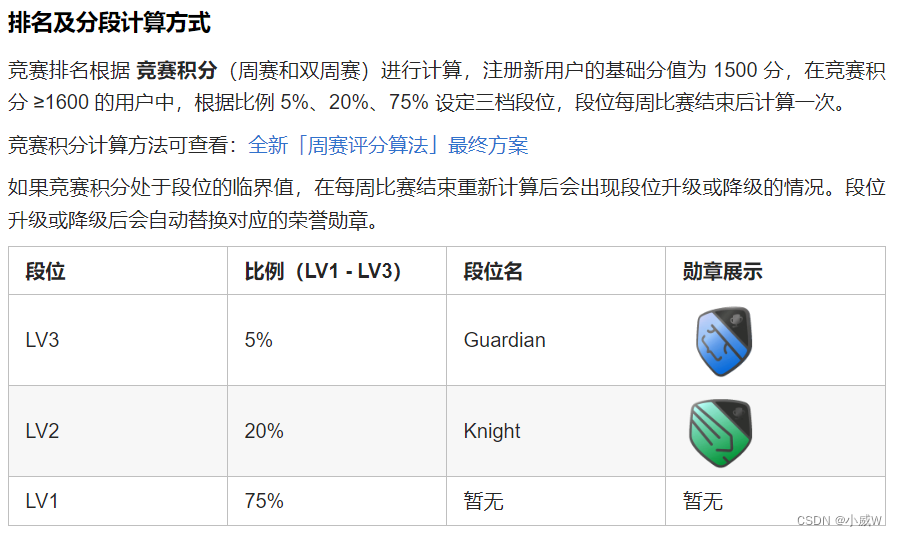
linux疑难问题排查实战专栏,分享了作为公司专家,在解决内存、性能、各类死机等疑难问题的排查经验,认真学习可以让你在日后工作中大放光彩。
本文总结介绍了项目开发过程中oom排查和内存优化的一些方法,主要是从内存问题查看到堆内存、栈内存、数据段内存优化为导向,结合实际优化实例介绍工具和方法的运用,展示每种优化方法优化过程,希望对读者有所帮助。
从下面几个角度展开:
1. 分析oom打印,确认各个进程物理内存占用情况,是否有明显使用不合理的进程
2. 确认glibc中的malloc缓存机制
3. Free、/proc/meminfo确认内存是否在逐步减少
4. 内存泄漏问题定位
5. 内存优化:栈、数据段、代码段优化
6. 其他优化点:drop_cache、线程裁剪、程序瘦身、结构体裁剪等
1、oom__killer概念介绍
oom__killer(out of memory killer)是Linux内核的一种内存管理机制,在系统可用内存较少的情况下,内核为保证系统还能够继续运行下去,会选择杀掉一些进程释放掉一些内存。
通常oom_killer的触发流程是:进程A想要分配物理内存(通常是当进程真正去读写一块内核已经“分配”给它的内存)->触发缺页异常->内核去分配物理内存->物理内存不够了,触发OOM。
一句话说明oom_killer的功能:当系统物理内存不足时,oom_killer遍历当前所有进程,根据进程的内存使用情况进行打分,然后从中选择一个分数最高的进程,杀之取内存。另外可能是内核驱动、内存碎片化严重等问题也会触发OOM。
2、oom问题分析
2.1oom日志分析
1、谁触发OOM
在系统触发OOM时,都会有现场信息打印,例如下面的:

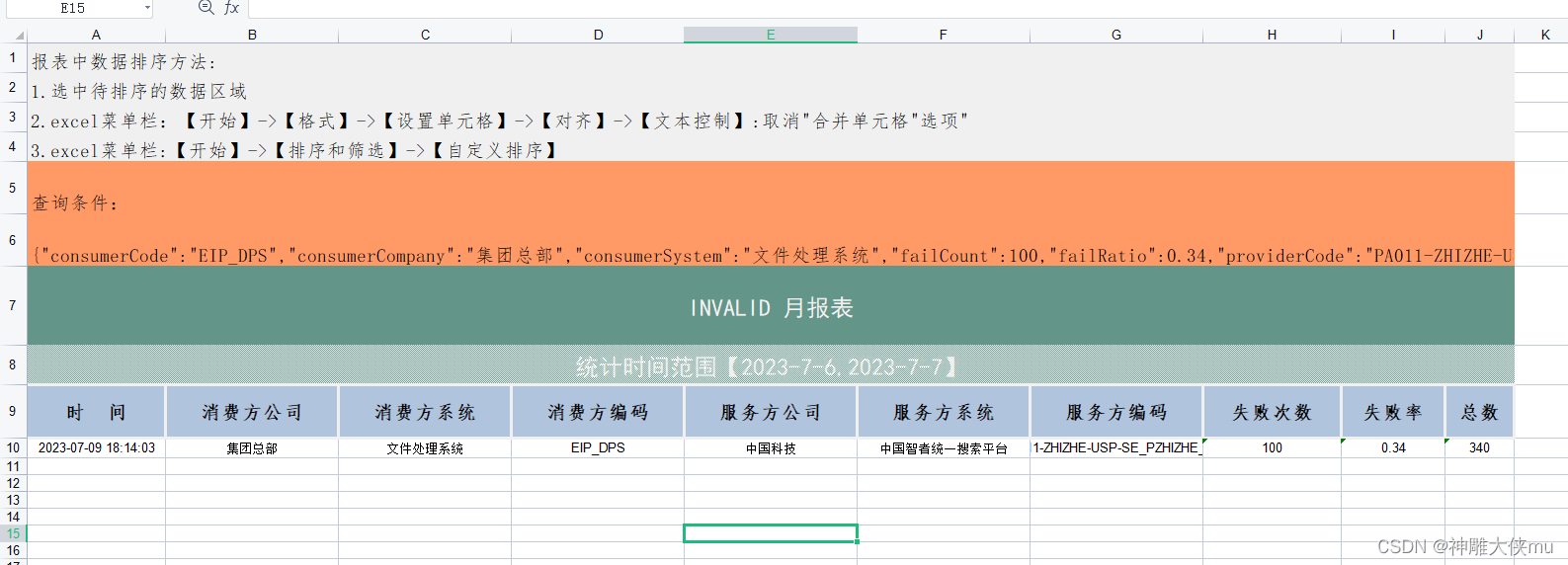
先来看一下第一行,它给出了oom killer是由谁触发的信息,order=0告诉我们所请求的内存的大小是多少,即ai0_P0_MAIN请求了2的0次方这么多个page的内存,也就是一个page(4KB)。
2、oom时内存情况

