1. Zookeeper Java客户端实战
ZooKeeper应用的开发主要通过Java客户端API去连接和操作ZooKeeper集群。可供选择的Java客户端API有:
- ZooKeeper官方的Java客户端API。
- 第三方的Java客户端API,比如Curator。
ZooKeeper官方的客户端API提供了基本的操作。例如,创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等。不过,对于实际开发来说,ZooKeeper官方API有一些不足之处,具体如下:
- ZooKeeper的Watcher监测是一次性的,每次触发之后都需要重新进行注册。
- 会话超时之后没有实现重连机制。
- 异常处理烦琐,ZooKeeper提供了很多异常,对于开发人员来说可能根本不知道应该如何处理这些抛出的异常。
- 仅提供了简单的byte[]数组类型的接口,没有提供Java POJO级别的序列化数据处理接口。
- 创建节点时如果抛出异常,需要自行检查节点是否存在。
- 无法实现级联删除。
总之,ZooKeeper官方API功能比较简单,在实际开发过程中比较笨重,一般不推荐使用。
1.1 Zookeeper 原生Java客户端使用
<!-- zookeeper client -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.8.0</version>
</dependency>
ZooKeeper常用构造器
ZooKeeper (connectString, sessionTimeout, watcher)
- connectString:使用逗号分隔的列表,每个ZooKeeper节点是一个host.port对,host是机器名或者IP地址,port是ZooKeeper节点对客户端提供服务的端口号。客户端会任意选取connectString中的一个节点建立连接。
- sessionTimeout : session timeout时间。
- watcher:用于接收到来自ZooKeeper集群的事件。
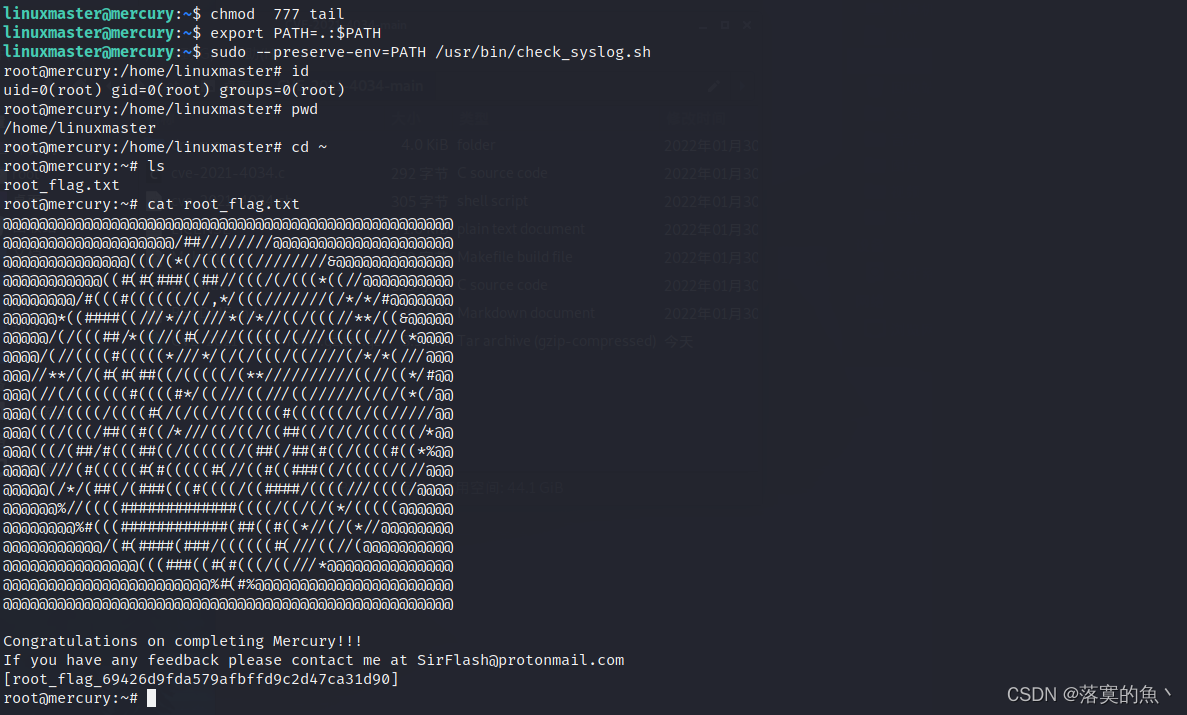
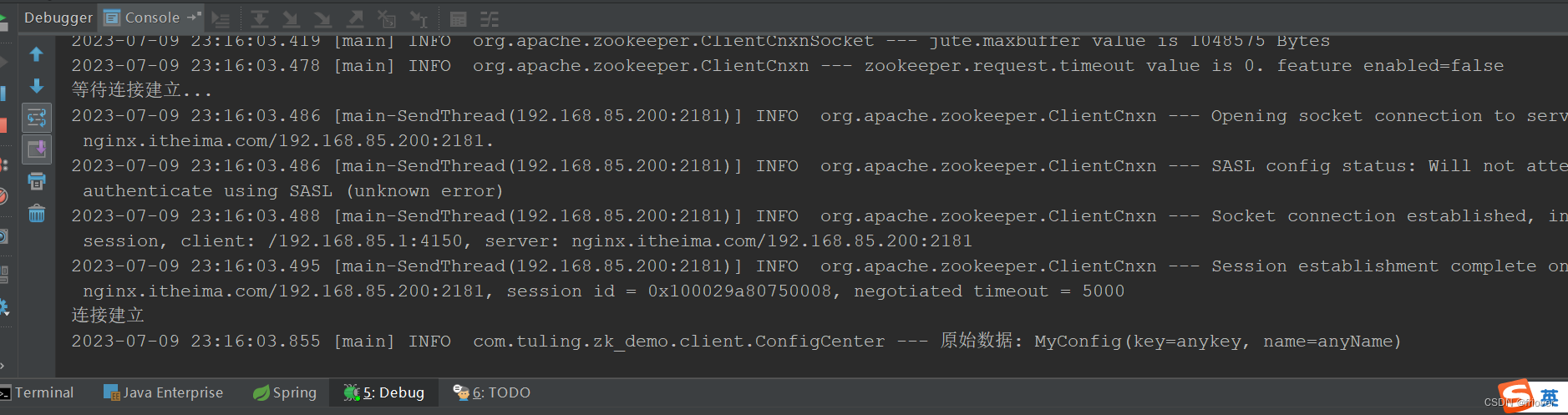
使用 zookeeper 原生 API,连接zookeeper
public class ConfigCenter {
private final static String CONNECT_STR="192.168.85.200:2181";
public static void main(String[] args) throws Exception {
ZooKeeper zooKeeper= ZooKeeperFacotry.create(CONNECT_STR);
MyConfig myConfig = new MyConfig();
myConfig.setKey("anykey");
myConfig.setName("anyName");
ObjectMapper objectMapper=new ObjectMapper();
byte[] bytes = objectMapper.writeValueAsBytes(myConfig);
//创建持久节点 create /myconfig
zooKeeper.create("/myconfig", bytes, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
