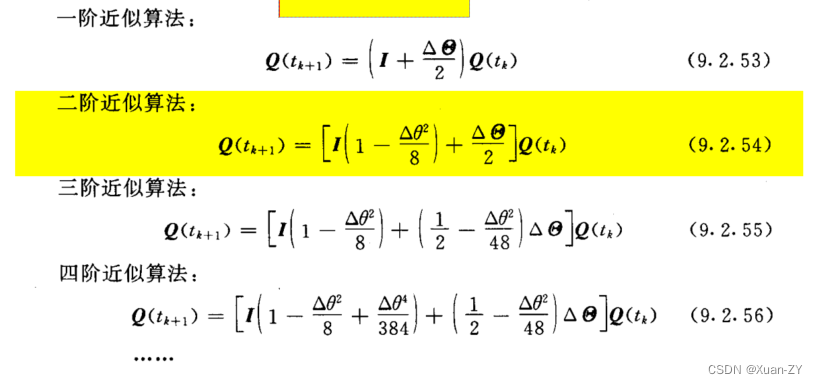DALL·E 1
DALL·E 1可以看成是VQ-VAE和文本经过BPE编码得到的embedding
AE(Auto Encoder)
encoder decoder结构,AE在生成任务时只会模仿不会创造,所有有了后面的VAE
VAE(Variational AutoEncoder)
不再学习固定的bottleneck特征,而开始学习distribution
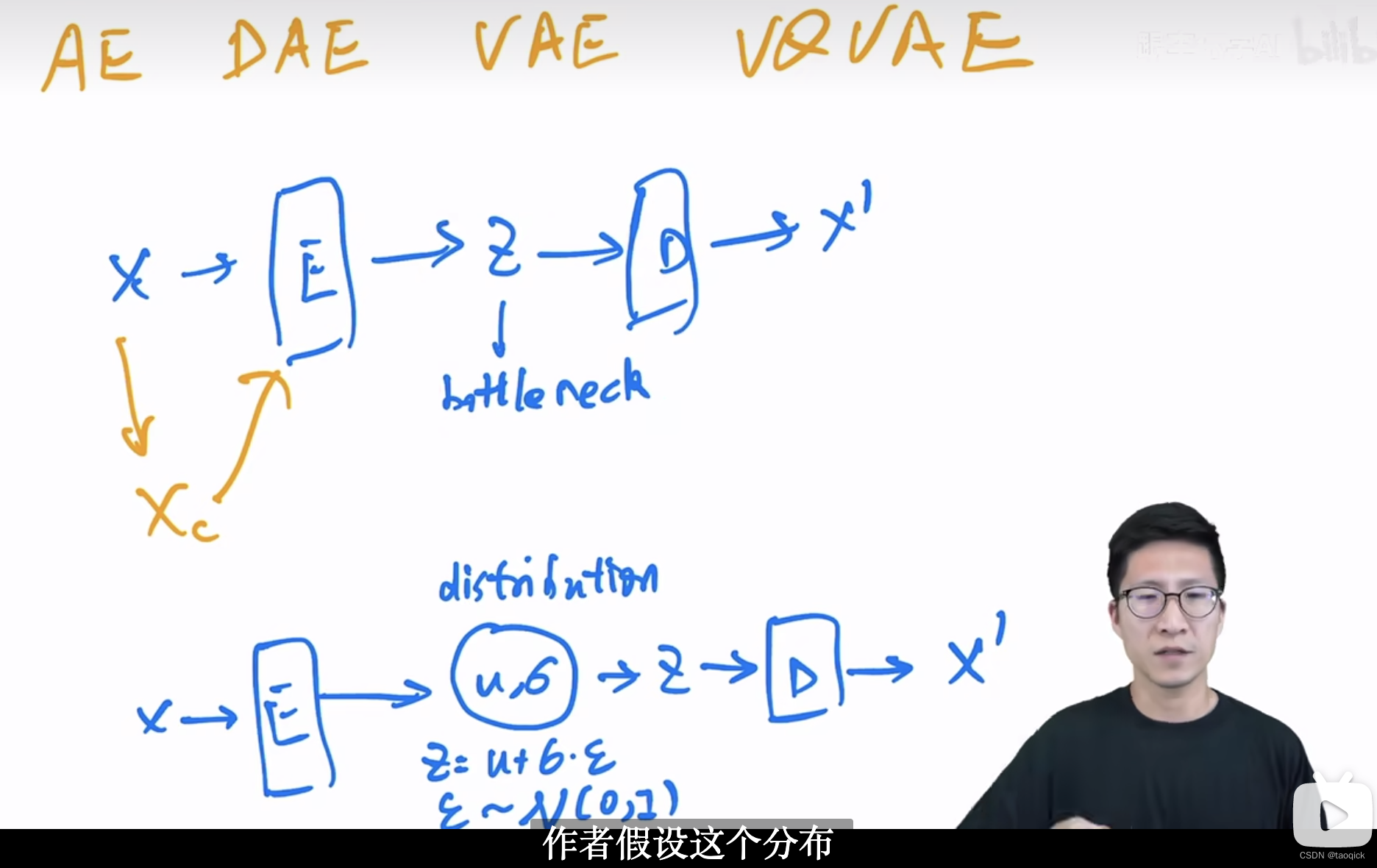
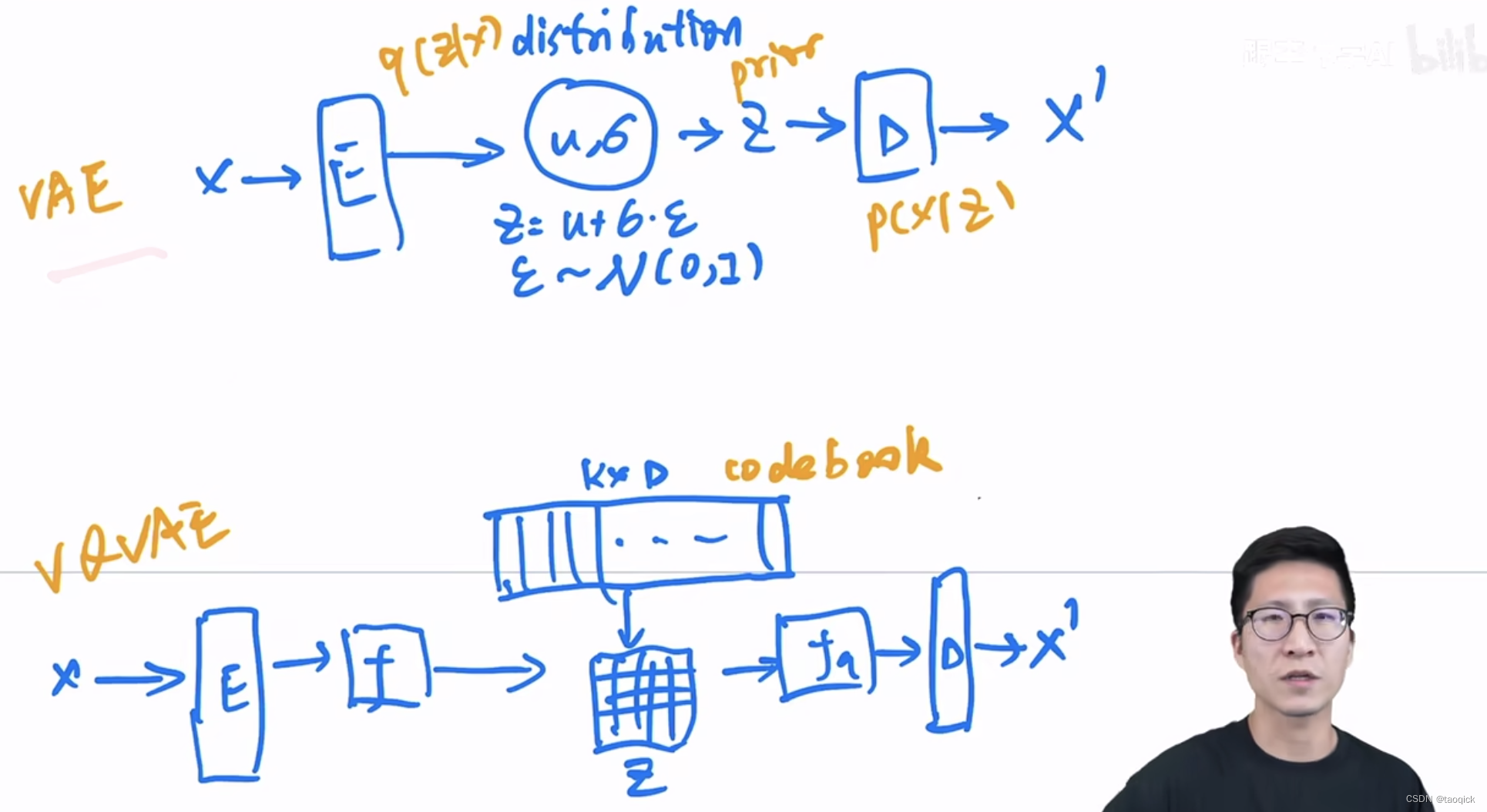
VQ-VAE(vector quantize)
把VAE的distribution的离散化成一个codebook(K*D,K一般是8192个聚类中心,D是512或者768), Beit也用了VQ-VAE的codebook。
VQ-VAE2
层级式
DALL·E 2
