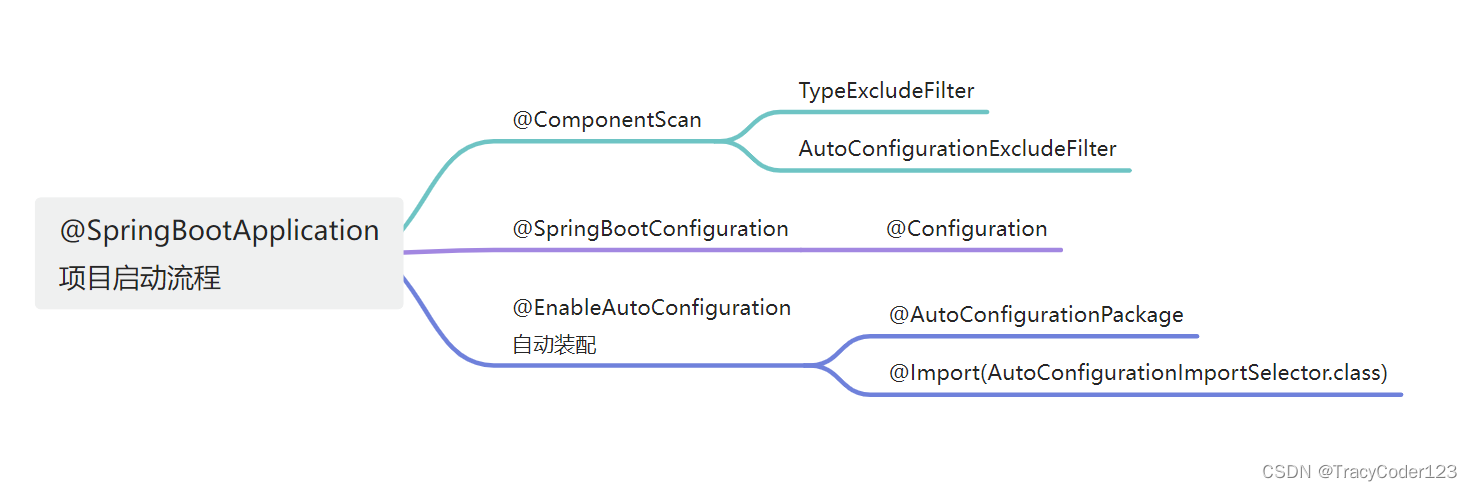
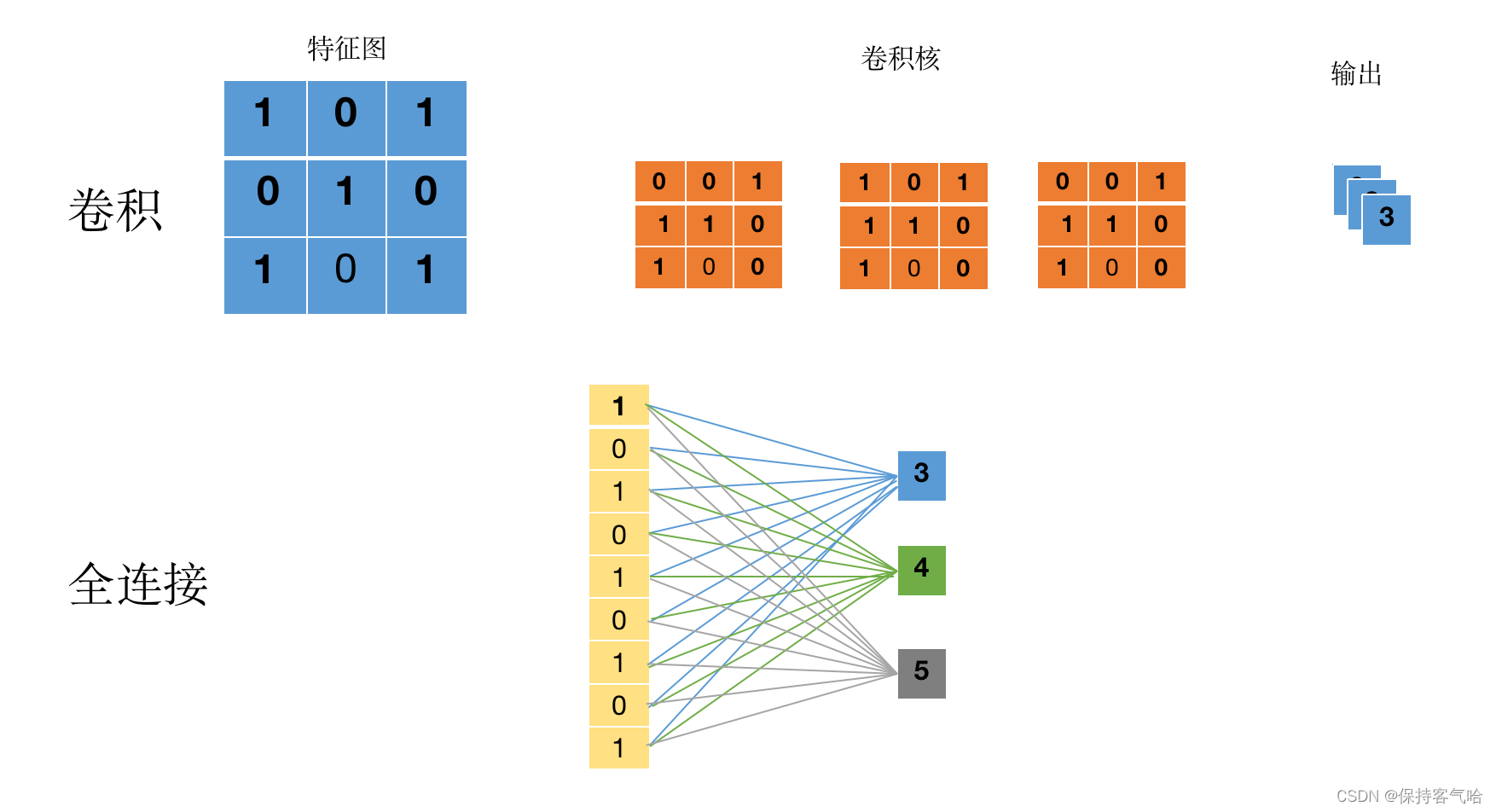
神经网络的数据存储中都使用张量(Tensor),那张量又是什么呢?
py 张量这一概念的核心在于,它是一个数据容器。它包含的数据几乎总是数值数据,因此它是数字的容器。你可能对矩阵很熟悉,它是二维张量。张量是矩阵向任意维度的推广[注意,张量的维度(dimension)通常叫作轴(axis)]。
一阶张量可以理解为一个向量,二阶张量可以理解为矩阵,三阶张量可以理解成立方体,四阶张量可以理解成立方体组成的一个向量,五阶张量可以理解成立方体组成的矩阵,依次类推。
1.1 标量(0D 张量)
仅包含一个数字的张量叫作标量(scalar,也叫标量张量、零维张量、0D 张量)。在 Numpy中,一个 float32 或 float64 的数字就是一个标量张量(或标量数组)。你可以用 ndim 属性来查看一个 Numpy 张量的轴的个数。标量张量有 0 个轴( ndim == 0 )。张量轴的个数也叫作阶(rank)。下面是一个 Numpy 标量。
import numpy as np
x = np.array(12)
print(x.ndim)
x
结果:
- 0
- array(12)
1.2 向量(1D 张量)
数字组成的数组叫作向量(vector)或一维张量(1D 张量)。一维张量只有一个轴。下面是一个 Numpy 向量。
import numpy as np
x = np.array([12, 3, 6, 14, 7])
print(x.ndim)
x
结果:
- 1
- array([12, 3, 6, 14, 7])
注意:这个向量有 5 个元素,所以被称为 5D 向量。不要把 5D 向量和 5D 张量弄混! 5D 向量只有一个轴,沿着轴有 5 个维度,而 5D 张量有 5 个轴(沿着每个轴可能有任意个维度)。维度(dimensionality)可以表示沿着某个轴上的元素个数(比如 5D 向量),也可以表示张量中轴的个数(比如 5D 张量),这有时会令人感到混乱。对于后一种情况,技术上更准确的说法是 5 阶张量(张量的阶数即轴的个数),但 5D 张量这种模糊的写法更常见。
1.3 矩阵(2D 张量)
向量组成的数组叫作矩阵(matrix)或二维张量(2D 张量)。矩阵有 2 个轴(通常叫作行和列)。你可以将矩阵直观地理解为数字组成的矩形网格。下面是一个 Numpy 矩阵。
import numpy as np
x = np.array([[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])
print(x.ndim)
结果:
- 2
1.4 3D 张量与更高维张量
将多个矩阵组合成一个新的数组,可以得到一个 3D 张量,你可以将其直观地理解为数字组成的立方体。下面是一个 Numpy 的 3D 张量。
import numpy as np
x = np.array([[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]]])
print(x.ndim)
结果:
- 3