Watcher watcher = new Watcher() {
@SneakyThrows
@Override
public void process(WatchedEvent event) {
if (event.getType()== Event.EventType.NodeDataChanged
&& event.getPath()!=null && event.getPath().equals("/myconfig")){
log.info(" PATH:{} 发生了数据变化" ,event.getPath());
//获取配置信息
byte[] data = zooKeeper.getData("/myconfig", this, null);
MyConfig newConfig = objectMapper.readValue(new String(data), MyConfig.class);
log.info("数据发生变化: {}",newConfig);
}
}
};
byte[] data = zooKeeper.getData("/myconfig", watcher, null);
MyConfig originalMyConfig = objectMapper.readValue(new String(data), MyConfig.class);
log.info("原始数据: {}", originalMyConfig);
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}
}

Zookeeper主要方法
- create(path, data, acl,createMode): 创建一个给定路径的 znode,并在 znode 保存data[]的 数据,createMode指定 znode 的类型。
- delete(path, version):如果给定 path 上的 znode 的版本和给定的 version 匹配, 删除znode。
- exists(path, watch):判断给定 path 上的 znode 是否存在,并在 znode 设置一个 watch。
- getData(path, watch):返回给定 path 上的 znode 数据,并在 znode 设置一个 watch。
- setData(path, data, version):如果给定 path 上的 znode 的版本和给定的 version 匹配,设置znode 数据。
- getChildren(path, watch):返回给定 path 上的 znode 的孩子 znode 名字,并在 znode设置一个 watch。
- sync(path):把客户端 session 连接节点和 leader 节点进行同步。
方法特点:
- 所有获取 znode 数据的 API 都可以设置一个 watch 用来监控 znode 的变化。
- 所有更新 znode 数据的 API 都有两个版本: 无条件更新版本和条件更新版本。如果 version 为-1,更新为无条件更新。否则只有给定的 version 和 znode 当前的 version 一样,才会进行更新,这样的更新是条件更新。
- 所有的方法都有同步和异步两个版本。同步版本的方法发送请求给 ZooKeeper 并等待服务器的响应。异步版本把请求放入客户端的请求队列,然后马上返回。异步版本通过 callback 来接受来 自服务端的响应。
同步创建节点:
@Test
