本文介绍Transformer的基本原理,主要记录一下自己的学习过程。
论文:https://arxiv.org/abs/1706.03762
参考:
- http://jalammar.github.io/illustrated-transformer/
- https://zhuanlan.zhihu.com/p/338817680
- https://blog.csdn.net/longxinchen_ml/article/details/86533005
主要参考了链接1中的内容,链接3是其翻译版本。
Transformer架构完全依赖于Attention机制,解决了输入输出的长期依赖问题,并且拥有并行计算的能力。整体结构如下图所示:

结构分四个部分:输入、encoder、decoder、输出
输入
这里说的是encoder的输入,Transformer输入是一个序列数据,在NLP中,Encoder 的 inputs就是分词后的词向量。可以是任意形式的词向量,如word2vec,GloVe,one-hot编码。
输入embedding后需要给每个word的词向量添加位置编码positional encoding,为什么需要添加位置编码呢?
因为一句话中,如果词语出现位置不同,意思可能发生变化。但是Transformer 的是完全基于self-Attention地,而self-attention是不能获取词语位置信息的,就算打乱一句话中词语的位置,每个词还是能与其他词之间计算attention值。
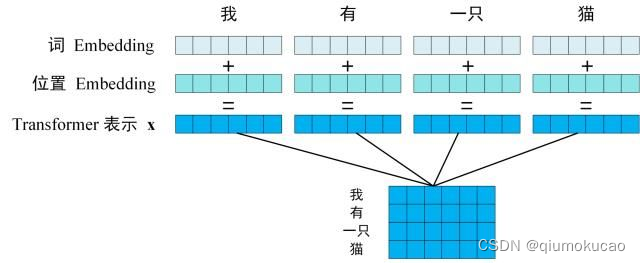
positional encoding怎么获取
1.可以通过数据训练学习得到positional encoding,类似于训练学习词向量,Google在之后的bert中的positional encoding便是由训练得到地。
2.《Attention Is All You Need》论文中Transformer使用的是正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,然后和对应的位置的词向量相加,位置向量维度和词向量的维度一致。过程如上图,PE(positional encoding)计算公式如下:
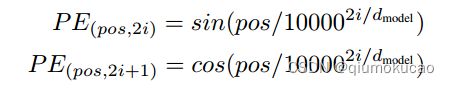
为什么使用正余弦位置编码?
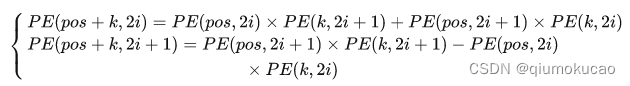
可以看出,对于 pos+k 位置的位置向量某一维 2i 或 2i+1 而言,可以表示为,pos 位置与 k 位置的位置向量的2i 与 2i+1维的线性组合,这样的线性组合意味着位置向量中蕴含了相对位置信息。
Encoder
编码器部分包括Multi-Head Attention、Add&Norm和Feed Forward,下面分别介绍。