可以看到normal区free的内存只有4084KB,比系统允许的最小值(min)还要低,这意味着application已经无法再从系统中申请到内存了,并且系统会开始启动oom killer来缓解系统内存压力。
这里我们说一下一个常见的误区,就是有人会认为触发了oom-killer的进程就是问题的罪魁祸首,比如我们这个例子中的这个ai0_P0_MAIN进程。其实日志中invoke oom-killer的这个进程有时候可能只是一个受害者,因为其他应用/进程已将系统内存用尽,而这个invoke oomkiller的进程恰好在此时发起了一个分配内存的请求而已。在系统内存已经不足的情况下,任何一个内存请求都可能触发oom killer的启动。
oom-killer的启动会使系统从用户空间转换到内核空间。内核会在短时间内进行大量的工作,比如计算每个进程的oom分值,从而筛选出最适合杀掉的进程。我们从日志中也可以看到最终杀死的进程。
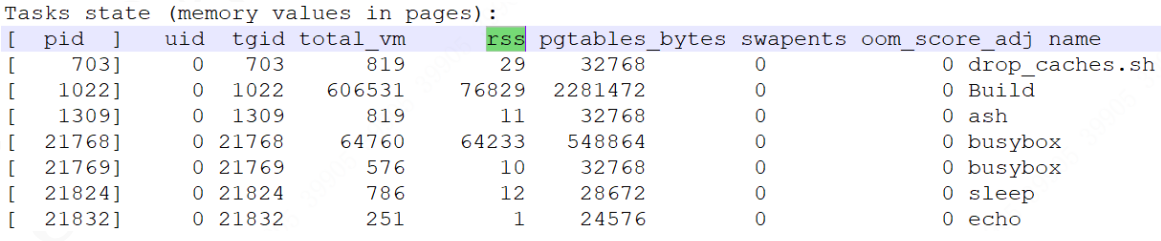
3、进程内存占用分析
Rss是物理内存的占用,可以看到build和busybox占用较多,build是主程序,占用合理,busybox占用250M明显不合理(单位是4KB)。
此oom打印为真实开发案例:由于测试工程师运行测试脚本压力测试,测试脚本大量占用内存导致oom,非问题。
2.2Glibc缓存确认
2.2.1内存站岗问题原因
Glibc使用了ptmalloc的内存管理方式。Glibc申请内存时是从分配区申请的,分为主分配区和非主分配区,分配区都有锁,在分配内存前需要先获取锁,然后再去申请内存。
一般进程都是多线程的,当多个线程同时需要申请内存时,如果只有一个分配区,那么效率太低。glibc为了支持多线程的内存申请释放,会在多个线程同时需要申请内存时根据cpu核数分配一定数量的分配区,将分配区分配给线程。
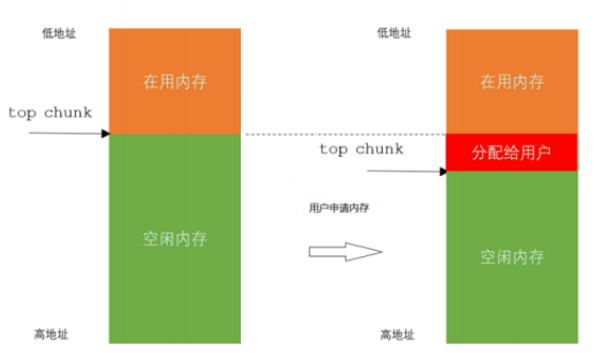
内存申请基本原理:当用户调用malloc申请内存时,glibc会查看是否已经缓存了内存,如果有缓存则会优先使用缓存内存,返回一块符合用户请求大小的内存块。
如果没有缓存或者缓存不足则会去向操作系统申请内存(可通过brk、mmap申请内存),然后切一块内存给用户,如图所示。