public void createTest() throws KeeperException, InterruptedException {
String path = zooKeeper.create(ZK_NODE, "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
log.info("created path: {}",path);
}
异步创建节点:
@Test
public void createAsycTest() throws InterruptedException {
zooKeeper.create(ZK_NODE, "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT,
(rc, path, ctx, name) -> log.info("rc {},path {},ctx {},name {}",rc,path,ctx,name),"context");
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}
1.2 Curator开源客户端使用
Curator是Netflix公司开源的一套ZooKeeper客户端框架,和ZkClient一样它解决了非常底层的细节开发工作,包括连接、重连、反复注册Watcher的问题以及NodeExistsException异常等。
引入依赖
- curator-framework是对ZooKeeper的底层API的一些封装。
- curator-client提供了一些客户端的操作,例如重试策略等。
- curator-recipes封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等。
</dependency>
<!--curator-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.1.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
创建一个客户端实例
public class CuratorDemo {
private final static String CLUSTER_CONNECT_STR="192.168.85.200:2181";
public static void main(String[] args) throws Exception {
//构建客户端实例
CuratorFramework curatorFramework= CuratorFrameworkFactory.builder()
.connectString(CLUSTER_CONNECT_STR)
.retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略
.build();
//启动客户端
curatorFramework.start();
String path = "/user";
// 检查节点是否存在
Stat stat = curatorFramework.checkExists().forPath(path);
if (stat != null) {
// 删除节点
curatorFramework.delete()
.deletingChildrenIfNeeded() // 如果存在子节点,则删除所有子节点
.forPath(path); // 删除指定节点
}
// 创建节点