将多个 3D 张量组合成一个数组,可以创建一个 4D 张量,以此类推。深度学习处理的一般是 0D 到 4D 的张量,但处理视频数据时可能会遇到 5D 张量。
1.5 关键属性
张量是由以下三个关键属性来定义的。
- 轴的个数(阶)。例如,3D 张量有 3 个轴,矩阵有 2 个轴。这在 Numpy 等 Python 库中也叫张量的 ndim 。
- 形状。这是一个整数元组,表示张量沿每个轴的维度大小(元素个数)。例如,前面矩阵示例的形状为 (3, 5) ,3D 张量示例的形状为 (3, 3, 5) 。向量的形状只包含一个元素,比如 (5,) ,而标量的形状为空,即 () 。(张量的形状)
- 数据类型(在 Python 库中通常叫作 dtype )。这是张量中所包含数据的类型,例如,张量的类型可以是 float32 、 uint8 、 float64 等。在极少数情况下,你可能会遇到字符( char )张量。==注意:==Numpy(以及大多数其他库)中不存在字符串张量,因为张量存储在预先分配的连续内存段中,而字符串的长度是可变的,无法用这种方式存储。
1.6 现实世界中的数据张量
我们用几个你未来会遇到的示例来具体介绍数据张量。你需要处理的数据几乎总是以下类别之一。
- 向量数据:2D 张量,形状为 (samples, features) 。
- 时间序列数据或序列数据:3D 张量,形状为 (samples, timesteps, features) 。
- 图像:4D张量,形状为 (samples, height, width, channels) 或 (samples, channels,height, width) 。
- 视频:5D张量,形状为 (samples, frames, height, width, channels) 或 (samples,frames, channels, height, width) 。
栗子 :
1.向量数据
这是最常见的数据。对于这种数据集,每个数据点都被编码为一个向量,因此一个数据批量就被编码为 2D 张量(即向量组成的数组),其中第一个轴是样本轴,第二个轴是特征轴。
我们来看两个例子:
- 人口统计数据集,其中包括每个人的年龄、邮编和收入。每个人可以表示为包含 3 个值的向量,而整个数据集包含 100 000 个人,因此可以存储在形状为 (100000, 3) 的 2D张量中。
- 文本文档数据集,我们将每个文档表示为每个单词在其中出现的次数(字典中包含20 000 个常见单词)。每个文档可以被编码为包含 20 000 个值的向量(每个值对应于字典中每个单词的出现次数),整个数据集包含 500 个文档,因此可以存储在形状为(500, 20000) 的张量中。
2.时间序列数据或序列数据
当时间(或序列顺序)对于数据很重要时,应该将数据存储在带有时间轴的 3D 张量中。每个样本可以被编码为一个向量序列(即 2D 张量),因此一个数据批量就被编码为一个 3D 张量(见下图)
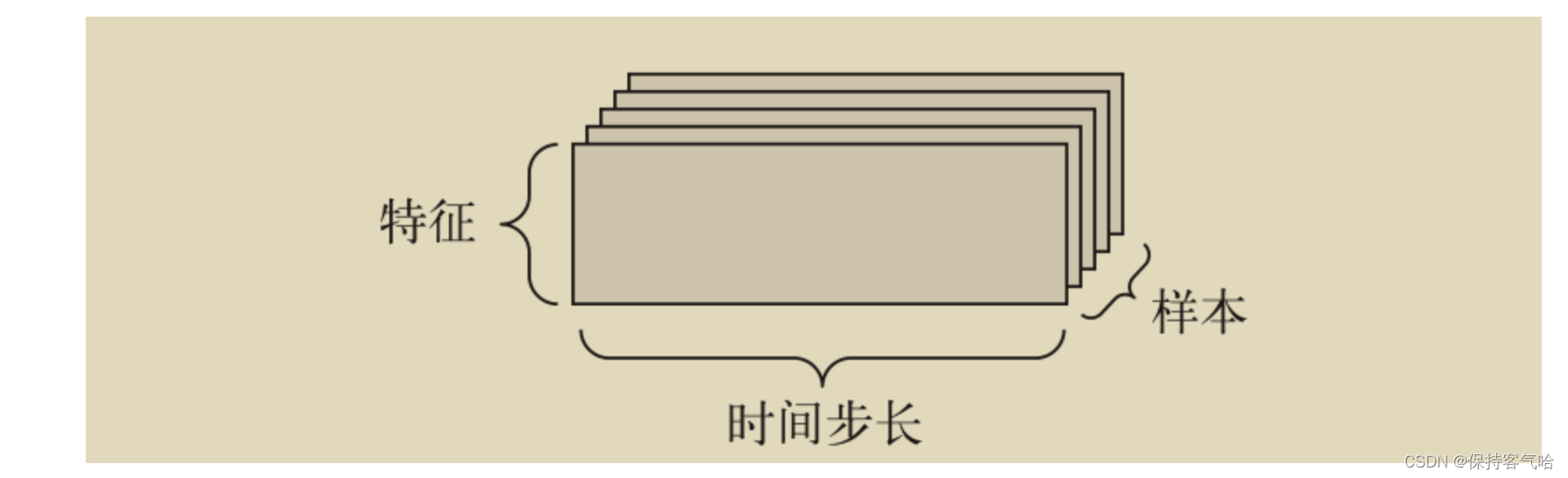
根据惯例,时间轴始终是第 2 个轴(索引为 1 的轴)。我们来看几个例子。
