Coggle 30 Days of ML(23年7月)任务三:使用TFIDF提取文本特征
任务三:使用TFIDF提取文本特征
- 说明:在这个任务中,需要使用Sklearn库中的TFIDF技术来提取文本特征,将文本转化为可供机器学习算法使用的数值表示。
- 实践步骤:
- 准备文本数据集。
- 使用Sklearn的
TfidfVectorizer类,设置相应的参数(如ngram_range、max_features等)来构建TFIDF特征提取器。 - 使用
TfidfVectorizer的fit_transform()方法,对文本数据集进行特征提取,得到TFIDF特征矩阵。
TfidfVectorizer是scikit-learn库中的一个文本特征提取工具,用于将文本数据转换为TF-IDF特征表示。下面是对TfidfVectorizer函数的功能和常用超参数的介绍:
ngram_range:特征中要包含的n元语法范围,默认为(1, 1),表示只提取单个词。max_df:单词的最大文档频率,超过该频率的单词将被忽略,默认为1.0,表示不忽略任何单词。min_df:单词的最小文档频率,低于该频率的单词将被忽略,默认为1,表示不忽略任何单词。
TFIDF算法
简单来说,向量空间模型就是希望把查询关键字和文档都表达成向量,然后利用向量之间的运算来进一步表达向量间的关系。比如,一个比较常用的运算就是计算查询关键字所对应的向量和文档所对应的向量之间的 “相关度”。
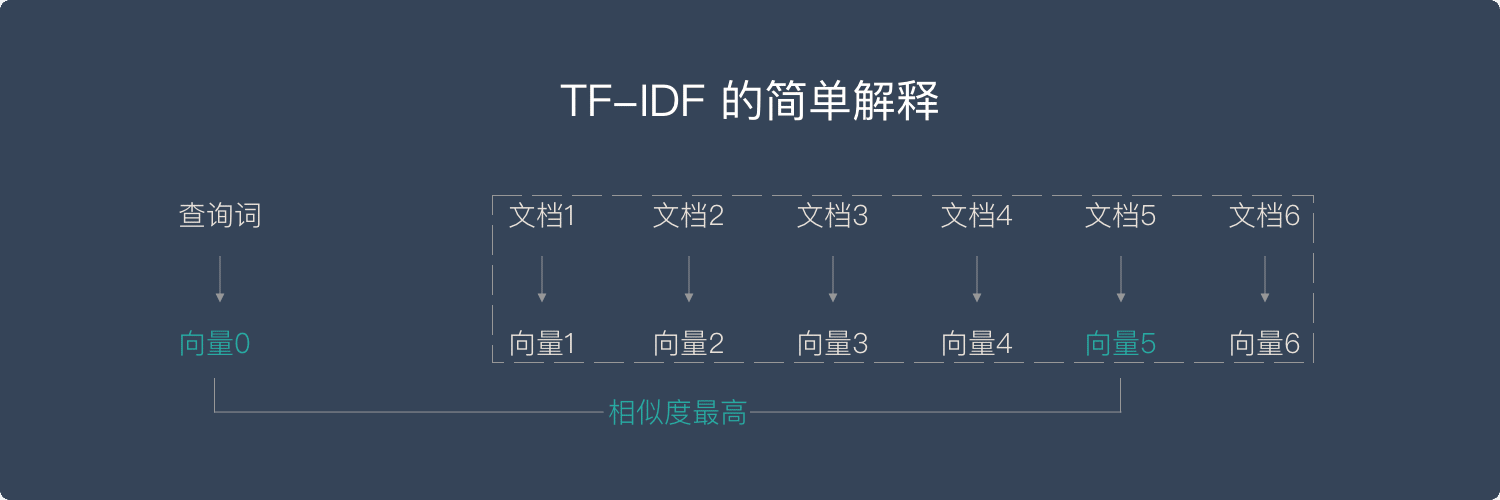
TF (Term Frequency)—— “单词频率”
意思就是说,我们计算一个查询关键字中某一个单词在目标文档中出现的次数。举例说来,如果我们要查询 “Car Insurance”,那么对于每一个文档,我们都计算“Car” 这个单词在其中出现了多少次,“Insurance”这个单词在其中出现了多少次。这个就是 TF 的计算方法。
TF 背后的隐含的假设是,查询关键字中的单词应该相对于其他单词更加重要,而文档的重要程度,也就是相关度,与单词在文档中出现的次数成正比。比如,“Car” 这个单词在文档 A 里出现了 5 次,而在文档 B 里出现了 20 次,那么 TF 计算就认为文档 B 可能更相关。
然而,信息检索工作者很快就发现,仅有 TF 不能比较完整地描述文档的相关度。因为语言的因素,有一些单词可能会比较自然地在很多文档中反复出现,比如英语中的 “The”、“An”、“But” 等等。这些词大多起到了链接语句的作用,是保持语言连贯不可或缺的部分。然而,如果我们要搜索 “How to Build A Car” 这个关键词,其中的 “How”、“To” 以及 “A” 都极可能在绝大多数的文档中出现,这个时候 TF 就无法帮助我们区分文档的相关度了。
IDF(Inverse Document Frequency)—— “逆文档频率”
就在这样的情况下应运而生。这里面的思路其实很简单,那就是我们需要去 “惩罚”(Penalize)那些出现在太多文档中的单词。
也就是说,真正携带 “相关” 信息的单词仅仅出现在相对比较少,有时候可能是极少数的文档里。这个信息,很容易用 “文档频率” 来计算,也就是,有多少文档涵盖了这个单词。很明显,如果有太多文档都涵盖了某个单词,这个单词也就越不重要,或者说是这个单词就越没有信息量。因此,我们需要对 TF 的值进行修正,而 IDF 的想法是用 DF 的倒数来进行修正。倒数的应用正好表达了这样的思想,DF 值越大越不重要。
TF-IDF 算法主要适用于英文,中文首先要分词,分词后要解决多词一义,以及一词多义问题,这两个问题通过简单的tf-idf方法不能很好的解决。于是就有了后来的词嵌入方法,用向量来表征一个词。
TfidfVectorizer类
https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
tfidf.fit(train_data['content'].apply(lambda x: ' '.join(x)))
train_tfidf_feat = tfidf.transform(train_data['content'].apply(lambda x: ' '.join(x)))
test_tfidf_feat = tfidf.transform(train_data['content'].apply(lambda x: ' '.join(x)))