curatorFramework.create()
.creatingParentsIfNeeded() // 如果父节点不存在,则创建父节点
.withMode(CreateMode.PERSISTENT)
.forPath(path, "Init Data".getBytes());
// 注册节点监听
curatorFramework.getData()
.usingWatcher(new CuratorWatcher() {
@Override
public void process(WatchedEvent event) throws Exception {
byte[] bytes = curatorFramework.getData().forPath(path);
System.out.println("Node data changed: " + new String(bytes));
}
})
.forPath(path);
// 更新节点数据 set /user Update Data
curatorFramework.setData()
.forPath(path, "Update Data".getBytes());
stat=new Stat();
//查询节点数据
byte[] bytes = curatorFramework.getData().storingStatIn(stat)
.forPath("/user");
System.out.println(new String(bytes));
ExecutorService executorService = Executors.newSingleThreadExecutor();
//异步处理,可以指定线程池
curatorFramework.getData().inBackground((item1, item2) -> {
System.out.println("background:"+item1+","+item2);
System.out.println(item2.getStat());
},executorService).forPath(path);
// 创建节点缓存,用于监听指定节点的变化
final NodeCache nodeCache = new NodeCache(curatorFramework, path);
// 启动NodeCache并立即从服务端获取最新数据
nodeCache.start(true);
// 注册节点变化监听器
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
byte[] newData = nodeCache.getCurrentData().getData();
System.out.println("Node data changed: " + new String(newData));
}
});
// 创建PathChildrenCache
PathChildrenCache pathChildrenCache = new PathChildrenCache(curatorFramework, path, true);
pathChildrenCache.start();
// 注册子节点变化监听器
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
if (event.getType() == PathChildrenCacheEvent.Type.CHILD_ADDED) {