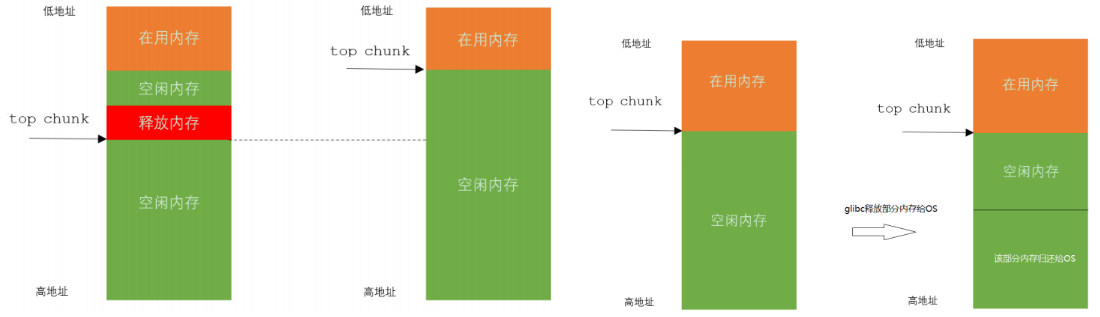
内存释放基本原理:当业务模块使用完毕后调用free释放内存时,glibc会检查该内存块虚拟地址上下内存块的使用状态(fast bin除外)。若其上一块内存空闲,则与上一块内存进行合并。若下一块内存空闲,则与下一块内存进行合并。
若下一块内存时top chunk(top chunk一直是空闲的),则看top chunk的大小是否超过一个阈值,如果超过一个阈值则将其释放给OS,如图所示。
内存站岗概念:内存站岗指的是glibc从OS申请到内存后分配给业务模块,业务模块使用完毕后释放了内存,但是glibc没有将这些空闲内存释放给OS,也就是缓存了很多空闲内存无法归还给系统的现象。
内存站岗原因:glibc设计时就确定其内存是用于短生命周期的,因此在设计上内存释放给OS的时机是当top chunk的大小超过一个阈值时会释放top chunk的一部分内存给OS。当top chunk不超过阈值就不会释放内存给OS。
那么问题来了,若与top chunk相邻的内存块一直在使用中,那么top chunk就永远也不会超过阈值,即便业务模块释放了大量内存,达到几十个G 或者上百个G,glibc也是无法将内存还给OS的。
2.2.2问题确认
在主程序中隔一段时间调用一次malloc_stats、mallinfo,都是glibc提供的函数,用户打印内存分配函数(如malloc、free)的详细调试信息。
代码实现:
static void print_mallinfo()
{
malloc_stats();
struct mallinfo mi = mallinfo();
printf("\t arena=%d, ordblks=%d, smblks=%d, hblks=%d, hblkhd=%d \n\t usmblks=%d, fsmblks=%d, "
"uordblks=%d, fordblks=%d, keepcost=%d\n\n",
mi.arena, /* non-mmapped space allocated from system */