Multi-Head Attention
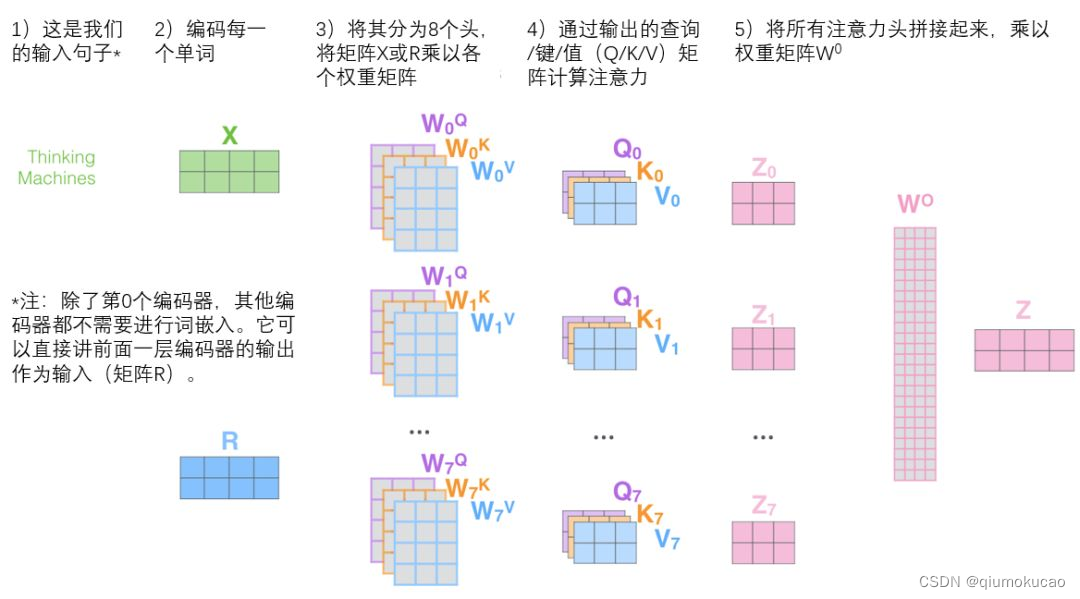
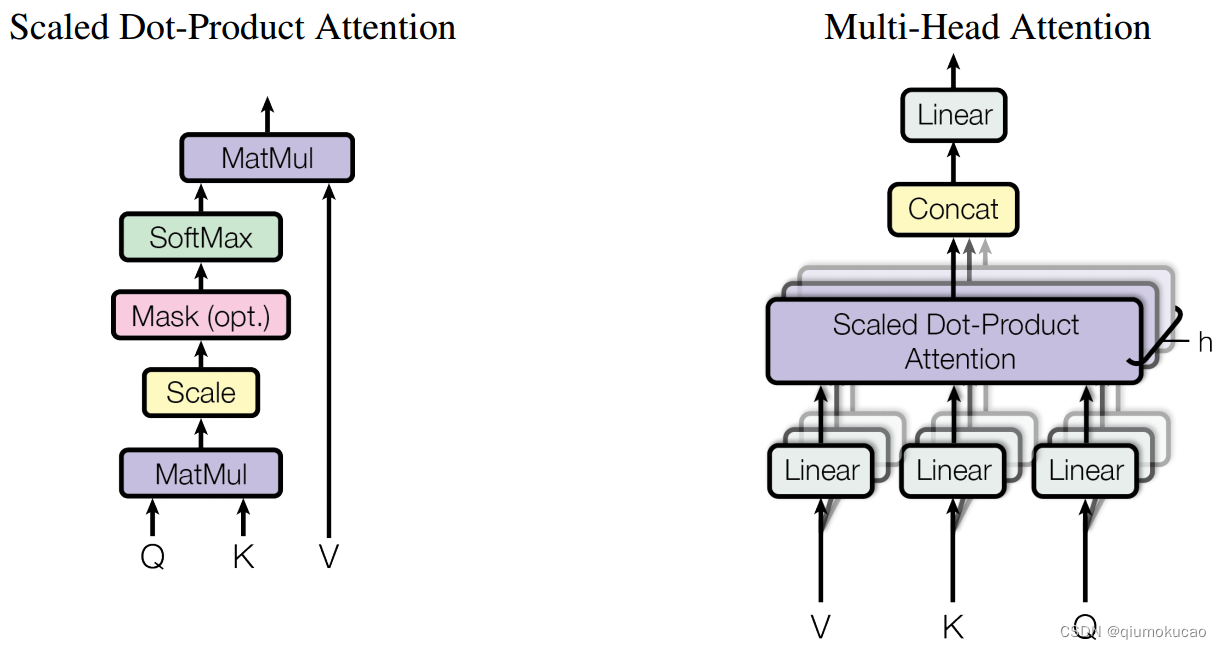 上图右侧就是 Multi-Head Attention部分,其中h代表有h个head,每个head部分的注意力计算,就是上图中左侧的过程。
上图右侧就是 Multi-Head Attention部分,其中h代表有h个head,每个head部分的注意力计算,就是上图中左侧的过程。
其中Q、K、V是输入通过参数运算得到的:
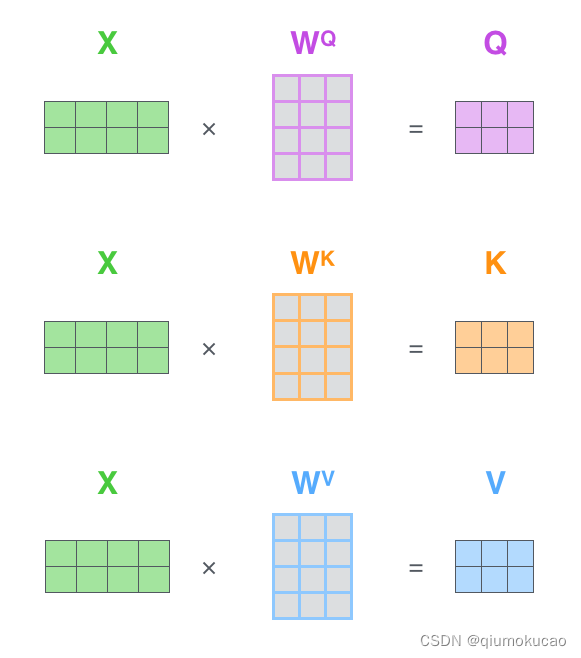
假如输入X维度是(4,512),权重W的维度是(512,64),得到的Q、K、V的维度就是(4,64)。
得到Q,K,V之后,接下来就是计算Attention值了。
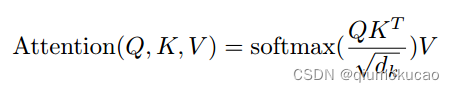

示例:
用当前词的q向量和所有的k向量计算点积,得到一个得分,这个得分意味着,我们在编码当前词的时候,需要在其他位置的词上集中多少的注意力。
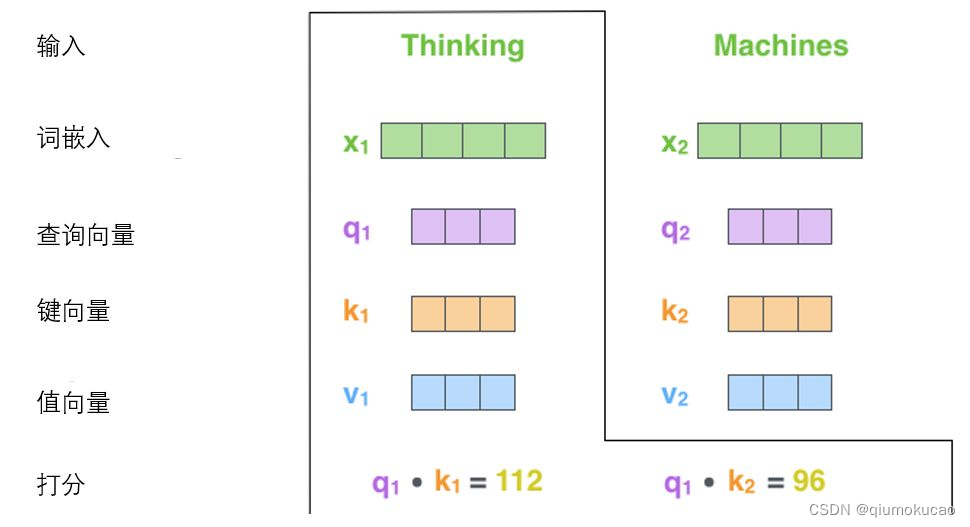
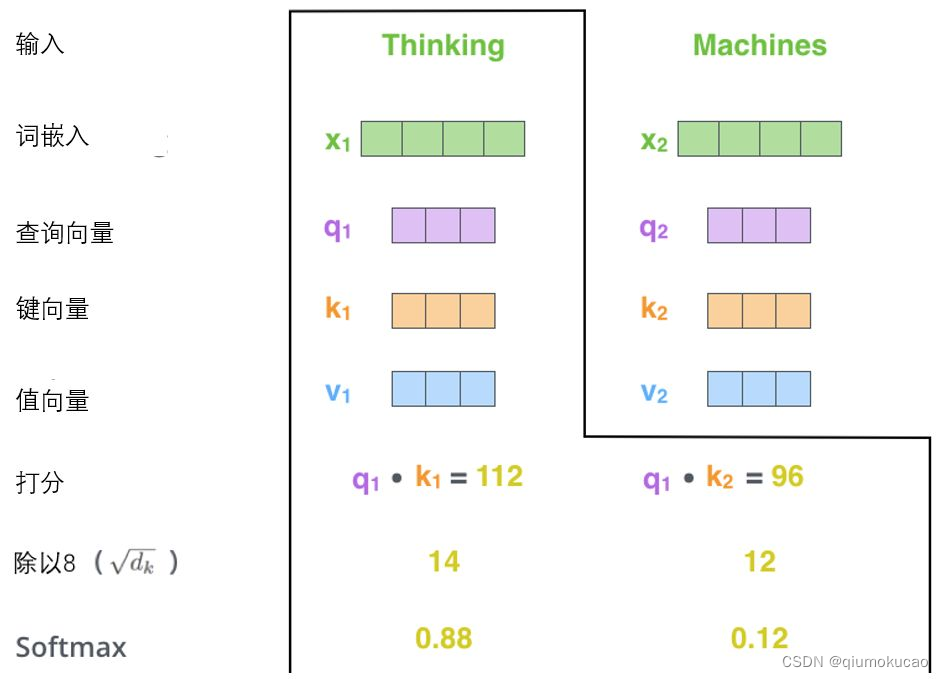
之后将得分先除以8(,q维度的平方根),再经过softmax进行归一化。
为什么要进行scale?