ChildData childData = event.getData();
System.out.println("Child added: " + childData.getPath());
} else if (event.getType() == PathChildrenCacheEvent.Type.CHILD_REMOVED) {
ChildData childData = event.getData();
System.out.println("Child removed: " + childData.getPath());
} else if (event.getType() == PathChildrenCacheEvent.Type.CHILD_UPDATED) {
ChildData childData = event.getData();
System.out.println("Child updated: " + childData.getPath());
}
}
});
Thread.sleep(Integer.MAX_VALUE);
}
}
- connectionString:服务器地址列表,在指定服务器地址列表的时候可以是一个地址,也可以是多个地址。如果是多个地址,那么每个服务器地址列表用逗号分隔,
如 host1:port1,host2:port2,host3:port3 - retryPolicy:重试策略,当客户端异常退出或者与服务端失去连接的时候,可以通过设置客户端重新连接 ZooKeeper 服务端。而Curator 提供了 一次重试、多次重试等不同种类的实现方式。在 Curator 内部,可以通过判断服务器返回的keeperException 的状态代码来判断是否进行重试处理,如果返回的是 OK 表示一切操作都没有问题,而 SYSTEMERROR表示系统或服务端错误。
超时时间:Curator 客户端创建过程中,有两个超时时间的设置。一个是 sessionTimeoutMs 会话超时时间,用来设置该条会话在 ZooKeeper 服务端的失效时间。另一个是 connectionTimeoutMs 客户端创建会话的超时时间,用来限制客户端发起一个会话连接到接收 ZooKeeper 服务端应答的时间。sessionTimeoutMs 作用在服务端,而 connectionTimeoutMs 作用在客户端。
2. Zookeeper在分布式命名服务中的实战
命名服务是为系统中的资源提供标识能力。ZooKeeper的命名服务主要是利用ZooKeeper节点的树形分层结构和子节点的顺序维护能力,来为分布式系统中的资源命名。
2.1 分布式API目录
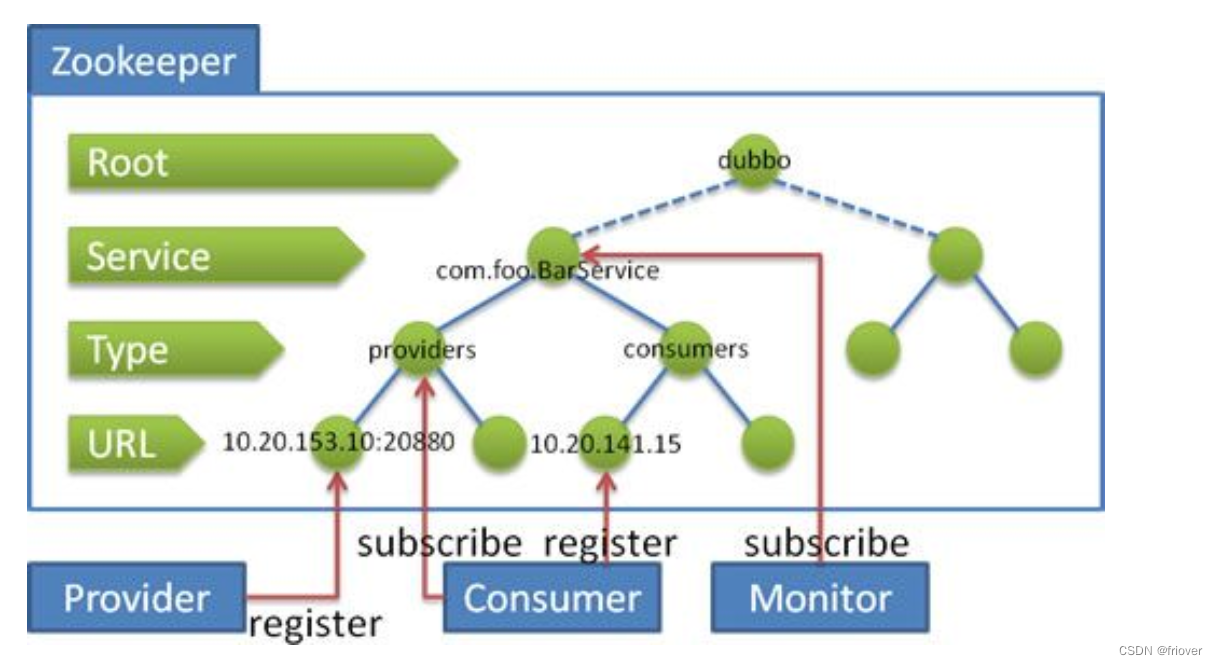
为分布式系统中各种API接口服务的名称、链接地址,提供类似JNDI(Java命名和目录接口)中的文件系统的功能。借助于ZooKeeper的树形分层结构就能提供分布式的API调用功能。
-
服务提供者(Service Provider)在启动的时候,向ZooKeeper上的指定节点/dubbo/${serviceName}/providers写入自己的API地址,这个操作就相当于服务的公开。
-
服务消费者(Consumer)启动的时候,订阅节点/dubbo/{serviceName}/providers下的服务提供者的URL地址,获得所有服务提供者的API。
2.2 分布式节点的命名
