目录
Sharding-JDBC介绍
数据分片剖析实战
Sharding-JDBC介绍

背景
随着通信技术的革新,全新领域的应用层出不穷,数据存量随着应 用的探索不断增加,数据的存储和计算模式无时无刻不面临着创新。面向交易、大数据、关联分析、物联网等场景越来越细分,单 一数据库再也无法适用于所有的应用场景。 与此同时,场景内部也愈加细化,相似场景使用不同数据库已成为常态。 由此可见,数据 库碎片化的趋势已经不可逆转。
ShardingJDBC是什么

Sharding-JDBC是Apache ShardingSphere生态圈中一款开源的分布式数据库第三方组件。ShardingSphere由它由Sharding-JDBC、 Sharding-Proxy和Sharding-Sidecar(规划中)这3款相互独立的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理 功能,适用于Java同构、异构语言、容器、云原生等各种多样化的应用场景。 Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额 外服务。 它使用客户端直连数据库, 以jar包形式提供服务,无需 额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各 种ORM 框架的使用。
适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库,目前支持MySQL,Oracle, SQLServer和PostgreSQL。
主要功能
1、数据分片
分库 、分表 、读写分离 、分片策略、 分布式主键
2、分布式事务
标准化的事务接口、XA强一致性事务、 柔性事务
3、数据库治理
配置动态化 、编排和治理 、数据脱敏 、可视化链路追踪
内部结构
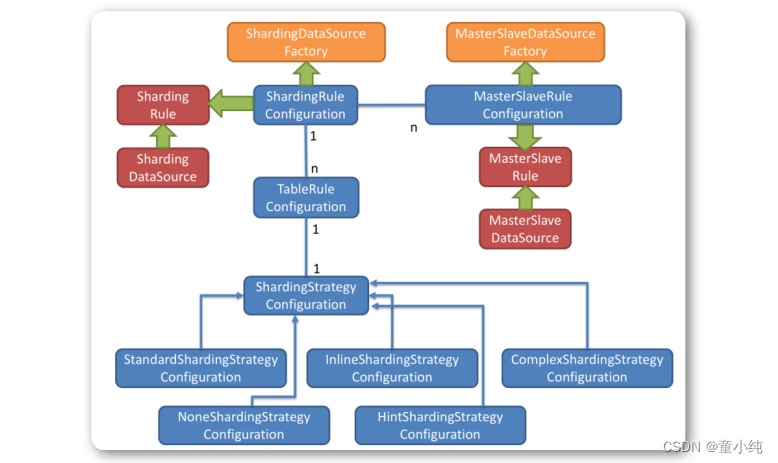
1、图中黄色部分表示的是Sharding-JDBC的入口API,采用工厂方法的形式提供。 目前有 ShardingDataSourceFactory支持分库分表,读写分离操作 MasterSlaveDataSourceFactory支持读写分离操作
2、图中蓝色部分表示的是Sharding-JDBC的配置对象,提供灵活多 变的配置方式。 TableRuleConfiguration,它包含分片配置规则 MasterSlaveRuleConfiguration,它包含的是读写分离的配置规则 ShardingRuleConfuguration,主入口,它包含多个 TableRuleConfiguration,也可以包含多个 MasterSlaveRuleConfiguration
3、图中红色部分表示的是内部对象,由Sharding-JDBC内部使用, 应用开发者无需关注。
Shardingjdbc通过ShardingRuleConfuguration和 MasterSlaveRuleConfiguration生成真正的规则对象,最终生成 我们要使用的Datasource。
Sharding-JDBC初始化流程: 根据配置信息生成configuration对象 通过Factory将configuration对象转化成Rule对象 通过Factory将Rule对象与DataSource对象进行封装 使用shardingjdbc进行分库分表操作
Sharding-JDBC使用过程
1、引入maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.1.1</version>
</dependency>
2、规则配置
Sharding-JDBC可以通过Java,YAML,Spring命名空间和 Spring Boot Starter四种方式配置,开发者可根据场景选择适合 的配置方式。
3、创建DataSource
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap,shardingRuleConfig, props);
实时效果反馈
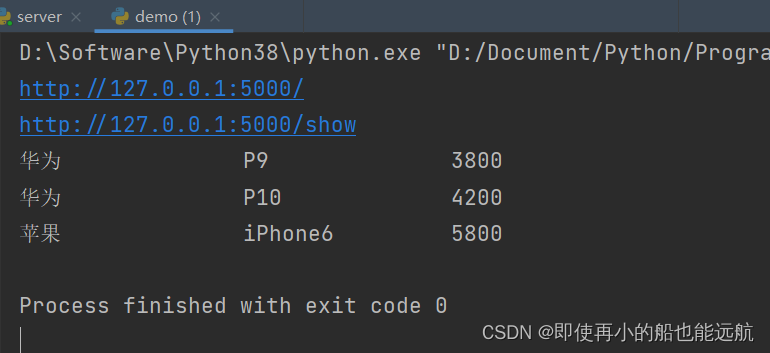
1. 使用Sharding-JDBC时必须引入哪个包
A sharding-jdbc-spring
B sharding-jdbc-core
C sharding-jdbc-core-spring
D sharding-jdbc-spring-boot-starter
数据分片剖析实战

