当涉及到集成学习时,投票法和袋装法是两种常见的技术,用于将多个基学习器(base learner)组合成一个强大的集成模型。
投票法(Voting):投票法是一种简单且常用的集成学习方法。在投票法中,多个基学习器(如随机森林、XGBoost、LightGBM等)被训练并组合在一起,通过对每个基学习器的预测结果进行投票来确定最终的集成预测结果。投票法可以根据投票方式分为两种类型:硬投票和软投票。
- 硬投票(Hard Voting):在硬投票中,每个基学习器投票给一个类别标签,最终的预测结果是得票最多的类别标签。
- 软投票(Soft Voting):在软投票中,每个基学习器给出了每个类别的概率估计,这些概率进行平均或加权平均,最终选择概率最高的类别标签作为预测结果。
投票法可以通过平衡不同基学习器之间的性能来提高整体预测的准确性和稳定性。它适用于二分类和多分类问题。
袋装法(Bagging):袋装法是一种基于自助采样(bootstrap sampling)的集成学习方法。在袋装法中,通过从原始训练集中随机有放回地采样生成多个训练子集,每个子集用于训练一个基学习器。然后,通过对基学习器的预测结果进行平均或多数投票来确定最终的集成预测结果。
- 袋装法的主要优势在于通过多样化训练数据的方式,可以减少过拟合的风险,并提高模型的泛化能力。袋装法适用于各种机器学习算法,如决策树、随机森林等。
需要注意的是,袋装法和投票法可以结合使用。在这种情况下,袋装法用于生成多个训练子集和基学习器,然后投票法用于集成基学习器的预测结果,得到最终的集成预测结果。这种结合使用的方法可以进一步提高集成模型的性能和鲁棒性。
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# 读取历史数据
df_o2d_temp = df_o2d[df_o2d['lt_rp_pod'] <= 120].reset_index().drop('index', axis=1)
history_data = df_o2d_temp[['dayofweek_secc_rp_created_local', 'hour_secc_rp_created_local', 'supplier_name', 'tms_sla', 'delivery_plant', 'actual_shipped_wh', 'ship_to_region', 'premier_premiumcare_legion_ultimate', 'cat_lt_rp_pod_1']]
# 选取需要使用的特征列
feature_cols = ['dayofweek_secc_rp_created_local', 'hour_secc_rp_created_local', 'supplier_name', 'tms_sla', 'delivery_plant', 'actual_shipped_wh', 'ship_to_region', 'premier_premiumcare_legion_ultimate']
# 使用独热编码处理特征列
encoder = OneHotEncoder(sparse=False, handle_unknown='ignore')
encoder.fit(history_data[feature_cols])
history_data_encoded = pd.DataFrame(encoder.transform(history_data[feature_cols]))
# 获取独热编码后的特征列名称
feature_names = encoder.get_feature_names(feature_cols)
# 将独热编码后的特征列与预测目标列合并
encoded_data = pd.concat([history_data_encoded, history_data['cat_lt_rp_pod_1']], axis=1)
# 拆分训练集和测试集
train_data = encoded_data.sample(frac=0.8, random_state=158)
test_data = encoded_data.drop(train_data.index)
# 分离特征列和目标列
train_features = train_data.iloc[:, :-1]
train_target = train_data.iloc[:, -1]
test_features = test_data.iloc[:, :-1]
test_target = test_data.iloc[:, -1]
# 将目标变量转换为整数标签
label_encoder = LabelEncoder()
train_target_encoded = label_encoder.fit_transform(train_target)
test_target_encoded = label_encoder.transform(test_target)
# 定义集成学习模型的基分类器
rf_model = RandomForestClassifier(n_estimators=200, random_state=42)
xgb_model = XGBClassifier(n_estimators=200, learning_rate=0.5, max_depth=20, reg_alpha=9, reg_lambda=5, gamma=0.6)