一个分布式系统通常会由很多的节点组成,节点的数量不是固定的,而是不断动态变化的。比如说,当业务不断膨胀和流量洪峰到来时,大量的节点可能会动态加入到集群中。而一旦流量洪峰过去了,就需要下线大量的节点。再比如说,由于机器或者网络的原因,一些节点会主动离开集群。
如何为大量的动态节点命名呢?一种简单的办法是可以通过配置文件,手动为每一个节点命名。但是,如果节点数据量太大,或者说变动频繁,手动命名则是不现实的,这就需要用到分布式节点的命名服务。
可用于生成集群节点的编号的方案:
(1)使用数据库的自增ID特性,用数据表存储机器的MAC地址或者IP来维护。
(2)使用ZooKeeper持久顺序节点的顺序特性来维护节点的NodeId编号。
在第2种方案中,集群节点命名服务的基本流程是:
- 启动节点服务,连接ZooKeeper,检查命名服务根节点是否存在,如果不存在,就创建系统的根节点。
- 在根节点下创建一个临时顺序ZNode节点,取回ZNode的编号把它作为分布式系统中节点的NODEID。
- 如果临时节点太多,可以根据需要删除临时顺序ZNode节点。
2.3 分布式的ID生成器
在ZooKeeper节点的四种类型中,其中有以下两种类型具备自动编号的能力
- PERSISTENT_SEQUENTIAL持久化顺序节点。
- EPHEMERAL_SEQUENTIAL临时顺序节点。
ZooKeeper的每一个节点都会为它的第一级子节点维护一份顺序编号,会记录每个子节点创建的先后顺序,这个顺序编号是分布式同步的,也是全局唯一的。
3. zookeeper实现分布式队列
常见的消息队列有:RabbitMQ,RocketMQ,Kafka等。Zookeeper作为一个分布式的小文件管理系统,同样能实现简单的队列功能。Zookeeper不适合大数据量存储,官方并不推荐作为队列使用,但由于实现简单,集群搭建较为便利,因此在一些吞吐量不高的小型系统中还是比较好用的。
3.1 设计思路
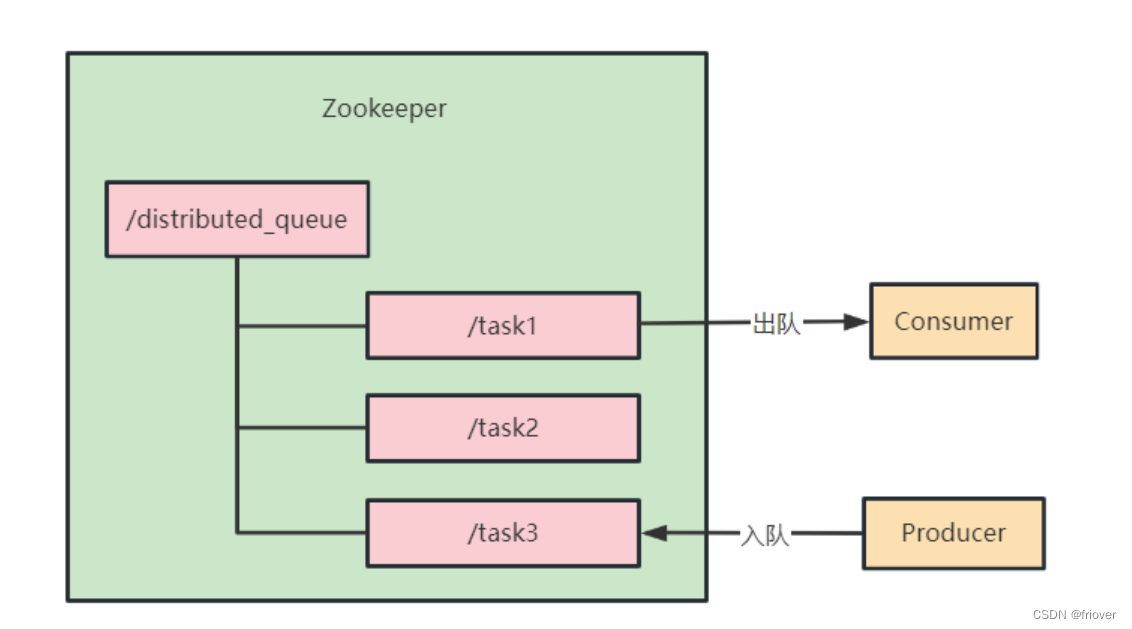
- 创建队列根节点:在Zookeeper中创建一个持久节点,用作队列的根节点。所有队列元素的节点将放在这个根节点下。
- 实现入队操作:当需要将一个元素添加到队列时,可以在队列的根节点下创建一个临时有序节点。节点的数据可以包含队列元素的信息。
- 实现出队操作:当需要从队列中取出一个元素时,可以执行以下操作:
获取根节点下的所有子节点。
找到具有最小序号的子节点。
获取该节点的数据。
删除该节点。
返回节点的数据。
package com.tuling.zkqueue.demo;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class DistributedQueueDemo {
private static final String QUEUE_ROOT = "/distributed_queue";
private ZooKeeper zk;
public DistributedQueueDemo(String zkAddress) throws IOException, InterruptedException {
CountDownLatch connectedSignal = new CountDownLatch(1);
zk = new ZooKeeper(zkAddress, 30000, event -> {
if (event.getState() == Watcher.Event.KeeperState.SyncConnected) {
connectedSignal.countDown();
}
});
