文章目录
- 1 InnoDB 行记录格式(理论)
- 1.1 Redundant 行记录格式
- 1.2 Compact 行记录格式(重点)
- 1.3 行溢出数据
- 1.4 Compressed 和 Dynamic 行记录格式
- 1.5 CHAR 的行结构存储
- 2 参考资料
1 InnoDB 行记录格式(理论)
在 InnoDB 存储引擎中,记录是以行的形式存储的,这意味着页中保存着表中一行行的数据。用户可以通过命令 SHOW TABLE STATUS LIKE 'table_name' 来查看当前表使用的行格式,其中 row_format 属性表示当前所使用的行记录结构类型。如:
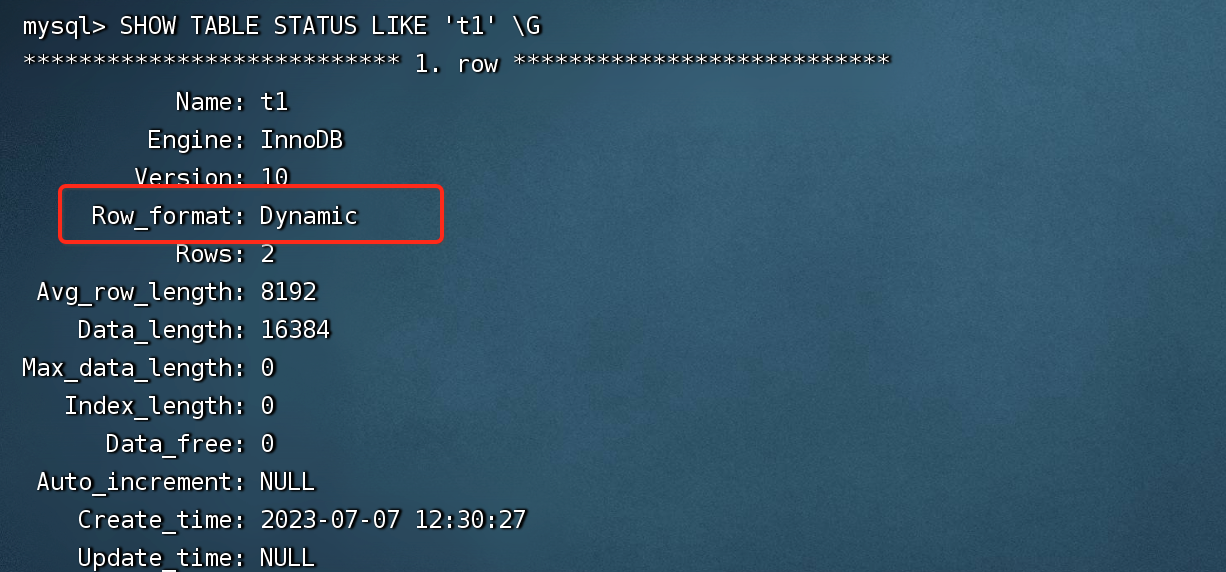
在 InnoDB 存储引擎发展历史中出现了多种行格式,如:Redundant、Compact、Dynamic 等
1.1 Redundant 行记录格式
前言:有配套的实验
Redundan 是旧的行记录格式,了解即可。Redundant 行记录采用如下图所示的方式存储:

字段长度偏移列表:
不同于 Compact 行记录格式,Redundant 行记录格式的首部是一个字段长度偏移列表,同样是按照列的顺序逆序放置的。若列的长度小于255字节,用1字节表示;若大于255字节,用2字节表示
举个栗子
-- 1、创建一个表
create table t1 (
a varchar(10),
b varchar(10),
c char(10),
d varchar(10)
) ENGINE = innodb charset=latin1 ROW_FORMAT = Redundant;
-- 2、插入数据
insert into select a,bb,bb,ccc;
从 t1.ibd 文件中捞出的字段长度偏移列表为[23 20 16 14 13 0c 06],调整顺序为[06 0c 13 14 16 20 23],表示的含义是第1个字段的长度是6,第2个字段的长度是6(06 + 06 = 0c),第3个字段的长度是7(0c + 07 = 13),第4个字段的长度是1(13 + 01 = 14),第5个字段的长度是2(14 + 02 = 16),第6个字段的长度是10(16 + 0a = 20),第7个字段的长度是3(20 + 03 = 23)。为什么会多出3个字段我们只定义了4个字段现有有7个,这3个字段是隐藏字段
第1个字段:即 rowid,确实是占用6个字节
第2个字段:即 TranactionID,确实是占用6个字节
第3个字段:即 roll pointer,确实是占用7个字节
第4个字段:即字符’a’,确实是占用1个字节
第5个字段:即字符’bb’,确实是占用2个字节
第6个字段:即字符’bb’,但是是 char(10) 类型,确实是占用10个字节
第7个字段:即字符’ccc’,确实是占用3个字节
特别的,在 Redundant 中 NULL 的长度是通过符号位表示的,即 16 进制的 80,换算成二进制是 10000000,这是个符号位表示不了任何长度,所以表示 NULL 就很合适了
记录头信息:
不同于Compact行记录格式,Redundant行记录格式的记录头占用6字节(48位),每位的含义如下表
| 名 称 | 大小(bit) | 描 述 |
|---|---|---|
| () | 1 | 未知 |
| () | 1 | 未知 |
| deleted_flag | 1 | 该行是否已被删除 |
| min_rcc_flag | 1 | 为1,如果该记录是预先被定义为最小的记录 |
| n_owned | 3 | 该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该条记录的索引号 |
| n_fields | 10 | 记录中列的数量 |
| lbyte_offs__flag | 1 | 偏移列表为1字节还是2字节 |
| next_record | 16 | 页中下一条记录(rowid)的相对位置(相对谁:相对本页的地址) |
| Total | 48 |
比较重要的 2 个项已经用黑体标出
n_owned:
跟 Compact 格式一样,不赘述
next_record:
页中下一条的相对位置。相对本页的地址,而 Compact 相对的本记录的偏移地址
具体列的数据:
记录头信息的后面就是行的具体数据了
1.2 Compact 行记录格式(重点)