tfidf = TfidfVectorizer(ngram_range=(1,2), max_features=5000)
tfidf.fit(train_data['content'].apply(lambda x: ' '.join(x)))
train_tfidf_feat = tfidf.transform(train_data['content'].apply(lambda x: ' '.join(x)))
test_tfidf_feat = tfidf.transform(train_data['content'].apply(lambda x: ' '.join(x)))
在上述的样例中,对于数据来说,第一个使用全部的默认参数,第二个tfidf设置了两个参数,分别是ngram_range和max_features
ngram_range:特征中要包含的n元语法范围,默认为(1, 1),表示只提取单个词。但是这里设置为(1,2),也就是ngram_range=(1, 2) 表示同时提取单个词和连续的两个词作为特征。
max_features:用于指定特征向量的最大维度或特征数量。在这个例子中,max_features=5000表示只选择最重要的5000个特征(根据TF-IDF权重进行排序),并且将它们作为特征向量的维度。
依据当前的方法和给出的例子,我最后也是用了TfidfVectorizer来进行取文本特征。
tfidf = TfidfVectorizer(token_pattern=r'\w{1}', max_features=4000, ngram_range=(1, 2))
train_tfidf = tfidf.fit_transform(train_data['content'])
test_tfidf = tfidf.fit_transform(test_data['content'])
当设置 token_pattern=r'\w{1}' 时,TfidfVectorizer 使用正则表达式模式 \w{1} 来确定什么样的字符串将被视为一个令牌(token)。
在这个模式中,\w 表示匹配任何字母、数字或下划线字符。{1} 表示前面的模式(\w)必须出现一次,即仅匹配一个字符。
因此,token_pattern=r'\w{1}' 表示令牌被定义为只包含一个字母、数字或下划线字符的字符串,包括长度为1的字符串。
使用这个正则表达式模式,TfidfVectorizer 将会将长度为1的字符串视为有效的令牌,并将其作为特征进行提取和表示。
请注意,根据具体的应用场景和文本数据的特点,可以调整
token_pattern的正则表达式模式以定义不同的令牌化规则。
不过我认为应该是连着的数字是为一个令牌,所以我继续修改,最后得到
tfidf = TfidfVectorizer(token_pattern=r'(?u)\b\w\w+\b', max_features=4000, ngram_range=(1, 2))
train_tfidf = tfidf.fit_transform(train_data['content'])
test_tfidf = tfidf.fit_transform(test_data['content'])
(?u): 这是一个正则表达式标记,表示启用 Unicode 匹配模式。它确保正则表达式可以正确处理 Unicode 字符。\b: 这表示一个单词边界,用于确保令牌的两侧是单词边界。它防止了令牌与其他字符连在一起的情况。\w\w+: 这表示匹配由至少两个字母、数字或下划线字符组成的字符串。\w表示匹配任何字母、数字或下划线字符,而+表示前面的模式(\w)必须出现一次或多次。\b: 再次使用单词边界,确保令牌的结尾是一个单词边界。
因此,token_pattern=r'(?u)\b\w\w+\b' 表示令牌由两个或更多个字母、数字或下划线字符组成的字符串构成,并且令牌的两侧是单词边界。这样的模式将会匹配长度大于等于2的连续字符序列作为令牌。
TfidfVectorizer 将使用这个正则表达式模式进行令牌化,生成相应的 TF-IDF 特征向量。这样,连续的长度大于等于2的字符序列将作为一个令牌被考虑,并用于计算 TF-IDF 权重。不过这样就会忽略长度为1的字符序列了,后续也可以进行改进。


![数据结构05:树与二叉树[C++][哈夫曼树HuffmanTree]](https://img-blog.csdnimg.cn/63c3e7cd38084e21b7dffcac19dbc494.png)