paper:CrossKD: Cross-Head Knowledge Distillation for Dense Object Detection
official implementation: https://github.com/jbwang1997/CrossKD
前言
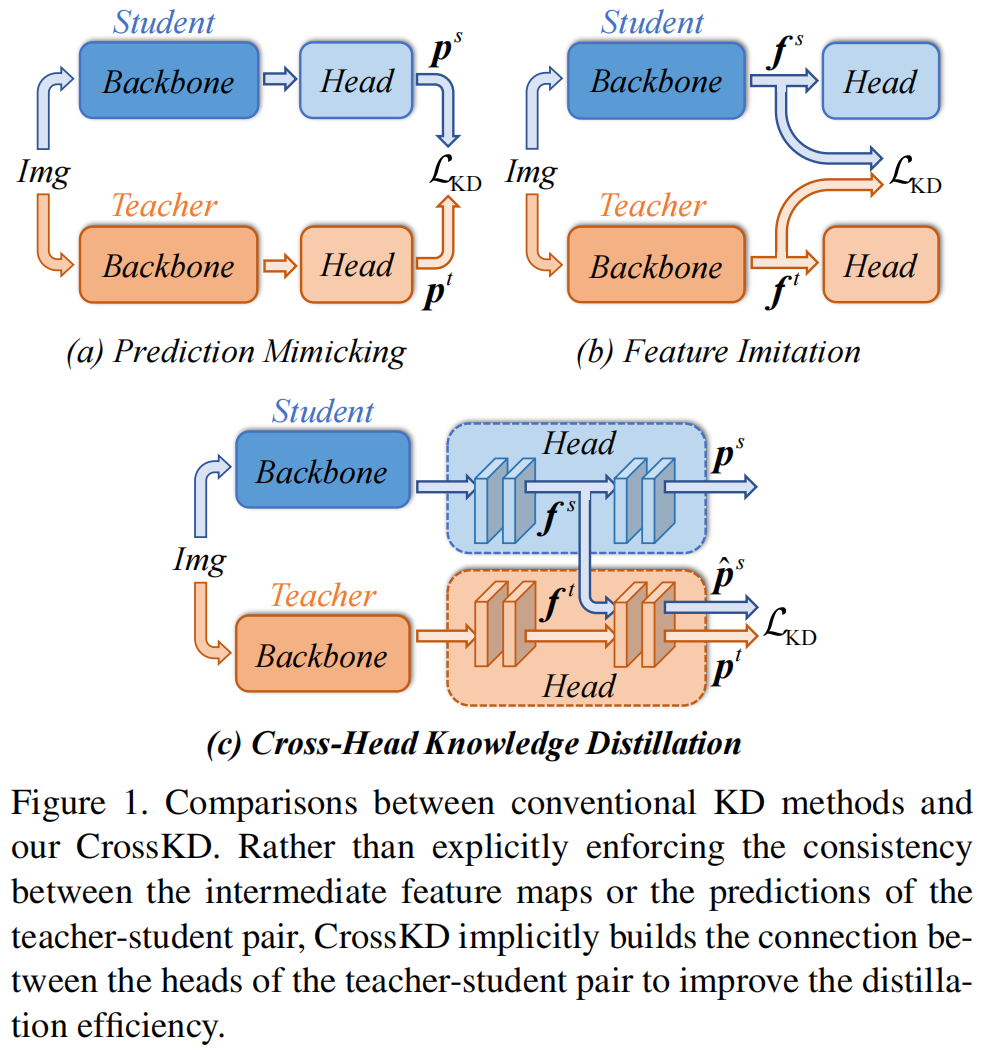
蒸馏可以分为预测蒸馏prediction mimicking和特征蒸馏feature imitation两种,2015年Geoffrey Hinton提出的KD知识蒸馏开山之作KD:Distilling the Knowledge in a Neural Network 原理与代码解析属于预测模拟,而FitNets: Hints for Thin Deep Nets 原理与代码解析就属于典型的特征模拟。然而长期以来,大家发现预测模拟相比于特征模拟更加低效,LD for Dense Object Detection(CVPR 2022)原理与代码解析表明,预测模拟具有转移特定任务知识的能力,这有利于学生同时进行预测模拟和特征模拟。这促使作者进一步探索和改进预测模拟。
本文的创新点
在预测模拟中,学生模型的预测需要同时模拟GT和教师模型的预测,但是教师模型的预测常常会和GT有很大的差异,学生模型在蒸馏过程中经历了一个矛盾的学习过程,作者认为这是阻碍预测模型获得更高性能的主要原因。
