文章目录
- 一 环境准备
- 二 需求
- 三 分析
- 1 拿到页面源代码
- 2 提取和解析数据
- 四 步骤流程
- 1 拿到页面源代码
- 2 提取和解析数据
- 五 完整代码
xpath是在XML文档中搜索内容的一门语言
html是xml的一个子集
一 环境准备
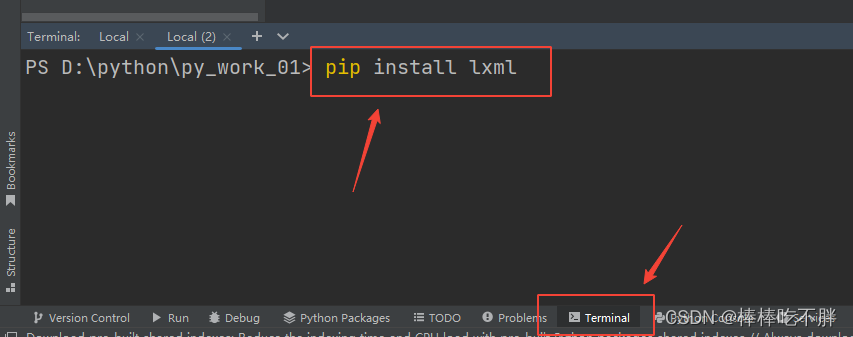
安装lxml模块
二 需求
爬取某网站的数据

三 分析
1 拿到页面源代码
2 提取和解析数据
四 步骤流程
1 拿到页面源代码
通过get请求获取访问页面的源代码,具体分析步骤此处不作重点讲述。
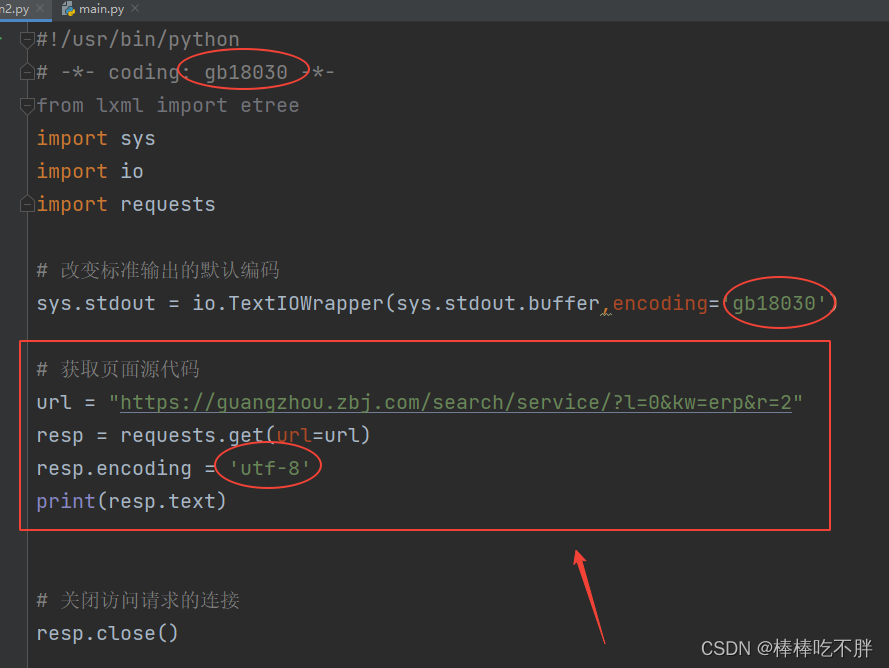
如果不太清楚,可以参考笔者的文章。
python-(6-3-1)爬虫—requests入门(基于get请求)
2 提取和解析数据
由于每一个小方框代表每一个公司所提供商品服务的数据信息,而这些内容都有相同的属性格式,我们只需要遍历每一个“小方框”即可。
接下来我们需要找到能够遍历所有“小方框”的HTML代码。
选中第一个小方框,右键“检查源代码”,定位到表示该小方框的HTML代码层。
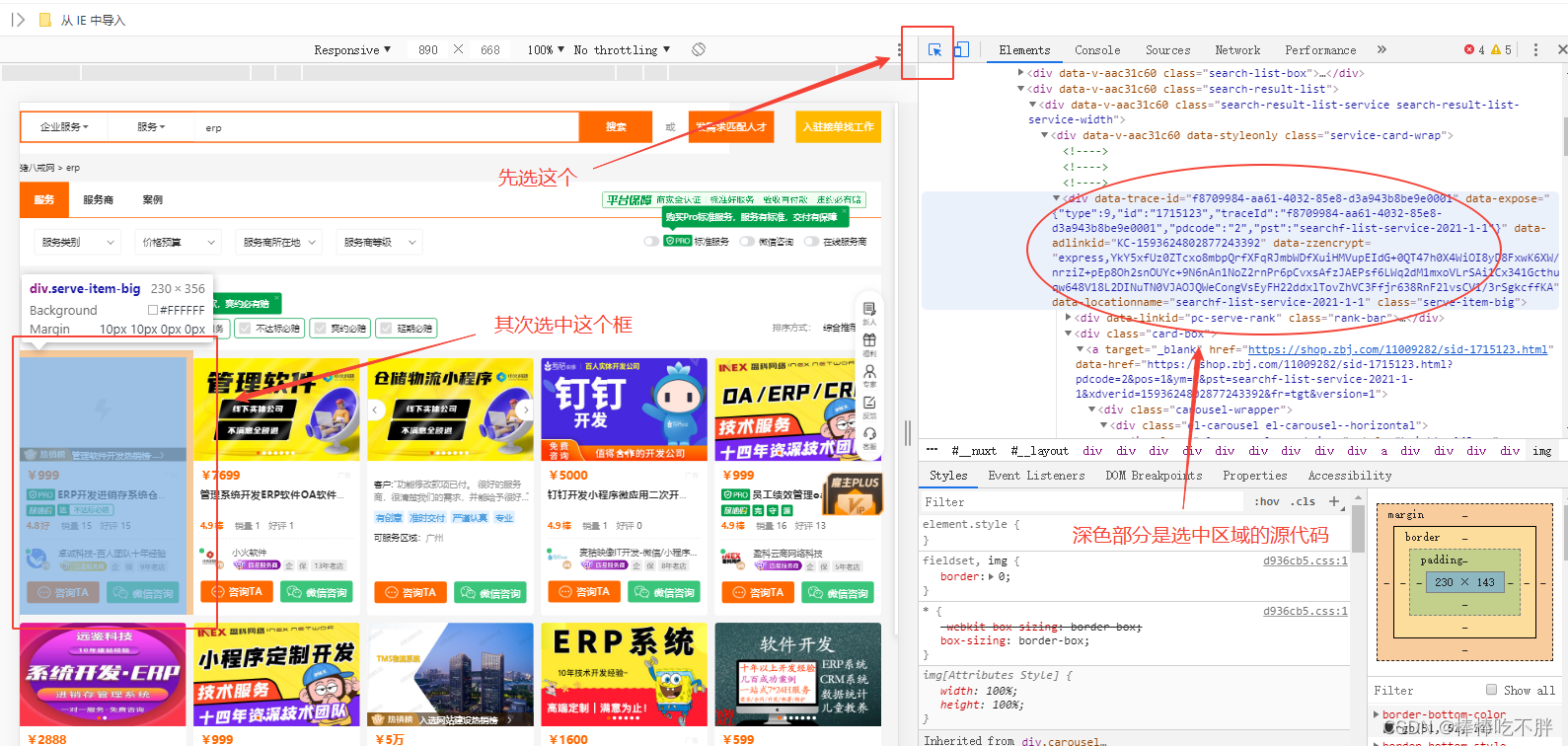
接着我们将代码向上拉,找到能够包含所有小方框的代码。
经过反复的试探和拉扯,确定出哪一行的代码包括所有的小方框。
但是,我们只需要第一个小方框的代码。
选中,然后右键选择xpath
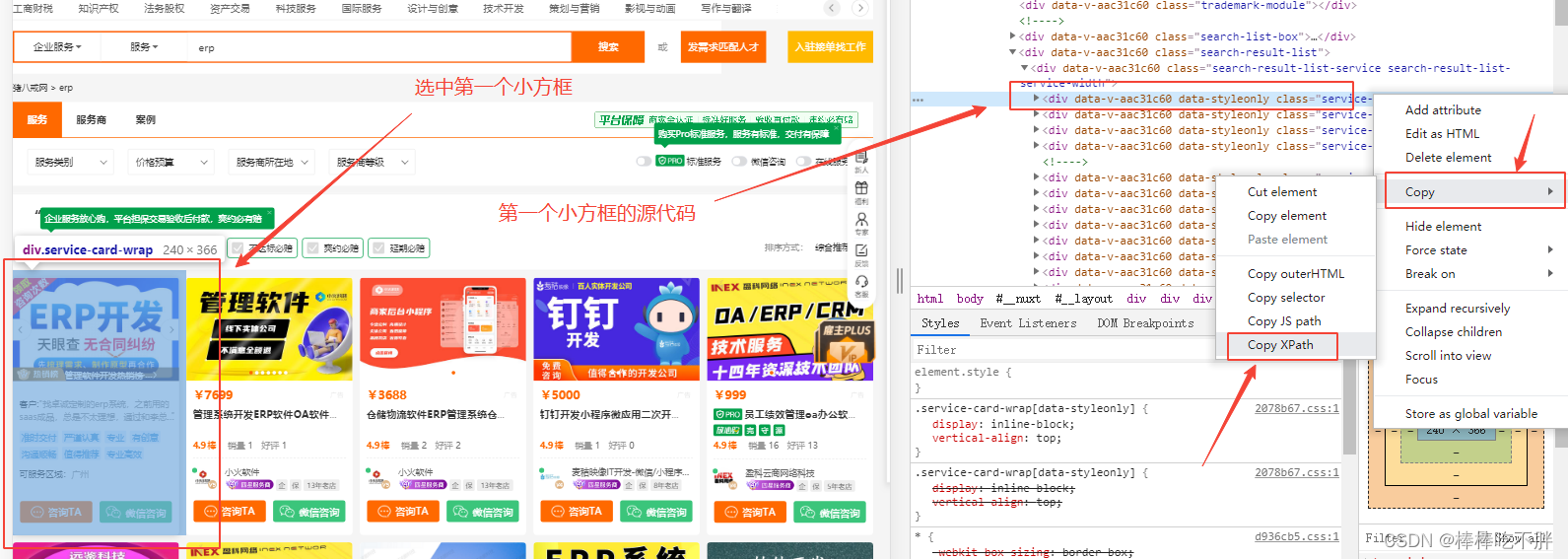