前言:有配套的实验
Compact 行记录格式其设计目标是高效地存储数据。简单来说,一个页中存放的行数据越多,其性能就越高。下图显示了 Compact 行记录的存储方式:

变长字段长度列表:
Compact行记录格式的首部是一个变长字段长度列表,该列表是指非NULL的字段,并且是按照列的顺序逆序处置的。变长字段就是指字段类型如 VARCHAR 等这些可以动态扩展的列,其长度有如下的 2 条规则:
- 若列的长度小于 255( 2 8 2^8 28) 字节,用 1 字节表示其长度即可
- 若列的长度大于 255 字节,用 2 字节表示其长度即可
变长字段的长度最大不可以超过2字节,这是因在MySQL数据库中VARCHAR类型的最大长度限制为65535
举个栗子
-- 1、创建一个表
create table t1 (
a varchar(10),
b varchar(10),
c char(10),
d varchar(10)
) ENGINE = innodb charset=latin1 ROW_FORMAT =COMPACT;
-- 2、插入数据
insert into select a,bb,ccc,dddd;
那么插入的第一条记录的变长字段列表为[04,02,01],分别对应dddd,bb,a的长度(逆序排可变长度列)
NULL 标志位列表:
变长字段之后的第二个部分是NULL标志位列表,列表表明了该行的所有字段中哪些字段是 NULL,二进制位值为1则该字段为NULL(是从二进制列表右往左数的)。如:
十六进制的 NULL 标志位列表为
07时,转换为二进制00000111,表明该表的字段不超过 8 个字段,且第 1、2、3 个字段均为 NULL十六进制的 NULL 标志位列表为
01 07时,转换为二进制为00000001 00000111,表明该表的字段个数大于 8 个小于 16 个,且第 1、2、3、9 个字段均为 NULL
记录头通用信息:
记录头通用信息一般包括 4 个小部分,依顺序分别是:Record Header(记录头)、RowID(主键)、TranactionID(事务 ID 列)、Roll Pointer(回滚指针列)
对于用户插入的记录一般 4 部分都有,而对于系统预设的一些记录一般只有 Record Header 其他则没有
重点看 Record Header 和 RowID
1、Record Header
记录头固定占用 5 个字节(40位),每位的含义见下表:
| 名 称 | 大小(bit) | 描 述 |
|---|---|---|
| () | 1 | 未知 |
| () | 1 | 未知 |
| dcleted_flag | 1 | 该行是否已被删除 |
| min_rcc_flag | 1 | 为1,如果该记录是预先被定义为最小的记录 |
| n_owned | 4 | 该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该条记录的排序记录 |
| recordtype | 3 | 记录该行记录的类型,000表示普通,001表示B+树的结点指针。。。 |
| next_record | 16 | 页中下一条记录的相对位置(相对谁:相对本记录的 rowid 地址) |
| Total | 40 |
记录头信息(Record Header)的最后两个字节就是next_record,next_record代表下一个记录的偏移量,即当前记录的位置(特指 rowid 的地址)加上next_record的偏移量就是下一条行记录的起时位置(特指 rowid 的地址),所以在页的内部,实则上也是通过一种链表的形式来串连各条行记录的
比较重要的 2 个项已经用黑体标出
n_owned:
该项表明该记录拥有多少个记录。**解释:**InnoDB 为了加快记录的查找速度,采用了稀疏目录的管理方式,多个记录对应一个稀疏目录条目,如查询 id = 5 时先把页加载到内存中,先确定该记录对应哪一个稀疏目录条目,随后定位到条目的第一个记录再依次遍历链表直到找到 id = 5 的记录。所以 n_owned=4 就表示 4 个记录共用一个稀疏目录条目
next_record:
该项代表下一个记录的偏移量。即当前记录的位置(特指 rowid 的地址)加上next_record的偏移量就是下一条行记录的起时位置(特指 rowid 的地址),所以在页的内部,实则上也是通过一种链表的形式来串连各条行记录的