connectedSignal.await();
try {
// 判断/distributed_queue节点是否存在
Stat stat = zk.exists(QUEUE_ROOT, false);
if (stat == null) {
//创建持久节点 /distributed_queue
zk.create(QUEUE_ROOT, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch (KeeperException e) {
e.printStackTrace();
}
}
/**
* 入队
* @param data
* @throws Exception
*/
public void enqueue(String data) throws Exception {
// 创建临时有序子节点
zk.create(QUEUE_ROOT + "/queue-", data.getBytes(StandardCharsets.UTF_8),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
/**
* 出队
* @return
* @throws Exception
*/
public String dequeue() throws Exception {
while (true) {
List<String> children = zk.getChildren(QUEUE_ROOT, false);
if (children.isEmpty()) {
return null;
}
Collections.sort(children);
for (String child : children) {
String childPath = QUEUE_ROOT + "/" + child;
try {
byte[] data = zk.getData(childPath, false, null);
zk.delete(childPath, -1);
return new String(data, StandardCharsets.UTF_8);
} catch (KeeperException.NoNodeException e) {
// 节点已被其他消费者删除,尝试下一个节点
}
}
}
}
public static void main(String[] args) throws Exception {
DistributedQueueDemo queue = new DistributedQueueDemo("192.168.85.200:2181");
// 生产者线程
new Thread(() -> {
for (int i = 0; i < 10; i++) {
try {
queue.enqueue("Task-" + i);
System.out.println("Enqueued: Task-" + i);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
// 消费者线程
new Thread(() -> {
for (int i = 0; i < 10; i++) {
try {
String task = queue.dequeue();
System.out.println("Dequeued: " + task);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
4.Zookeeper 分布式锁实战