- 股票价格数据集。每一分钟,我们将股票的当前价格、前一分钟的最高价格和前一分钟的最低价格保存下来。因此每分钟被编码为一个 3D 向量,整个交易日被编码为一个形状为 (390, 3) 的 2D 张量(一个交易日有 390 分钟),而 250 天的数据则可以保存在一个形状为 (250, 390, 3) 的 3D 张量中。这里每个样本是一天的股票数据。
- 推文数据集。我们将每条推文编码为 280 个字符组成的序列,而每个字符又来自于 128个字符组成的字母表。在这种情况下,每个字符可以被编码为大小为 128 的二进制向量(只有在该字符对应的索引位置取值为 1,其他元素都为 0)。那么每条推文可以被编码为一个形状为 (280, 128) 的 2D 张量,而包含 100 万条推文的数据集则可以存储在一个形状为 (1000000, 280, 128) 的张量中。
3.图像数据
图像通常具有三个维度:高度、宽度和颜色深度。虽然灰度图像(比如 MNIST 数字图像)只有一个颜色通道,因此可以保存在 2D 张量中,但按照惯例,图像张量始终都是 3D 张量,灰度图像的彩色通道只有一维。因此,如果图像大小为 256×256,那么 128 张灰度图像组成的批量可以保存在一个形状为 (128, 256, 256, 1) 的张量中,而 128 张彩色图像组成的批量则可以保存在一个形状为 (128, 256, 256, 3) 的张量中。
像张量的形状有两种约定:通道在后(channels-last)的约定(在 TensorFlow 中使用)和通道在前(channels-first)的约定(在 Theano 中使用)。Google 的 TensorFlow 机器学习框架将颜色深度轴放在最后: (samples, height, width, color_depth) 。与此相反,Theano将图像深度轴放在批量轴之后: (samples, color_depth, height, width) 。如果采用 Theano 约定,前面的两个例子将变成 (128, 1, 256, 256) 和 (128, 3, 256, 256) 。Keras 框架同时支持这两种格式。
4.视频数据
视频数据是现实生活中需要用到 5D 张量的少数数据类型之一。视频可以看作一系列帧,每一帧都是一张彩色图像。由于每一帧都可以保存在一个形状为 (height, width, color_depth) 的 3D 张量中,因此一系列帧可以保存在一个形状为 (frames, height, width,color_depth) 的 4D 张量中,而不同视频组成的批量则可以保存在一个 5D 张量中,其形状为(samples, frames, height, width, color_depth) 。
举个例子,一个以每秒 4 帧采样的 60 秒 YouTube 视频片段,视频尺寸为 144×256,这个视频共有 240 帧。4 个这样的视频片段组成的批量将保存在形状为 (4, 240, 144, 256, 3)的张量中。总共有 106 168 320 个值!如果张量的数据类型( dtype )是 float32 ,每个值都是32 位,那么这个张量共有 405MB。好大!你在现实生活中遇到的视频要小得多,因为它们不以float32 格式存储,而且通常被大大压缩,比如 MPEG 格式。
张量的立体图:

1.7 torch中的tensor有关操作
