VoxPoser是一种从大型语言模型(LLMs)中提取机器人操纵的可供性和约束的方法,它不需要额外的训练,并且可以泛化到开放集的指令。
地址:VoxPoser

它利用LLMs的编码能力,与视觉语言模型(VLMs)交互,生成3D值地图,将知识映射到机器人的观察空间。这些值地图可以用于运动规划框架,实现零样本合成闭环机器人轨迹。VoxPoser可以处理多种日常操纵任务,如打开抽屉、拿出面包、测量苹果重量等,只需给出自然语言指令和环境的RGB-D观察。
VoxPoser使用了GPT-3作为大型语言模型,它是一个基于Transformer的自回归模型,可以生成自然语言文本。VoxPoser还使用了CLIP作为视觉语言模型,它是一个基于对比学习的模型,可以将图像和文本映射到同一个语义空间。VoxPoser的主要思想是利用GPT-3的编码能力,生成一段代码,这段代码可以与VLM交互,从而生成一系列3D值地图,反映出给定语言指令的可供性和约束。这些值地图可以用于运动规划框架,实现零样本合成闭环机器人轨迹。具体来说,VoxPoser首先将语言指令作为输入,传递给GPT-3,然后GPT-3根据指令生成一段Python代码,这段代码可以调用VLM的API,从而将图像和文本映射到同一个语义空间。这样,GPT-3就可以利用VLM的视觉理解能力,生成与环境中的物体相关的值地图。
