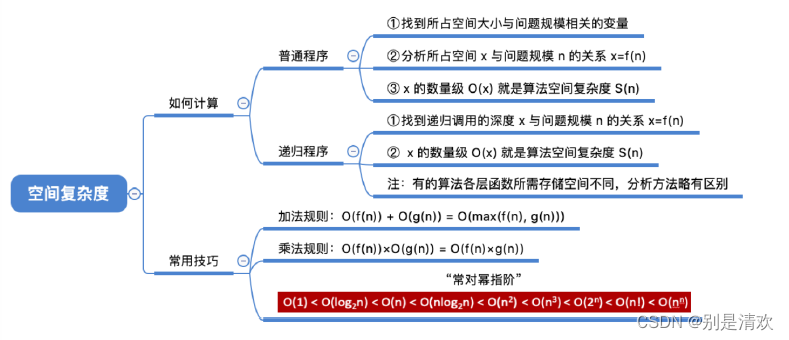
二战时期,英国数学家、计算机科学之父Alan Turing在布莱切利庄园成功破译了德军密码,为赢得世界反法西斯战争的胜利做出了重大贡献。为了表达对前辈先贤的敬意,本微实践取名为“布莱切利庄园的秘密”。
本文引用自作者编写的下述图书; 本文允许以个人学习、教学等目的引用、讲授或转载,但需要注明原作者"海洋饼干叔
叔";本文不允许以纸质及电子出版为目的进行抄摘或改编。
1.《Python编程基础及应用》,陈波,刘慧君,高等教育出版社。免费授课视频 Python编程基础及应用
2.《Python编程基础及应用实验教程》, 陈波,熊心志,张全和,刘慧君,赵恒军,高等教育出版社Python编程基础及应用实验教程
3. 《简明C及C++语言教程》,陈波,待出版书稿。免费授课视频
在人类尚未获得足够的算力之前,加密和解密都是手工进行的。受限于有限的人工算力,加解密只能采取一些简单的方法,比如下面这种:

