还没写完,别骂了.....遇到啥新东西也会补充进来
1. 损失函数/距离度量
1.1 KL散度
用来衡量分布之间距离
1.1.1 推导过程
如果想要对KL散度有一个比较好的理解,我其实建议看一下,从信息熵的角度入手我认为是一个比较好的切入点 相对熵(KL散度)、JS散度和Wasserstein距离
和
都是概率分布,
一般代表真实分布,
一般代表拟合
的近似分布

利用期望的计算公式就可以得到用期望表示的KL散度
1.1.2 性质
- 非负性:KL散度始终非负,即 KL(P || Q) ≥ 0。
- 零值:当且仅当P和Q相等时,KL散度为0,表示两个分布完全相同。
- 不对称性:KL散度是不对称的,即 KL(P || Q) ≠ KL(Q || P),表示P相对于Q的信息增益和P相对于Q的信息损失不同。
1.1.3 前向和反向KL散度
称为前向KL散度(forward Kullback-Leibler Divergence)
称为反向KL散度(reverse Kullback-Leibler Divergence)
【具体分析】进阶详解KL散度 - 知乎 (zhihu.com)
1.2 JS散度(Jensen–Shannon divergence)
为了解决KL散度不对称的的问题引入了 JS散度
1.2.1 公式
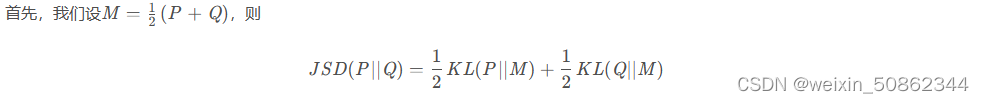
1.2.2 对称性证明
1.2.3 缺陷
当两个分布完全不重叠时,即便两个分布的中心距离有多近,其JS散度都是一个常数,以至于梯度为0,无法更新。
【参考】 GAN:两者分布不重合JS散度为log2的数学证明
1.3 Wasserstein Loss
2. GAN训练三大问题
- 不收敛:模型参数震荡,损失函数不能收敛到理论值;
- 模式崩溃:合成的样本都趋同;
- 梯度消失:判别器太强,生成器的梯度消失,训练无法继续。
生成对抗网络(GAN)的模式崩溃问题
3.1 模式崩溃
GAN本质上就是在对比真实分布和生成器生成的分布。
第一:生成器生成了不真实的样本。对应于那些不真实的样本,Pg(X)>0但Pr(X)≈0,此时KL 散度中间的被积项将会趋于∞;
第二:生成器没能生成真实的样本。对应于没能生成的那些真实样本,pr(x)>0 但 pg(x)≈0,此时 KL 散度中间的被积项将会趋于 0。
GAN 中优化生成器的损失函数要求 KL 散度尽量小。第一种情形损失接近无穷,惩罚巨大,生成器就会避免生成不真实的样本;第二种情形损失接近零,惩罚非常小,因此生成器完全有可能只生成单一的真实样本,而不生成更多不同的真实样本。生成单一的真实样本已经足够欺骗判别器,生成器没有必要冒着失真的风险生成多样化的样本,模式崩溃问题由此产生。
3.模型代码框架
【参考实现】facebookresearch/pytorch_GAN_zoo: A mix of GAN implementations including progressive growing
3.1 损失部分
3.1.1 鉴别器损失