在PyTorch中,torch.Tensor是存储和变换数据的主要工具。
Tensor与Numpy的多维数组非常相似。
Tensor还提供了GPU计算和自动求梯度等更多功能,这些使Tensor更适合深度学习。
1.7.1 tensor的创建
直接创建一个5*3的未初始化的Tensor:
x = torch.empty(5,3)
print(x)
output:
tensor([[-7.5439e-22, 1.6472e+25, 7.6232e-39],
[ 3.4438e-41, 0.0000e+00, 4.6566e-10],
[ 9.6121e-27, 2.0000e+00, 8.4078e-45],
[ 0.0000e+00, 1.1210e-44, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 3.3631e-44]])
创建一个5*3的随机初始化的Tensor
torch.rand:返回一个张量,包含了从区间[0,1)的均匀分布中抽取一组随机数,形状由可变参数size定义。
原型:
torch.rand(size,out=None,dtype=None,layout=torch.strided,device=None,
requires_grad=False)->Tensor
举例:
x = torch.rand(5,3)
print(x)
output:
tensor([[0.4982, 0.5067, 0.8433],
[0.2233, 0.0400, 0.7299],
[0.8650, 0.1319, 0.4268],
[0.2697, 0.3466, 0.0818],
[0.8822, 0.4286, 0.7233]])
torch.randn:返回一个张量,包含了从标准正态分布(Normal distribution)(均值为0,方差为1,即高斯白噪声)中抽取一组随机数,形状由可变参数sizes定义。
x = torch.randn(2,3)
print(x)
output:
tensor([[-0.7988, -1.9592, 0.4527],
[-1.4053, -2.1526, -0.1318]])
创建全为0的Tensor(指定数据类型)
x = torch.zeros(5,3,dtype=long)
print(x)
output:
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
根据数据直接创建
x = torch.tensor([5.5,3])
print(x)
output:
tensor([5.5000, 3.0000])
其余tensor的构造函数
Tensor(*sizes) 基础构造函数
ones(*sizes) 全1Tensor
zeros(*sizes) 全0Tensor
eye(*sizes) 对角线为1,其他为0
arange(s,e,step) 从s到e,步长为step
linespace(s,e,steps) 从s到e,均匀切分成steps份
normal(mean,std)/uniform(from,to) 正态分布/均匀分布
randperm(m) 随机排列