信息的发送方和接收方同时持有如上表所示的明密文字母对照表,该对照表对任何第三方保密。加密时,按照该对照表,将明文中的a映射为f,b映射为v,…,z映射为t,即得密文。解密时,同样按照该对照表,将密文中的f映射为a,v映射为b,…,t映射为z,即得明文。
在随书代码的CH6子目录下,文件article.txt包含了示例中的“明文”,其内容引自一本著名的英文小说:
A few days later, Tom invites Nick to a party in New York City. On the way, Tom picks up his ...
通过执行CH6子目录下的encode.py,可以将明文article.txt按前述加密方法加密成密文,文件名为encoded.txt:
f izg dfho efuzj, ulq sansuzo asrw ul f bfjuh sa azg hljw rsuh. la uyz gfh, ulq bsrwo cb yso ...
看起来,即便密文被第三方截获,也难以解读,实则不然。在正常的英文表达中,每个字母出现的频率是有差异的,比如e的出现频次通常最高的,而z、x、q则相较较低。这提供了一种解密思路:对密文中的字母出现频率进行统计,其中出现次数最高者极可能是e,次高者可能是t,最低者则可能是z、x或者q。
应用上述解密思路,我们设计了下述解密程序:
#decode.py
f = open("encoded.txt") #打开并读取密文内容至s
s = f.read().lower()
f.close()
stats = {} #对密文中的字母出现次数进行统计
for c in s:
if c.isalpha():
stats[c.lower()] = stats.get(c.lower(),0) + 1
stats = list(stats.items()) #将字典转换为列表,对字母按出现次数降序排序
stats.sort(key=lambda x:x[1],reverse=True)
stats = "".join([x[0] for x in stats])
print("密文统计的按频次降序排列的英文字母:", stats)
codes = "etansoirhldygmcubwfkvpjzxq"
print("语料统计的按频次降序排序的英文字母:",codes)
r = "" #进行解密,明文存于r
for c in s:
if c.isalpha():
r += codes[stats.index(c)]
else:
r += c
f = open("decoded.txt","wt") #将明文r写入文件
f.write(r)
f.close()
print("解密完成: decoded.txt")
🚩第2 ~ 4行:打开当前工作路径下的密文文件encoded.txt,将其中的内容按字符串形式读出,保存在变量s中。使用Python进行文件读写的详细方法,我们在第8章中讨论。请读者留意第3行中lower()函数的存在,在整个解密过程中,我们统一使用小写字母。
🚩第6 ~ 9行:借助于字典stats对密文中各字母的出现次数进行统计。统计完成后,stats中将得到形如{“a”:112, “x”:7, … “z”:3}的结果数据。统计过程中,我们使用for循环对密文s中的字符c逐一进行处理,如果字符c是英文字母(使用成员函数isalpha()进行判断),则将其在字典中的出现次数加1。请读者留意get()函数的运用,当某个字母是首次发现时,其在字典中尚不存在,此时,get()函数将返回默认值0。
🚩第11 ~ 14行:通过列表按统计的频次对字母进行降序排序。在字典中,键值对之间没有前后之分,因此排序只能通过列表进行。第11行将字典的键值对转换为列表,其内容形式为:[(“a”,112),( “q”,3),…,(“x”,7)]。第12行使用sort()函数对该列表进行排序,排序时通过匿名函数获取每个元组的下标1值,即频次做为排序依据。第13行使用列表推导语法将有序列表中的字母单独提取出来,并使用空字符串””将所有字母串接在一起。如执行结果的第1行所示,stats字符串的值为zufaolsjyedhpqrcvgiwnbmtkx,这表明在密文中,出现频次最高的是z,然后是u,f,出现频次最低是x。
🚩第16行:字符串codes给出了从正常语料库中统计的字母出现频次的降序排列。
🚩第19 ~ 24行:按照字母频次的统计结果,进行解密。字符串stats给出了密文统计的字母频次降序排列,字符串codes则给出了正常语料统计的字母频次降序排列。粗略地,我们认为,密文字母stats[i]对应的明文字母即为codes[i]。在下述统计结果中,z在密文中出现频次最高,我们认为它对应明文字母e;u在密文中出现频次为第二高,我们认为它对应明文字母t。
密文统计的按频次降序排列的英文字母: zufaolsjyedhpqrcvgiwnbmtkx [stats]
语料统计的按频次降序排序的英文字母: etansoirhldygmcubwfkvpjzxq [codes]
解密过程中,我们使用for循环逐一处理密文s中的字符c。如果字符c是字母(isalpha()),首先通过stats.index©找到它在密文中的频次排位,然后再以该频次排位作为下标,从codes中获得对应的明文字母,并将明文字母附加至明文字符串r。举例,假设c为字母”f”,stats.index©的结果为下标2,对照codes[2],明文字母即为”a”。如代码的第23 ~ 24行所示,对于那些不是字母的密文字符,直接将其附加至明文字符串r。
🚩第26 ~ 28行:将解密所得的明文字符串r写入文件decoded.txt。
使用Visual Studio Code打开解密文件decoded.txt,可见解密结果是正确的:
a few days later, tom invites nick to a party in new york city. on the way, tom picks up his ...
需要说明的是,由于密文较短,其字母频次统计结果不一定能与正常语料统计的字母频次完美对应。此时,按上述方法得到解密结果可能并不十分准确,比如z被错误解读成了q。在多数字母被正确解密的情况下,少数字母的错误对应关系容易通过人工进行校正。
源程序、数据文件下载: 请在浏览器中复制并录入下述地址
源程序、数据文件下载
为了帮助更多的年轻朋友们学好编程,作者在B站上开了两门免费的网课,一门零基础讲Python,一门零基础C和C++一起学,拿走不谢!
简洁的C及C++

Python编程基础及应用

如果你觉得纸质书看起来更顺手,目前Python有两本,C和C++在出版过程中。
Python编程基础及应用
Python编程基础及应用实验教程











![[MMDetection]绘制PR图](https://img-blog.csdnimg.cn/fd60ae5a3b07488180990b93e6550a86.png)