中的GANLoss类中的__init__函数中进行修改:
原代码:
def __init__(self, gan_mode, target_real_label=1.0, target_fake_label=0.0):
super(GANLoss, self).__init__()
self.register_buffer('real_label', torch.tensor(target_real_label))
self.register_buffer('fake_label', torch.tensor(target_fake_label))
self.gan_mode = gan_mode
if gan_mode == 'lsgan':
self.loss = nn.MSELoss()
elif gan_mode == 'vanilla':
self.loss = nn.BCEWithLogitsLoss()
elif gan_mode in ['wgangp']:
self.loss = None
else:
raise NotImplementedError('gan mode %s not implemented' % gan_mode)修改后的代码:
def __init__(self, gan_mode):
super(GANLoss, self).__init__()
target_real_label = random.randint(7, 12) * 0.1
target_fake_label = random.randint(0, 3) * 0.1
self.register_buffer('real_label', torch.tensor(target_real_label))
self.register_buffer('fake_label', torch.tensor(target_fake_label))
self.gan_mode = gan_mode
if gan_mode == 'lsgan':
self.loss = nn.MSELoss()
elif gan_mode == 'vanilla':
self.loss = nn.BCEWithLogitsLoss()
elif gan_mode in ['wgangp']:
self.loss = None
else:
raise NotImplementedError('gan mode %s not implemented' % gan_mode)Trick2:将图像输入鉴别器之前,将噪声添加到实际图像和生成的图像中
在models/cycle_gan_model.py中的CycleGANModle类中的backward_D_A函数和backward_D_B函数修改
原代码:
def backward_D_A(self):
"""Calculate GAN loss for discriminator D_A"""
fake_B = self.fake_B_pool.query(self.fake_B)
self.loss_D_A = self.backward_D_basic(self.netD_A, self.real_B, fake_B)
def backward_D_B(self):
"""Calculate GAN loss for discriminator D_B"""
fake_A = self.fake_A_pool.query(self.fake_A)
self.loss_D_B = self.backward_D_basic(self.netD_B, self.real_A, fake_A)修改后代码:
def backward_D_A(self):
"""Calculate GAN loss for discriminator D_A"""
real_B=self.real_B #(B C H W)
fake_B = self.fake_B_pool.query(self.fake_B) #(B C H W)
###给fake_B添加噪点
BatchSize_fake,C_fake,H_fake,W_fake=fake_B.size()
img_fake=fake_B.view(H_fake,W_fake,C_fake) #(H W C)
img_fake_np=img_fake.numpy() #将(H W C)的Tensor转为(H W C)的numpy
h_fake,w_fake,c_fake=img_fake_np.shape
Nd = 0.1
Sd = 1 - Nd
mask_fake = np.random.choice((0, 1, 2), size=(h_fake, w_fake, 1), p=[Nd / 2.0, Nd / 2.0, Sd]) # 生成一个通道的mask
mask_fake = np.repeat(mask_fake, c_fake, axis=2) # 在通道的维度复制,生成彩色的mask
img_fake_np[mask_fake==0]=0
img_fake_np[mask_fake==1]=255
img_fake_Tensor=torch.from_numpy(img_fake_np) #(H W C)numpy转为(H W C)的Tensor
H1_fake,W1_fake,C1_fake=img_fake_Tensor.size()
fake_B=img_fake_Tensor.view(BatchSize_fake,C1_fake,H1_fake,W1_fake) #将(H W C)的Tensor转为(B C H W)的Tensor
###给real_B添加噪点
BatchSize_real, C_real, H_real, W_real = real_B.size()
img_real = real_B.view(H_real, W_real, C_real)
img_real_np = img_real.numpy()
h_real, w_real, c_real = img_real_np.shape
mask_real = np.random.choice((0, 1, 2), size=(h_real, w_real, 1), p=[Nd / 2.0, Nd / 2.0, Sd]) # 生成一个通道的mask
mask_real = np.repeat(mask_real, c_real, axis=2) # 在通道的维度复制,生成彩色的mask
img_real_np[mask_real == 0] = 0
img_real_np[mask_real == 1] = 255
img_real_Tensor=torch.from_numpy(img_real_np)
H1_real,W1_real,C1_real=img_real_Tensor.size()
real_B=img_real_Tensor.view(BatchSize_real,C1_real,H1_real,W1_real)
self.loss_D_A = self.backward_D_basic(self.netD_A, real_B, fake_B)
def backward_D_B(self):
"""Calculate GAN loss for discriminator D_B"""
real_A=self.real_A
fake_A = self.fake_A_pool.query(self.fake_A)
###给fake_A添加噪点
BatchSize_fake, C_fake, H_fake, W_fake = fake_A.size()
