目录
Elasticsearch集群_测试集群状态
Elasticsearch集群_故障应对&水平扩容
Elasticsearch优化_磁盘选择
Elasticsearch优化_分片策略
Elasticsearch优化_内存设置
Elasticsearch案例_需求说明
Elasticsearch案例_ES自动补全
Elasticsearch案例_创建索引
Elasticsearch案例_准备数据
Elasticsearch案例_项目搭建
Elasticsearch案例_创建实体类
Elasticsearch案例_创建Repository接口
Elasticsearch案例_自动补全功能
Elasticsearch案例_搜索关键字功能
Elasticsearch案例_创建Controller类
Elasticsearch案例_前端页面
Elasticsearch集群_测试集群状态

1、在集群中创建一个索引
PUT /product1
{
"settings": {
"number_of_shards": 5, // 分片数
"number_of_replicas": 1 // 每个分片的副本数
},
"mappings": {
"properties": {
"id": {
"type": "integer",
"store": true,
"index": true
},
"productName": {
"type": "text",
"store": true,
"index": true
},
"productDesc": {
"type": "text",
"store": true,
"index": true
}
}
}
}2、查看集群状态
# 查看集群健康状态
GET /_cat/health?v
# 查看索引状态
GET /_cat/indices?v
# 查看分片状态
GET /_cat/shards?v实时学习反馈
1. 在Elasticsearch中,查看集群健康状态的请求路径为
A /_cat/nodes
B /_cat/health?v
C /_cat/indices?v
D /_cat/shards?v
2. 在Elasticsearch中,查看集群分片状态的请求路径为
A /_cat/nodes
B /_cat/health?v
C /_cat/indices?v
D /_cat/shards?v
Elasticsearch集群_故障应对&水平扩容

1 关闭一个节点,可以发现ES集群可以自动进行故障应对。
2 重新打开该节点,可以发现ES集群可以自动进行水平扩容。
3 分片数不能改变,但是可以改变每个分片的副本数:
PUT /索引/_settings
{
"number_of_replicas": 副本数
}
实时学习反馈
1. 关于Elasticsearch集群,以下说法正确的是
A ES集群不可以自动进行水平扩容
B ES集群分片数不能改变
C ES集群分片数可以改变
D ES集群副本数不能改变
Elasticsearch优化_磁盘选择

ES的优化即通过调整参数使得读写性能更快
磁盘通常是服务器的瓶颈。Elasticsearch重度使用磁盘,磁盘的效 率越高,Elasticsearch的执行效率就越高。这里有一些优化磁盘的技巧:
1、使用SSD(固态硬盘),它比机械磁盘优秀多了。
2、使用RAID0模式(将连续的数据分散到多个硬盘存储,这样可以并行进行IO操作),代价是一块硬盘 发生故障就会引发系统故障。
3、不要使用远程挂载的存储。
实时学习反馈
1. 关于Elasticsearch磁盘优化,说法错误的是
A 机械磁盘比固态硬盘优秀
B 固态硬盘比机械磁盘优秀
C RAID0模式可以并行进行IO操作
D 不要使用远程挂载的存储
Elasticsearch优化_分片策略

分片和副本数并不是越多越好。每个分片的底层都是一个Lucene索 引,会消耗一定的系统资源。且搜索请求需要命中索引中的所有分 片,分片数过多会降低搜索性能。索引的分片数需要架构师和技术 人员对业务的增长有预先的判断,一般来说我们遵循以下原则:
1、每个分片占用的硬盘容量不超过ES的最大JVM的堆空间设置(一 般设置不超过32G)。比如:如果索引的总容量在500G左右, 那分片数量在16个左右即可。
2、分片数一般不超过节点数的3倍。比如:如果集群内有10个节 点,则分片数不超过30个。
3、推迟分片分配:节点中断后集群会重新分配分片。但默认集群会 等待一分钟来查看节点是否重新加入。我们可以设置等待的时 长,减少重新分配的次数:
PUT /索引/_settings { "settings":{ "index.unassianed.node_left.delayed_timeout":"5m" } }4、减少副本数量:进行写入操作时,需要把写入的数据都同步到副 本,副本越多写入的效率就越慢。我们进行大批量进行写入操作 时可以先设置副本数为0,写入完成后再修改回正常的状态。
实时学习反馈
1. 关于Elasticsearch分片策略,说法正确的是
A 每个分片占用的硬盘容量一般不超过32G
B 分片数一般不超过节点数的3倍
C 进行大批量进行写入操作时可以先设置副本数为0,写入完成后 再修改回正常状态
D 以上说法都正确
Elasticsearch优化_内存设置

