目录
C++11简介
列表初始化
C++98中,{}的初始化问题
内置类型的列表初始化
自定义类型的列表初始化
变量类型推导
auto
decltype
nullptr
范围for循环
final和override
默认成员函数的控制
显式缺省函数
删除默认函数
C++11简介
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为C++11之前的最新C++标准名称。不过由于TC1主要是对C++98标准中的漏洞进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。
相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率。
总之,C++11新增加的特性给我们带来了许多的方便,而且容易实现更多功能。
C++11有一些很重要的点需要我们掌握,其中包括智能指针,右值引用(移动构造,完美转发等),lambda表达式等,而这些我会在后面的章节单独讲解。
列表初始化
C++98中,{}的初始化问题
在C++98中,标准允许使用花括号{}对数组元素进行统一的列表初始值设定。比如:
int array1[] = {1,2,3,4,5};
int array2[5] = {0};对于一些自定义的类型,却无法使用这样的初始化。比如
vector<int> v{1,2,3,4,5};这些STL库中的容器,vector,list,或者map啊等等,都不可以使用{}进行初始化,造成了非常大的麻烦,例如vector只能一个一个数据push_back(),非常的麻烦,所以C++11就支持了这种特性。
{}对于初始化数据的类型也分为两种:
内置类型的列表初始化
int main()
{
// 内置类型变量
int x1 = { 10 };
int x2{ 10 };
int x3 = 1 + 2;
int x4 = { 1 + 2 };
int x5{ 1 + 2 };
// 数组
int arr1[5]{ 1,2,3,4,5 };
int arr2[]{ 1,2,3,4,5 };
// 动态数组,在C++98中不支持
int* arr3 = new int[5]{ 1,2,3,4,5 };
// 标准容器
vector<int> v{ 1,2,3,4,5 };
map<int, int> m{ {1,1}, {2,2},{3,3},{4,4} };
return 0;
}以上都在C++11中被支持。

可以看到都已经被初始化。
注意:列表初始化可以在{}之前使用等号,其效果与不使用=没有什么区别
自定义类型的列表初始化
看下面这一段代码:
class Point
{
public:
Point(int x = 0, int y = 0) : _x(x), _y(y)
{
cout << "Point()" << endl;
}
private:
int _x;
int _y;
};
int main()
{
Point p1(1, 2);
//c++11写法,最好不要这么写,但应该看懂,知道这么写什么意思。
Point p2{ 1, 2 };
Point p3 = { 1,2 };
return 0;
}p1,p2,p3都可以被成功初始化吗?
答案是可以的!而且都是调用构造函数进行初始化。我们可以运行一下:
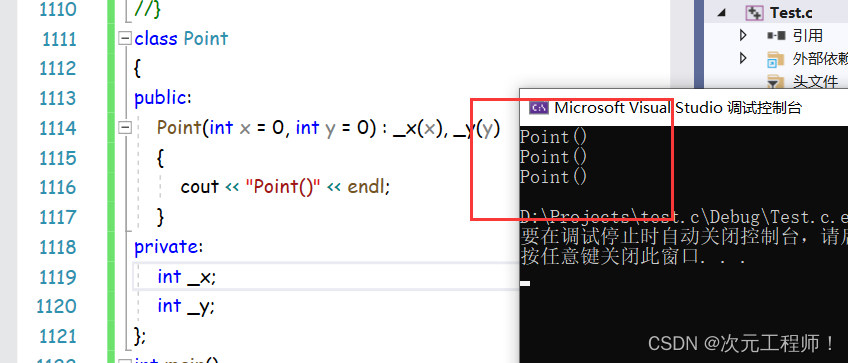
可以发现构造函数确实被调用了3次。
其实理论上说,p2和p3的{1,2}都应该先调用构造函数,然后调用拷贝构造给p2和p3,但编译器会直接优化成直接调用构造函数,相当于p1.
那说了半天,{}到底是个什么呢,也是个数据类型吗?
是的!它的名称是initializer_list,它也是一种数据类型。我们可以验证一下:
int main()
{
auto x = { 1,2,3,4,5,6 };
cout << typeid(x).name() << endl;
} 而且库中对initializer_list也有说明:
而且库中对initializer_list也有说明:
那它具体怎么用呢?库中提供了这些函数:
begin(),end()这些,它可以像迭代器一样去使用。下面这个用例也说明了这个用法:

for循环可以迭代器似的访问initializer_list里面的数据,
那么vector是如何支持它的呢?

