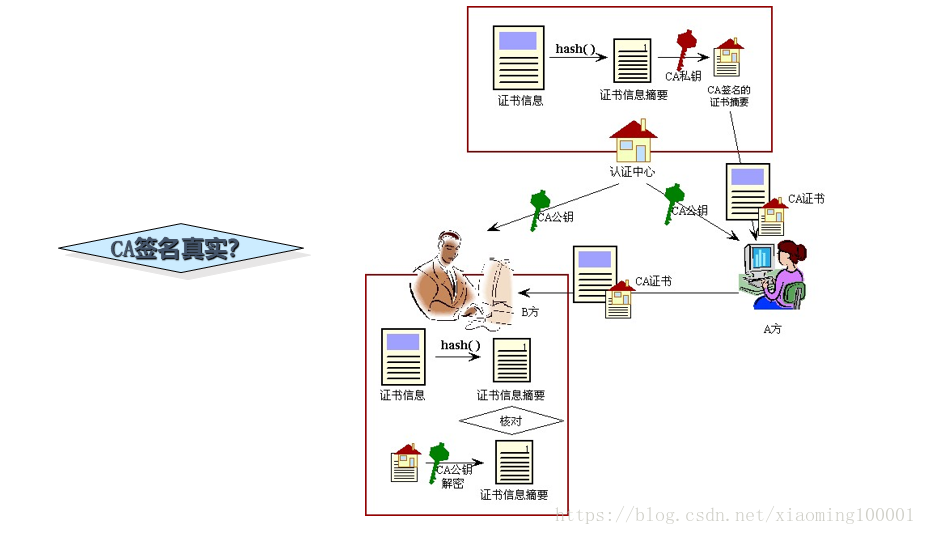
图像卷积
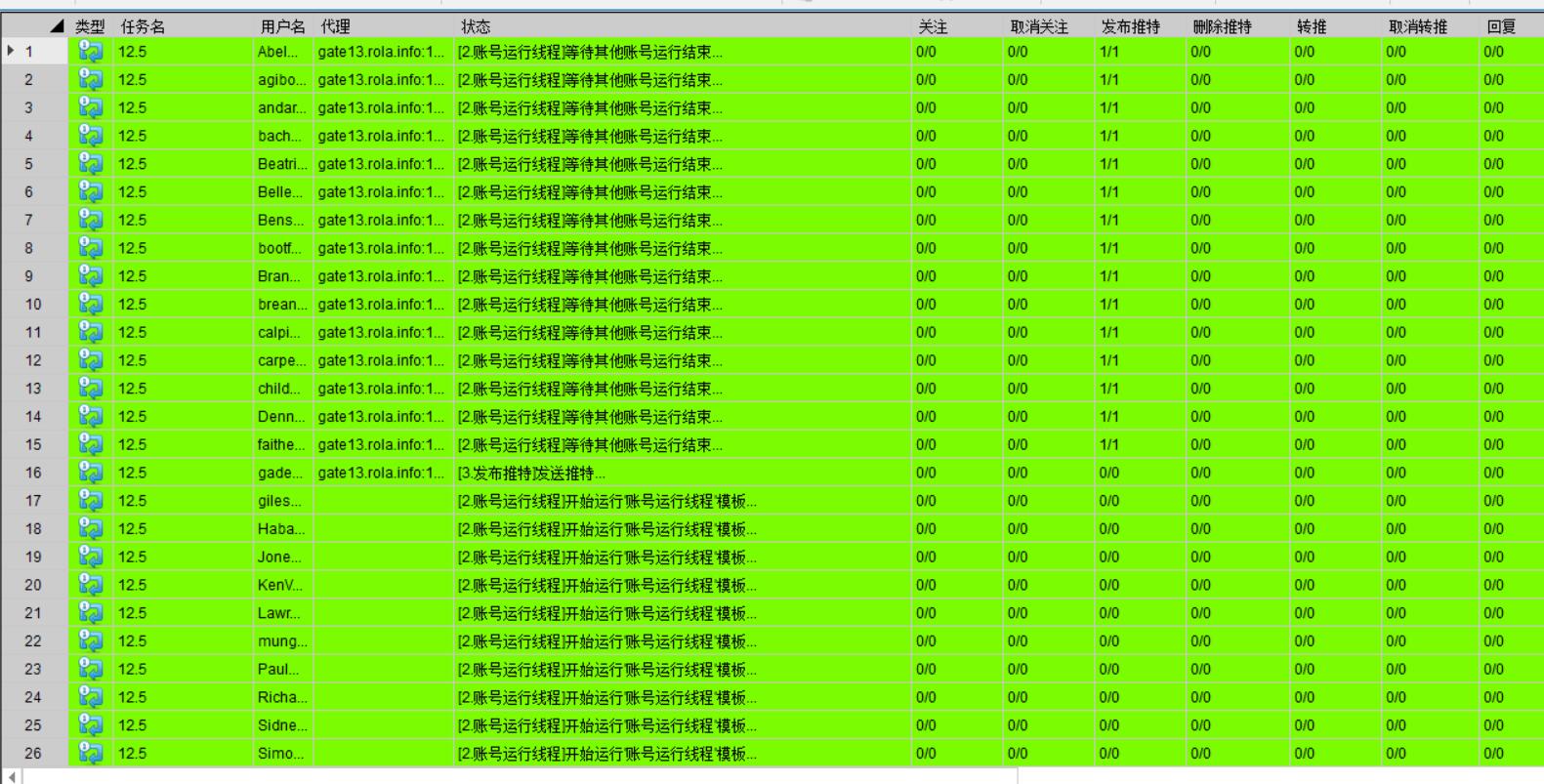
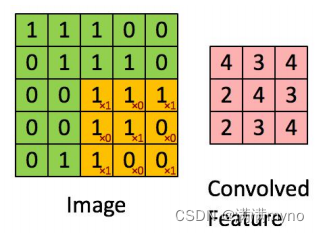
首先给出一个输入输出结果
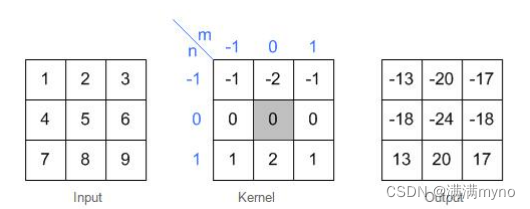
那他是怎样计算的呢?
卷积的时候需要对卷积核进行 180 的旋转,同时卷积核中心与需计算的图像像素对齐,输出结构为中心对齐像素的一个新的像素值,计算例子如下:

这样计算出左上角(即第一行第一列)像素的卷积后像素值。
给出一个更直观的例子,从左到右看,原像素经过卷积由 1 变成-8。
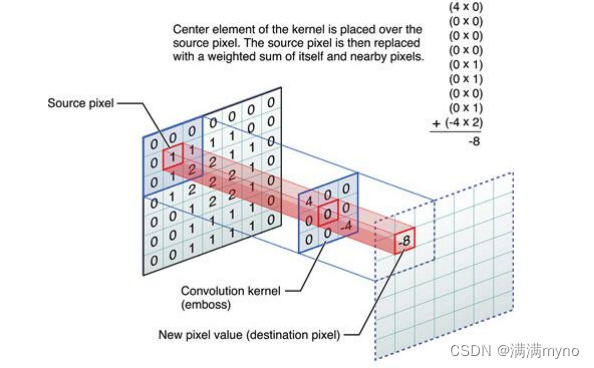
通过滑动卷积核,就可以得到整张图片的卷积结果
图像反卷积
这里提到的反卷积跟
1
维信号处理的反卷积计算是很不一样的,
FCN
作者称为
backwards convolution,有人称
Deconvolution layer is a very unfortunate name and should rather be called a transposed convolutional layer. 我们可以知道,在
CNN
中有
con layer
与
pool layer
,
con layer
进行对图像卷积提取特征,pool layer 对图像缩小一半筛选重要特征,对于经典的图像识别
CNN 网络,如 IMAGENET
