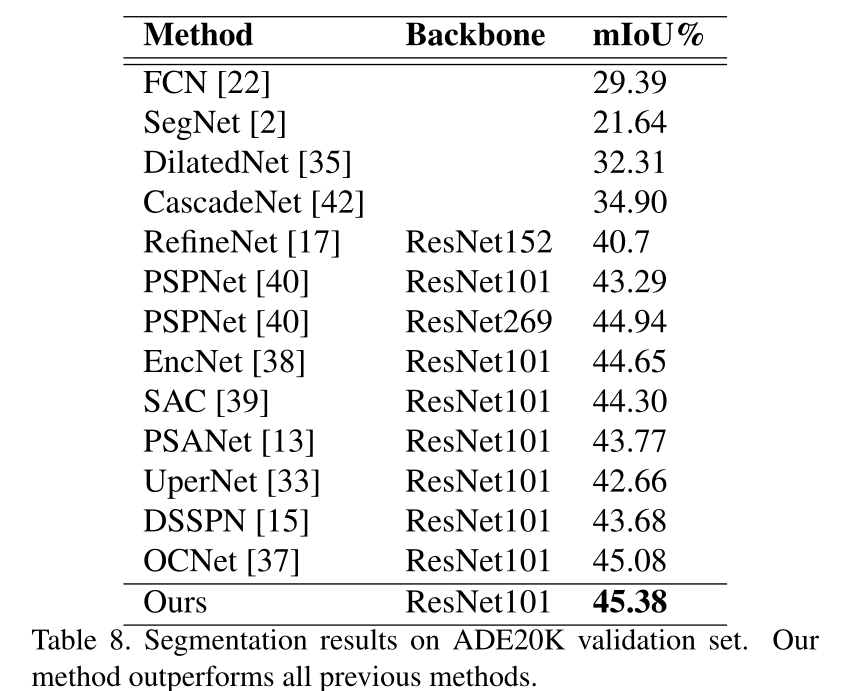
下文整理自清华大学大数据能力提升项目能力提升模块课程“Innovation & Entrepreneurship for Digital Economy”(数字经济创新创业课程)的精彩内容。
主讲嘉宾:
Kris Singh: CEO at SRII, Palo Alto, California
Visiting Professor of Tsinghua University
Rick McGeer:CEO at engageLively, California, USA


今天我们邀请的专家Rick McGeer,他在数据分析、软件以及互联网领域有深厚的专业知识,并且取得了一些非常好的成绩。他现在也在运营一家公司,主要关注数据分析的未来。他目前所拥有的数据分析工具,也正是我想分享给大家的,这种分析工具可以从各种资源当中捕获大量数据并且进行快速分析,并获得清晰的结果和结论。在开始之前,我还是简单地引入一些背景知识。
正如我在以前的课上所提到的,数据是数字经济的基础。过去的经济基础是石油、天然气和金融等,未来将是数字化和依赖于数据的数字化。所以无论你是什么领域、什么专业,数据分析都是你必备的技能。数据量增长极其之快,特别是在最近的十年里,数据呈现指数级增长。虽然拥有大量的数据是件好事,但是数据本身并不能提供价值,除非你知道如何分析并让数据变得有意义,而这就是我们今天所面临的挑战。数据可以分为结构化数据和非结构化数据,当今超过80%的数据都是非结构化的,我们并不知道应该如何分析,而没有合适的分析则数据毫无价值。
——Kris
我的计算机有1TB硬盘空间,1ZB是10亿TB,所以你需要一个十亿量级的硬盘来存储信息。而到2025年世界上将会有200个ZB的数据,而2010年仅有2个ZB,这意味着在15年内,我们的数据总量扩大了100倍。每18个月过去,这个数据量还要翻倍。所以到2025年,我们每个人需要30台计算机来存储个人数据。那么这么多数据究竟用来干什么呢?下图中有一个列表。但是Kris说,数据是21世纪的石油,他说得简直不能更正确了。