DALL·E 2本身来自于Hierarchical Text-Conditional Image Generation with CLIP Latents这篇,DALL·E 2一句话说就是prior(CLIP)+decoder(GLIDE)。CLIP不过多说了,GLIDE后面展开了很多细节
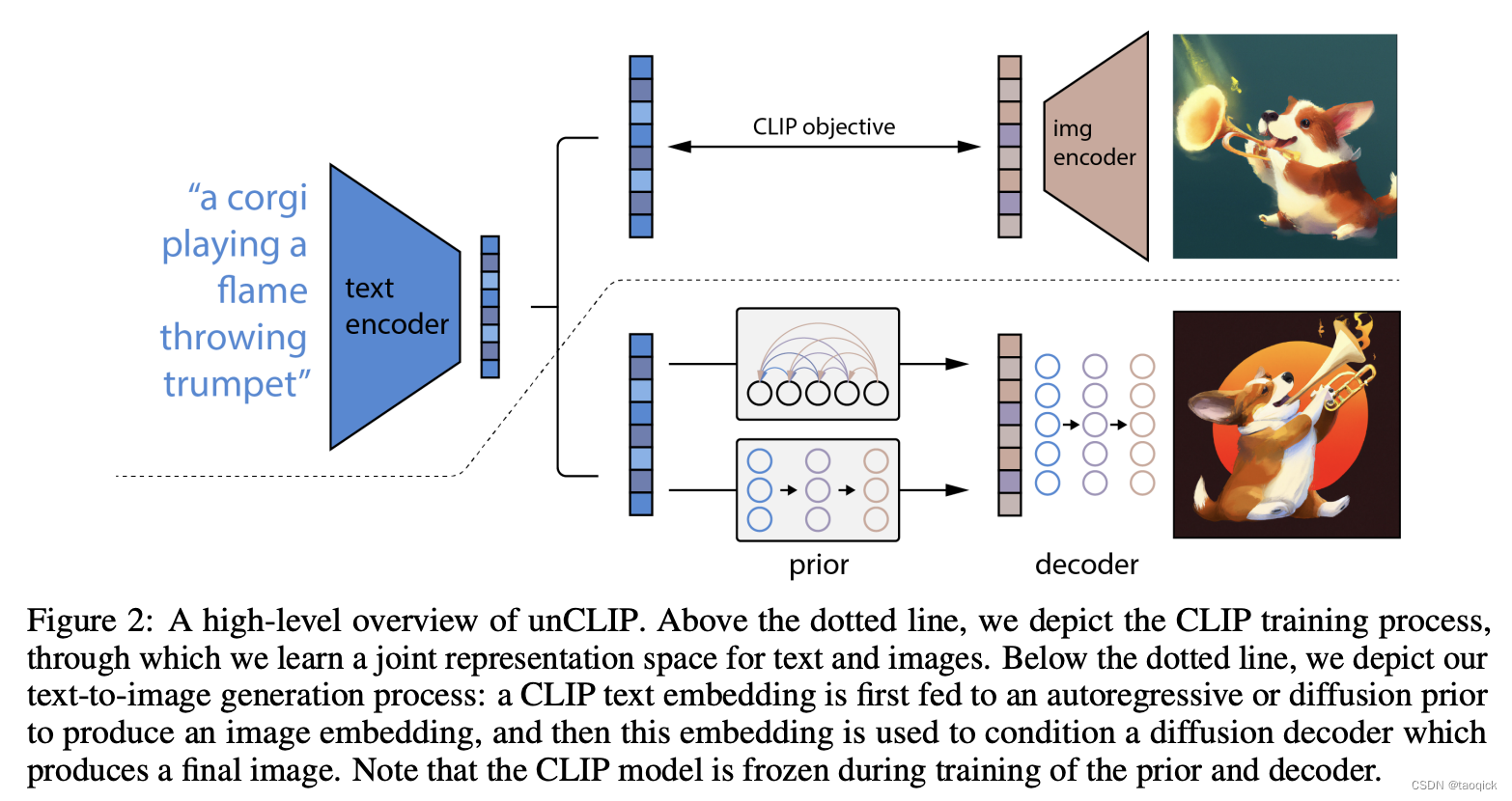
这篇里面的技术细节实际上比较少,感觉Yi Zhu老师在视频中最快速地普及了相关背景,后面也是沿着这个思路做了一些笔记:
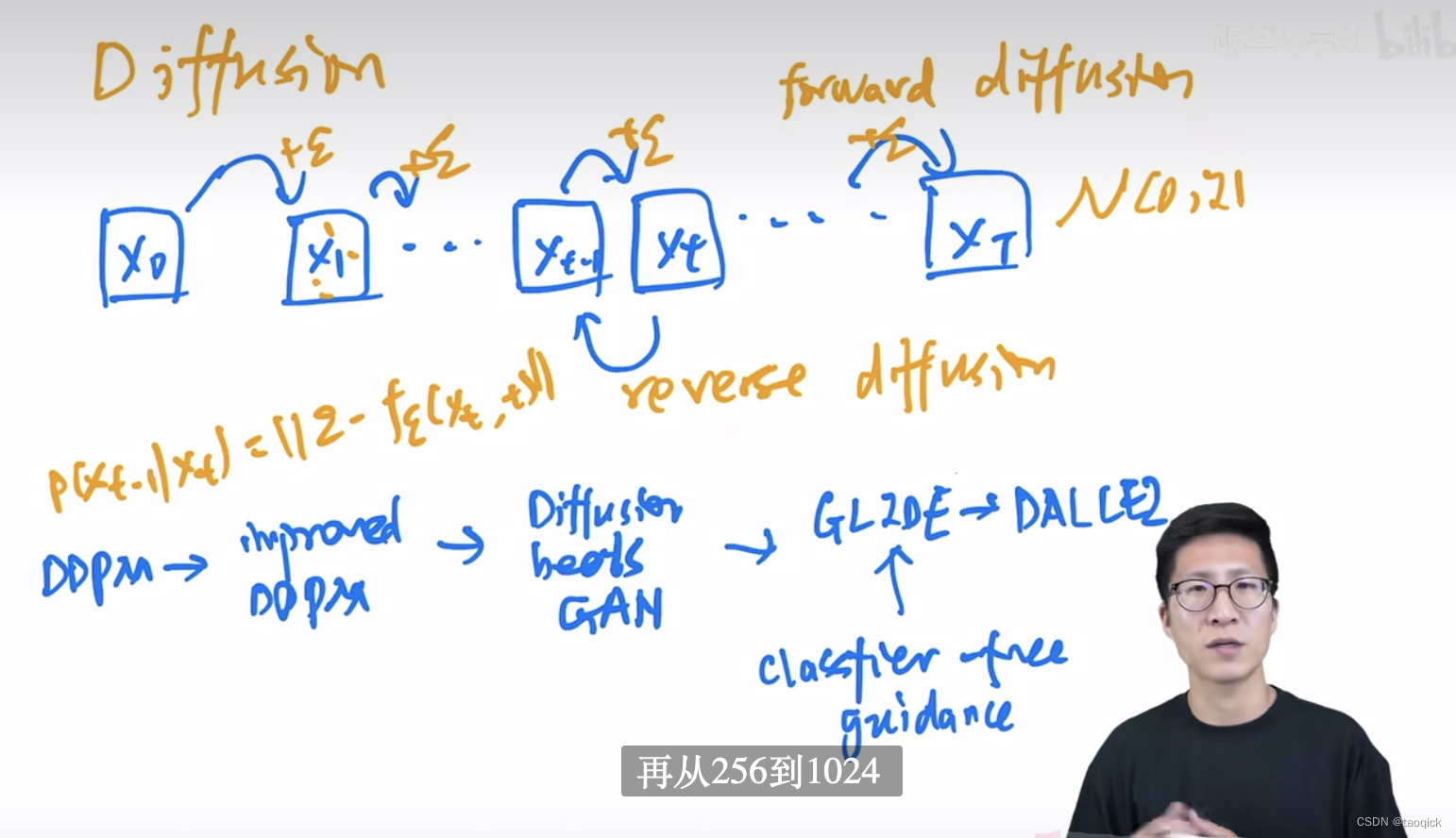
DDPM(Denoising Diffusion Probabilistic Model)
DDPM来自于Denoising Diffusion Probabilistic Model 20年这篇paper把它在高分辨率图像生成上调试出来了,从而引导出了后面的火热,其实早在15年Deep Unsupervised Learning using Nonequilibrium Thermodynamics这篇里数学推导基本有了,DDPM里有几个要点:
- 文章中提到的
β
1
,
.
.
.
,
β
T
\beta_1,...,\beta_T