假设向量 q 和 k的各个分量是互相独立的随机变量,均值是0,方差是1,那么$$ q.k$$的均值为0,方差为$$d_k$$,方差较大时,$$ q.k$$的值会处于softmax的梯度平缓的区域,除以之后,可以使方差为1。
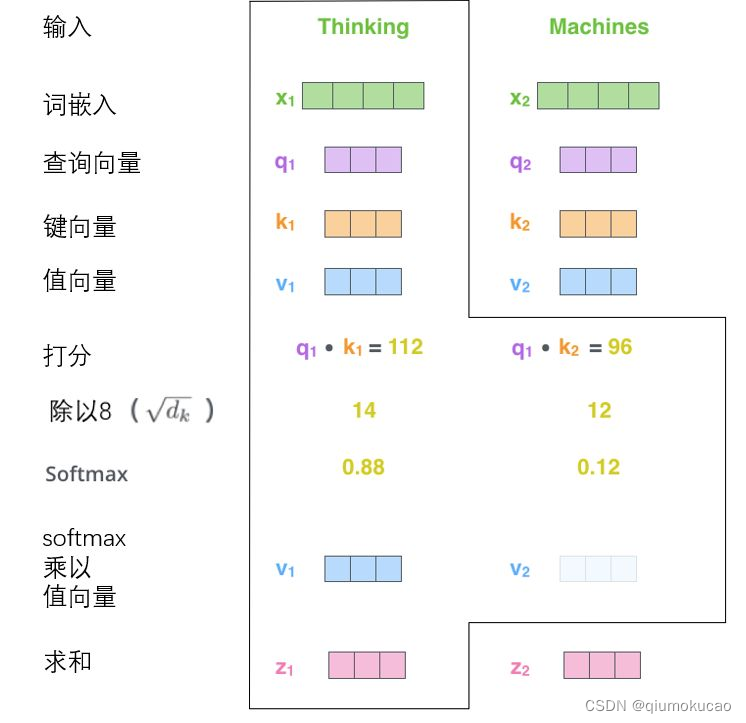
然后将结果和v向量进行加权求和。
通过增加一种叫做“多头”注意力(“multi-headed” attention)的机制,论文进一步完善了自注意力层,并在两方面提高了注意力层的性能:
1.它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
2.它给出了注意力层的多个“表示子空间”(representation subspaces)。接下来我们将看到,对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
计算公式:
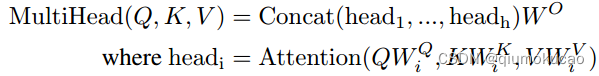
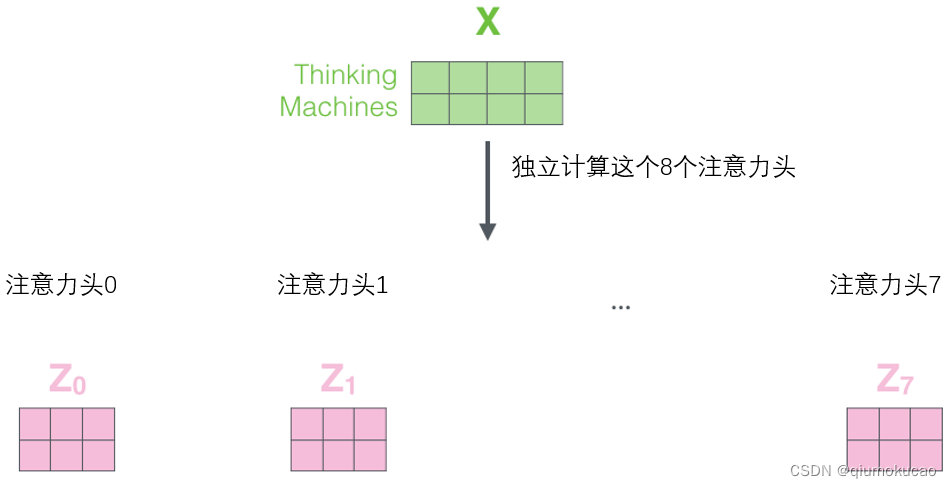
将八个输出矩阵压缩成一个输出矩阵:
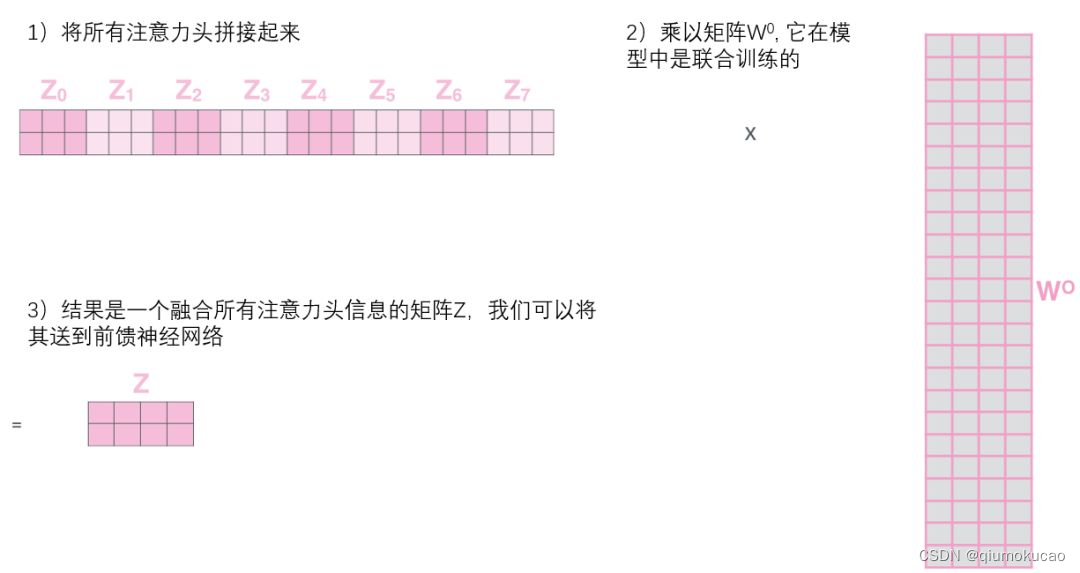
整个Multi-Head Attention 模块的过程合并如下:
Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
Add&Norm
在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个“层归一化”步骤。残差连接参考的是resnet网络。
Position-wise Feed-Forward Networks
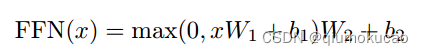
全连接层是一个两层的神经网络,先线性变换,然后ReLU非线性,再线性变换。
X是输入,Feed Forward 最终得到的输出矩阵的维度与X一致。
通过上面描述的 Multi-Head Attention,Add & Norm,Feed Forward,就可以构造出一个 Encoder block,Encoder block 接收输入矩阵 X(n×d) ,并输出一个矩阵 O(n×d) 。通过多个 Encoder block 叠加就可以组成 Encoder。