img_fake = fake_A.view(H_fake, W_fake, C_fake)
img_fake_np = img_fake.numpy()
h_fake, w_fake, c_fake = img_fake_np.shape
Nd = 0.1
Sd = 1 - Nd
mask_fake = np.random.choice((0, 1, 2), size=(h_fake, w_fake, 1), p=[Nd / 2.0, Nd / 2.0, Sd]) # 生成一个通道的mask
mask_fake = np.repeat(mask_fake, c_fake, axis=2) # 在通道的维度复制,生成彩色的mask
img_fake_np[mask_fake == 0] = 0
img_fake_np[mask_fake == 1] = 255
img_fake_Tensor = torch.from_numpy(img_fake_np)
H1_fake, W1_fake, C1_fake = img_fake_Tensor.size()
fake_B = img_fake_Tensor.view(BatchSize_fake, C1_fake, H1_fake, W1_fake)
###给real_A添加噪点
BatchSize_real, C_real, H_real, W_real = real_A.size()
img_real = real_A.view(H_real, W_real, C_real)
img_real_np = img_real.numpy()
h_real, w_real, c_real = img_real_np.shape
mask_real = np.random.choice((0, 1, 2), size=(h_real, w_real, 1), p=[Nd / 2.0, Nd / 2.0, Sd]) # 生成一个通道的mask
mask_real = np.repeat(mask_real, c_real, axis=2) # 在通道的维度复制,生成彩色的mask
img_real_np[mask_real == 0] = 0
img_real_np[mask_real == 1] = 255
img_real_Tensor = torch.from_numpy(img_real_np)
H1_real, W1_real, C1_real = img_real_Tensor.size()
real_B = img_real_Tensor.view(BatchSize_real, C1_real, H1_real, W1_real)
self.loss_D_B = self.backward_D_basic(self.netD_B, real_A, fake_A)加噪点思路:参考了该文章的椒盐噪点
并且由于fake_A等变量是(B,C,H,W)的Tensor,而文章中的算法是基于numpy,因此只需要将fake_A等变量先从Tensor->numpy->算法->Tensor
Trick3: 判别器的优化频率高于生成器。
原代码中判别器的训练次数和生成器的训练次数的比例是1:1,即每一个epoch的时候只训练一次Generator和Discriminator。现在我尝试一个epoch的时候,训练一次Generator,然后用其生成的fake图片训练3次Discriminator。
原理:1)Trick2的噪点会使Discriminator难以训练。
2)多训练Discriminator,能够刺激Generator模型的训练从而生成好的效果图。
在models/cycle_gan_model.py中的CycleGANModel类中的optimize_parameters函数中进行修改
原代码:
def optimize_parameters(self):
# forward
self.forward() # compute fake images and reconstruction images.
# G_A and G_B
self.set_requires_grad([self.netD_A, self.netD_B], False) # Ds require no gradients when optimizing Gs
self.optimizer_G.zero_grad() # set G_A and G_B's gradients to zero
self.backward_G() # calculate gradients for G_A and G_B
self.optimizer_G.step() # update G_A and G_B's weights
# D_A and D_B
self.set_requires_grad([self.netD_A, self.netD_B], True)
self.optimizer_D.zero_grad() # set D_A and D_B's gradients to zero
self.backward_D_A() # calculate gradients for D_A
self.backward_D_B() # calculate graidents for D_B
self.optimizer_D.step() # update D_A and D_B's weights修改后的代码:
def optimize_parameters(self):
# forward
self.forward() # compute fake images and reconstruction images.
# G_A and G_B
self.set_requires_grad([self.netD_A, self.netD_B], False) # Ds require no gradients when optimizing Gs
self.optimizer_G.zero_grad() # set G_A and G_B's gradients to zero
self.backward_G() # calculate gradients for G_A and G_B
self.optimizer_G.step() # update G_A and G_B's weights
# D_A and D_B
self.set_requires_grad([self.netD_A, self.netD_B], True)
for i in range(3):
self.optimizer_D.zero_grad() # set D_A and D_B's gradients to zero
self.backward_D_A() # calculate gradients for D_A
self.backward_D_B() # calculate graidents for D_B
self.optimizer_D.step() # update D_A and D_B's weights🔥🔥🔥🔥六、成果展示
🔥🔥由于要忙一些其他事情,这篇论文其实还未发表,一拖再拖。但很多小伙伴在后台私信问我细节。我就把绝大多数的创新细节都开源分享给大家了。实验数据这部分因为论文原因暂不公布。给大家看几张效果图。等后续我再update。
🔥🔥这是其中的一个实验春天和秋天的风格转换:



![[SSM]MyBatis的缓存与逆向工程](https://img-blog.csdnimg.cn/23f28a3097a44badb6af0b1e47d4295c.png)