总第548篇
2022年 第065篇

美团外卖推荐团队在推荐算法的长期落地实践中,针对外卖业务情境化特点对排序模型进行深入探索与优化。本文介绍了面向情境化建模的“情境细分+统一模型”建模思路,通过用户行为序列建模以及专家网络两个模块的优化,实现不同场景间对信息独有性的刻画和信息共性的相互传递,进而提升全部流量效率。
1. 引言
2. 问题与挑战
3. 情境化智能流量分发
3.1 情境化长序列检索
3.2 情境化多专家网络
4. 总结和展望
1. 引言
美团外卖推荐服务了数亿用户,通过持续优化用户体验和流量分发精准性,为用户提供品质生活,“帮大家吃得更好,生活更好”。对于“用户”,大家可能会有不同的理解,通常的理解是用户即是自然人。业界主要的推荐场景,如淘宝首页猜你喜欢、抖音快手 Feeds 流推荐等大部分也是这么认为的,在这些电商、短视频等业务中,用户无论何时何地使用推荐服务,他们的需求是大体统一的,商品、信息、视频等供给也是一致的。
但实际上,在美团外卖场景下,用户不仅是自然人,更是需求的集合。需求是与情境依存的,也就是有情境就有需求。美团外卖在不同的时间、空间以及其他更广义的环境下,用户需求、商家供给等都有显著区别。因此,本地化、餐饮习惯、即时履约共同构建了美团外卖多种多样的情境,进而衍生出用户多种多样的需求集合,推荐算法情境化可以帮助算法更好地理解并满足不同情境下用户需求。
2. 问题与挑战
外卖场景具有很强的地理位置和就餐文化约束,用户在不同地点(如公司、住所)的需求有较大差异。而且,所处时间也是决定用户下单的一个关键因素。以北京某地区高消费用户为例,工作日和周末在成单品类、成单价格、成单商家配送距离上有着明显的不同。如下图 1 所示,工作日与周末用户在口味、心态上有明显变化,工作日多为单人餐,以饭类套餐、轻食、米线为主,更加适应工作时的快节奏;而在周末,用户会适当犒劳自己、兼顾家人,倾向于选择更适合多人就餐的烧烤、韩国料理、火锅。从图 1 也可以发现,从工作日到周末时,用户的成单价格中位数由 30 元提高至 50 元,能够接受的配送距离也在变长。
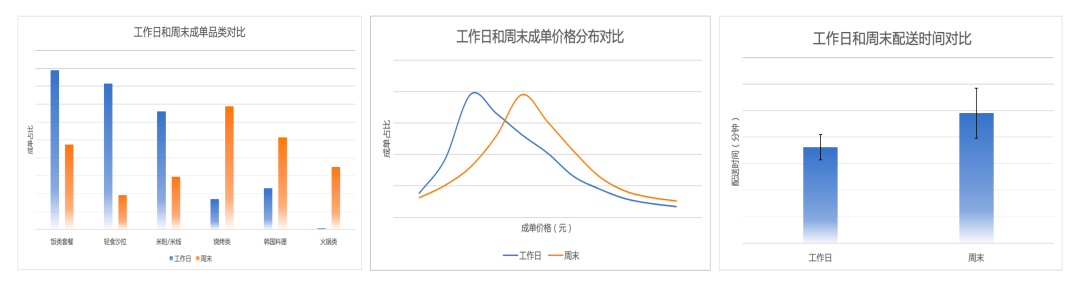
图1 某地区高消费用户在工作日和周末的差异性就餐习惯
美团外卖推荐需要满足“用户 X 时间 X 地点”等情境下的需求总和,应对需求的不断拓展和演化。为了更好的理解我们所面对的用户需求,如下图 2 所示,将其定义到一个魔方内(Magic Cube),用户、时间和地点是魔方的三个维度。其中,魔方中的每个点,如图 2 中黄色点,代表一个用户在一个特定情境下的需求;魔方中的每个小立方体,如图 2 中黄色立方体,代表一组相似用户在一组相近情境下的需求。此外,在问题定义上,为了支持情境维度的进一步扩展,我们使用超立方体(Hyper Cube)来定义更多维度的用户需求。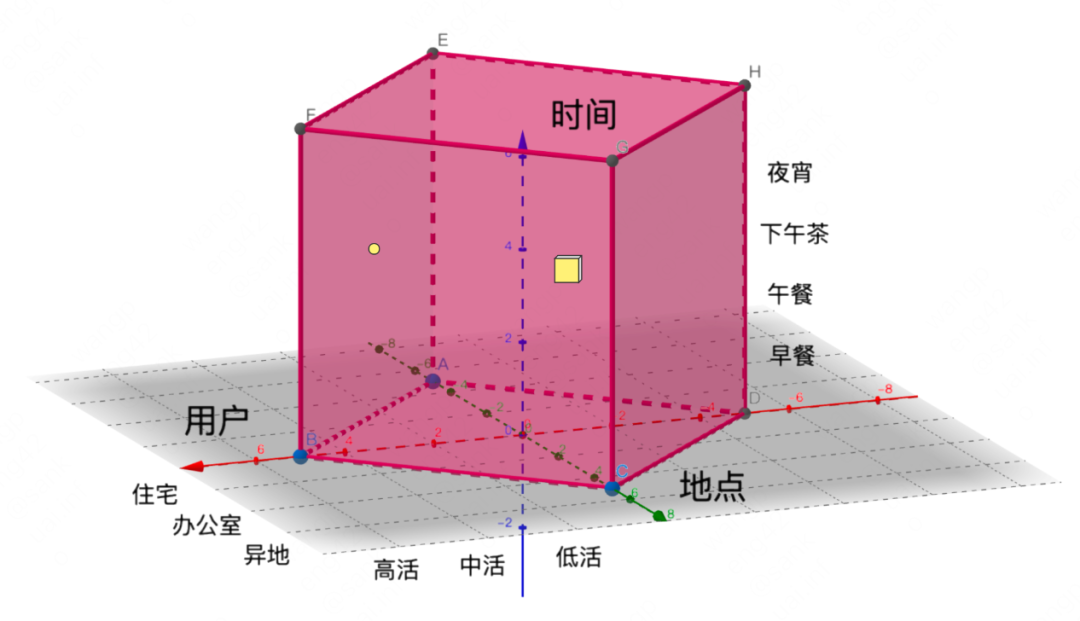
面对以上这种三维模式,模型设计是非常棘手的。以往的模型设计,比如用户兴趣建模,或者朴素的多层神经网络无法应对这些复杂的用户、时间和地理环境纠缠在一起的情况。用户兴趣建模通常采用连续建模方法,通过注意力机制提取重要行为偏好信息。但是在用户行为丰富的情况下,模型很难对所有行为进行学习,并且在外卖场景只有一部分历史行为与用户的当次访问高度相关,连续的行为建模会削弱相关部分的信号。
此外,朴素的多层神经网络基于全部情境下的数据和标签进行训练,只能学习到整体的数据分布表现,在每个情境下很难达到最佳效果。针对这一问题,阿里 SIM4首先考虑了把行为中的重要相关信息搜索出来进行建模的方式,但他们所要解决的问题在于降低用户超长序列建模的离在线资源消耗,并没有在模型中引入情境特点;蚂蚁 ASEM216、腾讯 CSRec17等通过模型自动化选择不同场景专家网络进行共享或独立学习提升全场景或者多任务模型表现,但是这些工作都只专注于单一维度情境,并没有做更广泛的拓展。
针对无限细分的用户情境以及情境的不断拓展和演化,为解决以上挑战,我们提出“情境细分+统一模型”(Segmented and Unified Model)的建模思路。情境细分针对用户特定情境进行针对性建模提升推荐精准度,统一模型将多个相近用户情境进行知识共享和迁移解决情境拓展和演化的问题。
具体来说,依据 Cube 中的每个情境,可以从用户历史行为中检索出与当次访问最相关的行为,精确刻画当前情境下的用户偏好。此外,我们设计多个专家网络,让各个专家专注于学习细分情境下的数据分布,然后基于用户、城市、时段、是否周末等情境强相关特征来进行专家的挑选,不同情境可以学习到是否共享某个专家或者学习到与众不同的专家选择分布。对于新用户或者行为不够丰富的用户,借鉴 Cube 的概念,可以考虑从 Cube 中检索出近似情境,并根据近似情境检索出的行为作为用户在当前情境下的兴趣补充,同时对于情境化专家网络,通过模型设计让不同专家专注于自己情境的同时,针对本情境,利用其他情境知识进行知识迁移,这样缓解了新用户冷启动问题以及可能存在的数据稀疏问题。
