前端mock数据的几种方式
前端在开发具体需求前,后端往往只提供接口文档,对于前端来说,最简单的方式就是把想要的数据写死在代码里进行开发,但这样的坏处就是和后端联调前还需要再把写死的数据从代码里删除,最好的方式是无侵入的 mock 。
文章将mock数据的方法总结为4类
- 死数据
- 重写请求方法(
xhr/fetch) node服务- 浏览器拦截
死数据
这种方法是最简单的,直接在相关方法里写死数据即可。
比如:
function login() {
// 直接写死userInfo,先不通过接口获取
const userInfo = { account: 'account', token: 'abcdef' };
}
对于小型项目而言,用这种方式就可以非常省时省力,不过大型项目或者页面数据非常多的项目则不太适合,后期对接的时候也需要花费一定的时间更改。
重写请求方法(xhr/fetch)
json文件
在项目中创建一个json文件,把所有mock数据都放在这个文件中。
{
"login": {
"code": 200,
"msg": "成功",
"data": {
"token": "abcdefg"
}
},
"logout": {
"code": 200,
"msg": "成功"
}
}
之后重写xhr、fetch方法,将请求直接拦截,并返回json文件中定义的假数据中。
文章只介绍简单的重写fetch方法,xhr方法其实非常类似,就不介绍了,如果大家感兴趣,可以自行实现。
const _fetch = fetch;
fetch = function (input) {
if (api[input]) {
return new Promise((resolve) => {
resolve(api[input]);
});
} else {
return _fetch.call(null, ...arguments);
}
};
在上面的方法中,从json文件中读取到所有需要拦截的mock数据,只有当没有找到未定义的mock路径时,才会调用原始的fetch方法发送请求去获取。
上述的完整代码如下:
<script type="text/javascript" src="./api.json"></script>
<script src="./index.js"></script>
<script>
fetch('login').then(res => {
console.log(res)
})
</script>
由于浏览器无法直接读取本地文件,因此通过script标签引入json文件(在json文件中定义一个api变量指向json数据,对于一些IDE规则验证无法通过,可能导致无法保存,可以把json后缀改成js)。
此demo演示只是用来讲解重写请求方法思路且只使用html开发的一些简单页面。而且现在github上也有很多开源的mock数据的三方库,大家在开发时基本上直接引入这些库进行使用即可。
Mock.js
Mock.js是一个模拟数据生成器,可以让前端独立于后端进行开发,其实原理也是通过拦截 XHR 和 fetch 请求,并返回自定义的数据类型。
Mock.mock("/login", {
code: 200,
msg: "成功",
data: {
token: "abcdefg",
},
});
fetch("/api/data", {
method: "POST",
})
.then((response) => response.json())
.then((json) => console.log(json));
而且Mock.js有一个好处就是可以通过它既有的语法来生成一些随机的数据(这样就不需要我们手动输入数据了),每次请求都会返回不同的数据。
Mock.mock('http://api.com', {