Compact 格式下一行的相对地址相对的是本记录的 rowid 的地址
2、RowID
该字段是表示行记录的主键,如果给表指定了主键就用指定的,如果没有则使用系统自动生成的
该字段的长度视情况而定,如果指定主键为 int 类型则占用 4 个字节,为 varchar 则可能更多;如果系统自动生成则固定为 6 个字节
3、TranactionID
事务 ID 列,占用 6 个字节
4、Roll Pointer
回滚指针列,占用 7 个字节
具体列的数据:
记录头信息的后面就是行的具体数据了
1.3 行溢出数据
1、行溢出是一种现象,是指数据存不下,在存储大对象(BLOB、TEXT)列类型时会很容易发生,它们的数据不存储在普通的页中(普通页只有 16KB 存不下),而是存储在特殊的页中(Uncompress BLOB页)
2、存储 varchar 列类型也有可能发生行溢出(毕竟 varchar 的最大长度可以支持 65535,普通页存不下)
3、BLOB 也并不一定存放在特殊页中,varcahr 也不一定不存放在特殊页中
4、到底是不是存在在特殊的页中,主要看一行数据的长度是不是太长了(一般的,如果一页中能存储下 2 行就存放在普通页。如果一页中只能存下一行数据那么页完全退化为链表)
执行如下几个测试观察然后理解 mysql 对 varchar 的长度和行长度是有限制的
-- 按照最大值设置 varchar
CREATE TABLE test (
a VARCHAR(65532)
)CHARSET=latin1 ENGINE=InnoDB;
-- 慢慢缩小 varchar 的大小
CREATE TABLE test (
a VARCHAR(65532)
)CHARSET=latin1 ENGINE=InnoDB;
-- 改成 GBK
CREATE TABLE test (
a VARCHAR(65532)
) CHARSET=GBK ENGINE=InnoDB;
-- 改成 UTF8
CREATE TABLE test (
a VARCHAR(65532)
) CHARSET=utf8 ENGINE=InnoDB;
-- 测试 mysql 对行长度的限制
CREATE TABLE test2 (
a VARCHAR(22000),
b VARCHAR(22000),
c VARCHAR(22000)
)CHARSET=latin1 ENGINE=InnoDB;
实验结果:
1、varchar 列类型中的长度指的是字节的长度,不是字符的长度,一般不要把 varchar 的长度设置的太大
2、每一行的数据大小也是有限制的,太长了一个普通页都存不下都要用特殊也,那怎么玩
1.4 Compressed 和 Dynamic 行记录格式
这 2 种是新的行记录格式,新的两种记录格式对于存放在BLOB中的数据采用了完全的行溢出的方式
1.5 CHAR 的行结构存储
前言:有配套的实验
通常理解VARCHAR是存储变长长度的字符类型,CHAR是存储固定长度的字符类型。在前面,用户已经了解行结构的内部的存储,并可以发现每行的变长字段长度的列表都没有存储CHAR类型的长度
但是,值得注意的是之前给出的两个例子中的字符集都是单字节的latinl格式。CHAR(N)中的N指的是字符的长度,而不是之前版本的字节长度。 也就说在不同的字符集下,CHAR类型列内部存储的可能不是定长的数据。在不同的字符集下,char(N) 的字节长度是不一样的,如在 charset=gbk 下 char(N) 最多占用 2N 个字节,在 charset=latin1 下 char(N) 占用 N 个字节,在 charset=utf8 下 char(N) 最多占用 3N 个字节
char(N)指的是 字符的长度,而varchar(N)指的是字节的长度
2 参考资料
官网:https://dev.mysql.com/doc/refman/8.0/en/innodb-row-format.html
InnoDB 行记录格式(实验):我的另外文章:《15.10 InnoDB 行记录格式(实验,重要)》
书籍:《InnoDB 存储引擎》,该书电子版练习作者无套路免费下载
传送门: 保姆式Spring5源码解析
欢迎与作者一起交流技术和工作生活
联系作者







![数据结构05:树与二叉树[C++][哈夫曼树HuffmanTree]](https://img-blog.csdnimg.cn/63c3e7cd38084e21b7dffcac19dbc494.png)


