目录
kmalloc 内存池中都有哪些尺寸的内存块
kmalloc 内存池如何选取合适尺寸的内存块
kmalloc 内存池的整体架构
KMALLOC_RECLAIM 表示需要分配可以被回收的内存,RECLAIM 类型的内存页,不能移动,但是可以直接回收,比如文件缓存页,它们就可以直接被回收掉,当再次需要的时候可以从磁盘中读取生成。或者一些生命周期比较短的内存页,比如 DMA 缓存区中的内存页也是可以被直接回收掉。编辑 kmalloc 内存池如何进行内存的分配与回收
参考文献
kmalloc 内存池体系的底层基石是基于 slab alloactor 体系构建的,其本质其实就是各种不同尺寸的通用 slab cache。

kmalloc 内存池中都有哪些尺寸的内存块
内核将这些不同尺寸的 slab cache 分类信息定义在 kmalloc_info[] 数组中,数组中的元素类型为 kmalloc_info_struct 结构,里边定义了对应尺寸通用内存池的相关信息。
const struct kmalloc_info_struct kmalloc_info[];
/* A table of kmalloc cache names and sizes */
extern const struct kmalloc_info_struct {
// slab cache 的名字
const char *name;
// slab cache 提供的内存块大小,单位为字节
unsigned int size;
} kmalloc_info[];-
size 用于指定该 slab cache 中所管理的通用内存块尺寸。
-
name 为该通用 slab cache 的名称,名称形式为
kmalloc-内存块尺寸(单位字节),这一点我们可以通过cat /proc/slabinfo命令查看。
const struct kmalloc_info_struct kmalloc_info[] __initconst = {
{NULL, 0}, {"kmalloc-96", 96},
{"kmalloc-192", 192}, {"kmalloc-8", 8},
{"kmalloc-16", 16}, {"kmalloc-32", 32},
{"kmalloc-64", 64}, {"kmalloc-128", 128},
{"kmalloc-256", 256}, {"kmalloc-512", 512},
{"kmalloc-1k", 1024}, {"kmalloc-2k", 2048},
{"kmalloc-4k", 4096}, {"kmalloc-8k", 8192},
{"kmalloc-16k", 16384}, {"kmalloc-32k", 32768},
{"kmalloc-64k", 65536}, {"kmalloc-128k", 131072},
{"kmalloc-256k", 262144}, {"kmalloc-512k", 524288},
{"kmalloc-1M", 1048576}, {"kmalloc-2M", 2097152},
{"kmalloc-4M", 4194304}, {"kmalloc-8M", 8388608},
{"kmalloc-16M", 16777216}, {"kmalloc-32M", 33554432},
{"kmalloc-64M", 67108864}
};从 kmalloc_info[] 数组中我们可以看出,kmalloc 内存池体系理论上最大可以支持 64M 尺寸大小的通用内存池。
kmalloc_info[] 数组中的 index 有一个特点,从 index = 3 开始一直到数组的最后一个 index,这其中的每一个 index 都表示其对应的 kmalloc_info[index] 指向的通用 slab cache 尺寸,也就是说 kmalloc 内存池体系中的每个通用 slab cache 中内存块的尺寸由其所在的 kmalloc_info[] 数组 index 决定,对应内存块大小为:2^index 字节,比如:
-
kmalloc_info[3] 对应的通用 slab cache 中所管理的内存块尺寸为 8 字节。但是这里的 index = 1 和 index = 2 是个例外,内核单独支持了 kmalloc-96 和 kmalloc-192 这两个通用 slab cache。它们分别管理了 96 字节大小和 192 字节大小的通用内存块。这些内存块的大小都不是 2 的次幂。
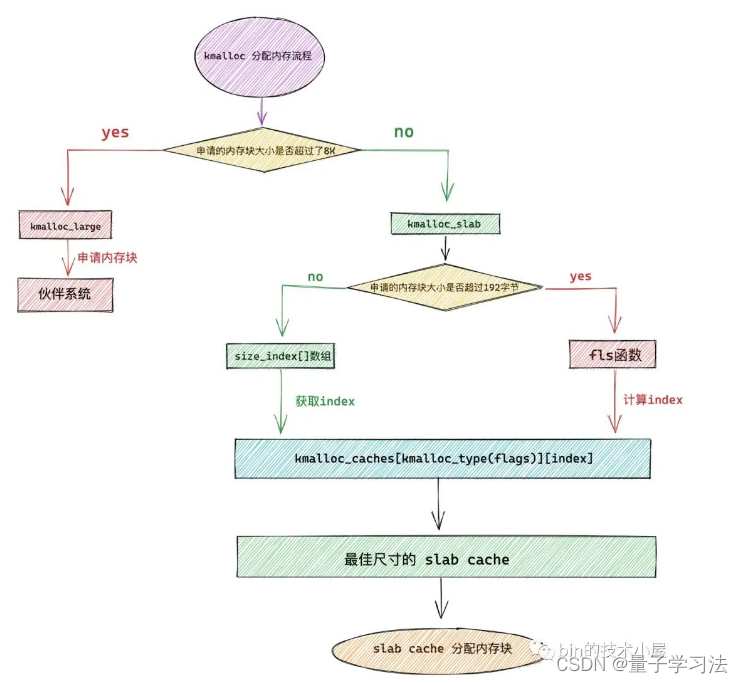
kmalloc 内存池如何选取合适尺寸的内存块
既然 kmalloc 体系中通用内存块的尺寸分布信息可以通过一个数组 kmalloc_info[] 来定义,那么同理,最佳内存块尺寸的选取规则也可以被定义在一个数组中。
内核通过定义一个 size_index[24] 数组来存放申请内存块大小在 192 字节以下的 kmalloc 内存池选取规则。
其中 size_index[24] 数组中每个元素后面跟的注释部分为内核要申请的字节数,size_index[24] 数组中每个元素表示最佳合适尺寸的通用 slab cache 在 kmalloc_info[] 数组中的索引。
static u8 size_index[24] __ro_after_init = {
3, /* 8 */
4, /* 16 */
5, /* 24 */
5, /* 32 */
6, /* 40 */
6, /* 48 */
6, /* 56 */
6, /* 64 */
1, /* 72 */
1, /* 80 */
1, /* 88 */
1, /* 96 */
7, /* 104 */
7, /* 112 */
7, /* 120 */
7, /* 128 */
2, /* 136 */
2, /* 144 */
2, /* 152 */
2, /* 160 */
2, /* 168 */
2, /* 176 */
2, /* 184 */
2 /* 192 */
};size_index 数组只是定义申请内存块在 192 字节以下的 kmalloc 内存池选取规则,当申请内存块的尺寸超过 192 字节时,内核会通过 fls 函数来计算 kmalloc_info 数组中的通用 slab cache 索引。
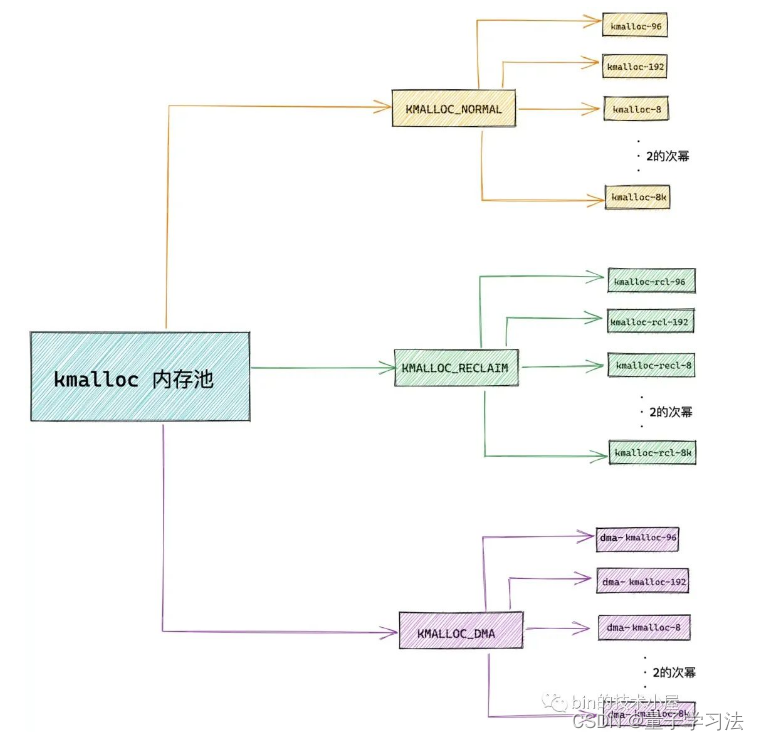
kmalloc 内存池的整体架构
kmalloc 内存池的本质其实还是 slab 内存池,底层依赖于 slab alloactor 体系,在 kmalloc 体系的内部,管理了多个不同尺寸的 slab cache,kmalloc 只不过负责根据内核申请的内存块尺寸大小来选取一个最佳合适尺寸的 slab cache

kmalloc 内存池中的内存来自于上面的 ZONE_DMA 和 ZONE_NORMAL 物理内存区域,也就是内核虚拟内存空间中的直接映射区域。

-
KMALLOC_NORMAL 表示 kmalloc 需要从 ZONE_NORMAL 物理内存区域中分配内存。
-
KMALLOC_DMA 表示 kmalloc 需要从 ZONE_DMA 物理内存区域中分配内存。
-
KMALLOC_RECLAIM 表示需要分配可以被回收的内存,RECLAIM 类型的内存页,不能移动,但是可以直接回收,比如文件缓存页,它们就可以直接被回收掉,当再次需要的时候可以从磁盘中读取生成。或者一些生命周期比较短的内存页,比如 DMA 缓存区中的内存页也是可以被直接回收掉。
 kmalloc 内存池如何进行内存的分配与回收
kmalloc 内存池如何进行内存的分配与回收
参考文献
深度解读 Linux 内核级通用内存池 —— kmalloc 体系