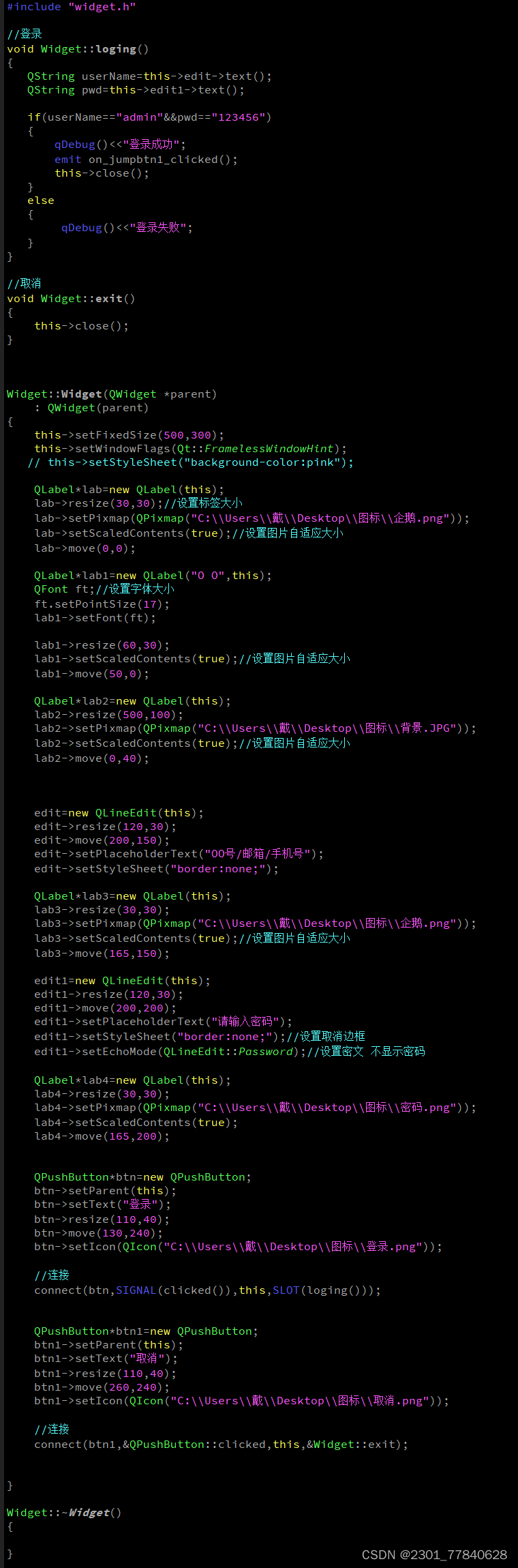
目录
一、Series对象
1.1 认识Series对象
1.2 Series对象的索引
1.3 获取Series的索引和值
二、DataFrame对象
2.1 认识DataFrame对象
2.2 DataFrame重要属性和函数
三、导入外部数据
3.1 导入.xls或.xlsx文件
3.2 导入csv文件
3.3 导入.txt文本文件
3.4 导入HTML网页
Pandas是数据分析三大剑客之一,是Python的核心数据分析库,它提供了快速、灵活、明确的数据结构,能够简单、直观、快速地处理各种类型的数据。Pandas提供的两个主要数据结构Series(一维数组结构)与DataFrame(二维数组结构),可以处理金融、统计、社会科学、工程等领域里的大多数典型案例,并且Pandas是基于NumPy开发的,可以与其他第三方科学计算库完美集成。
一、Series对象
Pandas是Python数据分析重要的库,而Series和DataFrame是Pandas库中两个重要的对象,也是Pandas中两个重要的数据结构。