β1,...,βT是方差,想预测reverse process(
x
0
x_0
x0是高清图像)中q的变化需要用到重采样技巧,需要预测均值和方差即可。而根据之前Deep Unsupervised Learning using Nonequilibrium Thermodynamics中的推导,预测均值即可,方差都不用了

- 想要预测reverse process中
q
(
x
t
∣
x
t
−
1
)
q(x_t|x_{t-1})
q(xt∣xt−1)预测它们之间的残差就够了,经过推导目标函数长成下图这样:

- 同时强调的一点,DDPM在预测残差 ϵ \epsilon ϵ中会引入time embedding,也就是恢复前期生成大致轮廓,后期生成细节。但是DDPM的部署和训练过程中需要多轮很慢很贵。 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)的backbone经常采用类似于Unet的结构
Improved DDPM
Improved DDPM来自于OpenAI的Improved Denoising Diffusion Probabilistic Models,几个要点:
- 均值和方差都预测一下效果会更好(原文中3.1. Learning Σθ(xt, t))
- 线性的schedule换成余弦的schedule(原文中3.2. Improving the Noise schedule)
- DDPM在scale后效果比较好
DENOISING DIFFUSION IMPLICIT MODELS,这个工作后面叫DDIM
这篇没有细看,从摘要看简单来说就是把采样过程给加速了,下面截图来自文章:

Diffusion Models Beat GANs on Image Synthesis
这也是发现DDPM在scale后效果后比较好OpenAI继续加大投入,这篇里面管自己的模型叫做ADM(ablated diffusion model):ADM refers to our ablated diffusion model, and ADM-G additionally uses classifier guidance;For upsampling, we use the upsampling stack from Nichol and Dhariwal [43] combined with our architecture improvements, which we refer to as ADM-U,几个要点:
- 模型变大变复杂,we match
BigGAN-deep even with as few as 25 forward passes per sample - Adaptive Group Normalization,We also experiment with a layer [43] that we refer to as adaptive group normalization (AdaGN), which incorporates the timestep and class embedding into each residual block after a group normalization operation [69], similar to adaptive instance norm [27] and FiLM [48].