以及list,map等等,全部都支持了。
所有的容器都支持这样的一个构造函数,所以我们才可以使用列表初始化。
int main()
{
//这里本质调用支持list(initializer_list<value_type> il类似这样的构造函数。
vector<int> v{ 1,2,3,4,5 };
}当然我们可以这样使用:
class Point
{
public:
Point(int x = 0, int y = 0) : _x(x), _y(y)
{
cout << "Point()" << endl;
}
int _x;
int _y;
};
int main()
{
vector<Point> vp{ {1,2},{3,4} };
for (auto e : vp)
{
cout << e._x << " " << e._y << endl;
}
}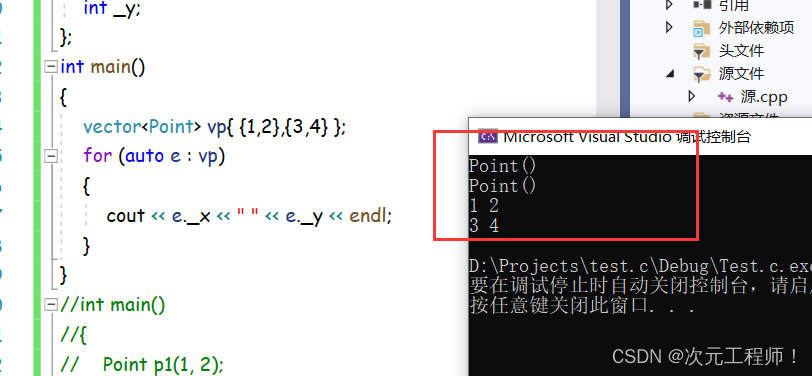
可以看到已经成功初始化了。
或者这样:
Point p1 = { 1,2 };
Point p2 = { 3,4 };
vector<Point> vp{ p1,p2};两种方法都可以,map用来来会更加舒服一些。
总结:C++11以后一切对象都可以用列表初始化。但是建议普通对象用以前的方式初始化,容器如果有需求的话可以使用初始化列表。
变量类型推导
auto
在定义变量时,必须先给出变量的实际类型,编译器才允许定义,但有些情况下可能不知道需要实际类型怎么给,或者类型写起来特别复杂,比如:
short a = 32670;
short b = 32670;
// c如果给成short,会造成数据丢失,如果能够让编译器根据a+b的结果推导c的实际类型,就不会存在问题.
short c = a + b;
auto d = a + b;
cout << c << endl;
cout << d << endl;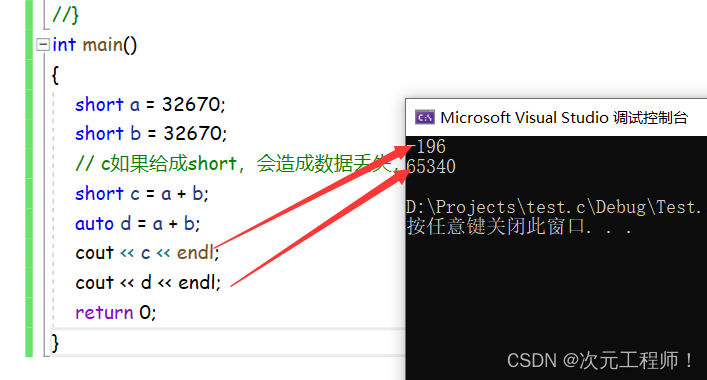
可以看到auto的结果是正确的。
还有一种情况是数据类型过于繁琐,很长.
std::map<std::string, std::string> m{ {"apple", "苹果"}, {"banana","香蕉"} };
// 使用迭代器遍历容器, 迭代器类型太繁琐( std::map<std::string, std::string>::iterator )
std::map<std::string, std::string>::iterator it = m.begin();
while (it != m.end())
{
cout << it->first << " " << it->second << endl;
++it;
}这个数据类型(std::map<std::string, std::string>::iterator)这么长,写起来未免让人有些难受。所以我们直接改成auto即可.