4.1目前分布式锁,比较成熟、主流的方案:
1)基于数据库的分布式锁。这种方案使用数据库的事务和锁机制来实现分布式锁。虽然在某些场景下可以实现简单的分布式锁,但由于数据库操作的性能相对较低,并且可能面临锁表的风险,所以一般不是首选方案
2)基于Redis的分布式锁。Redis分布式锁是一种常见且成熟的方案,适用于高并发、性能要求高且可靠性问题可以通过其他方案弥补的场景。Redis提供了高效的内存存储和原子操作,可以快速获取和释放锁。它在大规模的分布式系统中得到广泛应用。
3)基于ZooKeeper的分布式锁。这种方案适用于对高可靠性和一致性要求较高,而并发量不是太高的场景。由于ZooKeeper的选举机制和强一致性保证,它可以处理更复杂的分布式锁场景,但相对于Redis而言,性能可能较低。
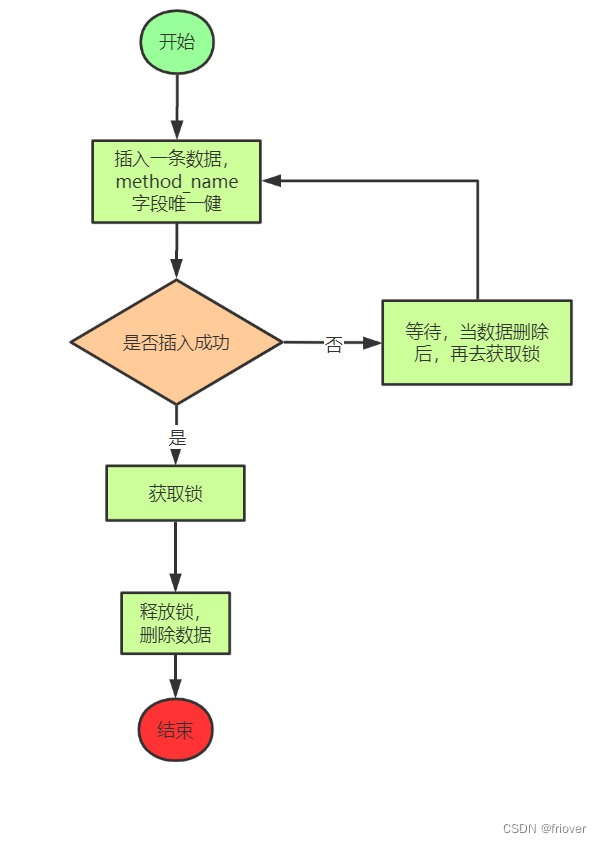
4.2 基于数据库设计思路
4.3 基于Zookeeper设计思路一
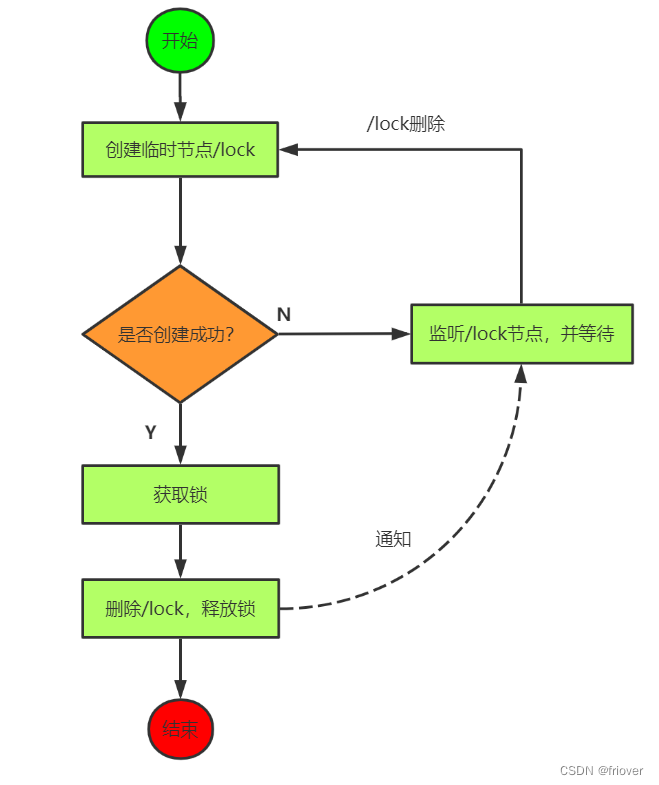
问题:如果所有的锁请求者都 watch 锁持有者,当代表锁持有者的 znode 被删除以后,所有的锁请求者都会通知到,但是只有一个锁请求者能拿到锁。
4.4 基于Zookeeper设计思路二
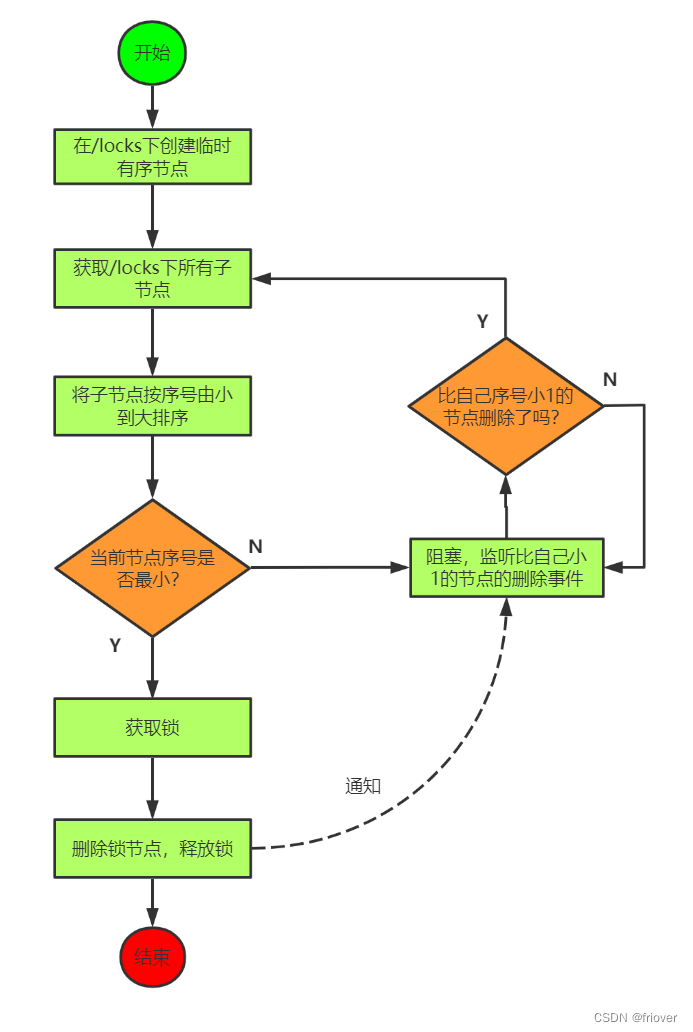
4.5 Curator 可重入分布式锁工作流程
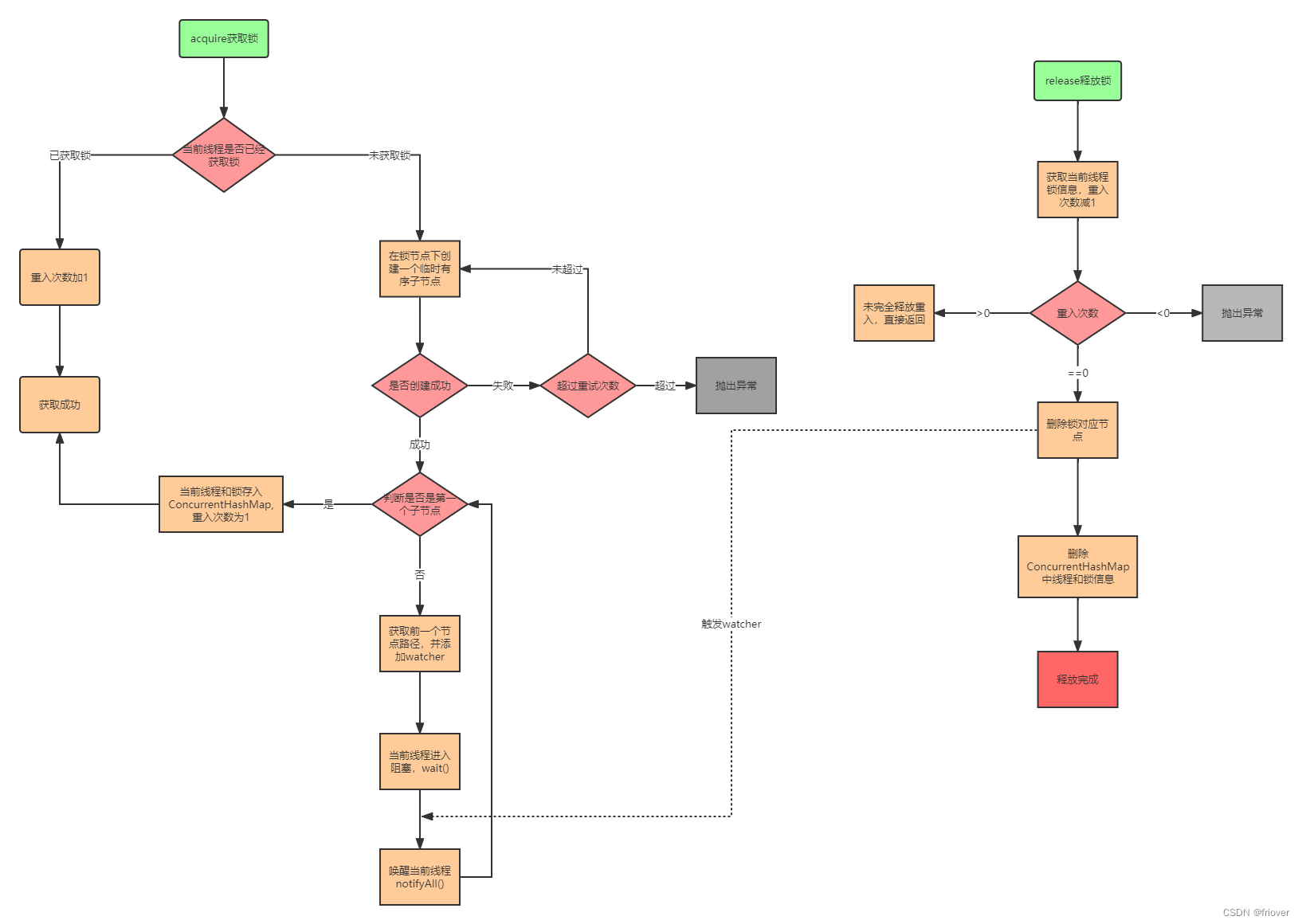
4.6 总结
优点:ZooKeeper分布式锁(如InterProcessMutex),具备高可用、可重入、阻塞锁特性,可解决失效死锁问题,使用起来也较为简单。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis。
在高性能、高并发的应用场景下,不建议使用ZooKeeper的分布式锁。而由于ZooKeeper的高可靠性,因此在并发量不是太高的应用场景中,还是推荐使用ZooKeeper的分布式锁。
5. 基于Zookeeper实现服务的注册与发现
5.1 设计思路
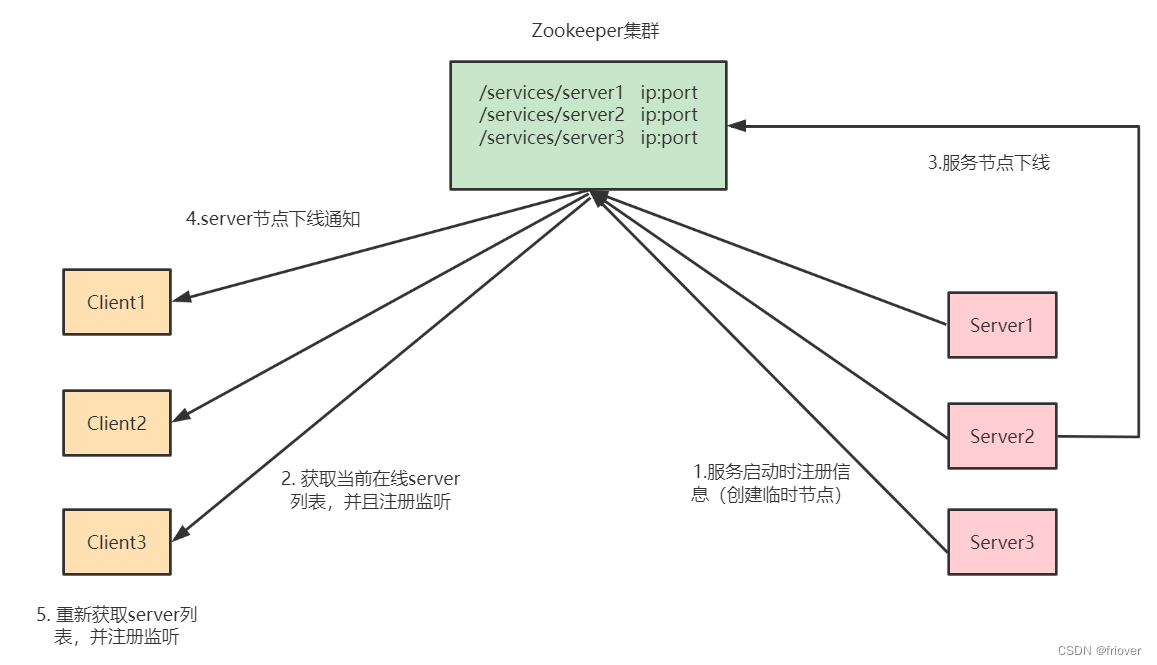
5.2 Zookeeper实现注册中心的优缺点
优点:
- 高可用性:ZooKeeper是一个高可用的分布式系统,可以通过配置多个服务器实例来提供容错能力。如果其中一个实例出现故障,其他实例仍然可以继续提供服务。
- 强一致性:ZooKeeper保证了数据的强一致性。当一个更新操作完成时,所有的服务器都将具有相同的数据视图。这使得ZooKeeper非常适合作为服务注册中心,因为可以确保所有客户端看到的服务状态是一致的。
- 实时性:ZooKeeper的监视器(Watcher)机制允许客户端监听节点的变化。当服务提供者的状态发生变化时(例如,上线或下线),客户端会实时收到通知。这使得服务消费者能够快速响应服务的变化,从而实现动态服务发现。
缺点:
- 性能限制:ZooKeeper的性能可能不如一些专为服务注册中心设计的解决方案,如nacos或Consul。尤其是在大量的读写操作或大规模集群的情况下,ZooKeeper可能会遇到性能瓶颈。


![[元带你学: eMMC协议 24] eMMC Packed Command CMD23读(Read) 写(write) 操作详解](https://img-blog.csdnimg.cn/img_convert/262abfa94e2b5642120b21810384ce4b.png)