在我的人生里,发生了人类历史上意义最深远的变革。人类第一次能够在非常短的时间里,在原子的水平上控制这个世界。而这一人类技术的重大变革关键在于数据。数据有很多应用,可以实现娱乐设施的优化。网飞利用数据来优化推荐我们所看的视频。但是这里是数据的爆炸,用于让我们以细粒度的层面控制整个世界,解决二十一世纪的挑战。让世界摆脱疾病困扰,实现碳减排以及其他任务。但是问题在于,这个大数据时代却没有量化分析方法,我们的要求完全超过了计算机工具的能力范畴。
我的朋友roger buss,他正在做攻克核心壳体技术,他想做成永久可用的电池。他们通过精细化操纵电池壳子周围的纳米材料,这需要上千次实验才能完成。我对roger说他是当代爱迪生,因为他像爱迪生一样持续地寻找合适的材料让实验成功。他在几个月的时间里持续对电池充放电,检验当前电池的充电能力。每次实验就会产生五百到一千条记录。所以在我跟他一起工作的时候,他已经有将近十亿的工作表记录储存在计算机上了。无结构的数据尚且难以使用,像这样有结构的数据也像散落的奶酪一样毫无头绪,在庞大的数据集里找到正确的数据并做完分析工作任务量太艰巨了,他完全没有可见的解决方法。
但现在他将数据都储存在云数据库里,并且全程实现共享分析,使用的工具在大学阶段就熟练掌握的可视化拖拽操作,不需要IT专业人才参与。因为云的出现,我们可以打破由于计算机硬件存储带来的限制,软件安装和维护也变得更为容易。我们现在都是数据的探索者,而非数据科学家,在我们的时代,编程还是少数人的技能。而在今天伯克利80%以上的学生至少上过一门编程课,40%的人至少上过一年的数据科学类课程。大部分人不是计算机科学家,但是编程却是他们工作的一部分。正如美国著名的记者Nate Silver曾说“每个记者都得会编程”。但他们只需要会用即可,所以云正是可以简化这一过程的工具,他们无限制地使用云上的工具做分析,也不用掌握IT技术。他们在个人计算机上使用Excel常常面临内存不够用的问题,现在他们可以使用Jupyter这一由伯克利大学开发的有着3500万用户的开源工具。Jupyter近五年的下载量甚至达到了1亿,日常活跃用户有3500万人,它可以用于做任何事。我所认为的分析计算环境就是一个基于云的平台,可以获取实验数据。软件在云平台上运行,实现线下同步,且环境是可以量化的。它可以使用任意的应用程序或系统聚类工具,用于本地和全局资源,没有区域限制,它可以获取所有计算机资源。
如今,获取所有计算机资源的基础已经实现了。一个可规模量化的计算机,在云上存储,可以获取任何数据资源,能够实现可视化,网络缓冲,不需要软件安装和维护。目前最流行的分析工具的基础服务器叫Jupyter hub。这个工具会提供给人们一个服务器,而存储本身是在云环境中实现。它是一个在云端的计算机,可以满足多种用途和需求。它有一个Jupyter实验室编辑器作为服务器的统一和可扩展前端。你也可以在一天甚至几个小时之内就建立一个新的服务器,充分利用Jupyter实验室的资源发展社区。重要的是它的主界面看起来就像是Windows或mac或一般的计算机桌面,不同之处在于这窗口能够像计算机程序一样获取巨大的云平台资源。启动器是这是屏幕右边的大区域是放程序的地方,虽然现在很空,但是它可以扩展到托管任何web前端的应用程序。我们的产品可以让你通过拖拽建立交互上仪表板,并发布到网络平台。我们的软件是云应用,你可以从桌面启动,并与环境无缝衔接。