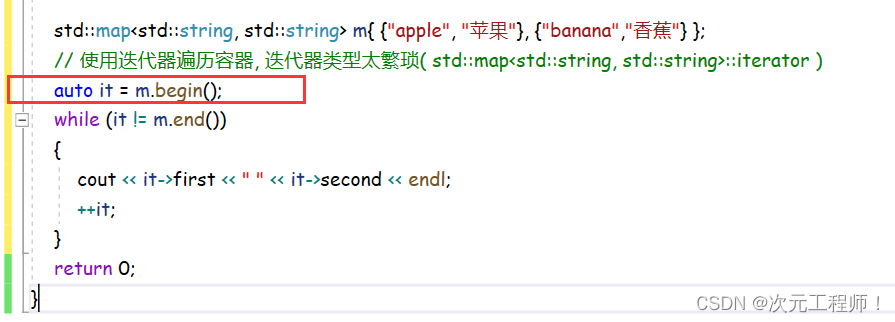
这样也看起来很简洁,唯一不足的就是可能可读性会稍差一些。
decltype
decltype是什么?
decltype是根据表达式的实际类型推演出定义变量时所用的类型.
它和typeid().name()和auto有什么区别呢?
先说和typeid().name()的区别:
typeid().name()可以得出变量或表达式的数据类型,但是不能利用推出的这个数据类型定义别的变量。
而decltype不仅可以得出变量或表达式的数据类型,而且还可以利用推出的这个数据类型定义新的变量。
例如:
int x = 1;
int y = 1;
cout << typeid(x + y).name() << endl;
//错误,typeid推出的数据类型不可以定义新的变量
typeid(x + y).name() z = x + y;
//正确,decltype推出的数据类型可以定义新的变量
decltype(x + y) z = x + y;
cout << z << endl;和auto的区别
decltype是根据其他表达式或变量推出的数据类型,进而来定义变量。
而auto是根据自身的表达式而推出的数据类型。
这个说法可能不太准确,但是意思确实是这样的。可以看下面的例子理解:
int x = 1;
//decltype是根据x推出的类型为int,所以z1类型为int
decltype(x) z1 = 20.23;
//auto是根据自身20.23自动推出类型为double,所以z2类型为double
auto z2 = 20.23;
cout << z1 << endl;
cout << z2 << endl;看完这些,相信大家已经对decltype的概念理解了吧。
总的来说,decltype可以根据推导出的类型去定义新的变量。
nullptr
在之前,C++中的NULL被定义成了字面量0,这可能会带来一些问题,因为0既能表示指针常量,又能表示整型常量。
比如有有两个重载函数,一个函数参数类型是int,另一个是int*.
而你传入参数NULL,按我们理解来说,应该是调用参数为int*的这个函数,而编译器不会,它会嗲用参数为int的这个函数,这就会出现一些问题.
所以出于安全和清晰的考虑,C++11增加了新的关键字nullptr,用于表示空指针。
内部是((void*)0).
范围for循环
这个建议大家参考我之前写的C++入门基础下有详细的语法和用法,这里就不再过多赘述。
final和override
这个也是建议大家参考我写的C++多态中,有对这两个关键字的用法的详细说明
默认成员函数的控制
在C++中对于空类编译器会生成一些默认的成员函数,比如:构造函数、拷贝构造函数、运算符重载、析构函数和&和const&的重载、移动构造、移动拷贝构造等函数。如果在类中显式定义了,编译器将不会重新生成默认版本。有时候这样的规则可能被忘记,最常见的是声明了带参数的构造函数,必要时则需要定义不带参数的版本以实例化无参的对象。而且有时编译器会生成,有时又不生成,容易造成混乱,于是C++11让程序员可以控制是否需要编译器生成.
显式缺省函数
在C++11中,可以在默认函数定义或者声明时加上=default,从而显式的指示编译器生成该函数的默认版本,用=default修饰的函数称为显式缺省函数.
class A
{
public:
A(int a) : _a(a)
{}
// 显式缺省构造函数,由编译器生成
A() = default;
// 在类中声明,在类外定义时让编译器生成默认赋值运算符重载
A& operator=(const A& a);
private:
int _a;
};
A& A::operator=(const A& a) = default;
int main()
{
A a1(10);
A a2;
a2 = a1;
return 0;
}删除默认函数
如果能想要限制某些默认函数的生成,在C++98中,是该函数设置成private,并且不给定义,这样只要其他人想要调用就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
class A
{
public:
A(int a) : _a(a)
{}
// 禁止编译器生成默认的拷贝构造函数以及赋值运算符重载
A(const A&) = delete;
A& operator(const A&) = delete;
private:
int _a;
};
int main()
{
A a1(10);
// 编译失败,因为该类没有拷贝构造函数
//A a2(a1);
// 编译失败,因为该类没有赋值运算符重载
A a3(20);
a3 = a2;
return 0;
}本章先到此结束了,这只是C++的一小部分,而且不算的上很重要,后面我们讲右值引用,智能指针时会进行更加详细的讲解。这些也是重中之重。