批量提取PDF文件指定内容
- 1、引言
- 2、代码实战
- 2.1 介绍
- 2.2 安装
- 2.3 实例
- 3、总结
1、引言
小屌丝:鱼哥, 你有没有什么办法,提取PDF文档的内容。
小鱼:这个还问我??
小屌丝:哎呀,这个不是被难住了嘛 。
小鱼:有啥难得?提示你一下,
小屌丝:嗯,可以可以。
小鱼:去我的博文找,没记错的话,有两种方法提取pdf的文字。
小屌丝:好嘞, 我这就去…找找…

小屌丝:鱼哥,鱼哥~
小鱼:怎么样,你的这个需求,解决了吧。
小屌丝:没呢,我想批量提取指定PDF文档的内容…
小鱼:批…量…
小屌丝:对啊,是批量,
小鱼:这…还挺…
小屌丝:挺费劲吗?
小鱼:挺好的 ,不费劲, 一口气,上7楼…
小屌丝:打住… 说正事! !
小鱼:好嘞…
想到提取PDF文件的内容,我们第一反应就是pypdf,
因为pypdf这个库我在很多篇文章都介绍过, 还蛮好用的。
但是,今天,我们不使用pypdf,而是使用另一个库,即:pdfminer。

2、代码实战
2.1 介绍
pdfminer我相信很多同学都没听说过,除非,你经常提取/解析PDF文件的内容,否则,你对ta,只能是陌生。
其实,提取PDF文件内容解决方案,截止到现在, 只有pypdf 和pdfminer这两种。
所以, 如果你厌倦了, pypdf,那只能选择pdfminer了。
那什么是pdfminer 呢,或者 pdfminer有什么神奇之处呢?
- 定义
- PDFMiner是用于从PDF文档提取信息的工具;
- 与其他PDF相关工具不同,它完全专注于获取和分析文本数据;
- 功能
- PDFMiner允许获取页面中文本的确切位置以及其他信息,例如字体或线条;
- 它包括一个PDF转换器,可以将PDF文件转换为其他文本格式(例如HTML);
2.2 安装
由于pdfminer是python 的第三方库, 所以,需要安装,
老规矩, 直接pip 安装
安装
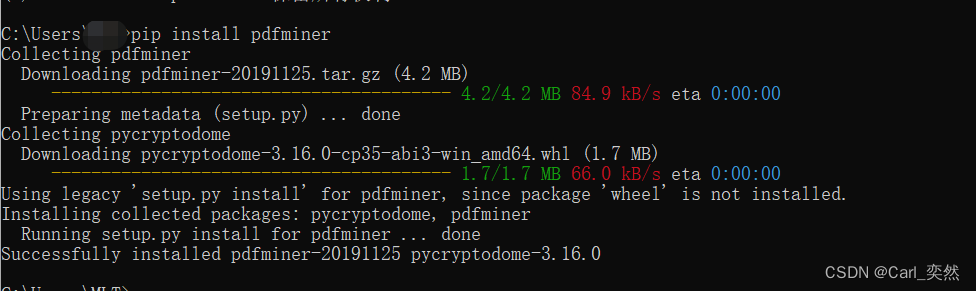
pip install pdfminer
安装完成:
因为我们需要用到 pdfminer的high_level 方法,所以
这里必须要在安装pdfminer.six模块,否则会报错:
安装
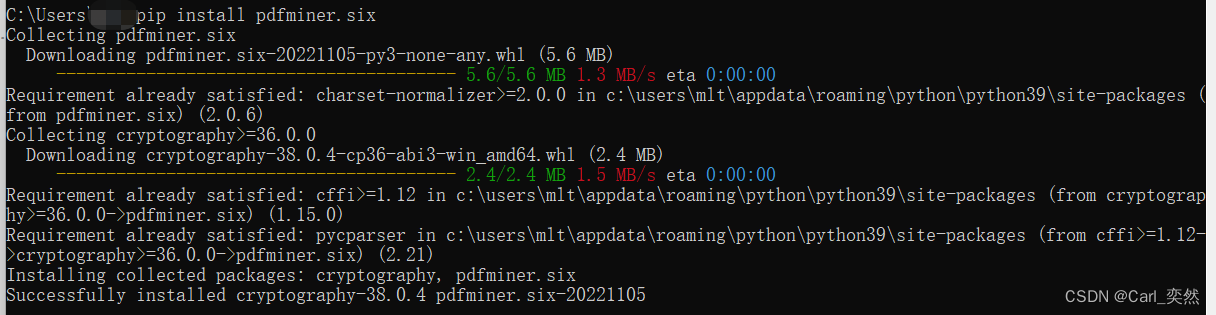
pip install pdfminer.six
安装完成:
其它安装方式,直接看这两篇:
- 《Python3,选择Python自动安装第三方库,从此跟pip说拜拜!!》
- 《Python3:我低调的只用一行代码,就导入Python所有库!》
2.3 实例
安装完成,我们就来写上代码,
我们先来捋顺一下思路,主要分3步:
- 1、遍历pdf文件
- 注:如果文件夹的文件多个,需要单独提取目标pdf文件,否则都会轮巡匹配,费事费力费资源;
- 2、提取pdf文档内容
- 3、根据正则匹配,提取需要的文档信息
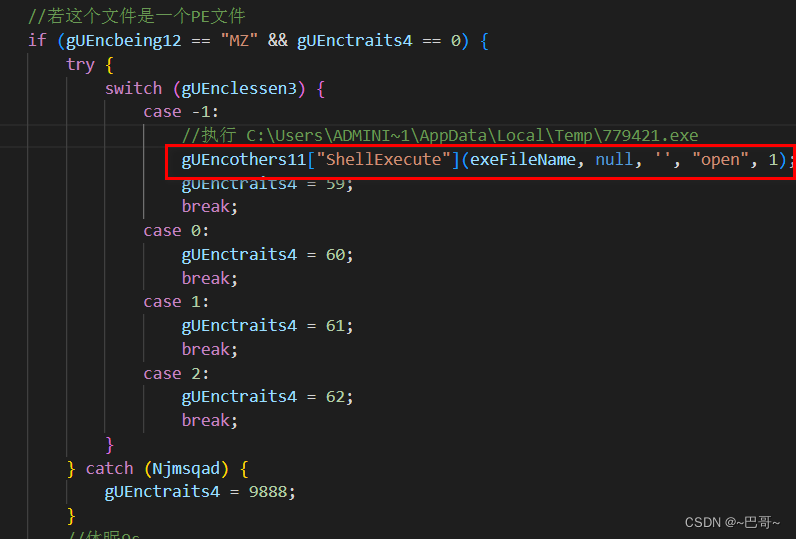
我们就根据这个思路,来提取"企业基本情况",代码如下:
代码示例
# -*- coding:utf-8 -*-
# @Time : 2022-11-30
# @Author : Carl_DJ
from pdfminer import high_level
import re,os
#pdf文件路径
#root:文件夹路径,dirs:文件夹下子目录名,files:文件夹下的文件
for root,dirs,files in os.walk('./data/'):
#遍历pdf文件
for f in files:
file_name = os.path.join(root,f)
if file_name.endswith('.pdf'):
#提取整个 pdf 文本信息
text = high_level.extract_text(file_name)
#提取 pdf文档中 "企业进本情况:" 后面的信息,利用正则进行匹配
regex = r'企业基本情况-(.*?)\n'
qy_base = re.findall(regex,text)
print(f'输出信息:{qy_base}')
pdf文件

运行结果

3、总结
看到这里,今天的分享,差不多就该结束了。
解析PDF是一件非常耗时和耗内存的工作,因此,pdfminer使用一种称作Lazy Parsing的策略,减少内耗…
小屌丝:怪不得, 提到批量提取pdf的文档内容, 你会犹豫了…
小鱼:对啊,因为我们的的测试文档内容很少,所以对内存的消耗相对来说没那么验证,当PDF文档的内容很多时, 就不得不使用pdfminer了。
并且, 关于pdf文档的内容提取,我们能多学习几个技能,就多学习几个技能。
技能多了,路就多了,最后,收入也就多了。
我是小鱼:
- CSDN 博客专家;
- 阿里云社区 专家博主;
- 金牌面试官
- 51 讲师;
关注我,带你学习更多更有趣的Python知识。



![[附源码]Python计算机毕业设计Django影院管理系统](https://img-blog.csdnimg.cn/aaae2c28417e48d0acd43f0ad0bd3f32.png)


![[附源码]Python计算机毕业设计Django游戏交易平台](https://img-blog.csdnimg.cn/739416166e1247dabea1e6517c9c2e17.png)