除了依据时间、地点进行情境细分之外,还可以将不同的流量入口(首页、金刚位、活动页)、业务类型(外卖、闪购、医药)都当成一种特殊的“情境”,这样“用户 X 时间 X 地点”可以自然拓展成“用户 X 时间 X 地点 X 入口 X 业务”的高维情境,通过对信息独有性的刻画和信息共性的相互传递,实现全部流量的效率提升。
3. 情境化智能流量分发
“情境细分+统一模型”的实现思路主要分为用户行为序列建模与专家网络结构两个组成部分,模型整体架构如图 3 所示:
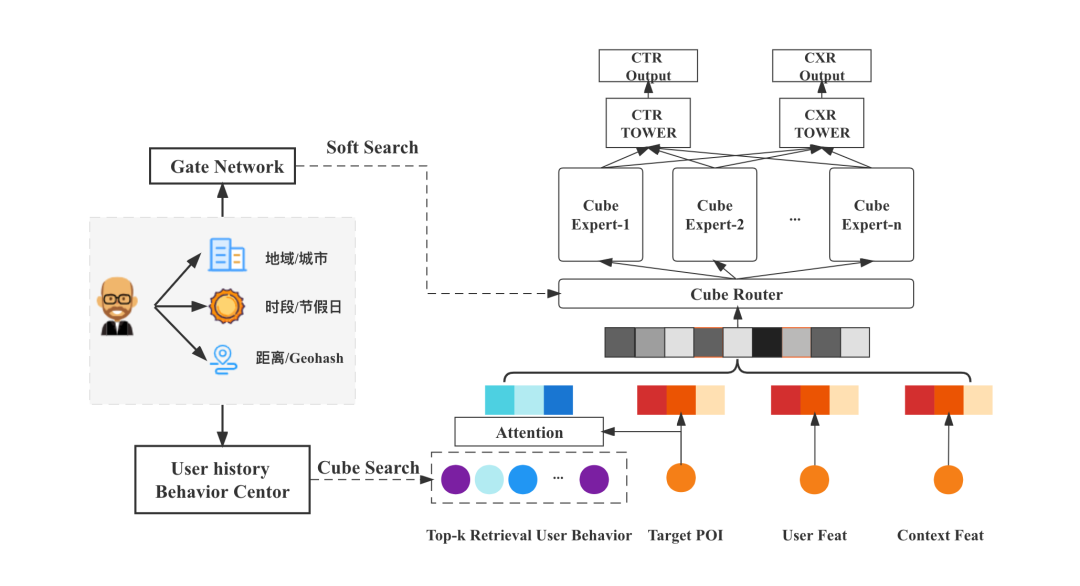
该模型通过 Cube 检索出特定细分情境下的用户行为进行序列建模,并且通过专家网络模型自动化对不同情境参数进行学习,保持了模型统一,既能刻画情境的独特性,也能实现不同情境间的知识共享和迁移。具体的,在用户行为序列建模上,首先仔细考虑了细粒度行为特征对于外卖商家推荐的重要作用,并以此为基础,根据时间、空间场景对用户序列进行长序列多路情境检索;对于专家网络结构,则先针对不同入口情境建立基于 Attention 机制的多入口情境建模,随后探索了情境化稠密 MMOE 和稀疏 MMOE 模型,发现在外卖场景中,专家网络可以学习到不同情境、不同任务的差别,进而提升模型精度。
基于该方案,对于 CTR、CXR(CTCVR)任务,模型在离线指标 AUC、GAUC(perSessionAUC)上均取得了显著提升,并在线上也取得了 UV_RPM、UV_CXR、PV_CTR、曝光新颖性、首购订单占比等指标收益。线上指标计算口径如下:
UV_RPM = 实付交易额(GMV)/曝光人数*1000
UV_CXR = 交易用户数/曝光人数
PV_CTR = 点击次数/曝光次数
曝光新颖性 = (A -(A∩B))/ A,该用户当前 session 内曝光的商家集合为 A,该用户 7 天内所有 session 中曝光过的商家集合为 B
首购订单占比 = 商家新用户的订单数/总订单数
3.1 情境化长序列检索
基于深度学习的方法在 CTR 预估任务中取得了巨大成功。早期,大多数工作使用深度神经网络来捕获来自不同领域的特征之间的交互,以便工程师可以摆脱枯燥的特征工程工作。最近,我们称之为用户兴趣模型的一系列工作,专注于从历史行为中学习潜在用户兴趣的表示,使用不同的神经网络架构,如 CNN、RNN、Transformer 和 Capsule 等。DIN1强调用户兴趣是多样的,并引入了注意力机制来捕捉用户对不同目标商品的不同兴趣。DIEN2指出,历史行为之间的时间关系对于建模用户的兴趣漂移很重要,并设计了一个带有辅助损失的 GRU 兴趣提取层。
但是,对于美团外卖,基于以上连续建模的方法,难以从用户历史行为中提取出与用户的当次访问情境高度相关的有效信息。MIMN3表明在用户兴趣模型中考虑长期历史行为序列可以显着提高模型的性能。但是较长的用户行为序列包含大量噪声,同时极大地增加了在线服务系统的延迟和存储负担。针对上述问题,SIM4提出把行为中的重要相关信息搜索出来。具体来说,在拿到需要被预估的商品信息后,可以像信息检索一样,对用户行为商品构建一个快速查询的索引。待预估商品的信息可以当做是一个 Query,从用户的所有行为中,查询与其相关的行为子序列。
因此,受启发于 MIMN 的超长序列和 SIM 的检索思路,我们设计出情境化序列检索方法,依据 Cube 内的情境,从用户超长的历史行为序列中检索出的与当次访问情境最相关性的用户行为,进而捕获更为精准的用户兴趣。
3.1.1 细粒度行为特征
不同于电商中的商品推荐形式,美团外卖推荐是以商家为主体,用户从进入商家到最终下单过程中具有更加丰富的细粒度行为,通过捕捉用户在商家中的细粒度行为,可以精细感知到用户差异化偏好,如注重品质商家的用户会更多查看商家/商品描述和评论,而折扣敏感度高的用户则会查看折扣信息、领取优惠券等。
工业实践中,用户行为序列特征往往包含商家/商品 ID、品类、价格等商家/商品表示特征,而在行为表示上除了用户到商家的点击之外,用户通过什么页面进入到商家点菜页、用户在商家点菜页中的细粒度行为,同样可以反映用户的偏好。因此,可以对用户从浏览商家到最终下单整个流程进行归纳分析,捕捉用户最细腻的行为并纳入模型,充分学习用户在外卖场景中重要的、最细粒度的行为及其所代表的意图偏好。