3.1.2 生成器损失

3.1.2 渐进式训练策略
在ProGAN出来之后,很多模型同样也选择了使用渐进式的训练策略。渐进式的训练策略以方便减少了时间,同时也会在一定程度上避免了模式奔溃
4.评估指标
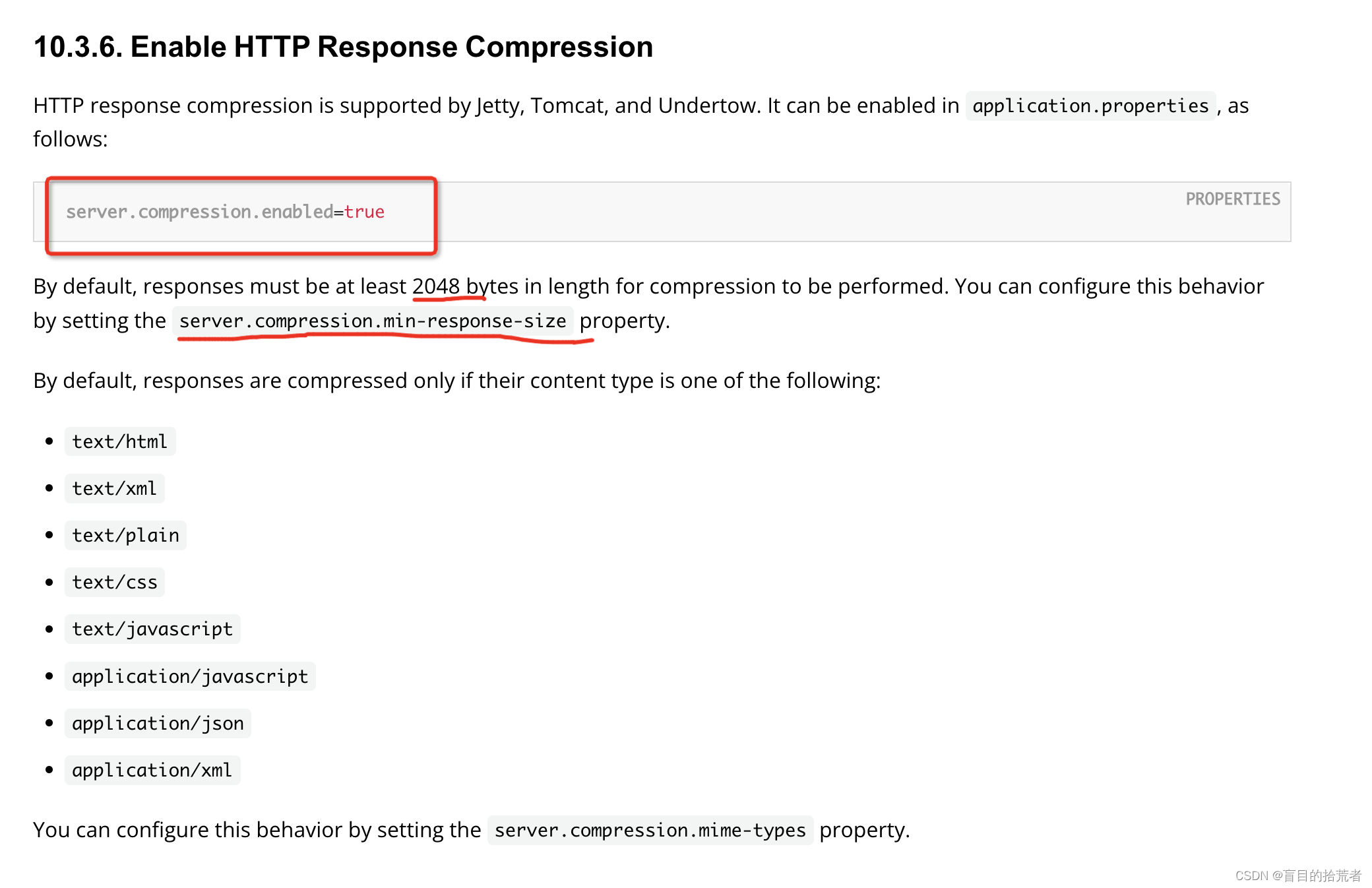
4.1 FID(Frechet Inception Distance score)
Frechet Inception 距离(FID)是评估生成图像质量的度量标准,专门用于评估生成对抗网络的性能。
基本原理:
- 删除模型原本的输出层,将输出层换为最后一个池化层(即全局空间池化层)的激活函数输出值。此输出层有 2,048 维的激活向量,因此,每个图像被预测为 2,048 个激活特征。该向量被称为图像的编码向量或特征向量。
- 然后使用以下公式计算 FID 分数:

- 该分数被记为 d^2,表示它是一个有平方项的距离。
- 「mu_1」和「mu_2」指的是真实图像和生成图像的特征均值(例如,2,048 维的元素向量,其中每个元素都是在图像中观察到的平均特征)。
- C_1 和 C_2 是真实图像的和生成图像的特征向量的协方差矩阵,通常被称为 sigma。
- || mu_1-mu_2 ||^2 代表两个平均向量差的平方和。Tr 指的是被称为「迹」的线性代数运算(即方阵主对角线上的元素之和)。
- sqrt 是方阵的平方根,由两个协方差矩阵之间的乘积给出
【参考】学习GAN模型量化评价,先从掌握FID开始吧