例如,如果指令是“打开抽屉”,那么GPT-3就会生成一段代码,这段代码会调用VLM的API,找到环境中最可能是抽屉的物体,并给它一个高的值,同时给其他物体一个低的值或者一个负的值(表示约束)。这样就形成了一个3D值地图,反映了指令的意图。
VoxPoser是一个创新的方法,它利用了大型语言模型和视觉语言模型的强大能力,实现了机器人操纵任务的零样本学习。它不需要任何额外的训练或者预定义的运动原语,只需要自然语言指令和环境观察。它还可以通过在线学习提高对接触丰富交互场景的动力学建模能力。VoxPoser在模拟和真实机器人环境中展示了在超过30种日常操纵任务上的优异表现,并且具有对动态干扰的鲁棒性。
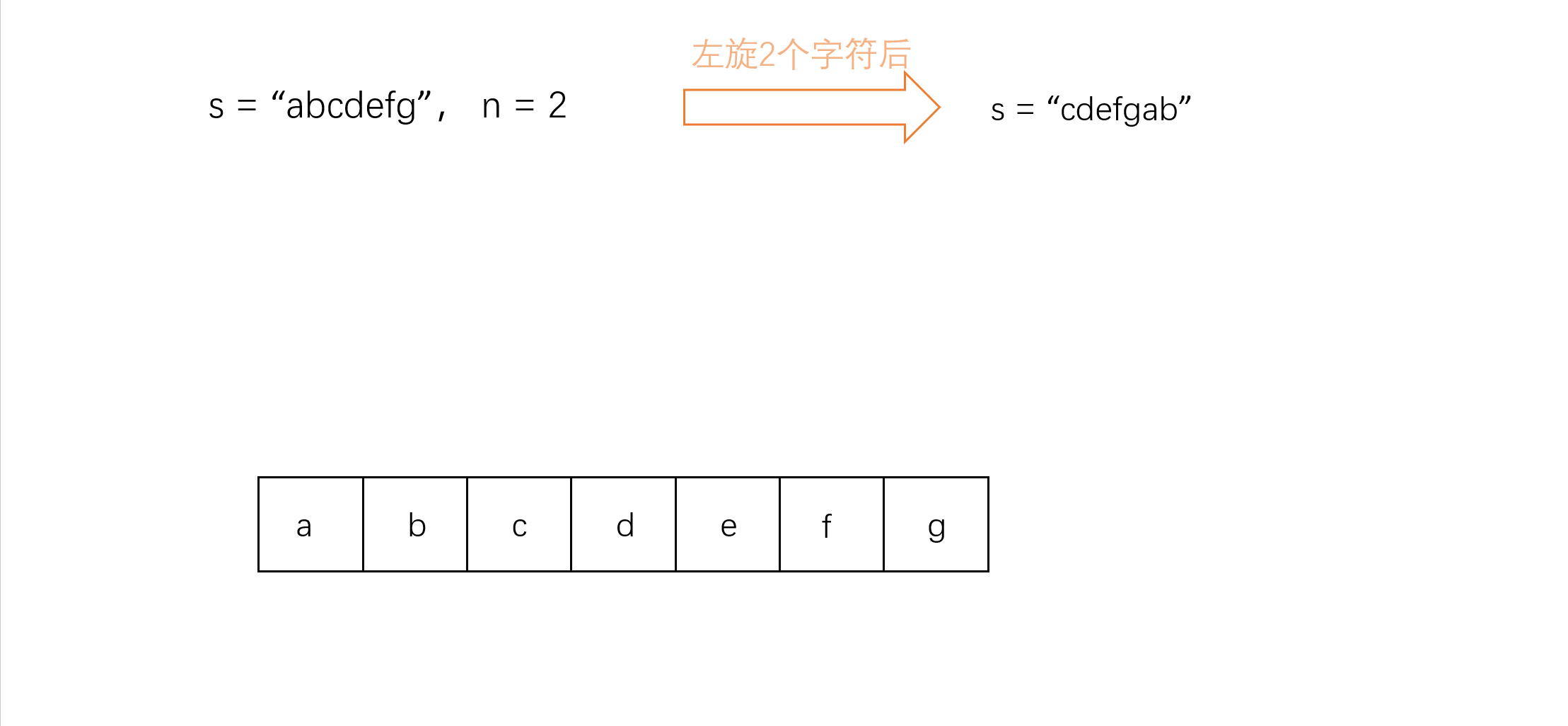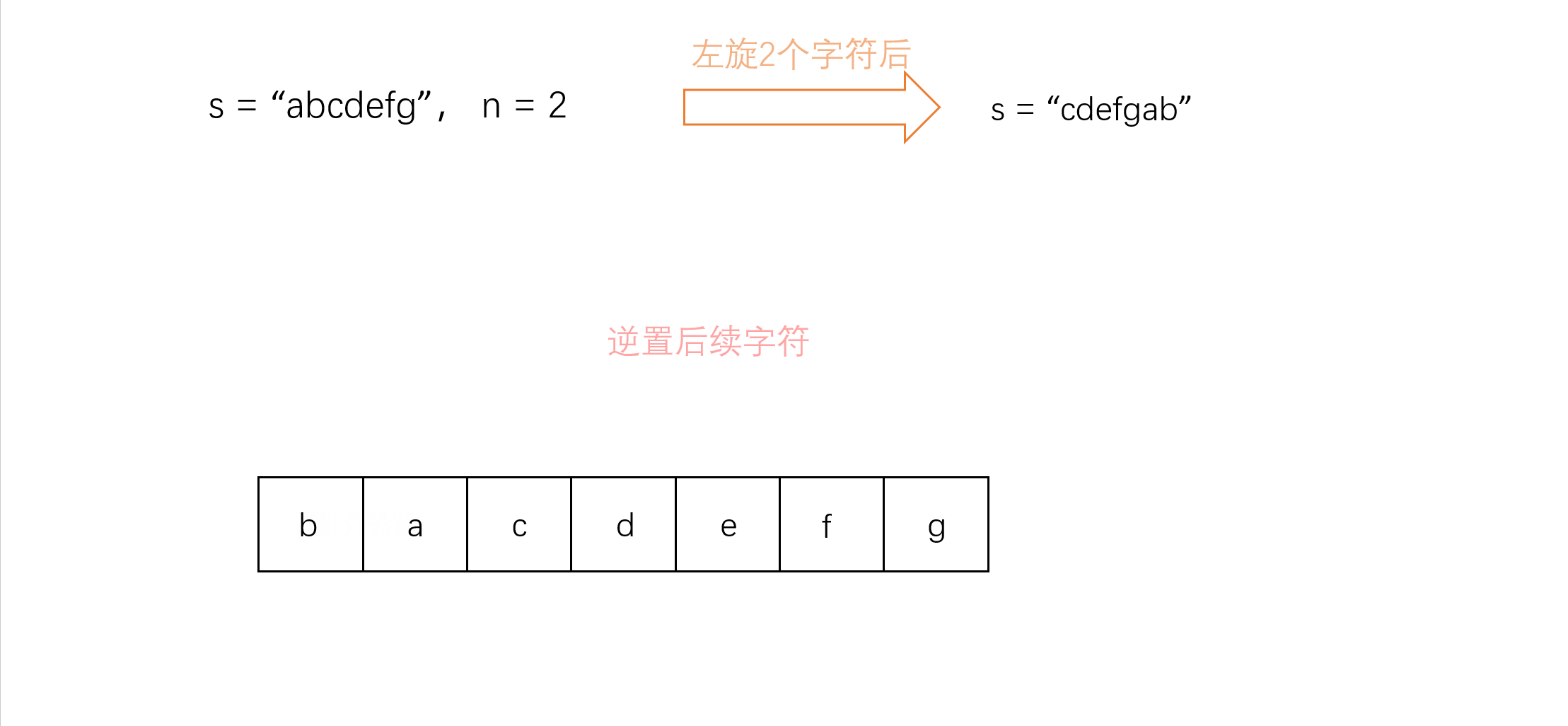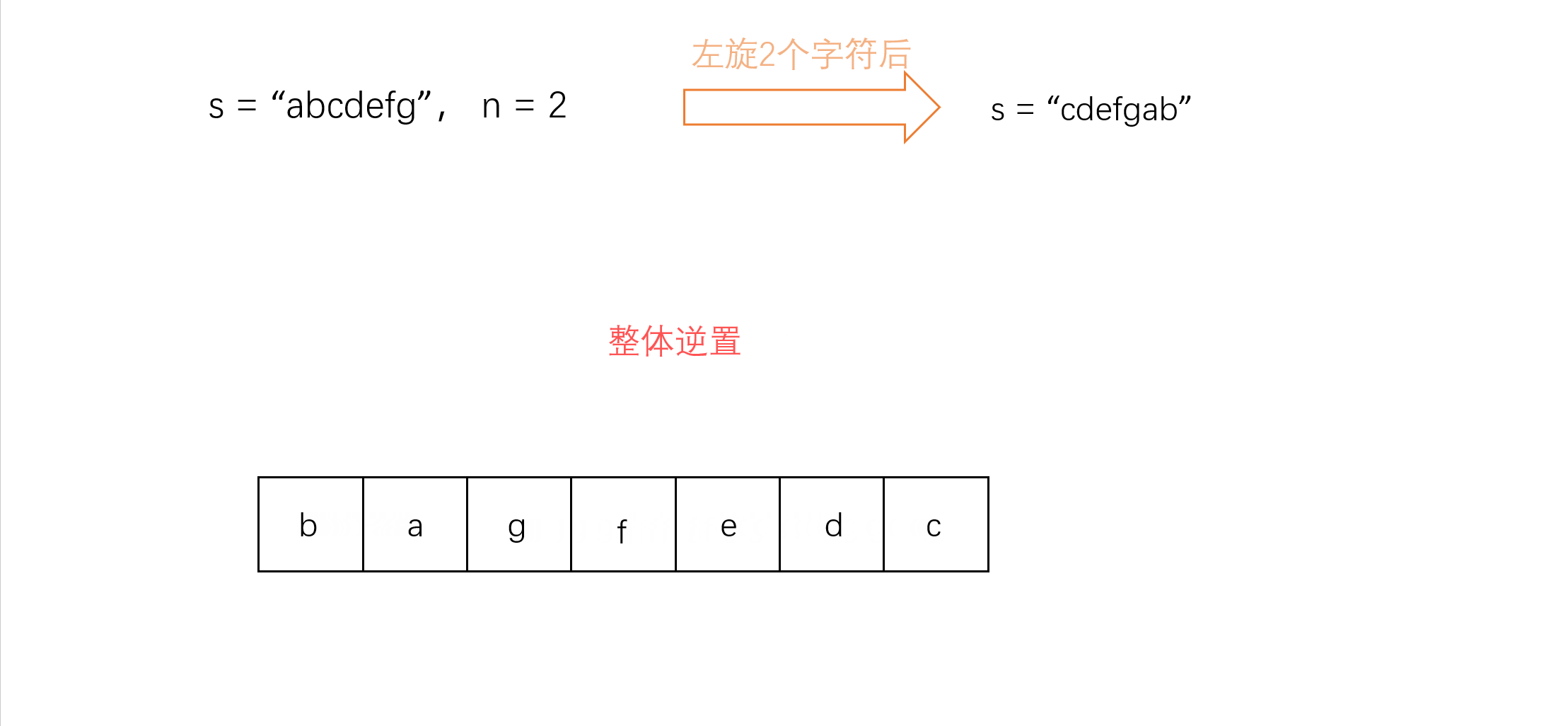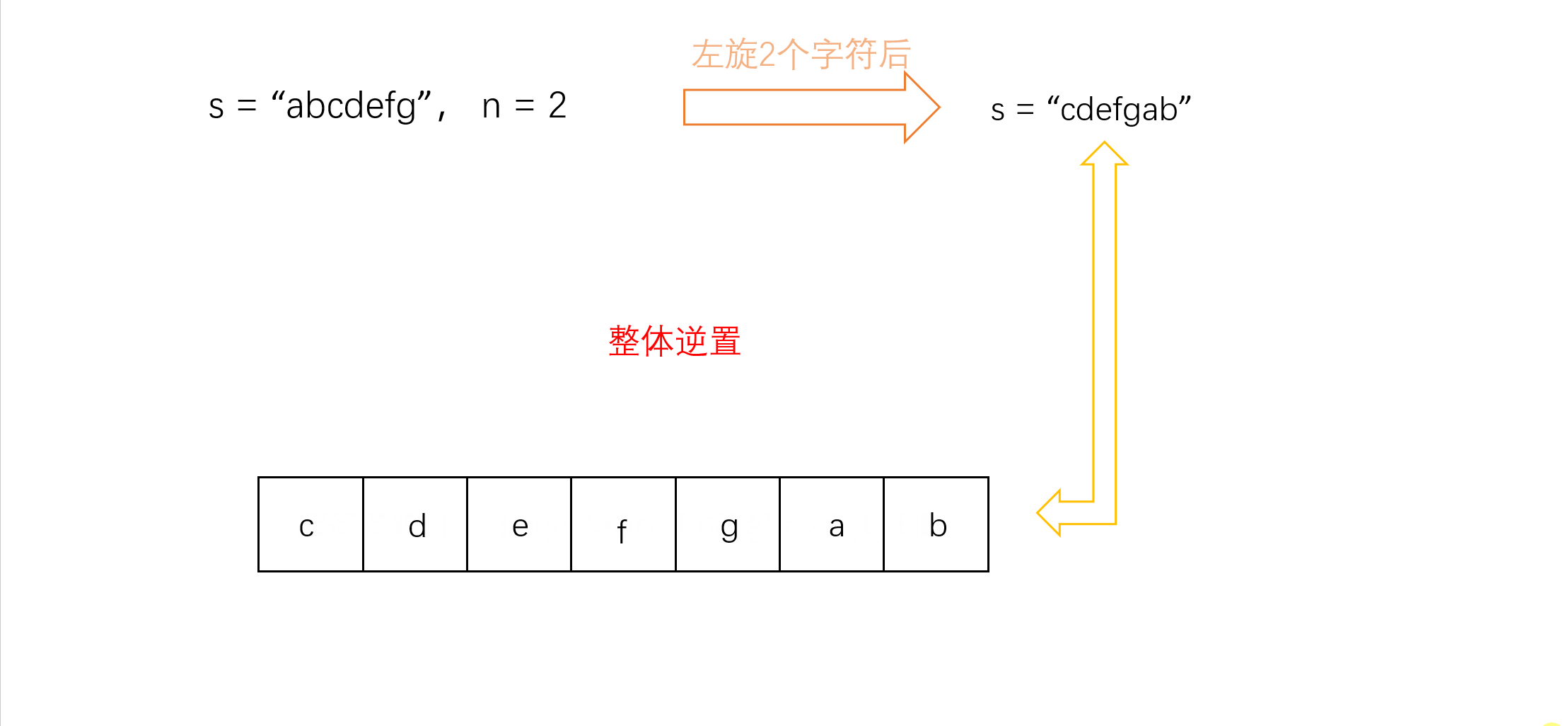





![[Unity实战]EnhancedScroller v2.21.4简单使用[开箱可用]](https://img-blog.csdnimg.cn/5e5e0370120c4e3585d018226d51eb4d.png)