mi.ordblks, /* number of free chunks */
mi.smblks, /* number of fastbin blocks */
mi.hblks, /* number of mmapped regions */
mi.hblkhd, /* space in mmapped regions */
mi.usmblks, /* maximum total allocated space */
mi.fsmblks, /* space available in freed fastbin blocks */
mi.uordblks, /* total allocated space */
mi.fordblks, /* total free space */
mi.keepcost /* top-most, releasable (via malloc_trim) space */
);
}打印内容:
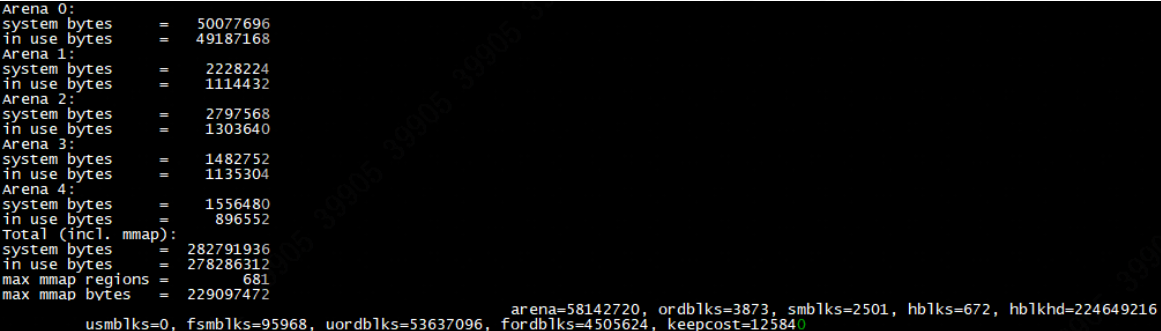
如果系统申请的内存(system bytes)远远大于在使用的内存(in use bytes),那么就怀疑可能是内存站岗问题导致glibc缓存过多。
2.2.3解决办法
1、减少子分配区个数
mallopt(M_ARENA_MAX, 2);2、降低mmap阈值:默认值是128KB
减少内存碎片,大于64KB就直接使用mmap的方式申请内存。
mallopt(M_MMAP_THRESHOLD, 64*1024);3、释放空闲区以减少内存碎片
malloc_trim()当我们通过free()释放区块时,如果相邻的空闲区块可以合并,glibc会将它们合并。但是,如果相邻的空闲区块来自不同的bin,glibc则无法将它们合并,这就会产生内存碎片。malloc_trim()的作用就是尝试释放这些未能合并但空闲的小区块,尽量减少内存碎片
malloc_trim可以在可用内存小图某个阈值之后隔一段时间调用一次。
2.3内存泄漏
2.3.1确认是否发生泄漏
内存泄漏排查的前提一定是确认存在泄漏的,经过2.2章节首先排除Glibc缓存的影响,那怎样就认为是发生了内存泄漏呢?