1.7.2 tensor的操作
Tensor的加法操作:
x = torch.rand(5, 3)
y = torch.rand(5, 3)
z = x + y
output:
tensor([[0.9107, 1.5307, 0.2904],
[0.9928, 0.3985, 0.6399],
[1.0703, 0.8709, 0.0269],
[0.5614, 0.4600, 0.1989],
[0.8026, 1.0747, 0.8526]])
加法形式二:
z=torch.add(x,y)
result = torch.empty(5, 3)
torch.add(x, y, out=result)
Tensor的索引操作:
我们还可以使用类似Numpy的索引操作来访问Tensor的一部分。需要注意的是:索引出来的结果与原数据共享内存,也即修改一个,另一个也会跟着修改。
x = torch.rand(5,3)
print(x)
y = x[0,:] # 逗号(,)前面的是行索引,代表起始位置是第一行,一直到第一行结束,逗号后面是列索引,代表第0列到最后一列
print(y)
y += 1
print(y)
print(x[0,:])
output:
tensor([[0.1120, 0.5599, 0.8453],
[0.6492, 0.0075, 0.5077],
[0.6824, 0.5775, 0.1888],
[0.3331, 0.4952, 0.3353],
[0.9872, 0.4524, 0.2140]])
tensor([0.1120, 0.5599, 0.8453])
tensor([1.1120, 1.5599, 1.8453])
tensor([1.1120, 1.5599, 1.8453])
1.7.3 tensor数据类型的转换
使用独立的函数如 int(),float()等进行转换
long_tensor = tensor.long()
features = features.float()
使用torch.type()函数
t2=t1.type(torch.FloatTensor)
1.7.4 Tensor的形状修改
用view()来改变Tensor的形状:
x = torch.rand(5, 3)
y = x.view(15)
print(y)
output:
tensor([0.4750, 0.1936, 0.5013, 0.8905, 0.5461, 0.7931, 0.3421, 0.1112, 0.9004,
0.7109, 0.7130, 0.7980, 0.2619, 0.5134, 0.2712])
-1所指的维度可以根据其他的维度推出来
z = x.view(-1,5)
print(z)
output:
tensor([[0.3031, 0.0860, 0.9618, 0.1796, 0.1792],
[0.6804, 0.4157, 0.7296, 0.8732, 0.1969],
[0.8737, 0.0186, 0.6638, 0.2070, 0.7613]])
注意:
view()返回的新tensor与源tensor共享内存,实际上就是同一个tensor,也就是更改一个,另一个也会跟着改变。