我们将用户从浏览商家到成单商品的全流程抽取出 70 种不同的 Micro-Behavior,总结归纳出四大步骤:定位商家、考察商家、挑选商品、结算提单。在归纳不同意图的 Micro-Behavior 时,综合考虑了该意图下 Micro-Behavior 的日均 PV、当日转化率、行为跳转路径以及页面展示信息,并剔除了日均 PV 覆盖率小于 1%的 Micro-Behavior,将相同意图的行为聚合到一起作为特征表示(比如评价 Tab 点击、评价标签点击和用户评价缩略图点击聚合成“查看评论”意图表示),最终抽象出 12 种不同意图的 Micro-Behavior,用来捕捉用户更深层次、更细粒度的兴趣。基于用户 Micro-Behavior 提炼出从进入商家到最终下单流程如下图 4 所示:
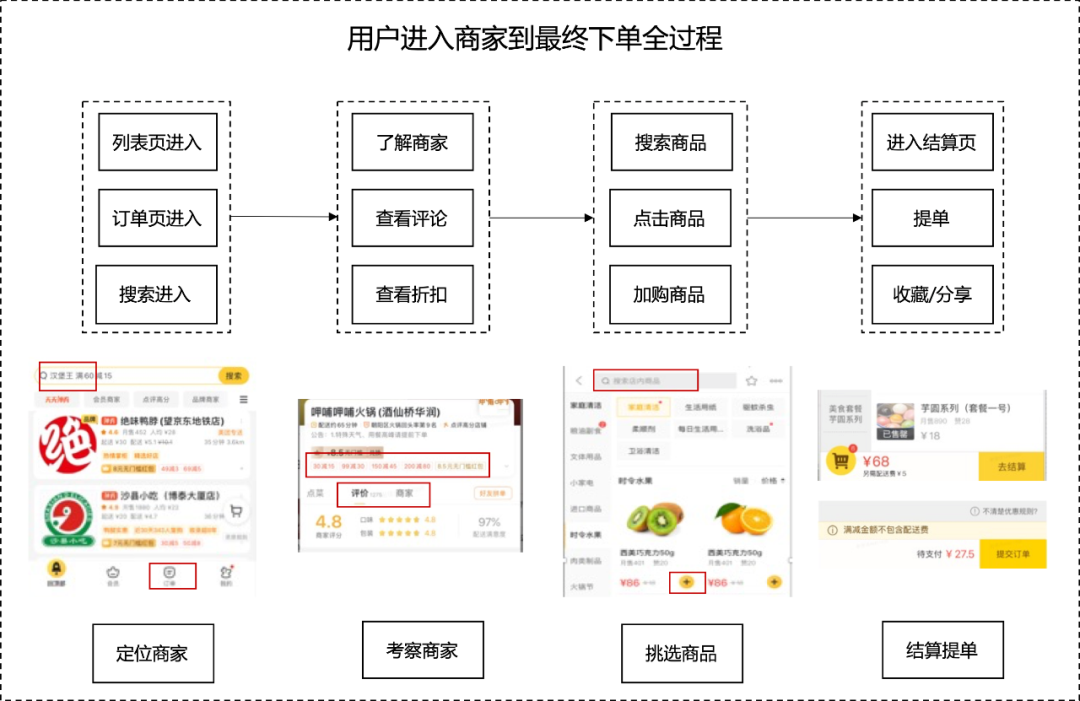
接下来,我们详细介绍下图 4 中用户点外卖过程的 4 类 12 种 Micro-Behavior。
定位商家是指用户进入商家的入口标识,它可以反映出用户对该商家感兴趣的原因;比如从搜索结果页进入代表用户是有较强的购买意愿,相比推荐结果页进店用户有更加清晰的意图。
考察商家的行为则包括点击了解商家详情、查看商品评论和查看商家折扣,它可以帮助更好的理解用户的关注点,学生群体可能更注重折扣,而家庭用户可能更加关注商家质量。
挑选商品意味着用户对商家的满意度达标了,其中,点击商品和加购商品能够体现出用户对商家不同的感兴趣程度。
结算提单则表示该商家能满足用户当前状况下的需求,既包含了对商家的认可,也包含对商家中商品的满意,收藏与分享更是表示出用户对商家的高度欣赏。
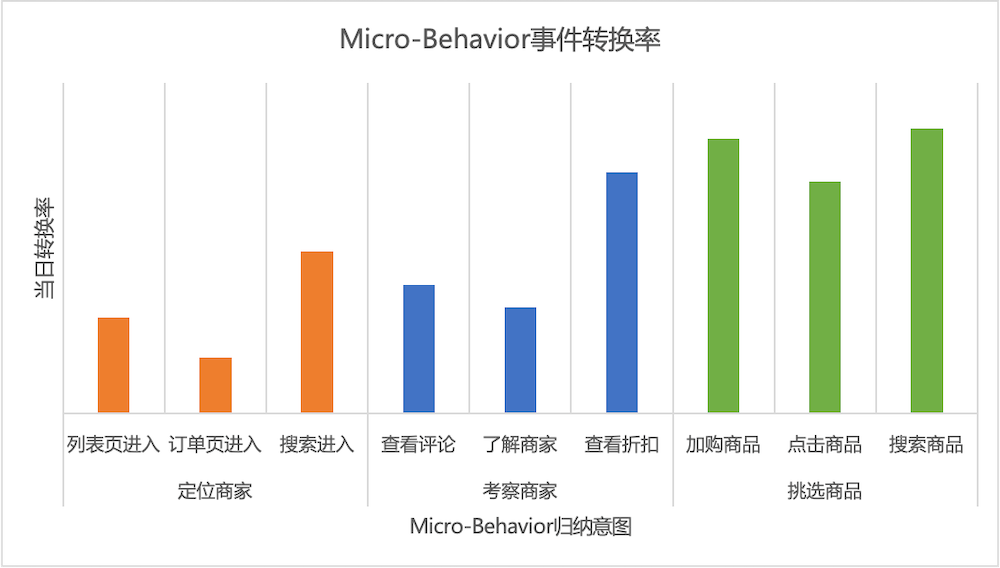
如下图 5 左所示,9 种不同意图的 Micro-Behavior 的当日转化率存在着明显差异(当日转化定义:用户在商家发生某一 Micro-Behavior 后的自然日内有成单;结算提单意图下 3 种行为由于转化率很高,因此不做展示)。
分别在用户实时(短周期行为)、历史(长周期行为)商家序列中引入 Micro-Behavior 信息。如下表所示,离线实验数据表明,引入的 Micro-Behavior 信息取得了比较明显的提升。最终,细粒度行为特征在线取得了 UV_RPM+1.77%,PV_CTR+1.05%的收益。

离在线实验效果表明引入 Micro-Behavior 信息增加了模型的精准推荐能力。此外,我们进一步对模型是否正确的学习了细粒度行为进行验证。随机选取一个用户的成单商家及其商家序列引入 Micro-Behavior 后 Attention 权重变化,如下图 6 所示,图左上部分表示用户行为序列中的商家以及相应 Micro-Behavior 信息,图右上部分是序列中商家引入 Micro-Behavior 信息后所对应的 Attention 权重可视化,方块颜色越深则表示 Attention 权重越大,图下部分是用户的最终成单商家“鸿鹄一品跷脚牛肉”在引入不同 Micro-Behavior 信息后的商家排名。通过对比序列中商家引入 Micro-Behavior 观察 Attention 权重的变化:
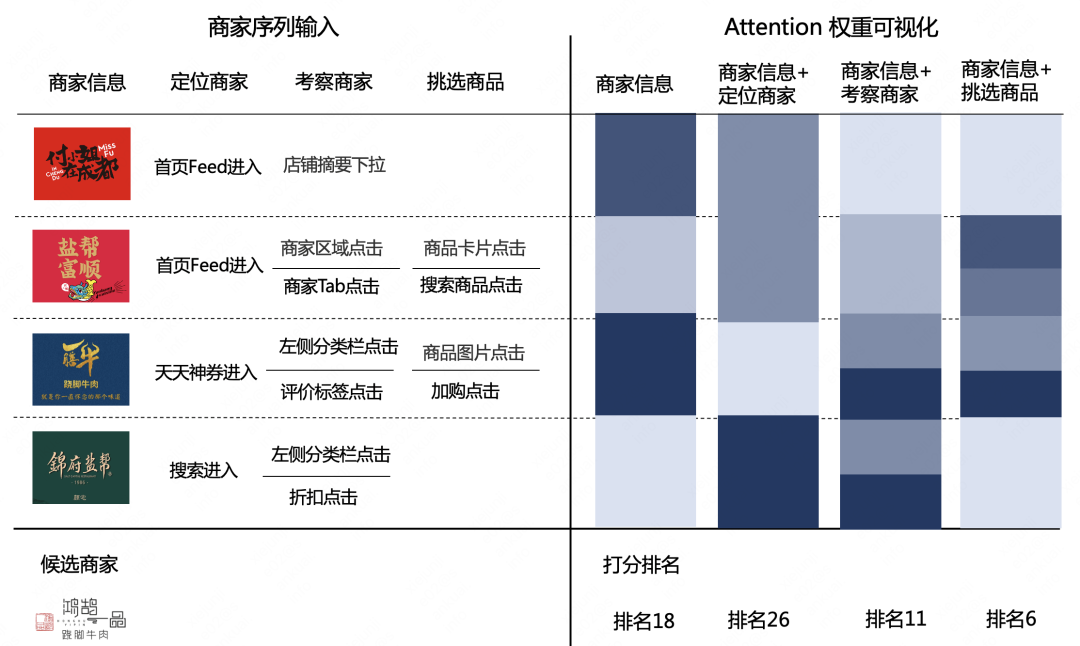
商家序列输入只有第一列商家信息时,Attention 权重主要由商家 ID、商家 Tag、商家名等信息决定,“一膳牛跷脚牛肉”和“鸿鹄一品跷脚牛肉”商家名、商家 Tag 都较为相似因而权重最大。
商家序列输入在商家信息基础上分别增加定位商家、考察商家、挑选商品的丰富行为后,根据右侧相应每个 Micro-Behavior 的 Attention 权重大小可以看到,定位商家这列中搜索进入商家权重最大,而列表页进入(首页 Feed 进入)权重相对较小,符合业务认知;考察商家这列行为中,查看折扣(折扣点击)和查看评论(评论标签点击)表示用户在筛选商家,其 Attention 权重远大于了解商家(店铺摘要下拉)等泛意图点击;挑选商品中的加购点击(加购商品)、搜索商品(搜索商品点击)行为能展现出用户的成单意图,由于该部分信息的丰富,候选商家排名提升至第 6 位。
从以上过程中可以看到,引入 Micro-Behavior 的信息越完善,模型对于用户兴趣的理解越是充分,用户最终成单的商家也是能够得以排名靠前。
3.1.2 长序列多路情境检索
美团外卖上线至今,已经积累了丰富的用户行为数据。将如此丰富的行为信息引入到模型中,是近期工业界和学术界的热门方向,我们在该方向上也进行了一系列探索。