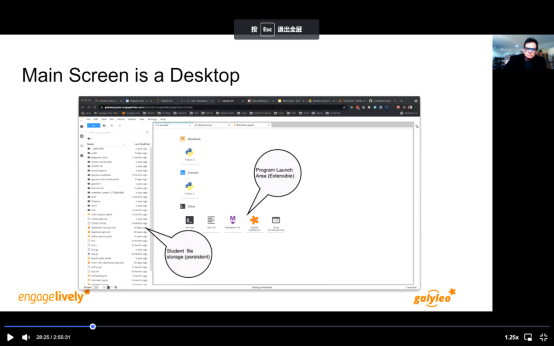
不只是我们,所有的云应用都在网络上有前端和后台,这就是二十一世纪的数据分析环境。容易的是搭建一个非常简单的数据服务器,所有人都可以自己搭建,完成基础的获取数据请求,并将数据请求通过Internet发出任务。我们需要做的就是把小型数据服务器放到设备面前,在响应请求时抛出数据并将其插入到Jupyter环境中,让任何人都可以看到。这在历史上可被认为是第三代网络计算环境的进化。第一代仅仅是简单的电子邮件和网络,在1990年代,人们可以发布文档并且通过网络和基本的交流方式进行传输。
第二代里,我们用表格作为企业展示工具,canva作为设计工具,如果你考虑一些这些东西都是独立的应用,不具备数据共享的能力。在很多方面,它们就像20世纪70年代计算机出现之前的网络一样,当时有一些专门的设备被称为文字处理器或cad工作站。他们并非通用计算机。而专用计算机只是在做文字处理工作,本质上只是一台运行前置字的计算机,但它不能运行其他任何东西,因为cpu太有限了。不管是设计生产力工具还是办公室套件,都太有限了,这是对网络理解力的不足,网络在普遍意义上可以成为计算环境、数据分析环境,把一切搬到云平台上。所以人们提供的是标准的竖井应用,很像70年代的文字处理器应用,而不是分析计算环境要做的任务,它是否提供了云计算中的通用计算机的等价品,在共享存储上有许多应用程序运行,这是第三代。这就是21世纪的数据分析环境,我也乐于向大家分享,感谢Kris的邀请。
——Rick McGeer
数据分析不仅在美国,在整个世界也是一个大的主题。能够以最佳方式处理数据的人,也能够建立起更好的经济。未来的经济就是数字经济——以数字创造价值。Galileo是一个非常好的平台,我知道在一些新兴经济体也在极力寻求合适的工具和技术用于搭建服务于群体和组织的平台。让我来总结一下Rick的发言,数据对我们所有人都很重要,数据体量增长极其之快,主要来源于智能手机、笔记本、传感器以及我们使用的其他技术。我们有大量的数据资源,而未来IOT数据爆炸式增长将取代其他数据来源排到数据增长的第一位。


AI和机器学习和各种新技术的基础都是数据。AI就是数据分析并让数据更有意义的一种方式。AI提供了平台和工具更好地进行数据分析,所以AI和数据之间建立了连接,从上图中你也可以看到数据挖掘、数据科学以及统计这些耳熟能详的术语都与数据本身有关系。
数据分析是一个全球化趋势。无论你是工程师、领导者或者数据科学家,甚至是工厂员工或者政府工作人员都在此一役中有独特的角色。
我们如何将数据转换为智能和行动。数据对我们个人而言意义不大,除非你对此进行了分析和理解,并找出其中的意义。这里有一个医疗的例子,我们如何使用数据,以及医疗如何具备更高效的潜力。今天的医疗系统有一系列的问题,很昂贵,也面临很多挑战,但这里有专业知识的人,我们有外科医生、内科医生还有很多其他的医生,他们对病人的感受理解更为准确,他们就可以使用他们的情境知识,并利用机器人这些技术工具进行诊断,但技术工具本身不可能非常有帮助,除非有了解医学领域专业知识的人在。

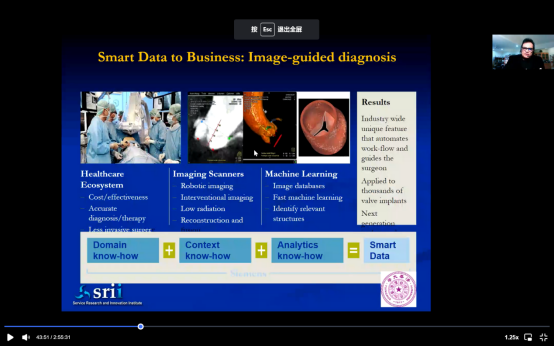
所以将情境和领域专长连接起来,并做分析,这就是AI和机器学习重要的原因。从专业知识开始,再到理解工作领域,之后再使用数据完成分析并协助你,获得结果。结果再用于帮助产生影响,这就叫做智慧数据。智慧数据需要领域专长、需要情境、需要分析技能,把这些整合在一起,就是叫智慧数据。
——Kris
编辑:于腾凯
校对:杨学俊