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C,这一矩阵后续会用到 Decoder 中。
Decoder
Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
Masked Multi-Head Attention
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。下面以 "我有一只猫" 翻译成 "I have a cat" 为例,了解一下 Masked 操作。

Decoder 可以在训练的过程中并行化训练,即将正确的单词序列 (<Begin> I have a cat) 和对应输出 (I have a cat <end>) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 "<Begin> I have a cat <end>"。
第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 "<Begin> I have a cat" (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
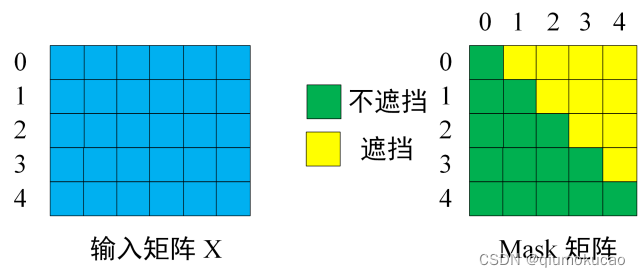
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。
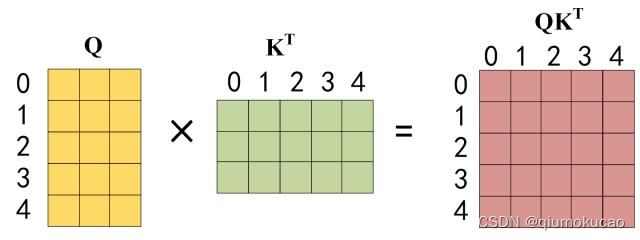
第三步:在得到 QKT 之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
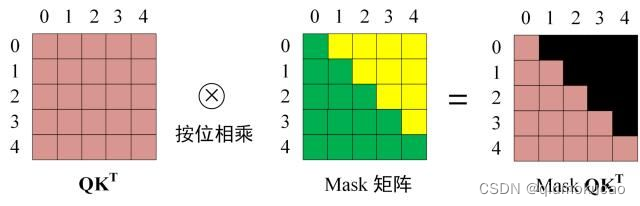
得到 Mask QKT 之后在 Mask QKT上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
第四步:使用 Mask QKT与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 Z1 是只包含单词 1 信息的。
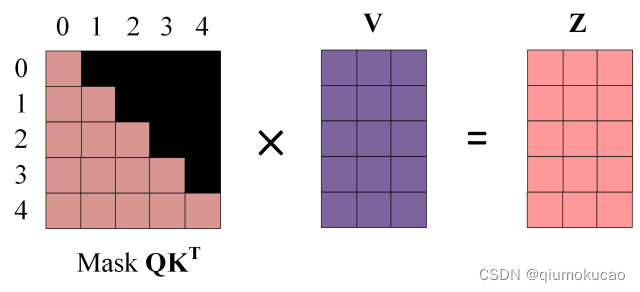