最初,我们直接将近三年的点击行为直接引入到模型中来,发现离线效果提升显著,但是带来的训练和推理的压力不可承受。在此基础上,借鉴了 SIM4,将候选商家的品类 ID 当作 Query,先从用户的行为序列中检索出相同品类的商家,再进行兴趣建模,离线取得了不错的收益。
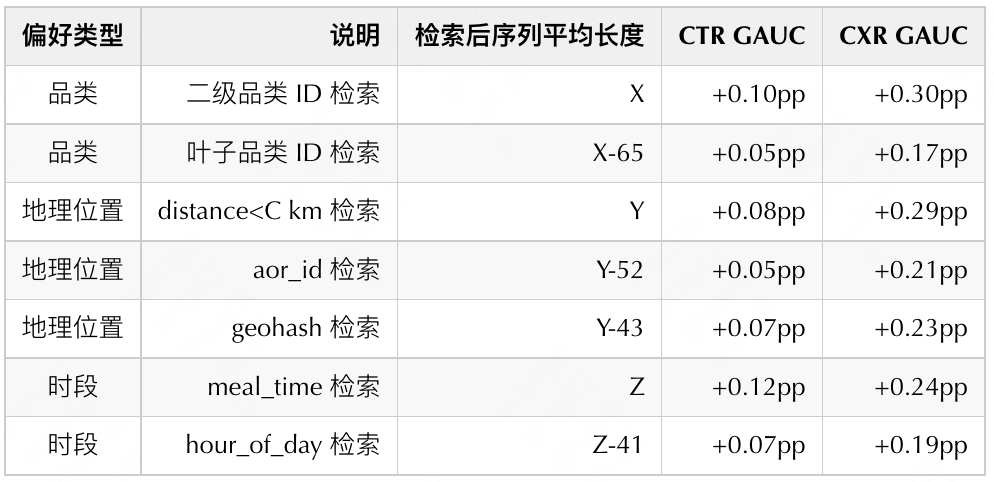
具体的,尝试过使用二级品类和叶子品类来分别做检索,在检索后根据分位点进行最大长度截断的情况下,二级品类检索出来的序列平均长度大约为 X,而叶子品类因为品类划分过细,检索出来的序列平均长度大幅减少。根据离线实验评估,最终选择了使用二级品类进行检索,在离线取得了 CXR GAUC+0.30pp 的效果。对于检索条件中,像二级品类和叶子品类这种泛化性与精确性之间的 trade off,我们目前正在进行更进一步的探索。
为了进一步提升模型的效果,考虑到用户兴趣建模从 DIN 发展到 SIM,都是根据候选商家、商品的属性,从用户的行为历史中提取对该候选商家、商品的兴趣,这在传统电商场景下是行的通的,因为用户对某一商家、商品的兴趣基本不会随着他所处位置、所处时段改变(用户要买手机壳,不会因为他在家还是在公司有改变,也不会因为他的购物时段是在早上还是晚上而改变)。但是餐饮外卖相较于传统电商,正如前面的问题与挑战中提到的,其鲜明的 LBS 和餐饮文化特色构成多种多样的情境,用户在不同的情境下对于不同的商家、商品的偏好是不一样的,是会变化的。因此,除了建模品类偏好外,还要进一步建模用户的地理位置偏好和时段偏好。
对于地理位置偏好的建模,尝试了使用用户当前所处地理位置的 geohash(一种地理位置编码,详见维基百科)/aor_id(蜂窝 ID)作为 Query 来检索用户历史行为中相同 geohash/aor_id 的商家,也根据业务经验,直接从用户的历史行为中将到用户当前请求位置的距离小于 C 公里的商家全部检索出来,检索后序列的平均长度如下表所示,根据离线实验评估,最终选择 distance<C km 检索来建模用户的地理位置偏好。公里数 C 这个参数是根据业务经验统计得到的超参,考虑到不同的用户对于距离的容忍度可能是不一样的,如何对不同的用户在不同的情境下对该超参进行调整,还在积极探索中。
对于时段偏好的建模尝试了两种检索方式:从用户的历史行为中,将与当前请求的 meal_time(根据业务将一天划分为早餐、午餐、下午茶、晚餐和夜宵)或 hour_of_day(行为小时时段)相同的商家检索出来。meal_time 划分的粒度更粗,检索出来的商家更多,从下表中也可以看到其离线结果更好,成为了建模时段偏好的最终选择。很明显,meal_time 检索和 hour_of_day 检索也存在泛化性与精确性之间的 trade off 问题。
最后,我们将二级品类 ID 检索序列(品类偏好)、distance<C km 检索序列(地理位置偏好)以及 meal_time 检索序列(时段偏好)全部加入到模型中,并根据各自的平均长度等信息对不同子序列分别进行了不同的最大长度调整,模型结构如下图 7 所示:
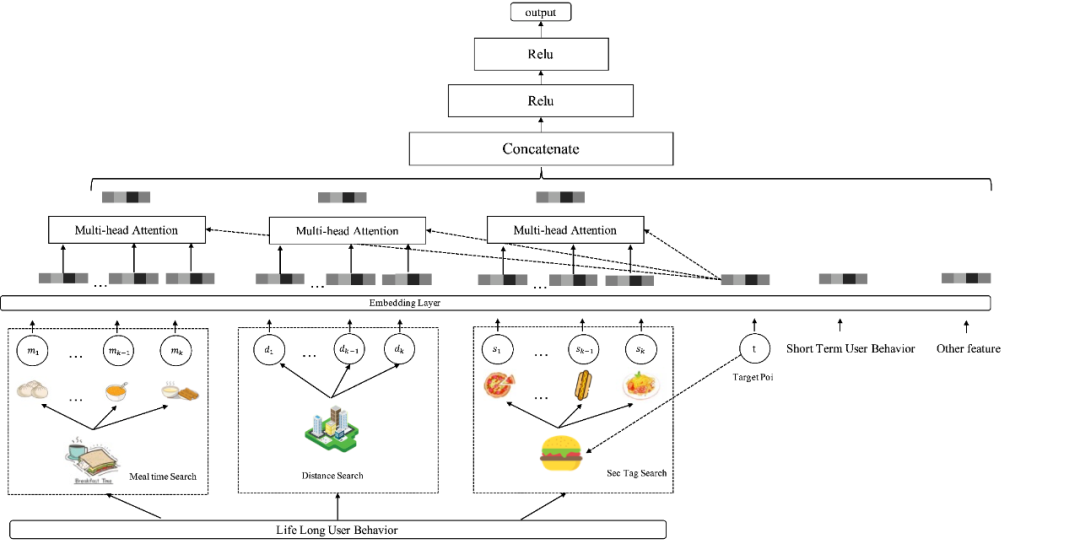
最终,在离线取得了 CTR GAUC+0.30pp,CXR GAUC+0.52pp 的收益,在线上取得了 UV_CXR+0.87%,UV_RPM+0.70%,PV_CTR+0.70%,首购订单占比+1.29%的收益。可以注意到上述长序列的引入,不仅带来了效率的提升,还带来了新颖性的提升,分析发现通过建模用户更长期的兴趣,扩展了模型的视野,不再集中于用户的短期兴趣,能更好地满足用户口味“短聚集,长多样”的特性。
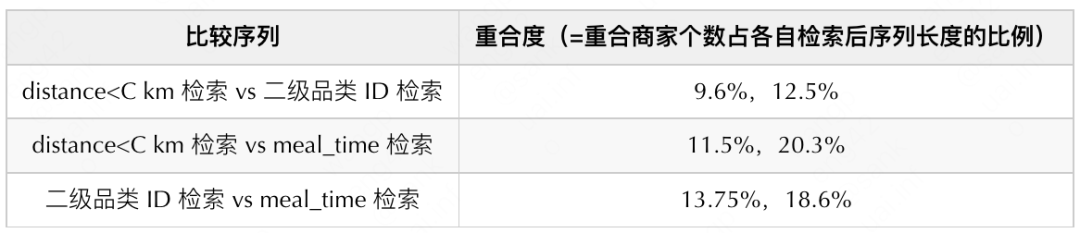
在后续的数据探查中,基于样本维度统计了二级品类 ID 检索序列、meal_time 检索序列和 distance<C km 检索序列的重合度情况。从下表可以看到,三者各自检索出的商家重合度确实非常的低,符合建模不同偏好的预期,也解释了为何三个序列叠加后,效果还是有增长的原因。
然而,当前三路检索合并的版本,虽然可以对用户的品类偏好、地理位置偏好和时段偏好进行有效的建模,但还是存在两个比较明显的缺陷。首先,各路检索序列中还是存在冗余信息,并且需要分别建模三个序列,带来的性能压力较大。其次,将情境割裂成一个个单独的维度进行建模,无法建模他们之间的联系,更真实准确的情况应该是对用户所处情境的不同维度进行统一建模。针对这两个问题,我们正在情境 Cube 的概念下,开展通过一个序列统一建模用户所处情境偏好的探索工作。
下文继续介绍长序列工程优化实践。长序列模型会为线上服务带来一系列工程挑战,序列长度变长极大增加了服务时数据传输成本与模型推理成本,需要针对这两个方面做专门优化。
