目录
- 对比学习原理解析
- 构建一个对比学习模型(代码详解)
- 导入库
- 构建简单的神经网络
- 构建对比学习的损失函数
- 开始训练
- 完整代码
对比学习原理解析
对比学习(Contrastive Learning)是一种无监督学习方法,用于从未标记的数据中学习表示。它的目标是通过将相似样本靠近并将不相似样本分开来学习有意义的表示。
对比学习的核心思想是通过最大化相似样本之间的相似性,并最小化不相似样本之间的相似性来训练模型。具体而言,对于每个样本,对比学习会构建一个正样本对和若干个负样本对。正样本对由同一类别或相似的样本组成,而负样本对则由不同类别或不相似的样本组成。然后,模型会被训练以使得正样本对的表示在嵌入空间中更接近,而负样本对的表示则更远离彼此。
对比学习的一个常见应用是自监督学习,其中模型通过利用输入数据的某种变换作为自动生成的标签进行训练。例如,在图像领域,可以通过对图像执行随机裁剪、旋转、遮挡等操作来生成正样本对和负样本对。模型被训练以使得经过变换的两个图像的表示更接近,而不同图像的表示更远离彼此。这样,模型可以学习到具有良好判别性能的图像表示,从而在后续的任务(如分类、检测等)中表现更好。
对比学习的优点之一是它不需要标记数据,因此可以广泛应用于大规模未标记数据集。它还具有较强的泛化能力和可解释性,使得它在许多领域如计算机视觉、自然语言处理和推荐系统等方面受到关注和应用。
图片识别一种对比学习:

加噪声自监督对比学习:
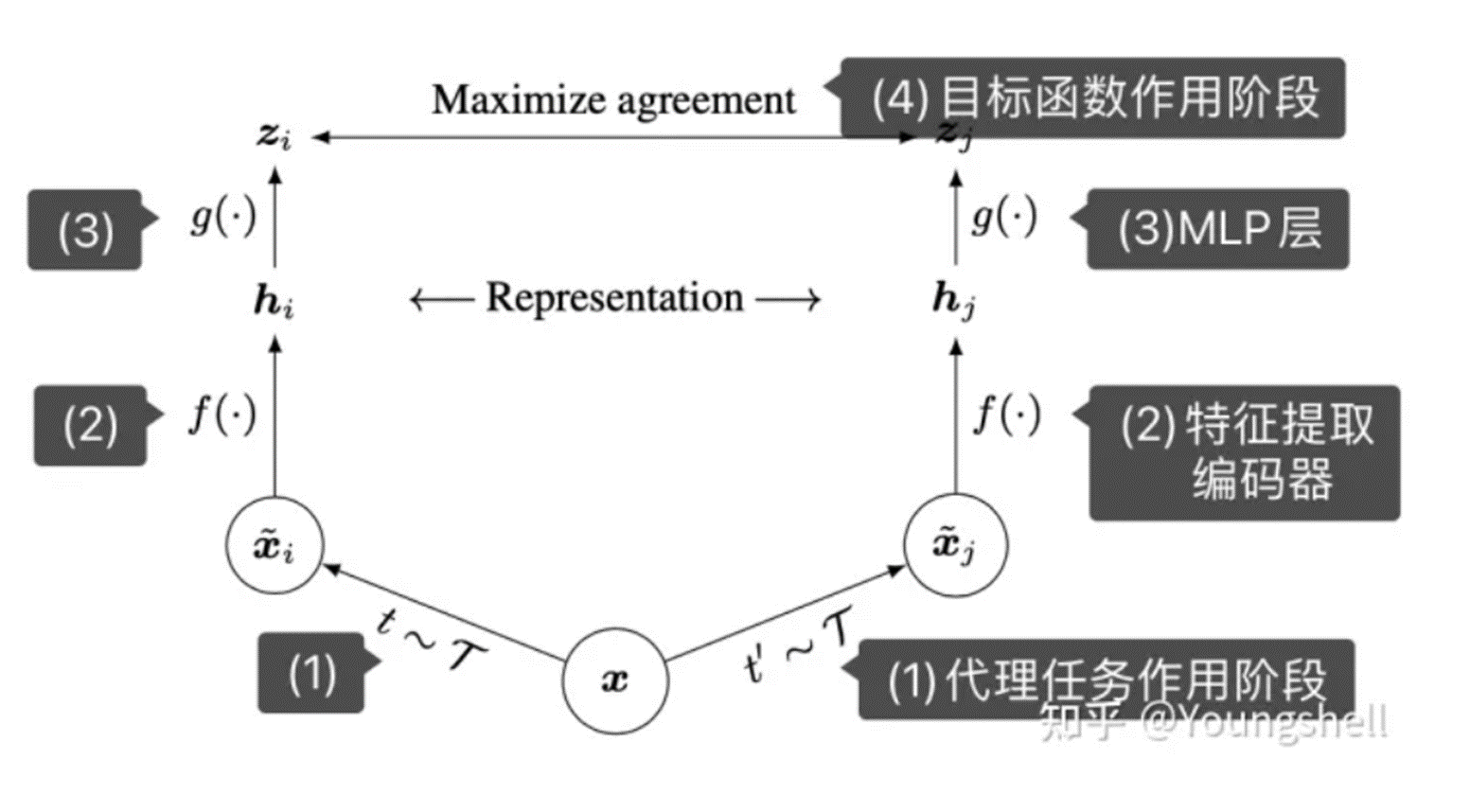
详情请见对比学习解释:https://blog.csdn.net/Exploer_TRY/article/details/116502372
构建一个对比学习模型(代码详解)
导入库
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
构建简单的神经网络
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 5 * 5, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128)
)
def forward(self, x1, x2):
out1 = self.conv(x1)
out1 = out1.view(out1.size(0), -1)
out1 = self.fc(out1)
out2 = self.conv(x2)
out2 = out2.view(out2.size(0), -1)
out2 = self.fc(out2)
return out1, out2
.view() 的作用是将张量转换为指定的形状。这在深度学习中很常见,因为神经网络的输入和输出通常需要特定的形状。通过使用 torch.view(),可以方便地调整张量的维度,以匹配网络的要求。
构建对比学习的损失函数
对比学习的损失函数需要自己构建,基本思想事利用欧式距离等计算两个编码之间的相似度。
class ContrastiveLoss(nn.Module):
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +
label * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
解释:
1、margin 表示一个边界或阈值
用于指定相似性的门槛。它是 Contrastive Loss(对比损失)函数的一个超参数。
Contrastive Loss 旨在鼓励相似样本距离更近,不相似样本距离更远。通过引入 margin 值,我们可以控制样本之间被认为是相似的程度。
具体来说,在计算对比损失时,我们会考虑两个样本输出向量的欧氏距离(euclidean_distance)。如果 label 表示这两个样本是相同类别的,我们希望 euclidean_distance 较小,因为相似的样本应该更接近。反之,如果 label 表示这两个样本是不同类别的,我们希望 euclidean_distance 较大,因为不相似的样本应该相隔较远。
在计算损失时,我们使用以下公式:
loss_contrastive = (1 - label) * euclidean_distance^2 + label * max(margin - euclidean_distance, 0)^2
其中 (1 - label) * euclidean_distance^2 部分表示相似样本的损失,label * max(margin - euclidean_distance, 0)^2 部分表示不相似样本的损失。当 euclidean_distance 小于 margin 时,不相似样本的损失为 0。
因此,margin 控制了相似性的门槛,较小的 margin 值会鼓励更严格的相似性定义,而较大的 margin 值会放宽相似性的限制。通过调整 margin 的取值,可以根据任务需求和数据特点来优化对比学习模型的性能。
2、label 是一个表示样本对是否属于同一类别的标签
它用于计算对比损失(contrastive loss)。
在对比学习中,通常使用成对的样本来构建训练数据集。对每个样本对,label 可以取以下两个值之一:
如果两个样本属于相同的类别或具有相似性,则 label 为 0。
如果两个样本属于不同的类别或具有差异性,则 label 为 1。
通过这种方式,我们可以指定哪些样本是相似的(label=0),哪些样本是不相似的(label=1)。
在损失函数的前向传播方法中,label 用于加权计算对比损失。具体地,当 label=0 时,我们希望 euclidean_distance 较小,因为相似的样本应该更接近;当 label=1 时,我们希望 euclidean_distance 较大,因为不相似的样本应该相隔较远。
因此,label 在对比损失函数中起到了区分相似性和差异性的作用,并用于根据样本对的真实标签调整损失的计算。
3、计算欧式距离pairwise_distance
F.pairwise_distance 是 PyTorch 中的一个函数,用于计算两个张量之间的欧氏距离。它可以用来衡量两个特征向量或样本之间的相似性或差异性。
开始训练
## 加载数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
train_dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=64)
## 构建网络
model = SiameseNetwork()
criterion = ContrastiveLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
## 训练模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(num_epochs):
for batch_idx, (img1, img2, label) in enumerate(train_dataloader):
img1, img2, label = img1.to(device), img2.to(device), label.to(device)
optimizer.zero_grad()
output1, output2 = model(img1, img2)
loss = criterion(output1, output2, label)
loss.backward()
optimizer.step()
if (batch_idx+1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(
epoch+1, num_epochs, batch_idx+1, len(train_dataloader), loss.item()))
# 保存模型
torch.save(model.state_dict(), './model.pt')
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 5 * 5, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128)
)
def forward(self, x1, x2):
out1 = self.conv(x1)
out1 = out1.view(out1.size(0), -1)
out1 = self.fc(out1)
out2 = self.conv(x2)
out2 = out2.view(out2.size(0), -1)
out2 = self.fc(out2)
return out1, out2
class ContrastiveLoss(nn.Module):
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +
label * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
## 加载数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
train_dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=64)
## 构建网络
model = SiameseNetwork()
criterion = ContrastiveLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
## 训练模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(num_epochs):
for batch_idx, (img1, img2, label) in enumerate(train_dataloader):
img1, img2, label = img1.to(device), img2.to(device), label.to(device)
optimizer.zero_grad()
output1, output2 = model(img1, img2)
loss = criterion(output1, output2, label)
loss.backward()
optimizer.step()
if (batch_idx+1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(
epoch+1, num_epochs, batch_idx+1, len(train_dataloader), loss.item()))
# 保存模型
torch.save(model.state_dict(), './model.pt')