'name': '@cname', // 中文名称
"age|20-30": 1 // 20~30随机数,1用来确定类型
});
由于请求在发送前被拦截,实际上并没有发送对应的请求,会导致在
Chrome控制台就看不见对应的请求。
当然还有wsm这些非常受欢迎的库,这些就不一一介绍了,感兴趣的朋友们自行去阅读相关使用文档。
启动一个node服务
我们可以使用node服务来模拟创建一个服务端,返回的数据其实也可以参照前面提到的json文件格式。
const fs = require("fs");
const http = require("http");
const app = http.createServer((req, res) => {
const file = JSON.parse(fs.readFileSync("./api.json", "utf-8"));
if (file[req.url]) {
res.end(file[req.url]);
} else {
res.end({ code: 200 });
}
});
app.listen(3000, () => {
console.log("server start");
});
以上也是一个非常简单的例子,可以根据需求来使用express或者koa框架来实现一个更完善的mock服务。
webpack搭建项目
在使用vue2或者webpack搭建项目的时候,webpack内部其实已经启动了一个node服务,用的是Express ,而且它们是同一个团队开发的。
既然已经有了一个 http 服务器,所以也没必要再开启另一个新的http服务了,通过给 webpack 传递一个函数,重写返回的数据即可。
只需要通过 setupMiddlewares 重写数据即可。
const path = require("path");
module.exports = {
entry: "./src/main.js",
output: {
path: path.resolve(__dirname, "./dist"),
filename: "bundle.js",
},
devServer: {
static: path.resolve(__dirname, "./dist"),
setupMiddlewares: (middlewares, devServer) => {
if (!devServer) {
throw new Error("webpack-dev-server is not defined");
}
middlewares.unshift({
path: "/login",
middleware: (req, res) => {
// mock 数据模拟接口数据
res.send({
code: 200,
msg: "成功",
data: {
token: "abcdefg",
},
});
},
});
return middlewares;
},
},
};
使用mock网站生成
其实这个也类似于node服务,不过不需要自行写一个mock服务而已,直接在网站上配置即可。
比如easy mock、fastmock
浏览器拦截
just mock
just mock 是一个浏览器插件,在代码中什么都不需要更改,只需要添加相应的接口和数据即可实现拦截。
在just mock网站中下载对应的压缩包,在chrome中加载已解压的扩展程序即可进行使用。

接着进行相应的编辑添加对应的 mock 数据就好。
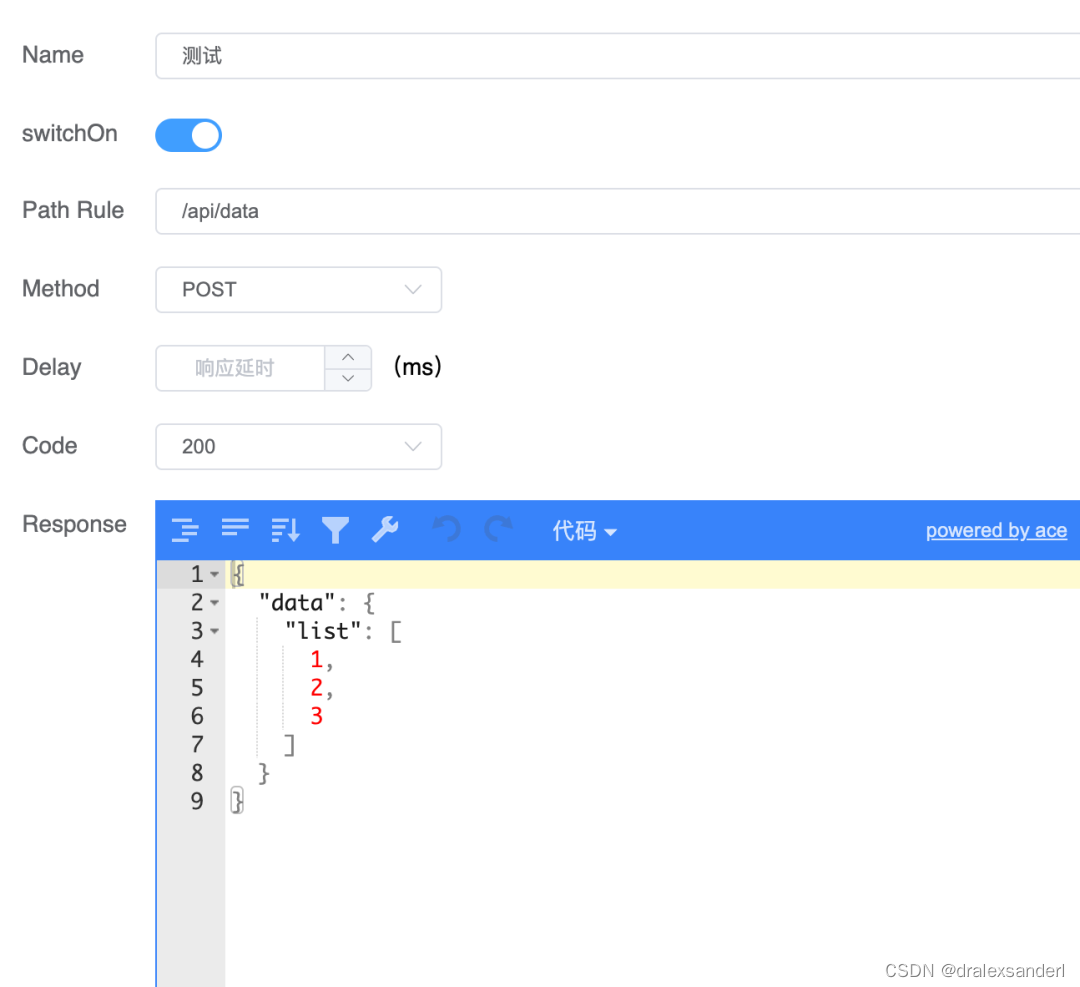
这样接口就会被拦截。
浏览器插件原理和
mockjs是一样的,但会更加轻便,无需融入到代码中。两者的原理是一样的,都是在网络请求前重写了全局的xhr和fetch