数据传输优化:重复检索信息压缩。以 tag_id 检索为例,由于方案中采用的是较为粗的品类划分,tag_id 本身数量是非常有限,一次请求 batch 内候选商家所对应的 tag_id 具有非常多的重复。基于以上分析,在同一请求内检索时,只保留不重复的 tag_id 子序列特征,最终将整体传输数据压缩为之前的 1/7 左右,优化效果十分明显。
模型推理优化:
1)Embedding 从内存转移到 GPU 显存存储。在模型计算模块,会根据模型输入特征在 CPU 哈希表中查询 Embedding,查询优化的核心是解决 CPU 哈希表查询效率低的问题,查询效率低主要是哈希冲突多,查询线程少造成的。为从根本上解决以上问题,我们将 CPU 哈希表升级为 GPU 哈希表,将模型 Embedding 从内存转移到 GPU 显存存储,并直接在 GPU 上进行查询操作。GPU 哈希表做了数据重排等优化,大量降低了哈希冲突时的数据探测次数,且利用 GPU 提供的更多线程,在发生哈希冲突时能够做到更快查询。压测表明,通过以上优化,可以利用更短的时间处理更多的查询,查询问题得到有效解决。
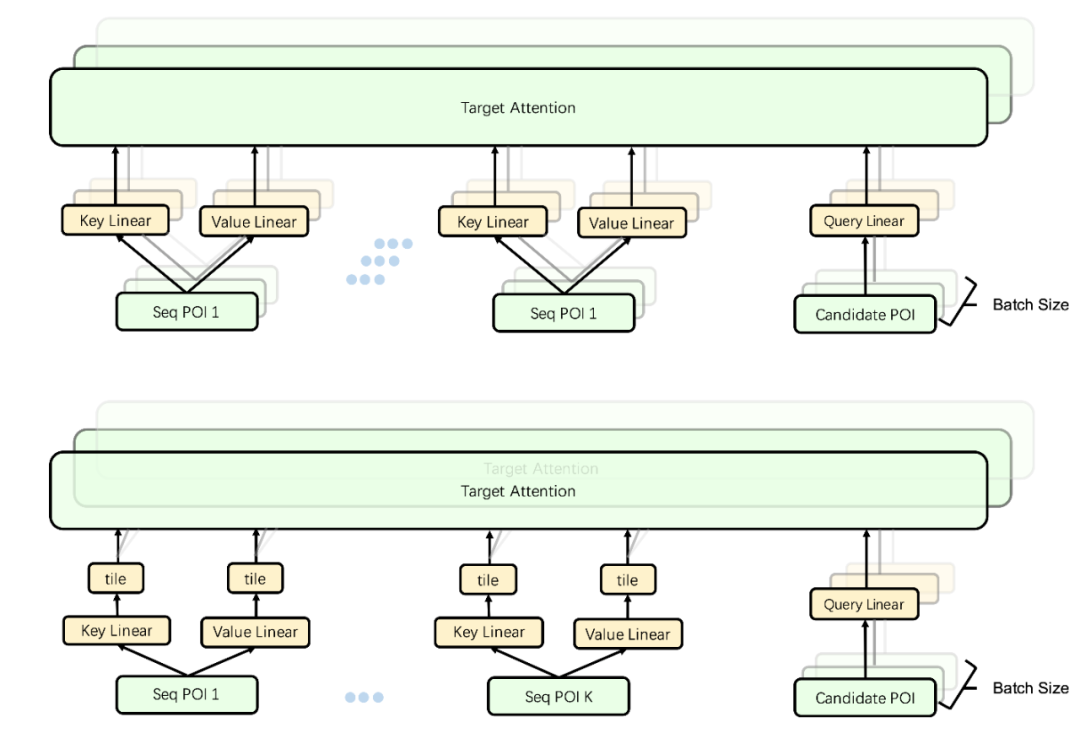
2)用户序列计算图折叠。长序列模块的加入,给线上计算带来了巨大压力,因此考虑对线上计算图进行优化。由于一次请求中,在 Batch 内部,用户部分序列输入都是一致的,原始计算图对用户序列做投影时,会产生大量重复冗余计算。基于这一点,我们在请求模型服务时将用户侧序列的 id 查询模块以及投影计算在计算图中进行折叠,如图 8 所示,把用户侧特征 batch size 先缩小至 1,只计算一次,然后与候选商家计算 attention 时再进行展开,通过计算图折叠,极大减小了线上序列部分带来的巨大计算开销。
3.2 情境化多专家网络
大部分工业界的 CTR 预估模型遵循传统 Embedding&MLP 范式,将用户兴趣向量、商家/商品表征和其他特征作为输入,通过朴素的多层神经网络学习特征、样本、标签之间的关系。另有学术界一些熟知的工作如 PNN5、DeepFM6、xDeepFM7、DCN8等方法,都在努力建模特征间共现关系、特征的特异性、特征的层次结构关系、样本之间的关系等信息,并且在公开数据集和部分特定工业场景下取得显著效果。而在 NLP 领域,2018 年 10 月,Google 发布 BERT9模型,刷新了 11 个 NLP 任务的最好水平,由此开启了 NLP“大炼模型”时代,引爆了业界的研究热潮。
专家混合(Mixture of Experts, MOE)模型被证明是通往容量更大、性能更强大的机器学习模型的有效途径。MOE 是基于分而治之的原则建立的,其中问题空间在几个神经网络专家之间划分,由门控网络进行监督。在 MOE 基础上,MMOE10提出一种新颖的多任务学习方法,在所有任务中共享专家子模型,使 MOE 结构适应多任务学习,在 Google 的大规模内容推荐系统取得显著收益。
受启发于 MOE,我们首先探索不同入口下的多专家网络模型,然后利用 MMOE 将入口情境拓展到城市、时段等多种复杂情景中去,让各个专家专注于学习细分情境下的数据分布,学习不同情境下用户兴趣,最后探索稀疏化 MMOE 建模,在保持推理性能不变的前提下进一步提升模型效果。采用情境化多专家网络还可能导致情境多维叉乘造成 Expert 海量的问题,对于这一位问题,在某些具有明确差异的情境,比如入口,我们会采用一个 Expert 对应一个入口的方案,对于不特别明确的复杂情境,例如时间交叉地点等,我们会采用固定数量 Expert 对海量 Expert 降维,然后利用 Gate 网络做自动化学习。
3.2.1 多入口情境建模
美团外卖涵盖多个推荐入口,包括首页 Feed(主要流量入口),以及美食“金刚”、甜点“金刚”、夜宵“金刚”、下午茶等子频道。对于不同入口情境建模存在以下挑战:
各个推荐入口在流量大小、用户行为丰富程度、商家曝光量存在明显差异,多个小入口的数据量不足首页 Feed 的 10%,导致样本积累量有限,难以使用这些数据训练出高精度的模型。
用户在各个入口下的行为存在互斥关系。例如,用户不会在同一时刻在不同频道同时下单,因此简单地将每个入口看作一个任务作为学习目标的传统多任务建模范式,难以取得较好的模型精度。
为满足用户的体验,不同频道会有相应的品类规则、时段规则、以及特殊的业务扶持规则,这使得各频道推荐入口间有不同程度的差异与共性。不同推荐入口在用户与商家两方面存在交集的同时,在用户行为、商家分布等方面也存在不小差异,比如首页 Feed 会包含全部商家品类,甜点饮品主要包含奶茶、咖啡、甜点等品类商家。因此,模型如何建模出各频道间的共性与差异性,同时动态地建模各个频道间的关系变得尤为重要。