ES默认占用内存是4GB,我们可以修改config/jvm.option设置ES的 堆内存大小,Xms表示堆内存的初始大小,Xmx表示可分配的最大内存。
1、Xmx和Xms的大小设置为相同的,可以减轻伸缩堆大小带来的压力。
2、Xmx和Xms不要超过物理内存的50%,因为ES内部的Lucene也要占据一部分物理内存。 3、Xmx和Xms不要超过32GB,由于Java语言的特性,堆内存超过32G会浪费大量系统资源,所以在内 存足够的情况下,最终我们都会采用设置为31G:
-Xms 31g -Xmx 31g例如:在一台128GB内存的机器中,我们可以创建两个节点,每个 节点分配31GB内存。
实时学习反馈
1. 关于Elasticsearch内存设置,说法正确的是
A Xmx和Xms的大小设置为相同的
B Xmx和Xms不要超过物理内存的50%
C Xmx和Xms不要超过32GB
D 以上说法都正确
Elasticsearch案例_需求说明
接下来我们使用ES模仿百度搜索,即自动补全+搜索引擎效果:
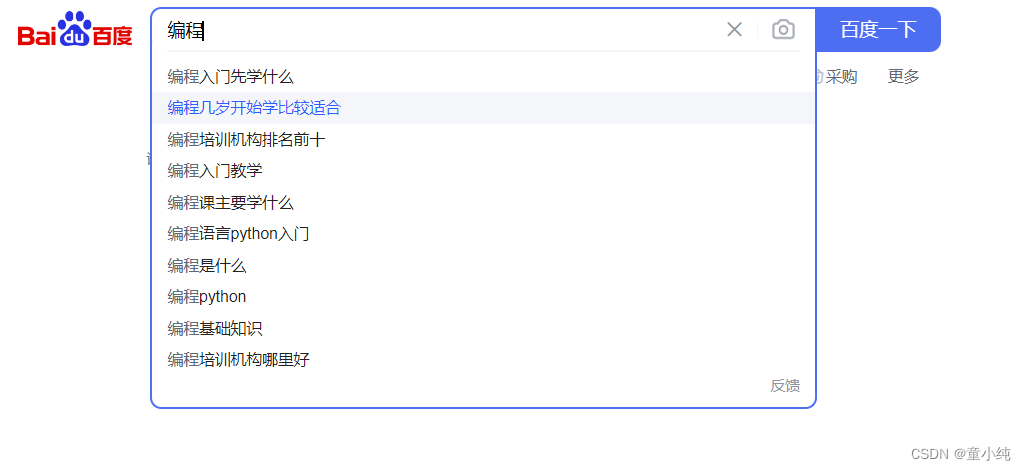