(顾名思义,view()仅仅改变了对这个张量的观察角度)
Pytorch中的Tensor支持包含一百多种操作,包含转置,索引,切片,数学运算,线性代数,随机数等。
1.7.5 Tensor的数据转换
使用PyTorch进行深度学习模型的训练时,通常需要将输入数据转换为PyTorch张量的形式,以便进行张量操作和自动求导。而在模型预测时,通常需要将输出的PyTorch张量转换为NumPy数组的形式,以便进行后续的分析和可视化
item()
作用:它可以将一个标量Tensor转换为一个Python number:
x = torch.randn(1)
x = x.item()
print(x)
output:
tensor([1.4716])
1.4715948104858398
Tensor 转 NumPy
使用numpy()将Tensor转换成NumPy数组:
注意,这样产生的NumPy数组与Tensor共享相同的内存,改变其中一个另一个也会改变!
a = torch.ones(5)
print(a)
b = a.numpy() # 转为numpy
print(b)
output:
tensor([1., 1., 1., 1., 1.])
[1. 1. 1. 1. 1.]
NumPy数组转Tensor
使用from_numpy()将NumPy数组转换为Tensor:
注意,这样产生的NumPy数组与Tensor共享相同的内存,改变其中一个另一个也会改变
a = np.ones(5)
print(a)
b = torch.from_numpy(a)
print(b)
output:
[1. 1. 1. 1. 1.]
tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
1.7.6 Tensor的广播机制
x = torch.arange(1, 3).view(1,2) #[1,2]
print(x)
y = torch.arange(1, 4).view(3,1)
print(y)
print(x+y)
output:
tensor([[1, 2]])
tensor([[1],
[2],
[3]])
tensor([[2, 3],
[3, 4],
[4, 5]])
1.7.7 tensor运算的内存开销
索引,view()是不会开辟新的内存的,而像y=x+y这样的运算是会开辟新的内存的,然后y指向新的内存。
1.7.8 Tensor ON GPU
用方法to()可以将Tensor在CPU和GPU之间相互移动。
# 以下代码只有在PyTorch GPU版本上才会执⾏
if torch.cuda.is_available():
device = torch.device("cuda") # GPU
x = torch.arange(1, 3).view(1,2)
y = torch.ones_like(x,device=device) #直接创建一个在GPU上的Tensor
x = x.to(device) # 等价于 .to("cuda")
z = x + y
print(z)
print(z.to("cpu", torch.double)) # to()还可以同时更改数据类型
reference:hereandhere