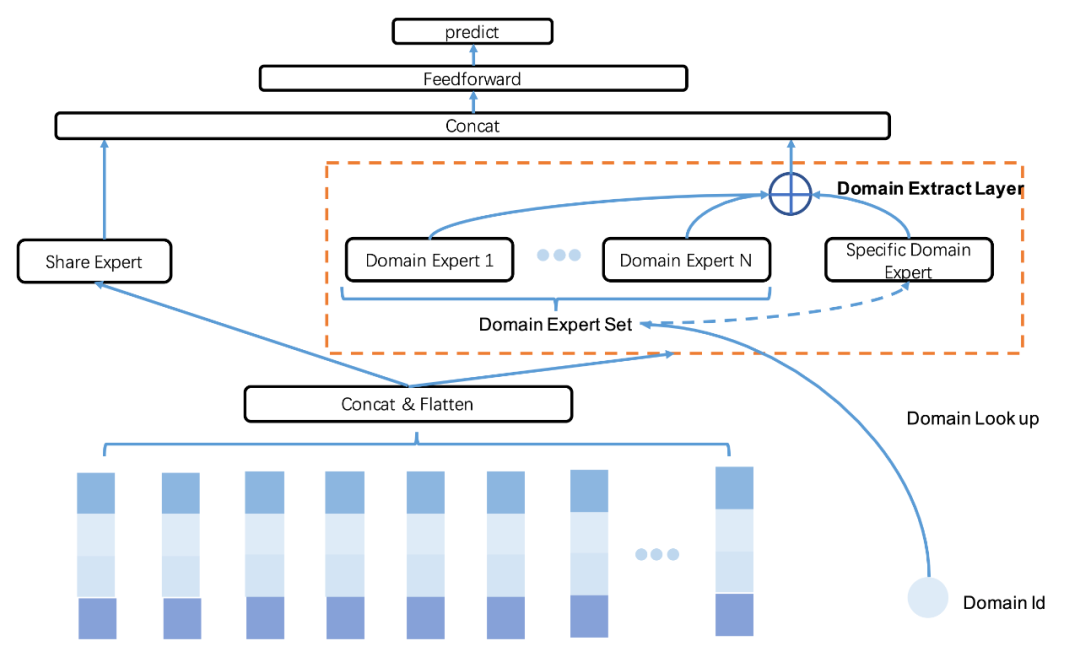
我们通过实现多入口统一建模(AutoAdapt)解决以上挑战。具体的,设计了如图 9 所示的多入口情境专家模型,在模型结构的特征 Embedding 和多任务 Tower 之间构建了 Share Expert 学习全部入口的信息,该 Expert 将始终处于激活状态;为了捕捉多入口之间的区别与联系,构建了 Domain Extract 模块,为每个入口设置一个由 MLP 组成的专家网络(Expert)。
为了使每个入口对应的 Expert 可以充分建模私有的表达,在模型训练和推理时,对于入口 i 的样本或请求,根据入口 ID 激活其对应 Expert Di,该 Expert 产生的输出将 Xi 将直接输入到任务对应的 Tower 当中。
对于一个入口的样本或请求,在保证该入口的 Expert 一定会被激活的情况下,以一定概率去激活其它入口的 Expert,并对这些 Expert 的输出做 Pooling 抽取,从而有效地利用到其它入口的知识。很显然,入口间的相似程度、同一样本对不同入口知识的依赖程度都是不同的,为此增加了一个 Query-Key Attention 模块去做动态概率激活。如图 9 中 Domain Extract 模块所示,对入口 i 的样本或请求,将其自身的 Expert 的输出 Xi 作为 Query,而将其在其它入口 Expert 的输出作为 Key,Query 和 Key 间的相似性 Attention 得分即为对应 Expert 的激活概率,使用经过 Softmax 归一化后的激活概率对各个 Expert 的输出做加权聚合得到表征 Xagg,该表征也将输入给预估任务对应的 Tower。
离线实验上,我们采用全入口数据混合训练+入口 ID 特征的模型作为基线,尝试了 Multi-Task(为各个入口分别设置一个预估任务)、MMOE、STAR11等方法。由于用户在外卖各入口的消费行为存在互斥关系,且小入口的行为样本较为稀疏,因此直接采用多任务的方式效果较差,而引入 MMOE 会有一定的提升。与此同时,对比阿里的 STAR,该方法中各个入口拥有自己的独立网络参数,但未能捕获各个入口间的关系,在外卖推荐场景中提升有限。相比之下,AutoAdapt 在主入口和小的入口上都实现了较大的提升。
为了对 Attention 产生的激活权重做可视化分析,具体的,我们在评估集上中对 Attention 的结果根据不同入口 Query 做分组统计求平均,如下图 10 所示,纵轴代表作为 Query 的入口、横轴代表作为 Key 的入口,图中每个点的值代表某一入口对作为 Query-Key 情况下 Attention score 的平均值。例如,第二行代表着美食金刚(D1)作为 Query 时,对其它入口 Expert 的平均激活概率,发现模型可以学习到符合认知的入口相似关系,例如,当下午茶样本(D7)作为 Query 时,它和甜点饮品(D2)Expert 的平均激活概率为 0.3,明显高于对其它入口的激活概率,另外美食金刚(D1)和正餐频道(D5)同样有着很高的相关性。
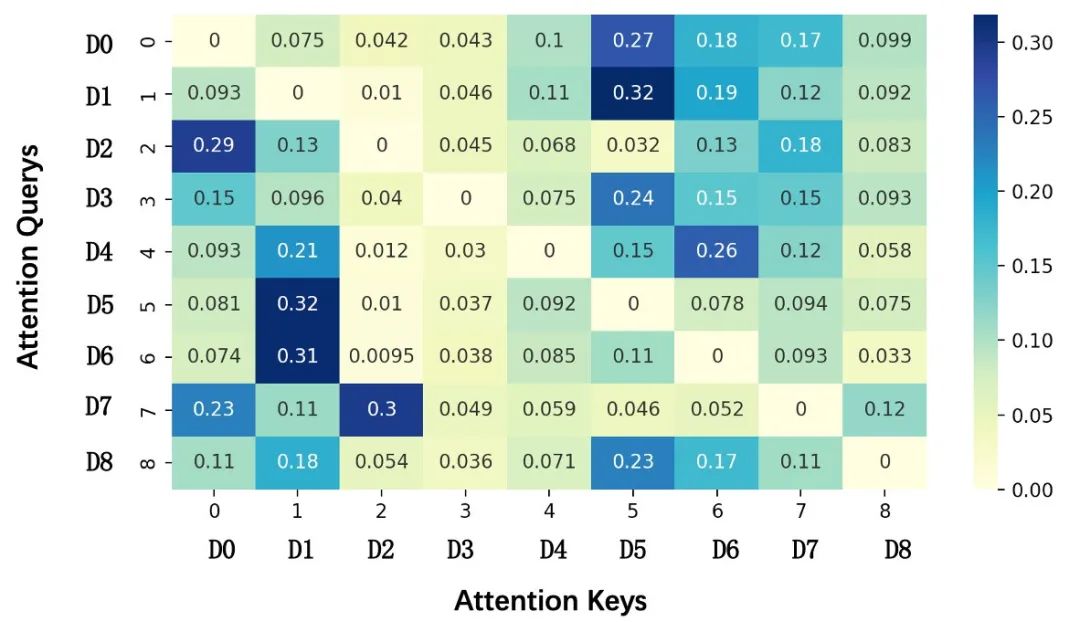
图10 不同入口 Attention 权重热力图
该解决方案不仅实现了首页 Feed、美食“金刚”、甜点饮品等流量入口间模型的统一,同时也为各个入口带来了显著的离线指标收益和线上指标的增长。经过联合建模,小入口可以有效利用到首页 Feed 的丰富信息,使得线上和离线效果提升显著,此外,对于首页 Feed,该方案同样有显著的效果提升,不同场景线上收益如下表所示:

3.2.2 情境化稠密 MMOE
专家网络是情境化建模的主要手段之一,模型可以根据不同情境自动选择需要激活的参数参与推理达到整体更高的精度水平。我们发现在 Share-Bottom CTR/CXR 多目标结构基础上,引入 MMOE 结构可以带来显著的离线 CTR/CXR AUC 收益(如下表所示),可以发现当 Experts 数量达到 64 时,CTR GAUC 和 CXR GAUC 分别有 0.3pp 与 0.4pp 左右的提升。
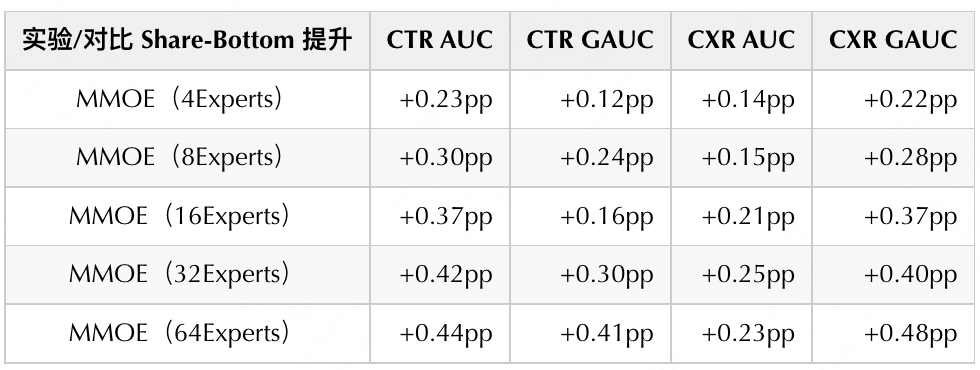
引入大数量级 Experts 的 MMOE 结构可带来较显著的离线收益,但同时也会相应带来离线训练以及线上服务成本的增加,需要做效果与效率之间的权衡。我们在保持一定离线训练时长与在线 Latency 约束下,选择了 4Experts MMOE 版本作为新的基线模型,并做详细的探索,进行较为细致的优化,包括:
引入残差连接:受 Switch Transformer12启发,引入 embedding layer 与 Experts 输出层之间的残差连接,用来缓解梯度消失,离线 CXR GAUC+0.1pp。
MMOE 的 Gate 优化:尝试在 MMOE 的 Gate 的 embedding layer 中只输入时段、城市等强情境特征(即基于情境来为每个任务选择 Expert),并在实验中发现相较于在 Gate 中使用所有特征,这种只用场景强相关特征来构建 Gate 的方式反而会取得一定离线 GAUC 提升,离线 CXR GAUC+0.1pp。
非线形激活:多项 NLP 工作如 B Zoph13、Chen14等指出,采用非线形激活可以进一步提升大规模模型效果,我们利用 Gelu 替换 leaky relu 激活函数,离线 CXR GAUC+0.11pp。
最终,情境化稠密 MMOE 在线取得了 UV_RPM+0.75%,PV_CTR+0.89%,曝光新颖性+1.51%的收益。
3.2.3 情境化稀疏 MMOE
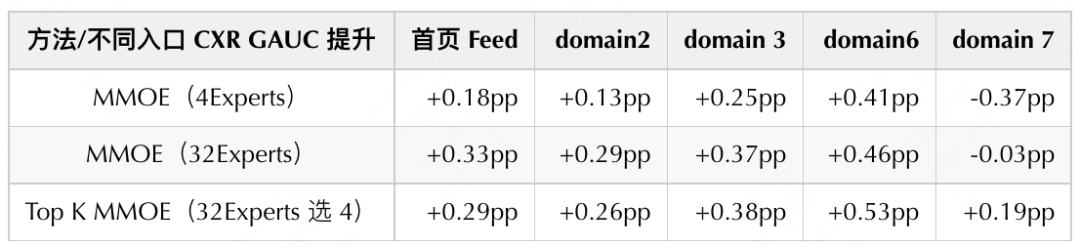
在探索得到稠密 MMOE 最优版本之后,我们开始对稀疏 MMOE 模型进行探索。借鉴 Google 提出的 Sparse Expert Model,如 Switch Transformer 等,我们采用 Top K MMOE 方法进行尝试。其核心思想在于,每条样本根据 Gate 的计算结果,从所有 N 个 Experts 的输出中只选取 K 个(K<<N)进行后续计算。下表实验结果表明,采用 32Experts 对比 4Experts 在不同入口离线指标均有明显提升,同时 Top K MMOE(32Experts 选 4)与 FLOPs 相同 MMOE 4Experts 相比在不同入口都具有明显的优势,效果接近 MMOE 32experts。
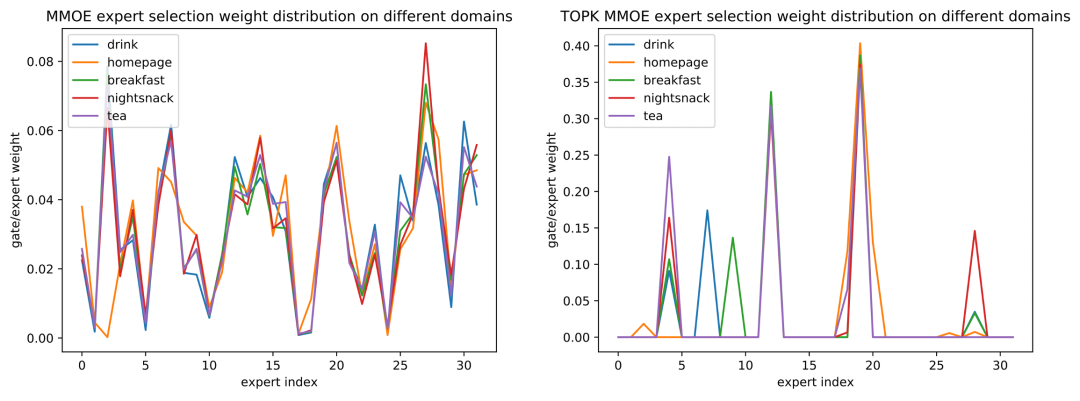
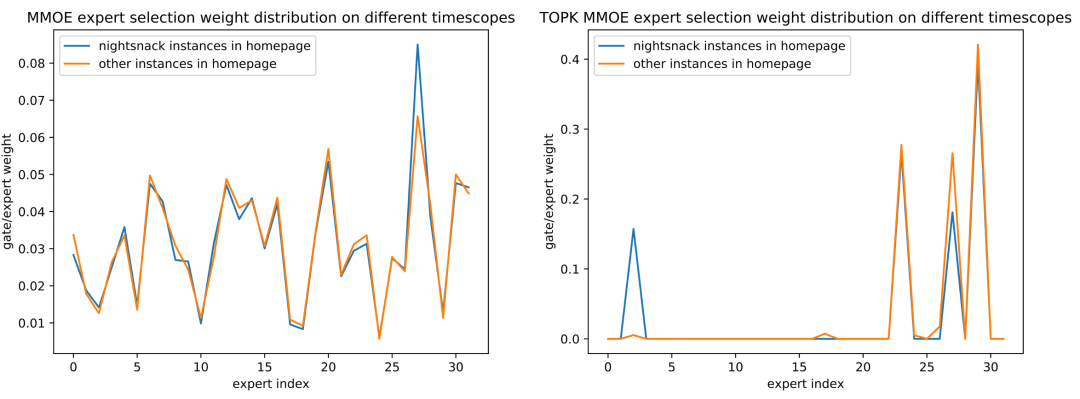
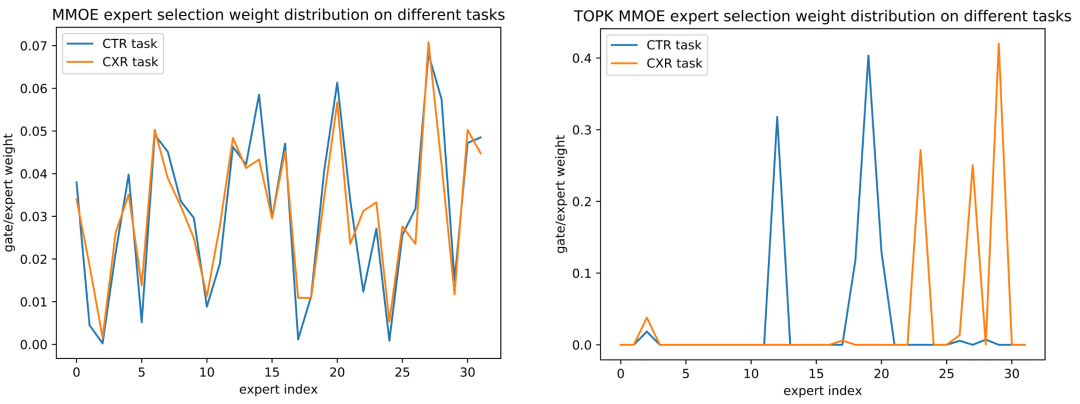
继续分析稀疏 MMOE 是否能学到各个切片下的共性与差异性,对 MMOE 和 Top K MMOE 的 CTR 任务在各个 domain 上的 Expert Gate 分布进行可视化。可以发现,稀疏 Top-K 方法相比稠密方法,更能学到根据不同入口、不同时段、不同任务来选择不同的 Expert 进行 serving。例如,针对不同的时段情境,图 11 中下午茶入口与早餐入口的分布明显不同、图 12 中首页入口的夜宵时段与非夜宵时段的分布明显不同;针对模型中不同的任务目标,如图 13 中 CTR/CXR 任务的分布也明显不同,这些都与实际中的业务认知相符,表明稀疏 MMOE 中不同专家学习到了不同情境、不同任务之间的差异性。
4. 总结和展望
得益于 Cube 概念,我们可以持续探索更多情境,以及优化该情境下的冷启动问题。例如用户处于异地时,可以通过比较情景 Cube 的相似性,找到近似情景下有较成熟行为的用户,并将其兴趣偏好及其行为迁移过来(实现中为每个情景建立一个活跃用户池),达到缓解冷启动阶段用户体验差的问题。
此外,在情境化长序列检索中,往往存在单路检索信息较少,整体检索线上性能差的问题,我们考虑探索新的多属性检索机制将多路检索合并为单路检索,在提高检索速度的同时扩充检索信息的丰富程度来进一步提升模型效果;在稀疏专家网络上,我们发现推荐模型存在严重的参数饱和现象:当稠密参数增加到一定程度时,模型效果提升会快速衰减。因此,通过简单扩充专家数量来提升效果是不可取的,在未来将考虑结合 AutoML、交叉网络等手段提高参数利用效率,寻求在推荐场景落地稀疏专家网络的工业级解决方案。
5. 本文作者
瑞东、俊洁、乐然、覃禹、秀峰、王超、张鹏、尹斌、北海等,均来自到家事业群/到家研发平台/搜索推荐技术部。
6. 参考文献
[1] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction. SIGKDD 2018.
[2] Zhou G, Mou N, Fan Y, et al. Deep interest evolution network for click-through rate prediction. AAAI 2019.
[3] Pi Q, Bian W, Zhou G, et al. Practice on long sequential user behavior modeling for click-through rate prediction. SIGKDD 2019.