Elasticsearch案例_ES自动补全
es为我们提供了关键词的自动补全功能:
GET /索引/_search
{
"suggest": {
"prefix_suggestion": {// 自定义推荐名
"prefix": "elastic",// 被补全的关键字
"completion": {
"field": "productName",// 查询的域
"skip_duplicates": true, //忽略重复结果
"size": 10 //最多查询到的结果数
}
}
}
}注:自动补全对性能要求极高,ES不是通过倒排索引来实现 的,所以需要将对应的查询字段类型设置为completion。
PUT /product2
{
"mappings":{
"properties":{
"id":{
"type":"integer",
"store":true,
"index":true
},
"productName":{
"type":"completion"
},
"productDesc":{
"type":"text",
"store":true,
"index":true
}
}
}
}
POST /product2/_doc
{
"id":1,
"productName":"elasticsearch1",
"productDesc":"elasticsearch1 is a goodsearch engine"
}
POST /product2/_doc
{
"id":2,
"productName":"elasticsearch2",
"productDesc":"elasticsearch2 is a goodsearch engine"
}
POST /product2/_doc
{
"id":3,
"productName":"elasticsearch3",
"productDesc":"elasticsearch3 is a goodsearch engine"
}Elasticsearch案例_创建索引
PUT /news
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"ik_pinyin": {
"tokenizer": "ik_smart",
"filter":"pinyin_filter"
},
"tag_pinyin": {
"tokenizer": "keyword",
"filter":"pinyin_filter"
}
},
"filter": {
"pinyin_filter": {
"type": "pinyin",
"keep_joined_full_pinyin": true,
"keep_original": true,
"remove_duplicated_term": true
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "integer",
"index": true
},
"title": {
"type": "text",
"index": true,
"analyzer": "ik_pinyin",
"search_analyzer":"ik_smart"
},
"content": {
"type": "text",
"index": true,
"analyzer": "ik_pinyin",
"search_analyzer":"ik_smart"
},
"url": {
"type": "keyword",
"index": true
},
"tags": {
"type": "completion",
"analyzer": "tag_pinyin",
"search_analyzer":"tag_pinyin"
}
}
}
}Elasticsearch案例_准备数据
使用logstash工具可以将mysql数据同步到es中:
1、解压logstash-7.17.0-windows-x86_64.zip
logstash要和elastisearch版本一致
2、在解压路径下的/config中创建mysql.conf文件,文件写入以下 脚本内容:
input {
jdbc {
jdbc_driver_library => "E:\新课\Elasticsearch\软件\案例\mysql-connector-java-5.1.37-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql:///news"
jdbc_user => "root"
jdbc_password => "root"
schedule => "* * * * *"
jdbc_default_timezone => "Asia/Shanghai"
statement => "SELECT * FROM news;"
}
}
filter {
mutate {
split => {"tags" => ","}
}
}
output {
elasticsearch {
hosts =>
["192.168.0.187:9200","192.168.0.187:9201","192.168.0.187:9202"]
index => "news"
document_id => "%{id}"
}
}3、在解压路径下打开cmd黑窗口,运行命令:
bin\logstash -f config\mysql.conf4、测试自动补齐
GET /news/_search
{
"suggest": {
"my_suggest": {
"prefix": "li",
"completion": {
"field": "tags",
"skip_duplicates": true,
"size": 10
}
}
}
}Elasticsearch案例_项目搭建
创建Springboot项目,加入SpringDataElasticsearch和SpringMVC 的起步依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>写配置文件:
spring:
elasticsearch:
uris: 192.168.0.187:9200,192.168.0.187:9201,192.168.0.187:9202
logging:
pattern:
console: '%d{HH:mm:ss.SSS} %clr(%-5level) --- [%-15thread] %cyan(%-50logger{50}):%msg%n'
Elasticsearch案例_创建实体类
@Document(indexName = "news")
@Data
public class News {
@Id
@Field
private Integer id;
@Field
private String title;
@Field
private String content;
@Field
private String url;
@CompletionField
@Transient
private Completion tags;
}Elasticsearch案例_创建Repository接口
public interface NewsRepository extends ElasticsearchRepository<News, Integer> {
}
Elasticsearch案例_自动补全功能
@Service
public class NewsService {
@Autowired
private ElasticsearchRestTemplate template;
// 自动补齐
public List<String> autoSuggest(String keyword) {
// 1.创建补全请求
SuggestBuilder suggestBuilder = new SuggestBuilder();
// 2.构建补全条件
SuggestionBuilder suggestionBuilder = SuggestBuilders
.completionSuggestion("tags")
.prefix(keyword)
.skipDuplicates(true)
.size(10);
suggestBuilder.addSuggestion("prefix_suggestion", suggestionBuilder);
// 3.发送请求
SearchResponse response = template.suggest(suggestBuilder,IndexCoordinates.of("news"));
// 4.处理结果
List<String> result = response
.getSuggest()
.getSuggestion("prefix_suggestion")
.getEntries()
.get(0)
.getOptions()
.stream()
.map(Suggest.Suggestion.Entry.Option::getText)
.map(Text::toString)
.collect(Collectors.toList());
return result;
}
}Elasticsearch案例_搜索关键字功能
在repository接口中添加高亮搜索关键字方法
// 高亮搜索关键字
@Highlight(fields = {@HighlightField(name = "title"), @HighlightField(name = "content")})
List<SearchHit<News>> findByTitleMatchesOrContentMatches(String title, String content);service类中调用该方法
// 查询关键字
public List<News> highLightSearch(String keyword){
List<SearchHit<News>> result = repository.findByTitleMatchesOrContentMatches(keyword, keyword);
// 处理结果,封装为News类型的集合
List<News> newsList = new ArrayList();
for (SearchHit<News> newsSearchHit : result) {
News news = newsSearchHit.getContent();
// 高亮字段
Map<String, List<String>> highlightFields = newsSearchHit.getHighlightFields();
if (highlightFields.get("title") != null){
news.setTitle(highlightFields.get("title").get(0));
}
if (highlightFields.get("content") != null){
news.setContent(highlightFields.get("content").get(0));
}
newsList.add(news);
}
return newsList;
}Elasticsearch案例_创建Controller类
@RestController
public class NewsController {
@Autowired
private NewsService newsService;
@GetMapping("/autoSuggest")
public List<String> autoSuggest(String term){ // 前端使用jqueryUI,发送的参数默认名为term
return newsService.autoSuggest(term);
}
@GetMapping("/highLightSearch")
public List<News> highLightSearch(String term){
return newsService.highLightSearch(term);
}
}
Elasticsearch案例_前端页面
我们使用jqueryUI中的autocomplete插件完成项目的前端实现。
<script>
$("#newsTag").autocomplete({
source: "/autoSuggest", // 请求路径
delay: 100, //请求延迟
minLength: 1 //最少输入多少字符像服务器发送请求
})
function search() {
var term = $("#newsTag").val();
$.get("/highLightSearch", {term:term}, function (data) {
var str = "";
for (var i = 0; i < data.length;i++) {
var document = data[i];
str += "<li>" +
" <h4>" +
" <a href='" +document.url + "' target='_blank'>" +document.title + "</a>" +
" </h4> " +
" <p>" +document.content + "</p>" +
" </li>";
}
$("#news").html(str);
})
}
</script>