为了缓解学习目标冲突的问题,本文提出了一种新的蒸馏方法CrossKD,将学生检测头的中间特征送入教师的检测头,得到的预测结果与教师的原始预测结果进行蒸馏,这种方法有两个好处,首先KD损失不影响学生检测头的权重更新,避免了原始检测损失和KD损失的冲突。此外由于交叉头的预测和教师的预测共享了部分教师的检测头,两者的预测相对一致,缓解了学生-教师之间的预测差异,提高了预测模拟的训练稳定性。
预测模拟、特征模拟以及本文提出的cross kd分别为图1的(a)(b)(c)所示
方法介绍
CrossKD的整体架构如图3所示
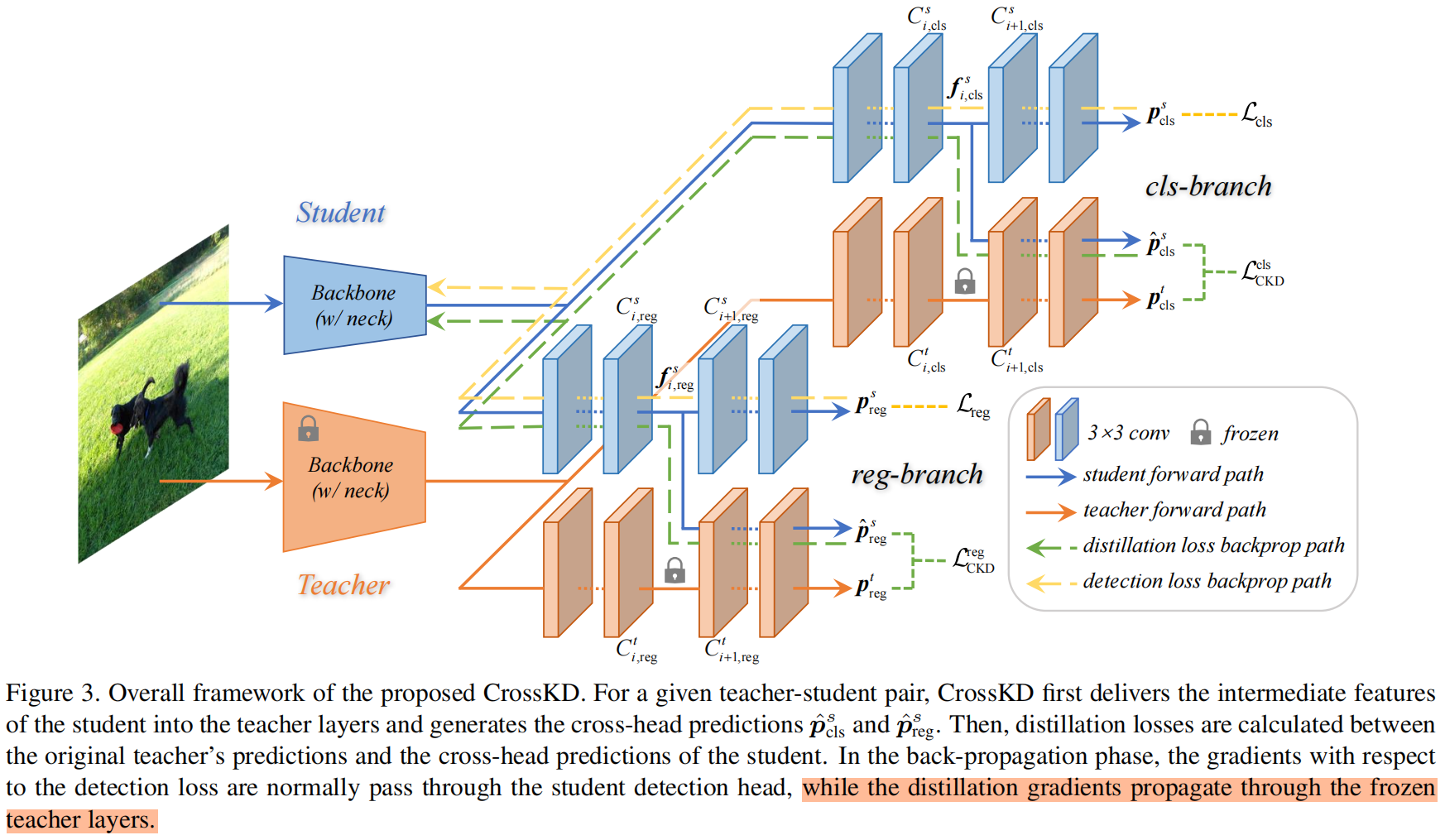
给定一个dense detector比如RetinaNet,每个检测head通常由一系列卷积组成,表示为 \(\left \{ C_{i} \right \} \)。为了简便,我们假设每个检测头共有 \(n\) 个卷积层,(比如RetinaNet中n=5,包括4个隐含层和1个预测层)。我们用 \(f_{i},i\in\left \{ 1,2,...,n-1 \right \} \) 来表示 \(C_{i}\) 的输出特征图,\(f_{0}\) 表示 \(C_{1}\) 的输出特征图。预测 \(p\) 是由最后一个卷积层 \(C_{n}\) 的输出,教师和学生的最终预测结果可以分别表示为 \(p^{t},p^{s}\)。
CrossKD将学生检测头的中间特征 \(f_{i}^{s},i\in\left \{ 1,2,...,n-1 \right \} \) 送入 \(C^{t}_{i+1}\),即教师检测头的第 \((i+1)\) 个卷积层,得到交叉头的预测 \(\hat{p}^{s}\)。和之前的方法不同,我们不计算 \(p^{s}\) 和 \(p^{t}\) 之间的KD损失,而是计算 \(\hat{p}^{s}\) 和 \(p^{t}\) 之间的KD损失,如下

其中 \(\mathcal{S}(\cdot)\) 和 \(|\mathcal{S}|\) 分别是region selection principle和归一化因子。本文作者没有涉及复杂的 \(\mathcal{S}(\cdot)\),分类分支 \(\mathcal{S}(\cdot)\) 是常量值1,回归分支前景区域 \(\mathcal{S}(\cdot)\) 为1背景区域 \(\mathcal{S}(\cdot)\) 为0。
实验结果
首先是一些消融实验,教师网络采用ResNet-50+GFL,学生网络为ResNet-18。
Positions to apply CrossKD.
上面说过将学生检测头的第 \(i\) 个卷积层的输出送入教师网络,这里作者比较了不同 \(i\) 的值对最终结果的影响,当 \(i=0\) 时表示直接将FPN的输出特征送入教师网络的head,具体结果如下
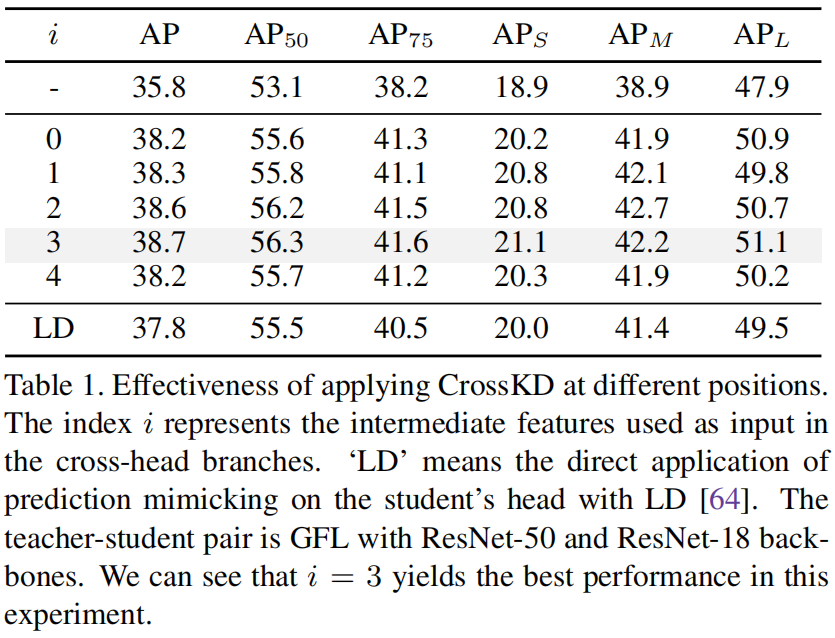
可以看出当 \(i=3\) 时, 模型的最终精度最高,因此后续实验都采用默认配置 \(i=3\)。
CrossKD v.s. Feature Imitation.
作者对比了CrossKD和特征蒸馏的SOTA方法PKD,为了公平起见,与CrossKD相同的位置上执行PKD,包括 \(i=0\) 的neck和 \(i=3\) 的head,结果如下
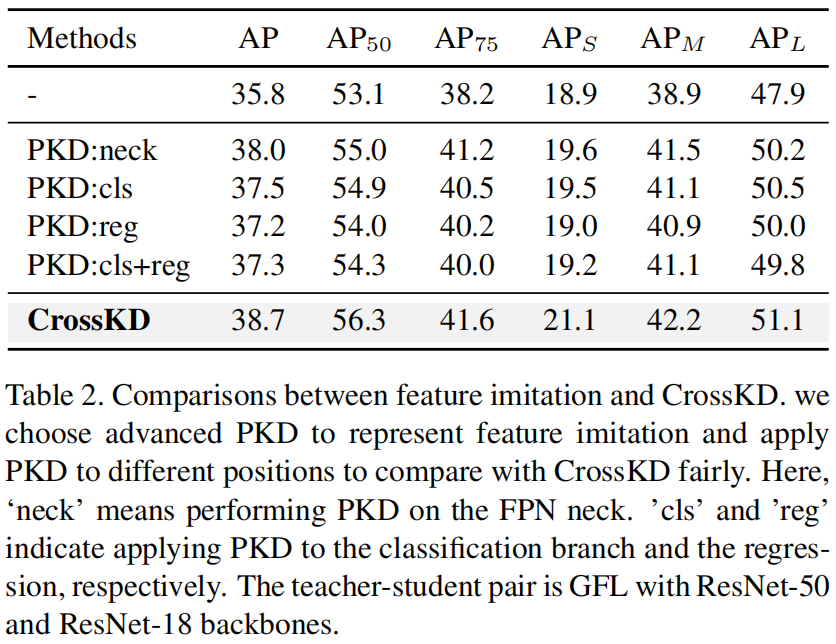
可以看出,无论PKD在什么位置,效果都不如CrossKD。
CrossKD for Lightweight Detectors.
作者将CrossKD轻量的检测器上的结果如下
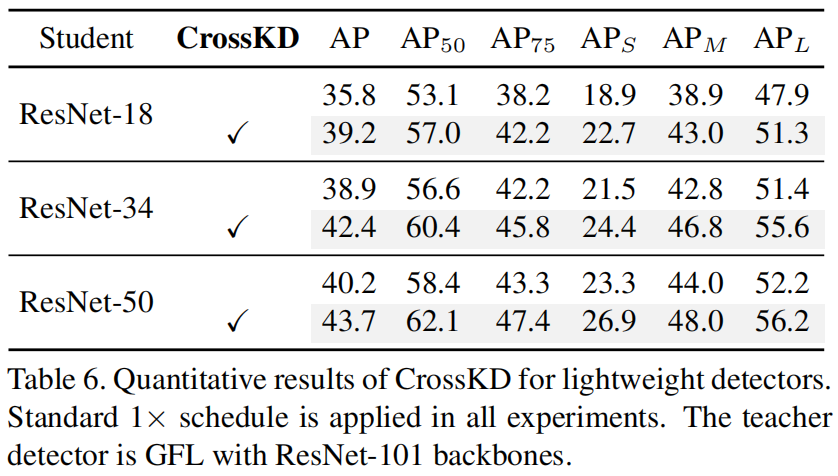
可以看出,教师网络为ResNet-101+GFL,学生网络为ResNet-50、ResNet-34、ResNet-18,CrossKD都可以显著提升精度。
Comparison with SOTA KD Methods
和其它目标检测的SOTA蒸馏方法的对别如下表,可以看出,CrossKD优于现有的所有方法。

代码解析
官方的实现是基于mmdetection,并将crosskd用到了atss、fcos、gfl、retinanet中,以atss为例,代码在mmdet/models/detectors/crosskd_atss.py中,loss部分代码如下。首先原始输入 batch_inputs分别经过教师和学生的backbone和neck,self.teacher_extract_feat就是教师网络的backbone和neck,self.extract_feat就是学生网络的backbone和neck。
def loss(self, batch_inputs: Tensor,
batch_data_samples: SampleList) -> Union[dict, list]:
"""Calculate losses from a batch of inputs and data samples.
Args:
batch_inputs (Tensor): Input images of shape (N, C, H, W).
These should usually be mean centered and std scaled.
batch_data_samples (list[:obj:`DetDataSample`]): The batch
data samples. It usually includes information such
as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
Returns:
dict: A dictionary of loss components.
"""
tea_x = self.teacher.extract_feat(batch_inputs)
tea_cls_scores, tea_bbox_preds, tea_centernesses, tea_cls_hold, tea_reg_hold = \
multi_apply(self.forward_hkd_single,
tea_x,
self.teacher.bbox_head.scales,
module=self.teacher)
stu_x = self.extract_feat(batch_inputs)
stu_cls_scores, stu_bbox_preds, stu_centernesses, stu_cls_hold, stu_reg_hold = \
multi_apply(self.forward_hkd_single,
stu_x,
self.bbox_head.scales,
module=self)
reused_cls_scores, reused_bbox_preds, reused_centernesses = multi_apply(
self.reuse_teacher_head,
tea_cls_hold,
tea_reg_hold,
stu_cls_hold,
stu_reg_hold,
self.teacher.bbox_head.scales)
outputs = unpack_gt_instances(batch_data_samples)
(batch_gt_instances, batch_gt_instances_ignore,
batch_img_metas) = outputs
losses = self.loss_by_feat(tea_cls_scores,
tea_bbox_preds,
tea_centernesses,
tea_x,
stu_cls_scores,
stu_bbox_preds,
stu_centernesses,
stu_x,
reused_cls_scores,
reused_bbox_preds,
reused_centernesses,
batch_gt_instances,
batch_img_metas,
batch_gt_instances_ignore)
return losses得到的neck输出特征tea_x和stu_x,然后分别进入函数self.forward_hkd_single,实现如下
def forward_hkd_single(self, x, scale, module):
cls_feat, reg_feat = x, x
cls_feat_hold, reg_feat_hold = x, x
for i, cls_conv in enumerate(module.bbox_head.cls_convs):
cls_feat = cls_conv(cls_feat, activate=False)
if i + 1 == self.reused_teacher_head_idx:
cls_feat_hold = cls_feat
cls_feat = cls_conv.activate(cls_feat)
for i, reg_conv in enumerate(module.bbox_head.reg_convs):
reg_feat = reg_conv(reg_feat, activate=False)
if i + 1 == self.reused_teacher_head_idx:
reg_feat_hold = reg_feat
reg_feat = reg_conv.activate(reg_feat)
cls_score = module.bbox_head.atss_cls(cls_feat)
bbox_pred = scale(module.bbox_head.atss_reg(reg_feat)).float()
centerness = module.bbox_head.atss_centerness(reg_feat)
return cls_score, bbox_pred, centerness, cls_feat_hold, reg_feat_hold其中分别经过教师和学生的head,包括cls分支和reg分支,self.reused_teacher_head_idx就是学生head中要送入教师的检测头的特征的索引,将这个位置的特征保存下来后续送入教师head,即函数reuse_teacher_head。
def reuse_teacher_head(self, tea_cls_feat, tea_reg_feat, stu_cls_feat,
stu_reg_feat, scale):
reused_cls_feat = self.align_scale(stu_cls_feat, tea_cls_feat)
reused_reg_feat = self.align_scale(stu_reg_feat, tea_reg_feat)
if self.reused_teacher_head_idx != 0:
reused_cls_feat = F.relu(reused_cls_feat)
reused_reg_feat = F.relu(reused_reg_feat)
module = self.teacher.bbox_head
for i in range(self.reused_teacher_head_idx, module.stacked_convs):
reused_cls_feat = module.cls_convs[i](reused_cls_feat)
reused_reg_feat = module.reg_convs[i](reused_reg_feat)
reused_cls_score = module.atss_cls(reused_cls_feat)
reused_bbox_pred = scale(module.atss_reg(reused_reg_feat)).float()
reused_centerness = module.atss_centerness(reused_reg_feat)
return reused_cls_score, reused_bbox_pred, reused_centerness注意这里有个align_scale的步骤,论文中没有提及,即将学生head的特征减去均值除以方差后,再乘以教师head对应位置特征的方差接着再加上教师特征的均值,如下
def align_scale(self, stu_feat, tea_feat):
N, C, H, W = stu_feat.size()
# normalize student feature
stu_feat = stu_feat.permute(1, 0, 2, 3).reshape(C, -1)
stu_mean = stu_feat.mean(dim=-1, keepdim=True)
stu_std = stu_feat.std(dim=-1, keepdim=True)
stu_feat = (stu_feat - stu_mean) / (stu_std + 1e-6)
#
tea_feat = tea_feat.permute(1, 0, 2, 3).reshape(C, -1)
tea_mean = tea_feat.mean(dim=-1, keepdim=True)
tea_std = tea_feat.std(dim=-1, keepdim=True)
stu_feat = stu_feat * tea_std + tea_mean
return stu_feat.reshape(C, N, H, W).permute(1, 0, 2, 3)



![[ICML 2023] Fast inference from transformers via speculative decoding](https://img-blog.csdnimg.cn/e83aeef2f1ba4045a47f3ab465a685b4.png#pic_center)