就可以得到第一个服务商的xpath

由于XPATH的特性,我们可以根据第一个小方框的“路径”,得到它的“兄弟”的内容。
也就是去掉后面的索引[1]即可。
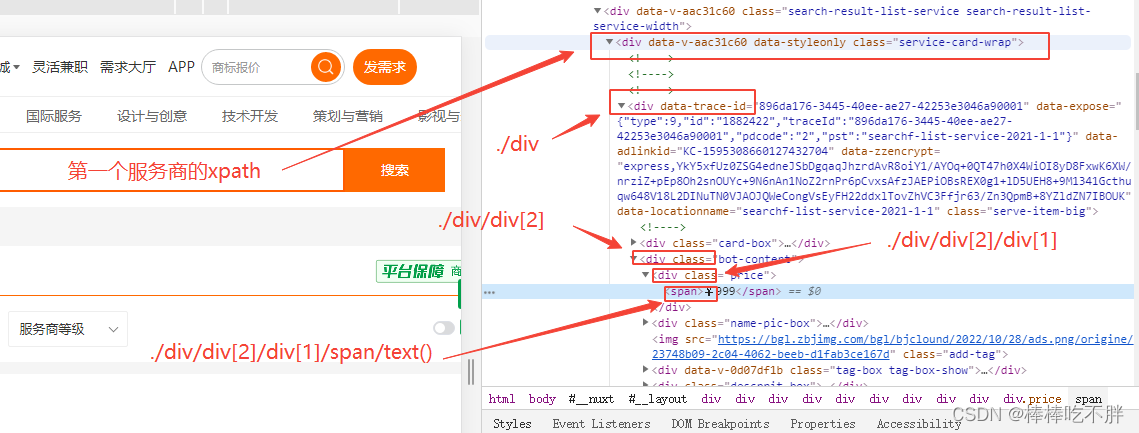
接着从第一个服务商的xpath开始往下数,然后就能得到价格信息。
以此类推,其他服务商的价格信息也是相同的xpath,遍历即可。

同样的道理,我们也可以抓取其他的数据。
比如公司名称,比如服务的标签。
除了我们手动去数xpath,还可以通过 copt xpath 后,比较二者的“绝对路径”,推断出“相对路径”。(如果是学习过Linux的读者,可能会更理解这句话)
五 完整代码
#!/usr/bin/python
# -*- coding: gb18030 -*-
from lxml import etree
import sys
import io
import requests
# 改变标准输出的默认编码
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
# 获取页面源代码
url = "https://guangzhou.zbj.com/search/service/?l=0&kw=erp&r=2"
resp = requests.get(url=url)
resp.encoding = 'utf-8'
# 解析获得的HTML源代码
html = etree.HTML(resp.text)
# 拿到每一个服务商的div
# 第一个服务商的xpath后面是有/div[1]标记,去掉[1]后就是/div所有的服务商的div
divs = html.xpath('//*[@id="__layout"]/div/div[2]/div/div[4]/div[4]/div[1]/div')
for div in divs:
# 得到服务商的价格
price = div.xpath("./div/div[2]/div[1]/span/text()")
# 如果有空值,则过滤掉
if price == []:
continue
# 去掉金额前面的¥符号
price = price[0].strip("¥")
# 得到服务商的公司名
name = div.xpath("./div/a/div[2]/div[1]/div/text()")[0]
# 得到服务商的供应服务描述
label = "erp".join(div.xpath("./div/div[2]/div[2]/a/text()"))
# 得到服务商的支持地点
location = div.xpath("./div/div[1]/a/div[2]/div/span[2]/text()")[-1]
# 输出结果
print(name+"_"+price+"_"+label+"_"+location)
# 关闭访问请求的连接
resp.close()












![[附源码]Python计算机毕业设计Django在线票务系统](https://img-blog.csdnimg.cn/4bdd0694275e4768b4c09a90c690edf5.png)