第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵 Zi ,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出Zi 然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
Multi-Head Attention
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
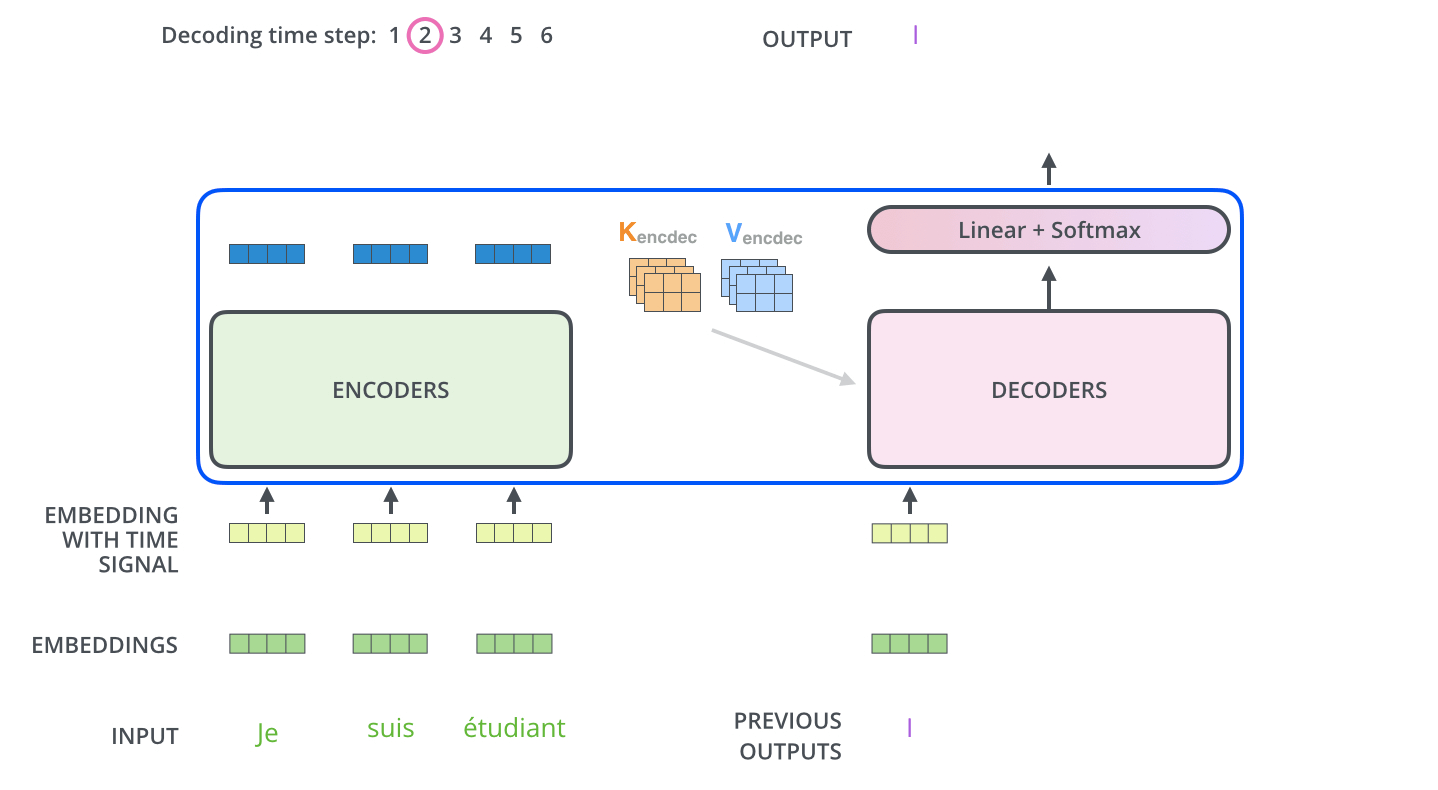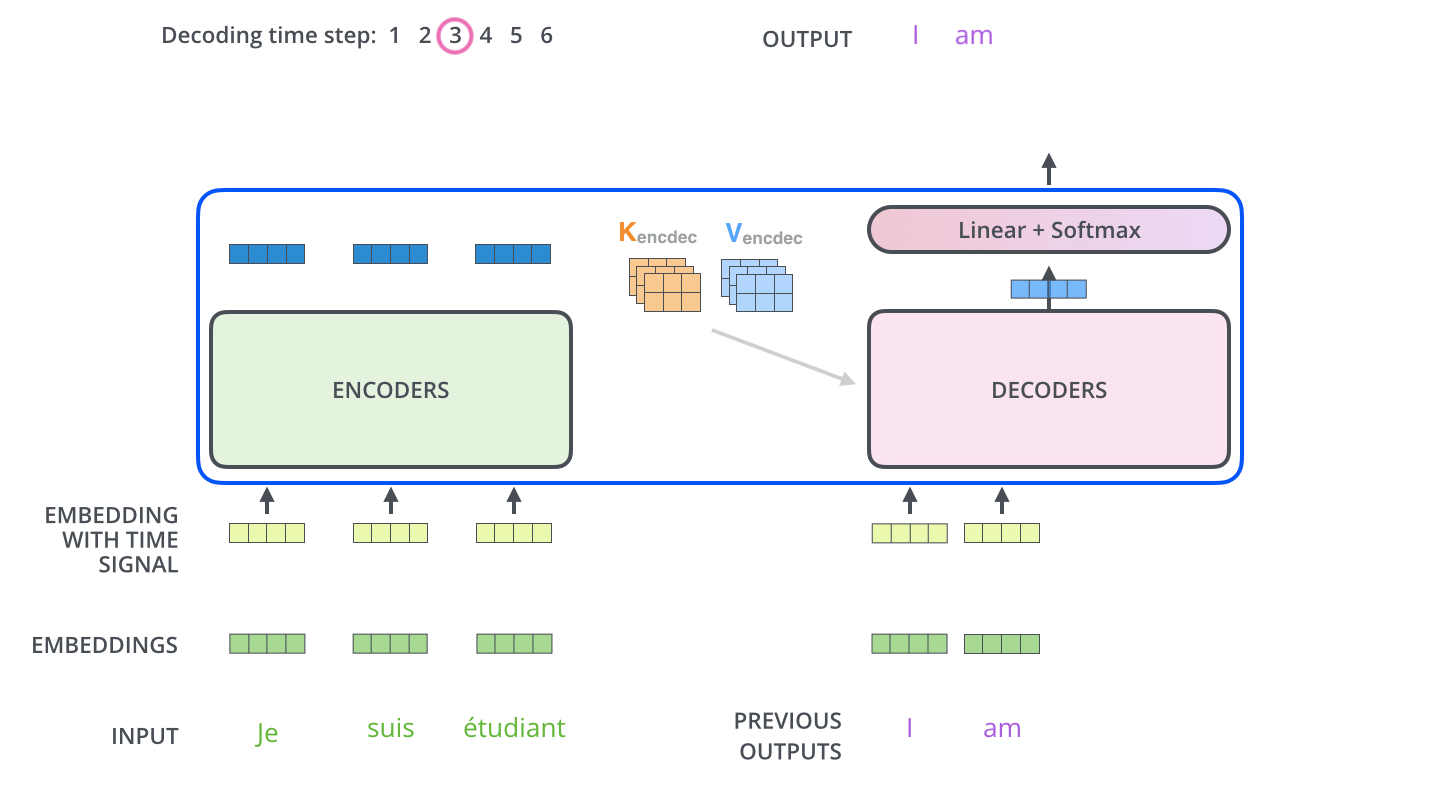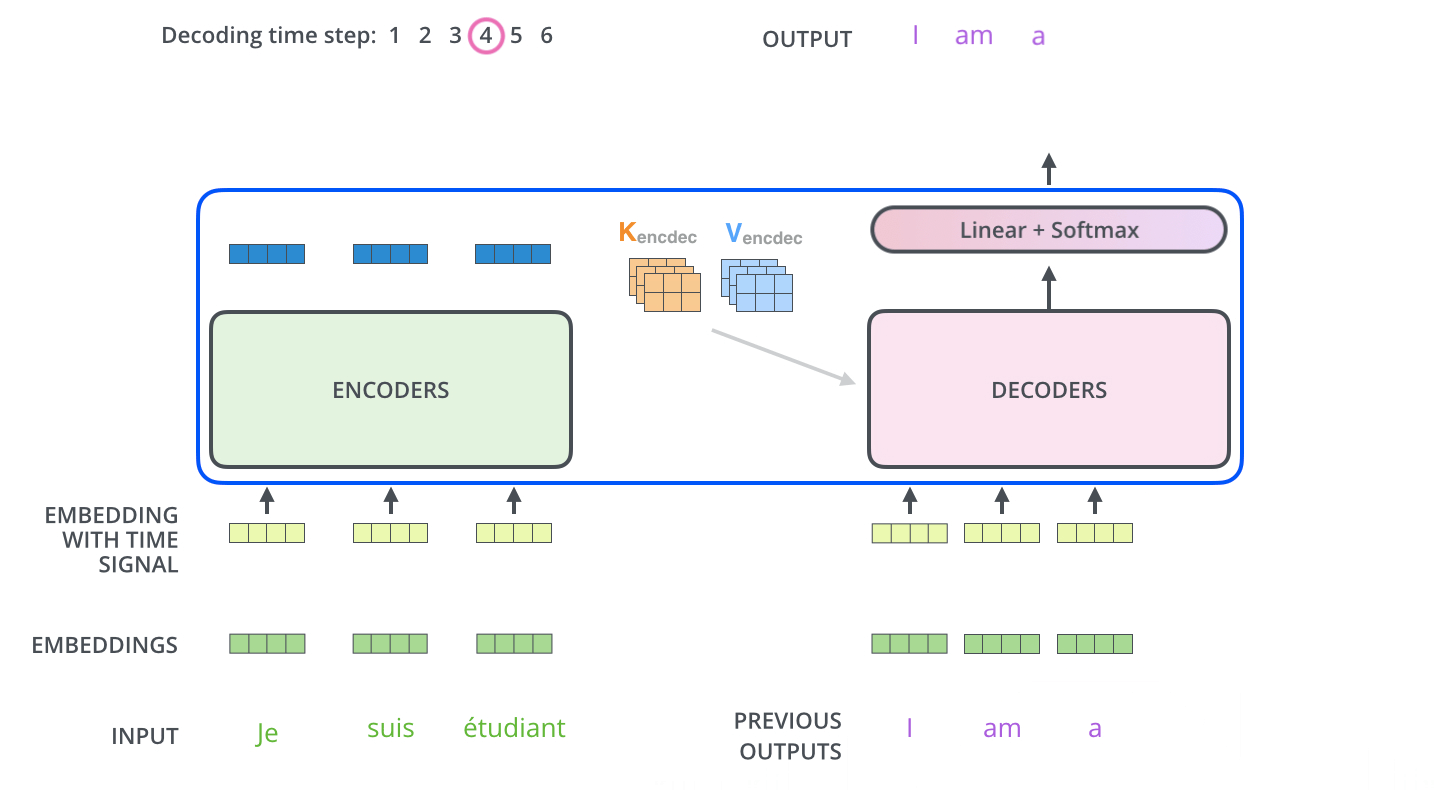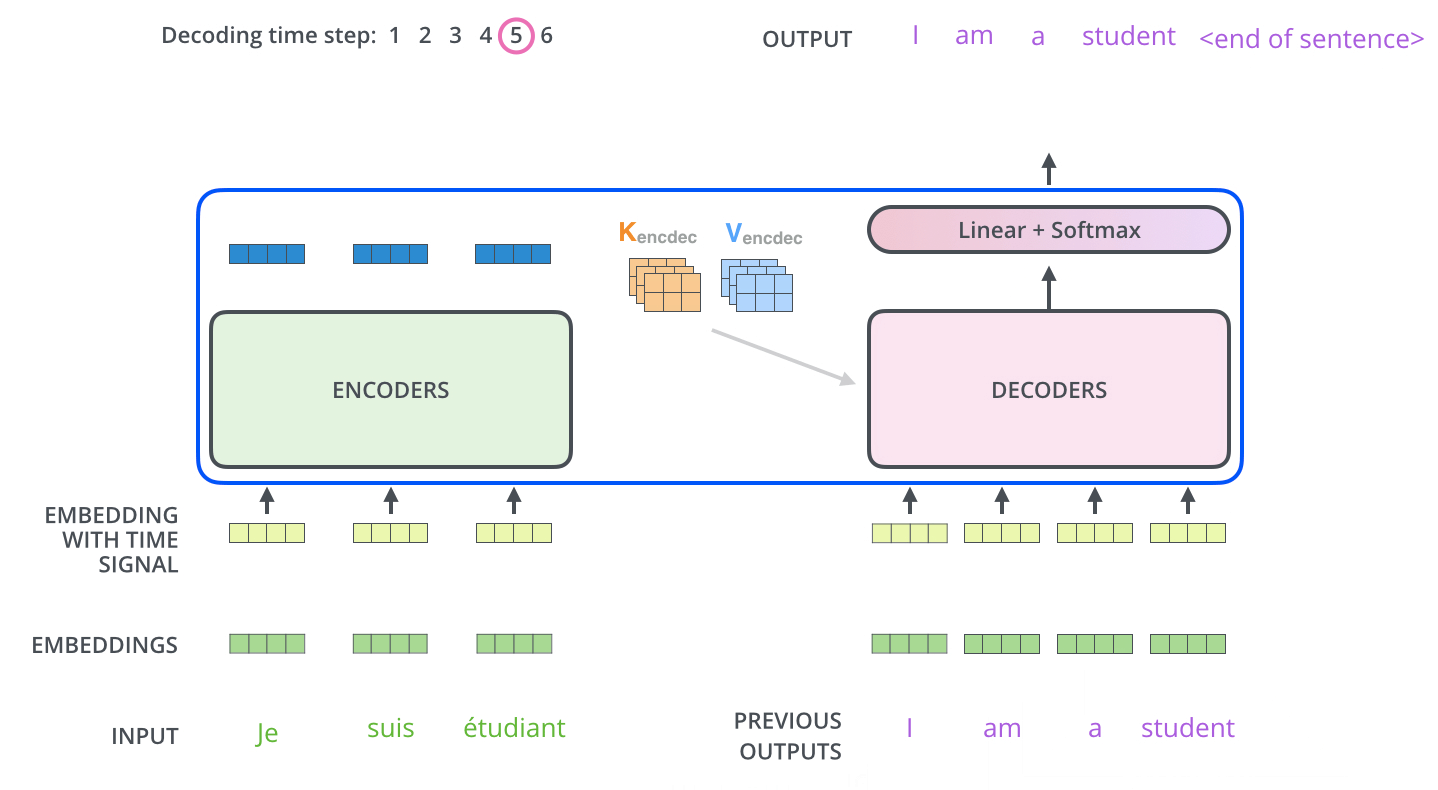
输出
Decoder 输出经过一个线性层,然后接softmax,得到输出概率,获取概率值最大的位置,其在词表中对应的单词即为预测结果(也可以采用beam search的方法得到预测结果)。
预测流程如下: