1.标记-清除算法
最基础的算法,分为两个阶段,“标记”和“清除”
原理:
- 标记阶段:collector从mutator根对象开始进行遍历,对从mutator根对象可以访问到的对象都打上一个标识,一般是在对象的header中,将其记录为可达对象。
- 清除阶段,collector对堆内存(heap memory)从头到尾进行线性的遍历,如果发现某个对象没有标记为可达对象-通过读取对象的header信息,则就将其回收。

可回收对象内存被收回,内存释放出来。
不足:
- 标记和清除效率低
- 回收之后有大量的不连续的空间碎片,这就会导致之后程序需分配大块连续的内存时,无法找到在足够的连续内存而不得不提前进行另一次的垃圾回收动作。
2.复制算法
为了解决效率问题,出现了复制算法
原理:
它可以将内存按照容量划分为大小相同的两块,每次只使用一块,当这块内存用完后,会将还存活的对象都放到另一块等大的内存中,最后再把已使用过的内存空间清理掉。这样每次都只会对半个内存回收,分配时不需要考虑内存空间碎片等问题。

缺点:
- 牺牲了一半的内存,成本太高。
- 当对象的存活率高时,就需要进行繁多的复制,效率就会下降。
tip:
然而,现在得商业虚拟机都采用这种算法来处理新生代 ,因为新生代“朝生夕死”,所以不需要按照1:1的比例来分配,而是将内存分为一块较大的Eden和两块Survivor区域,每次使用Eden和其中一块的Survivor区域。
当进行垃圾回收时,会将Eden和使用过的Survivor中存活的对象复制到另一块没使用过的Survivor区域中。
HotSpot默认Eden和Survivor比例为8:1,这样相对1:1浪费一半的内存来说,我们只浪费了10%的内存。我们不能保证每次内存回收过后存活对象都不超过10%,因此,当Survivor区域内存不够时,就需要依赖老年代来进行分配担保 (Handle Promotion )
3.标记-整理法
标记和整理
算法:
- 标记:与标记/清除算法是一模一样的,均是遍历GC Roots,然后将存活的对象标记。
- 整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。
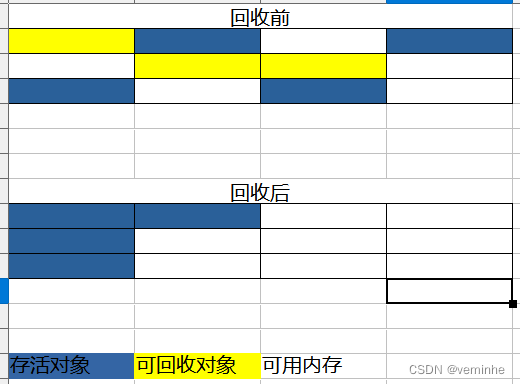
优点:
标记/整理算法不仅可以弥补标记/清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价。
缺点:
效率不高,不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。
效率:复制算法>标记/整理算法>标记/清除算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。
内存整齐度:复制算法=标记/整理算法>标记/清除算法。
内存利用率:标记/整理算法=标记/清除算法>复制算法。
4.分代收集
按照对象存活周期的不同, 将内存划分为几块。一般是把Java堆分为新生代和年老带,根据各个年代采用最合适的算法。譬如在新生代每次垃圾回收只有少量的存活,就使用复制法,在年老代中,对象都活的久,没有额外的内存担保空间,就必须采用“标记清除”出或者“标记整理”。









![[ICML 2023] Fast inference from transformers via speculative decoding](https://img-blog.csdnimg.cn/e83aeef2f1ba4045a47f3ab465a685b4.png#pic_center)