[4] Pi Q, Zhou G, Zhang Y, et al. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. CIKM 2020.
[5] Qu Y, Cai H, Ren K, et al. Product-based neural networks for user response prediction. ICDM 2016.
[6] Guo H, Tang R, Ye Y, et al. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv:1703.04247, 2017.
[7] Jianxun Lian, et al. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. KDD 2018.
[8] Wang R, Shivanna R, Cheng D, et al. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. WWW 2021.
[9] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805, 2018.
[10] Ma J, Zhao Z, Yi X, et al. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-experts. KDD 2018.
[11] Sheng X R, Zhao L, Zhou G, et al. One model to serve all: Star topology adaptive recommender for multi-domain ctr prediction. CIKM 2021.
[12] Fedus W, Zoph B, Shazeer N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv:2101.03961, 2021.
[13] Zoph B, Bello I, Kumar S, et al. Designing effective sparse expert models. arXiv 2202.08906, 2022.
[14] Chen Z, Deng H Wu Y, Gu Q. Towards Understanding Mixture of Experts in Deep Learning. arXiv:2208.02813, 2022.
[15] Zhou M, Ding Z, Tang J, et al. Micro behaviors: A new perspective in e-commerce recommender systems. WSDM 2018.
[16] Zou X, Hu Z, Zhao Y, et al. Automatic Expert Selection for Multi-Scenario and Multi-Task Search. SIGIR 2022.
[17] Bai T, Xiao Y, Wu B, et al. A Contrastive Sharing Model for Multi-Task Recommendation. WWW 2022
---------- END ----------
招聘信息
搜索推荐算法工程师
岗位职责
发展大规模深度学习、图学习等技术,利用注意力机制、记忆网络、关系网络等模块,从跨多个时空场景的海量数据中理解用户需求、发掘用户兴趣,优化点击率、转化率模型,为用户展示更合适、更感兴趣的美食和商品;
发展强化学习、可解释深度学习、多模态学习、多目标优化等技术,优化重排、混排模型,智能调控流量分发,优化平台生态,实现消费者和商家共赢;
使用知识图谱、计算视觉、自然语言生成等技术,面向用户兴趣,帮助商家自动化智能生成展示内容和文案,提升推广效率;
追踪并研究人工智能前沿技术,探索技术在零售、医疗电商场景的应用。
感兴趣的同学可以将简历发送至:libeihai02@meituan.com。
也许你还想看
| 美团外卖搜索基于Elasticsearch的优化实践
| TensorFlow在美团外卖推荐场景的GPU训练优化实践
| GPU在外卖场景精排模型预估中的应用实践
前端 | 算法 | 后端 | 数据
安全 | Android | iOS | 运维 | 测试