lgbm_model = LGBMClassifier(n_estimators=200, learning_rate=0.5, max_depth=20)
lr_model = LogisticRegression()
# 定义投票法集成学习模型
ensemble_model = VotingClassifier(
estimators=[('rf', rf_model), ('xgb', xgb_model), ('lgbm', lgbm_model), ('lr', lr_model)],
voting='hard' # 使用硬投票进行集成
)
# 训练模型并进行预测
rf_model.fit(train_features, train_target_encoded)
xgb_model.fit(train_features, train_target_encoded)
lgbm_model.fit(train_features, train_target_encoded)
lr_model.fit(train_features, train_target_encoded)
ensemble_model.fit(train_features, train_target_encoded)
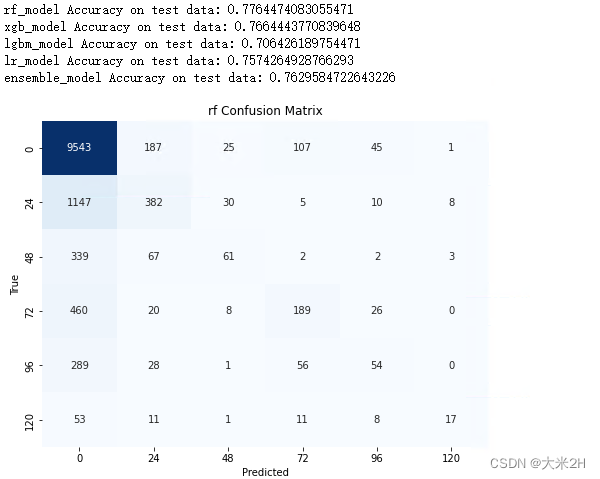
print('rf_model', "Accuracy on test data:", accuracy_score(test_target_encoded, rf_model.predict(test_features)))
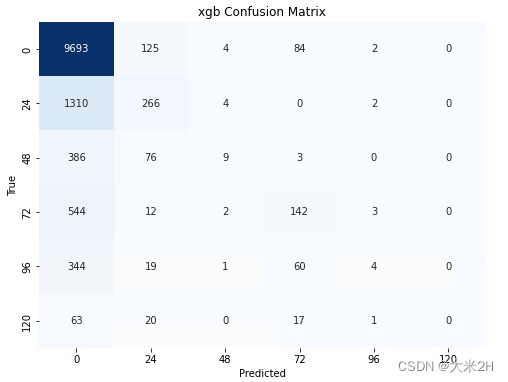
print('xgb_model', "Accuracy on test data:", accuracy_score(test_target_encoded, xgb_model.predict(test_features)))
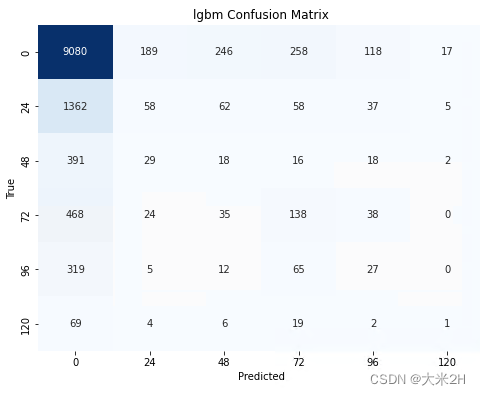
print('lgbm_model', "Accuracy on test data:", accuracy_score(test_target_encoded, lgbm_model.predict(test_features)))
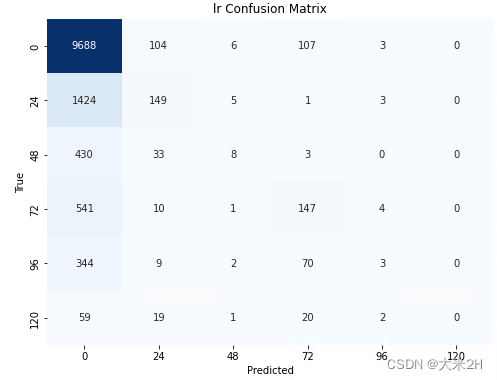
print('lr_model', "Accuracy on test data:", accuracy_score(test_target_encoded, lr_model.predict(test_features)))
print('ensemble_model', "Accuracy on test data:", accuracy_score(test_target_encoded, ensemble_model.predict(test_features)))
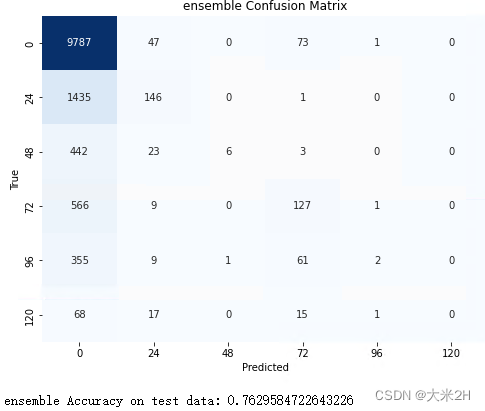
# 绘制混淆矩阵函数
def plot_confusion_matrix(model, test_features, test_target, model_name):
predictions = model.predict(test_features)
cm = confusion_matrix(test_target, predictions)
# 绘制混淆矩阵热力图
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', cbar=False,
xticklabels=label_encoder.classes_, yticklabels=label_encoder.classes_)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('{0} Confusion Matrix'.format(model_name))
plt.show()
# 绘制混淆矩阵
plot_confusion_matrix(rf_model, test_features, test_target_encoded, 'rf')
plot_confusion_matrix(xgb_model, test_features, test_target_encoded, 'xgb')
plot_confusion_matrix(lgbm_model, test_features, test_target_encoded, 'lgbm')
plot_confusion_matrix(lr_model, test_features, test_target_encoded, 'lr')
plot_confusion_matrix(ensemble_model, test_features, test_target_encoded, 'ensemble')
predictions = ensemble_model.predict(test_features)
# 评估模型
accuracy = accuracy_score(test_target_encoded, predictions)
print('ensemble', "Accuracy on test data:", accuracy)