文章目录
- 从尾到头打印链表
- 描述
- 示例1
- 示例2
- 思路
- 完整代码
从尾到头打印链表
描述
输入一个链表的头节点,按链表从尾到头的顺序返回每个节点的值(用数组返回)。
如输入{1,2,3}的链表如下图:

返回一个数组为[3,2,1]
0 <= 链表长度 <= 10000
示例1
输入:
{1,2,3}
返回值:
[3,2,1]
示例2
输入:
{67,0,24,58}
返回值:
[58,24,0,67]
思路
看一下链表的结构
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
可以看到,其只能从链表的头部遍历到尾部
要想实现逆序输出,可以使用栈这个数据结构,因为其特点就是后进先出
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
Stack<Integer> stack = new Stack<>(); //创建空栈
while (listNode != null) { //将链表元素压入栈中
stack.push(listNode.val);
listNode = listNode.next;
}
ArrayList<Integer> newList = new ArrayList<>(); //创建返回的列表
if (!stack.empty()) { //空栈则返回空列表
for (int i = stack.size() - 1; i >= 0; i--) {
newList.add(stack.pop());
}
}
return newList;
}
这段代码中最令人疑惑的就是遍历栈的循环条件部分:
for (int i = stack.size() - 1; i >= 0; i--)
可以看到循环体内的pop操作似乎和i的值无关,那么for循环条件判断应该就是用来判断循环次数,但是当把循环的i从0开始时,答案就会报错:
for (int i = 0; i <= stack.size() - 1; i++)
我也不太清楚这是什么原理,然后后面我又尝试使用迭代器进行遍历:
Iterator<Integer> iterator = stack.iterator();
while (iterator.hasNext()) {
int element = iterator.next();
newList.add(element);
}
但是遍历的结果居然是从栈底开始取元素,我也不清楚哪里出了问题。
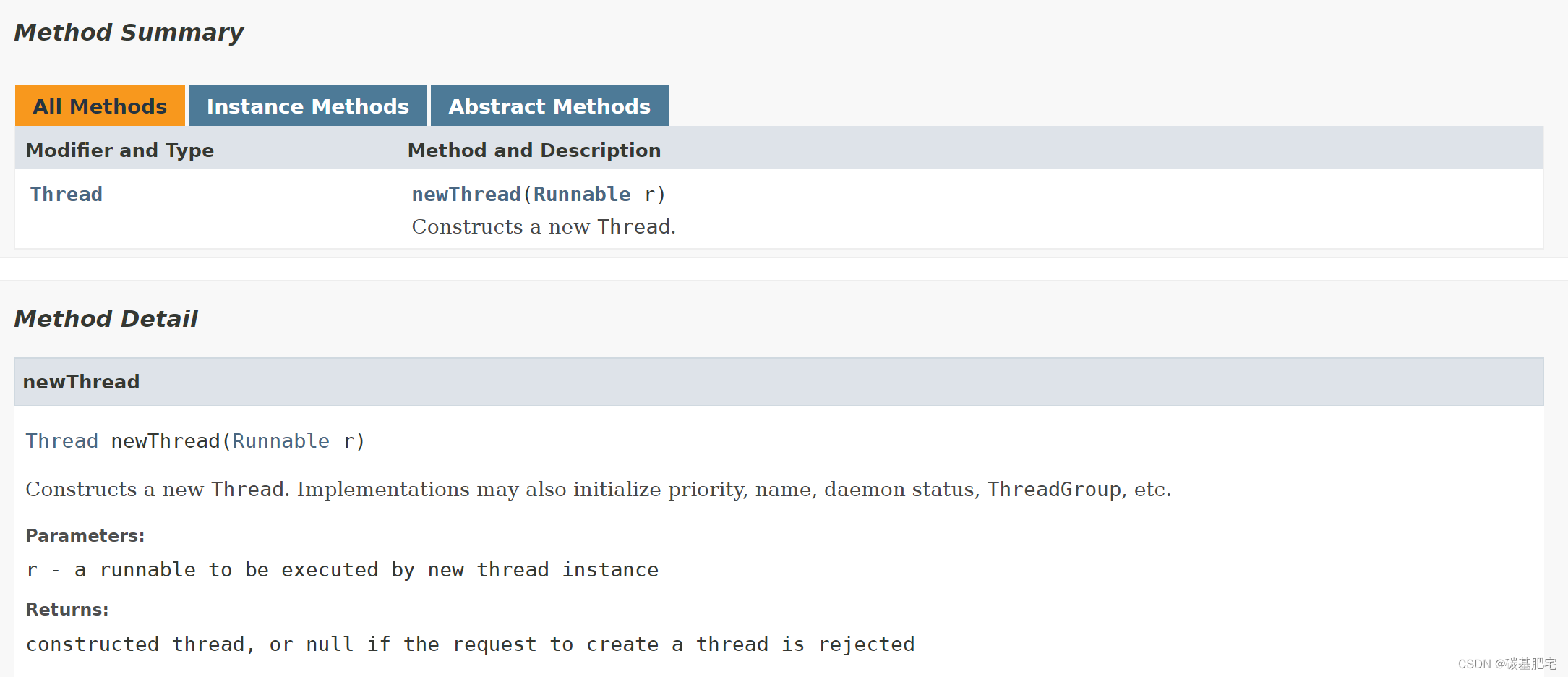
然后看了别人的解法发现,实际上ArrayList这个结构有一个方法add,查看api帮助文档:

这实际上很好的满足了题目要求的条件,因为链表是正向访问的,所以只要将每个访问的元素都存在第一个位置,那么新来的元素就会将旧的元素往后面挤,从而实现最新访问的链表元素会存在ArrayList的第一位,而最早访问的链表元素是存在ArrayList的最后一位,从而实现逆序输出
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
ArrayList<Integer> newList = new ArrayList<>();
while (listNode != null) {
newList.add(0,listNode.val);
listNode = listNode.next;
}
return newList;
}
这种方法比使用stack更简洁明了,而且不会出现那些遍历栈的问题。
完整代码
import java.util.*;
/**
* public class ListNode {
* int val;
* ListNode next = null;
*
* ListNode(int val) {
* this.val = val;
* }
* }
*
*/
import java.util.ArrayList;
public class Solution {
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
ArrayList<Integer> newList = new ArrayList<>();
while (listNode != null) {
newList.add(0,listNode.val);
listNode = listNode.next;
}
return newList;
}
}










![[element-ui] el-descriptions站位,换行用法](https://img-blog.csdnimg.cn/f89c8d6b0bbd49a2852f829ba5113a58.png)