随着程序运行,占用内存大小持续增长,及时程序闲置也是如此,那我们认为是存在内存泄漏的。
Meminfo查看,free和MemAvailable都在逐步减少,直至oom死机,那么就是存在内存泄漏问题的。
# cat /proc/meminfo
MemTotal: 365924 kB //总内存大小
MemFree: 74584 kB //剩余内存
MemAvailable: 251220 kB //可用内存:包含了部分buffer和cache
Buffers: 58952 kB //设备操作缓存,如访问/dev/sda1
Cached: 164596 kB //文件操作缓存,如访问某个文件2.3.2泄漏源定位
内存泄漏定位还是蛮多的:ASAN、valgrind、gperfTools、malloc重载等,在之前文章中我们已经介绍过了,读者可根据自己的需求进行选择。
详见:内存泄漏问题排查
3、内存优化
在经过第二章的学习,我们已经可以排除Glibc缓存和内存泄漏问题导致的内存不足死机了,本章我们开始学习如何进行内存优化,发现我们程序中的不合理使用。
3.1栈内存优化
在之前文章我们已经讲解过了,详见:栈上局部变量定义过大导致设备oom
大概思路:
1、ulimit –a确认栈内存大小;如:4096KB
2、通过cat proc/PID/smaps命令查看此进程中内存的申请信息,并搜索所有的4096KB为栈内存
3、依次查看每个栈对应的真实物理内存Rss,可能绝大多数都是30KB以下,超过100KB的我们就需要关注一下是否代码实现时定义了超大的局部变量
4、反汇编搜索“sp, sp, #”字段,后面跟随着是栈的大小
5、可以使用脚本处理,按照大小排序,从上至下按照栈大小结合代码逐一排查
3.2堆内存优化
堆内存的优化首先得确认何处申请了堆内存,堆内存申请的小,才能确认此处的堆内存申请是否合理,一般方法:
1. 使用gerftools,打印出所有内存申请的堆栈,按照从打到小排序,确认内存申请是否合理。(不推荐)
2. 各个模块实现自己的调试信息,在malloc前进行封装,每次的申请和释放内存管理起来,可用调试命令查看各模块申请未释放的内存大小、名字,各模块独自结合代码分析占用是否合理。(推荐)
3. Malloc重载,所有申请未释放的内存打堆栈,依次解析出符号分析。(不推荐)
3.3数据段
在之前文章我们已经讲解过了,详见:《【内存】数据段大小分析.docx》
数据段的分析主要包含:.bss、.rodata、.data段
大体思路:
1. 使用nm打印出不各个数据段中发符号的地址、大小、变量名称:arm-linux-nm --format=sysv build | grep .bss > bss.txt
2. 使用脚本提取变量名称和大小
3. 按照大小排序,从大到小依次优化每个变量
3.4代码段
在之前文章我们已经讲解过了,详见:《【内存】代码段大小分析.docx》
大体思路:
1. 生成可执行程序build的反汇编文件