核心概念
真实表
数据库中真实存在的物理表。例如b_order0、b_order1
逻辑表
在分片之后,同一类表结构的名称(总称)。例如b_order。
数据节点
在分片之后,由数据源和数据表组成。例如ds0.b_order1
绑定表
指的是分片规则一致的关系表(主表、子表),例如b_order和b_order_item,均按照 order_id分片,则此两个表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联, 可以提升关联查询效率。
b_order:b_order0,b_order1
b_order_item: b_order_item0,b_order_item1
没有配置绑定关系,采用笛卡尔积关联查询4条sql语句
select * from b_order0 o left join b_order_item0 i on o.order_id = i.order_id
where o.order_id in(10,11)
select * from b_order0 o left join b_order_item1 i on o.order_id = i.order_id
where o.order_id in(10,11)
select * from b_order1 o left join b_order_item0 i on o.order_id = i.order_id
where o.order_id in(10,11)
select * from b_order1 o left join b_order_item1 i on o.order_id = i.order_id
where o.order_id in(10,11)
配置了绑定关系,只需要查2条sql语句
select * from b_order0 o left join b_order_item0 i on o.order_id = i.order_id
where o.order_id in(10,11)
select * from b_order1 o left join b_order_item1 i on o.order_id = i.order_id
where o.order_id in(10,11)
广播表
在使用中,有些表没必要做分片,例如字典表、省份信息等,因为他们数据量不大,而且这种表可
能需要与海量数据的表进行关联查询。广播表会在不同的数据节点上进行存储,存储的表结构和数 据完全相同。
数据分片流程解析

SQL解析分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 Sharding-JDBC采用不同的解析器对SQL进行解析,解析器类型如 下:
Mysql解析器
Oracle解析器
SQLSERVER解析器
PostgreSql解析器
默认解析器 sql-92标准
查询优化
负责合并和优化分片条件,如OR等。
SQL路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前 支持分片路由和广播路由。
SQL改写
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为 正确性改写和优化改写。
SQL执行
通过多线程执行器异步执行SQL。
结果归并
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并 包括流式归并、内存归并和使用装饰者模式的追加归并这几种方 式。
SQL使用规范
兼容全部常用的路由至单数据节点的SQL; 路由至多数据节点的 SQL由于场景复杂,分为稳定支持、实验性支持和不支持这三种情况 :
1、稳定支持 全面支持 DQL、DML、DDL、DCL、TCL 和常用 DAL。 支持分页、去重、排序、分组、聚合、表关联等复杂查询。
SELECT 主语句
SELECT select_expr [, select_expr ...]
FROM table_reference [, table_reference ...]
[WHERE predicates]
[GROUP BY {col_name | position} [ASC | DESC], ...]
[ORDER BY {col_name | position} [ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
select_expr
* |
[DISTINCT] COLUMN_NAME [AS] [alias] | (MAX | MIN | SUM | AVG)(COLUMN_NAME | alias) [AS] [alias] | COUNT(* | COLUMN_NAME | alias) [AS] [alias]table_reference
tbl_name [AS] alias] [index_hint_list]
| table_reference ([INNER] | {LEFT|RIGHT}
[OUTER]) JOIN table_factor [JOIN ON
conditional_expr | USING (column_list)]
子查询
子查询和外层查询同时指定分片键,且分片键的值保持一致时,由内核提供稳定支持。
2、实验性支持
实验性支持特指使用 Federation 执行引擎提供支持。 该引擎处于快速开发中,用户虽基本可用,但仍需大量优化,是实验性产 品。
子查询
子查询和外层查询未同时指定分片键,或分片键的值不一致时, 由 Federation 执行引擎提供支持,例如:
SELECT * FROM (SELECT * FROM t_order) o;
SELECT * FROM (SELECT * FROM t_order) o WHERE o.order_id = 1;
SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o;
SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id = 2;
跨库关联查询
当关联查询中的多个表分布在不同的数据库实例上时,由 Federation 执行引擎提供支持。 假设 t_order 和 t_order_item 是多数据节点的分片表,并且未配置绑定表规则,t_user和 t_user_role是分布在不同的数据库实例上的单表,那么 Federation 执行引擎能够支持如下常用的关联查询。
SELECT * FROM t_order o INNER JOIN t_order_item i ON o.order_id = i.order_id
WHERE o.order_id = 1;
SELECT * FROM t_order o INNER JOIN t_user u ON o.user_id = u.user_id WHERE o.user_id = 1;
SELECT * FROM t_order o LEFT JOIN t_user_role r ON o.user_id = r.user_id WHERE o.user_id = 1;
SELECT * FROM t_order_item i LEFT JOIN t_user u ON i.user_id = u.user_id WHERE i.user_id = 1;
SELECT * FROM t_order_item i RIGHT JOIN t_user_role r ON i.user_id = r.user_id WHERE i.user_id = 1;
SELECT * FROM t_user u RIGHT JOIN t_user_role r ON u.user_id = r.user_id WHERE u.user_id = 1;
3、不支持
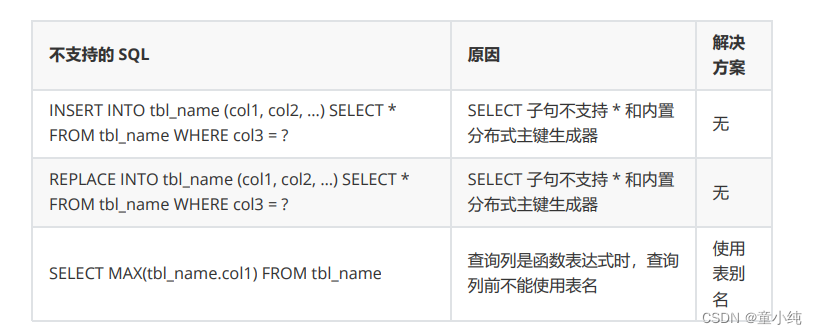
以下 CASE WHEN 语句不支持: CASE WHEN 中包含子查询 CASE WHEN 中使用逻辑表名(请使用表别名)


![[元带你学: eMMC协议 24] eMMC Packed Command CMD23读(Read) 写(write) 操作详解](https://img-blog.csdnimg.cn/img_convert/262abfa94e2b5642120b21810384ce4b.png)