- 这篇里面用了Classifier Guidance,Classifier Guidance的细节下面说
Classifier Guidance
Classifier Guidance这篇出现前diffusion model的在IS(Inception Score)和FID(Frechet lnception Distance)上的分数比不过GAN,Classifier Guidance的出现改变了这个局面,先来写写IS和FID的定义:
- IS(Inception Score):IS 实际上是在做一个 KL 散度计算,具体公式为
I S ( G ) = e x p ( E x − p g ( x ) K L ( p ( y ∣ x ) ∣ ∣ p ( y ) ) ) IS(G)=exp(E_{x-p_g(x)}KL(p(y|x)||p(y))) IS(G)=exp(Ex−pg(x)KL(p(y∣x)∣∣p(y)))其中, p ( y ∣ x ) p(y|x) p(y∣x)是指对一张给定的生成图像x,将其输入预训练好的Inception-v3 分类网络后输出的类别概率, p ( y ) p(y) p(y)则是边缘分布,表示对于所有的生成图像来说,这个预训练好的分类网络输出的类别的概率的期望。如果生成图像中包含有意义且清晰可辨认的目标,则分类网络应该以很高的置信度将该图像判定为一个特定的类别,所以 p ( y ∣ x ) p(y|x) p(y∣x)应该具有较小的。如果p(y)的熵较大,p(y|x)熵较小,即所生成的图像包含了非常多的类别,而每一张图像的类别又明确且置信度离,此时p(y|x)与p(y)的 KL 散度很大。可以看出,IS并没有将真实样本与生成样本进行比较,它仅在量化生成样本的质量和多样性。 - FID(Frechet lnception Distance):加入了真实样本与生成样本的比较它同样是将生成样本输入到分类网络中,不同的是,FID 不是对网络最后一层的输出概率P(y|x)进行操作,而是对网络倒数第二层的响应即特征图进行操作。具体来说,FID 是通过比较真实样本和生成样本的特征图的均值和方差来计算的
- sFID: 在FID度量中增加spatial信息,除了标准FID引入的最后一层pooling之外,还额外引入了前边的7层conv的feature map来计算mean和covariance。
继续回到Classifier Guidance这个方法,这里其实是通过牺牲一部分图片的多样性来换取真实性。这里的guidance一般是一个在imagenet上预训练好的分类器,这个分类器的梯度刚好暗含了是否包含某类物体,具体来说,对于DDPM是把梯度加到了均值上;对于DDIM是把梯度加在了残差
ϵ
\epsilon
ϵ上,下图来自Diffusion Models Beat GANs on Image Synthesis:

CLASSIFIER-FREE DIFFUSION GUIDANCE
这篇的改进顾名思义,把Classifier Guidance里的Classifier通过有没有y:这里的y就表示guidance的信号,原来是个classifier,现在换成有这个文本就是y,没有这个文本就是空,来学这种距离。好处当然是摆脱了分类器限制,但缺点是有没有这个条件增加了forward的成本

GLIDE (Guided Language to Image Diffusion for Generation and Editing)
Glide来自于GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models这篇,有了上面那堆铺垫才能理解这篇,无非是把ADM改进成了Classifier Free Guidance,也就是摘要里提的 CLIP guidance and classifier-free guidance,重点关注下Guidance是怎么加进去的,直接看文中2.4部分即可:

文本经过transformer输出一组embedding后,进入ADM模型需要通过两条路径,一条是经过AdaGN进入ADM,另一条是进入concat到ADM的attention context中。这里的
f
(
x
t
)
f(x_t)
f(xt)是CLIP image encoder,
g
(
c
)
g(c)