,最后输出结果是
1X1X1000
,
1000
是类别种类,
1x1
得到的是。
FCN 作者,或者后来对 end to end
研究的人员,就是对最终
1x1
的结果使用反卷积(事实上
FCN作者最后的输出不是 1X1
,是图片大小的
32
分之一,但不影响反卷积的使用)。
这里图像的反卷积与 full
卷积原理是一样的,使用了这一种反卷积手段使得图像可以变大,FCN 作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现 end to end
。
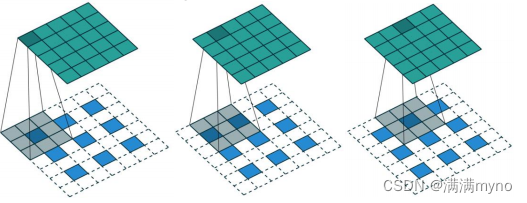
这里说另外一种反卷积做法,假设原图是
3*3
,首先使用上采样让图像变成
7*7
,可以看到图像多了很多空白的像素点。使用一个 3*3
的卷积核对图像进行滑动步长为
1
的
valid
卷积,得到一个5*5
的图像,我们知道的是使用上采样扩大图片,使用反卷积填充图像内容,使得图像内容变得丰富,这也是 CNN
输出
end to end
结果的一种方法。韩国作者
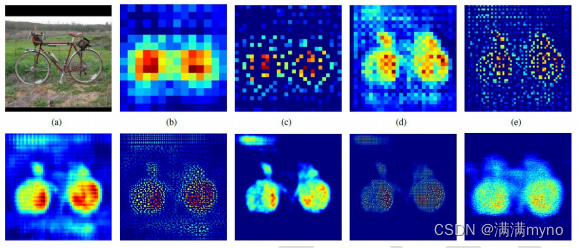
Hyeonwoo Noh 使用 VGG16 层CNN 网络后面加上对称的 16 层反卷积与上采样网络实现 end to end 输出,其不同层上采样与反卷积变化效果如下:
经过上面的解释与推导,对卷积有基本的了解,但是在图像上的 deconvolution 究竟是怎么一回事,可能还是不能够很好的理解,因此这里再对这个过程解释一下。