arm-mix410-linux-objdump -d build > objdump.log2. nm解析执行程序依赖的各个库,并针对每个库生成一个符号文件
arm-mix410-linux-nm -A lib*.a | grep T > ./*.a.log3. 依次遍历每个*.a.log文件,解析出函数名,在objdump.log文件中搜索,确认开始地址和结束地址以及函数代码段大小,生成*.a.log.ok文件
4. 依次遍历每个*.a.log.ko文件,计算每个库的代码段大小
3.5其他优化项
3.5.1drop_cache
定期释放linux的page cache和reclaimable slab cache,加快内存回收:
#清理文件页、目录项、inodes等各种缓存
$echo 3 > /proc/sys/vm/drop_caches3.5.2线程裁剪
在实际的大型项目中,由于代码的不断演进,维护人员的不断变化,会存在很多无效的线程,如:
1. A项目使用的线程,B项目无需创建,但是由于代码没有做相应的控制,即使B项目部需要,但是仍然创建了
2. 某个业务功能,根据用户个数或者通道个数来创建线程,每新增一路则新增一个线程,但实际上多个对象共用一个线程也是能处理过来的。
增对上述情况,我们可以先查看线程个数,然后增加每个线程进行优化:
1. gdb thread apply all bt:查看所有线程,并结合代码依次确认其合理性
2. pidstat查看:查看pid对应的所有线程
./pidstat -p pid -t 注:
1. 想在上述两种方法中看到线程名字,需要在线程执行体中调用:
prctl(PR_SET_NAME, "thread_name"); //注意是在线程执行体中调用2. 优化出的物理内存并不是ulimit所看到的线程大小,ulimit对应的是虚拟内存,物理内存实际没这么大
3.5.3程序瘦身
针对ko驱动、动态库和可执行程序,进行strip,删除调试信息
strip -S lib_exe_name缺点:调试时不方便,无法解析符号
3.5.4结构体裁剪
减少复杂嵌套结构体的大小:
1. 根据情况减小数组下标
2. 根据本产品业务需求,可用编译宏进行控制处理,删除较大的无效结构体成员
3.5.5内存文件系统
Mount查看当前设备挂载情况,找到/dev/mem行,/dev/mem是将后面的目录挂载到内存,目录中文件是存储在内存中的,可以对该目录中文件大小做一个优化。
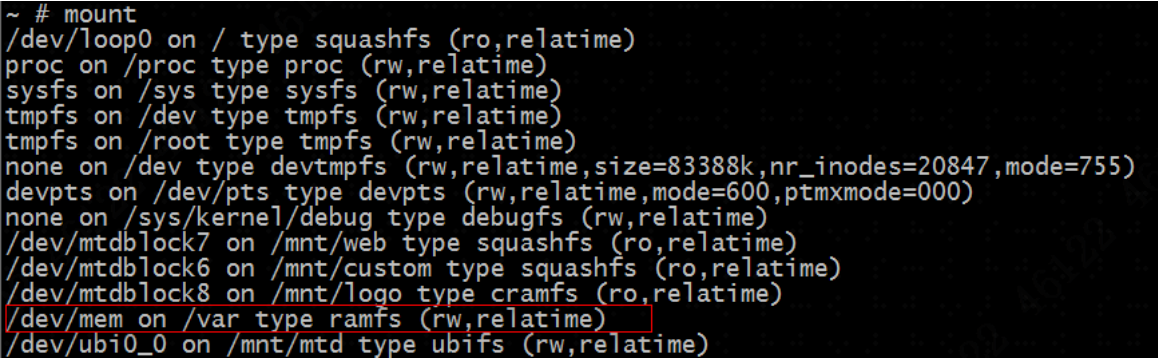
查看/var目录,对/var目录做一个优化。
3.5.6驱动加载
驱动加载也会申请内存,一些无用的驱动可以取消加载
4、总结
本文总结介绍了项目开发过程中oom排查和内存优化的一些方法,主要是从内存问题查看到堆内存、栈内存、数据段内存优化为导向,结合实际优化实例介绍工具和方法的运用,展示每种优化方法优化过程,希望对读者有所帮助。