g(c) 是CLIP text encoder。其中的 s 称作guidance scale(非常重要)。为什么对均值更新做改造就可以引入CLIP来guide,需要参考Diffusion Models Beat GANs on Image Synthesis的4.1章,需要一些公式推导,它的物理意义是在逐步采样过程中,多往caption和图像匹配值大的方向走,少往不一致的方向走。就这个物理意义而言,其实有很多别的实现方式。
Stable Diffusion原理
来自于High-Resolution Image Synthesis with Latent Diffusion Models(https://ommer-lab.com/research/latent-diffusion-models/),Stable diffusion更像是商品名称,Latent diffusion更接近算法方案的描述,这俩说的是一个东西。
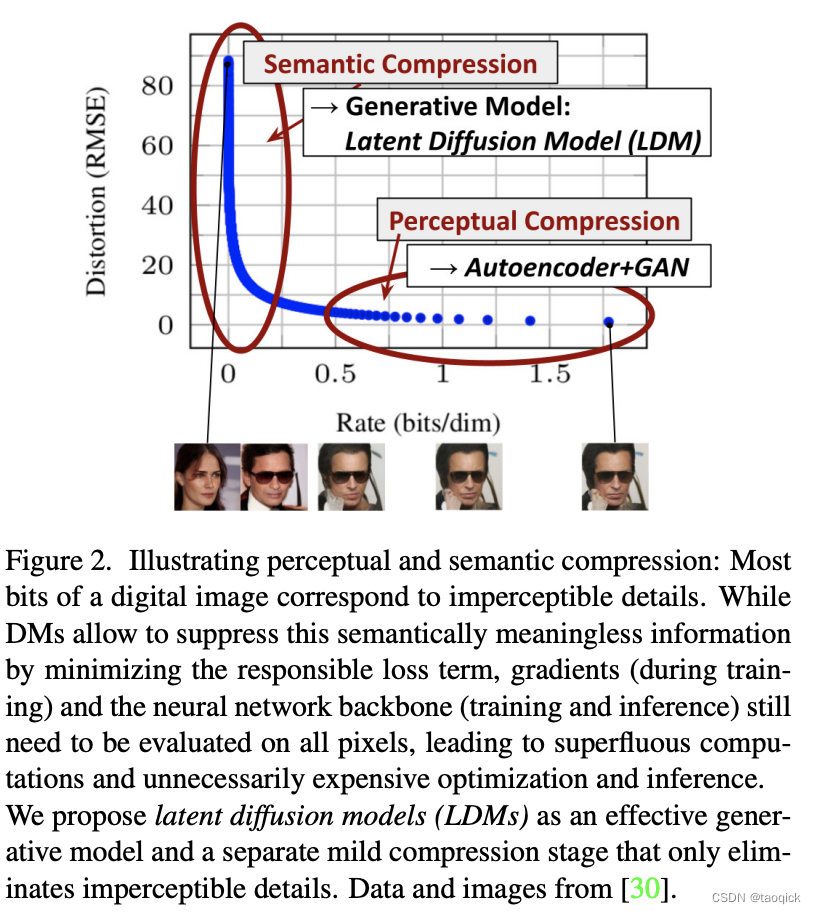
对于diffusion模型,在图像上的forward diffusion过程和reverse学习过程的计算量很大,而大部分的计算是花在了对于语义和感知影响不大的像素上。用在图像冗余信息的计算是可以被节省的。Latent diffusion模型的就是按照这个思路,先通过encoder来将图片变换到latent space,只保留语义信息,感知信息通过引入encoder/decoder来学习和压缩。即diffusion模型在stable diffusion中只处理低维的、强语义信息、低冗余的数据。对latent使用denoising diffusion模型来建模生成过程,并在denoising过程中通过attention机制引入用于指导生成内容的文本、图像等信息。整体目标函数如下图:

模型的实现包含了三个子模型,分别对应
- 图像像素空间到latent空间转化的AutoencoderKL
- latent空间中的Denoising UNetModel
- 引入文本prompt特征的FrozenOpenCLIPEmbedder
下面对代码进行一些分析
AutoencoderKL
使用https://huggingface.co/stabilityai/stable-diffusion-2的参数,对几个样例图像做encode和decode的结果,会发现decode后和原始图像非常接近。这部分代码在https://github.com/Stability-AI/stablediffusion/blob/main/ldm/models/autoencoder.py#L13
Denoising Unet
UNet中的prompt 特征的引入使用了cross attention,代码在https://github.com/Stability-AI/stablediffusion/blob/main/ldm/modules/diffusionmodules/openaimodel.py#L277。参考原文中的描述,y就是文本,KV就是文本学到的intermediate layers,用Q对应的UNet embedding来去找KV

Prompt的encoding
文中采用了ViT-H/14 on LAION-2B的embedding,文本的embedding tensor是高维的(77*1024),并没有清晰的图像语义信息,描述的语义相近的文本的embedding l2距离并不一定相近
笔记参考了以下信息
- 【DALL·E 2(内含扩散模型介绍)【论文精读】】https://www.bilibili.com/video/BV17r4y1u77B?vd_source=e260233b721e72ff23328d5f4188b304
- https://kexue.fm/archives/9119
- Denoising Diffusion Probabilistic Models
- Improved Denoising Diffusion Probabilistic Models
- Hulu书
- GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
- Stable Diffusion:High-Resolution Image Synthesis with Latent Diffusion Models


![[ICML 2023] Fast inference from transformers via speculative decoding](https://img-blog.csdnimg.cn/e83aeef2f1ba4045a47f3ab465a685b4.png#pic_center)