目前使用得最多的 deconvolution 有 2 种,上文都已经介绍。
方法 1:full 卷积, 完整的卷积可以使得原来的定义域变大。
方法 2:记录 pooling index,然后扩大空间,再用卷积填充。
图像的 deconvolution 过程如下:
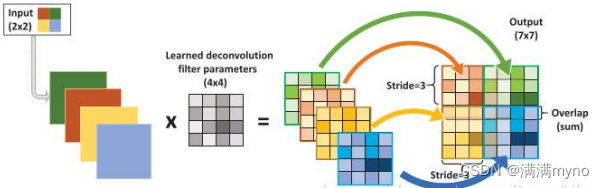
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
即输入为 2x2 的图片经过 4x4 的卷积核进行步长为 3 的反卷积的过程
1. 输入图片每个像素进行一次 full 卷积,根据 full 卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即 4x4 大小的特征图,输入有 4 个像素所以 4 个 4x4 的特征图
2. 将 4 个特征图进行步长为 3 的 fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为 3 是指每隔 3 个像素进行 fusion, 重叠部分进行相加,即输出的第 1 行第 4 列是由红色特阵图的第一行第四列与绿色特征图的第
一行第一列相加得到,其他如此类推。
可以看出翻卷积的大小是由卷积核大小与滑动步长决定, in 是输入大小, k 是卷积核大小, s 是滑动步长, out 是输出大小 得到 out = (in - 1) * s + k
上图过程就是, (2 - 1) * 3 + 4 = 7