Series是Python的Pandas库中的一种数据结构,它类似一维数组,由一组数据以及与这组数据相关的标签(即索引)组成,或者仅有一组数据没有索引也可以创建一个简单的Series。Series可以存储整数、浮点数、字符串、Python对象等多种类型的数据。
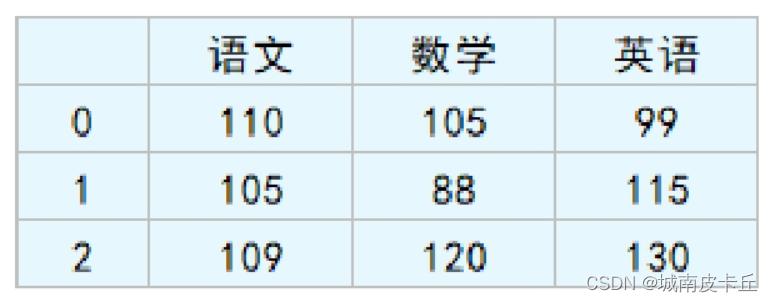
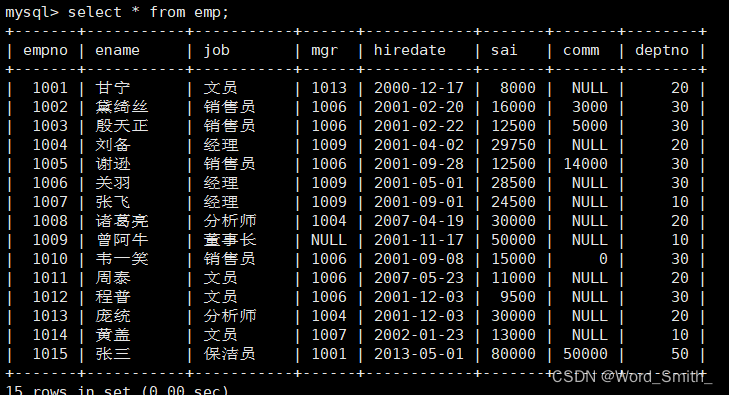
例如,在成绩表(见上图)中包含了Series对象和DataFrame对象,其中“语文”“数学”“英语”3列中的每一列均是一个Series对象,而“语文”“数学”“英语”3列组成了一个DataFrame对象,见下图

1.1 认识Series对象
创建Series对象主要使用Pandas的Series()方法,语法如下:
s=pd.Series(data,index=index)
- data:表示数据,支持Python字典、多维数组、标量值(即只有大小,没有方向的量。也就是说,只是一个数值,如s=pd.Series(5))
- index:表示行标签(索引)
- 返回值:Series对象。
- 当data参数是多维数组时,index长度必须与data长度一致。如果没有指定index参数,则自动创建数值型索引(从0~data数据长度-1)
例如在上述成绩表中添加一列“物理”’成绩
import pandas as pd
s=pd.Series([98,56,86])
print(s)1.2 Series对象的索引
创建Series对象时会自动生成整数索引,默认值从0开始至数据长度减1。除了使用默认索引,还可以通过index参数手动设置索引。
s1=pd.Series([98,56,86],index=['王五','赵六','小七'])
s2=pd.Series([98,67,55],index=[1,2,3])
print(s1)
print(s2)
Series对象的位置索引是从0开始数,[0]是Series第一个数,[1]是Series第二个数
s1=pd.Series([98,56,86],index=['王五','赵六','小七'])
print(s1[1])#输出Series第二个数

但是,需要注意Series不能使用[-1]定位索引。
Series标签索引与位置索引方法类似,用[ ]表示,里面是索引名称,注意index的数据类型是字符串,如果需要获取多个标签索引值,用[[ ]]表示(相当于[ ]中包含一个列表)。
例如,通过标签索引“王五”和“赵六”获取物理成绩,程序代码如下:
import pandas as pd
s1=pd.Series([98,56,86],index=['王五','赵六','小七'])
print(s1['王五'])#通过一个标签索引获取索引值
import pandas as pd
s1=pd.Series([98,56,86],index=['王五','赵六','小七'])
print(s1['王五'])#通过一个标签索引获取索引值
print(s1[['王五','赵六']])#通过多个标签索引获取索引值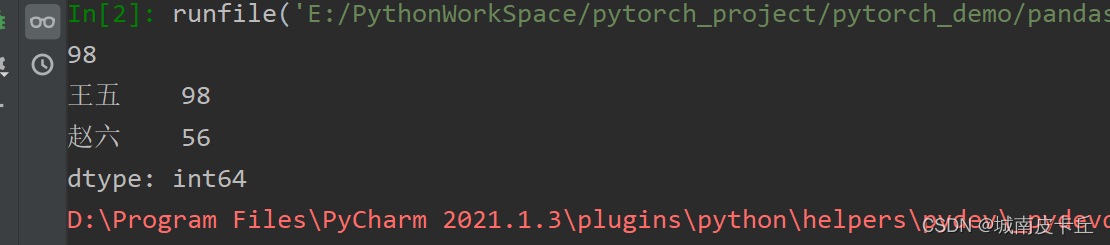
用标签索引做切片,包头包尾(即包含索引开始位置的数据,也包含索引结束位置的数据)。例如通过标签切片索引“王五”至“赵六”获取数据。程序代码如下:
s1=pd.Series([98,56,86],index=['王五','赵六','小七'])
print(s1["王五":"赵六"])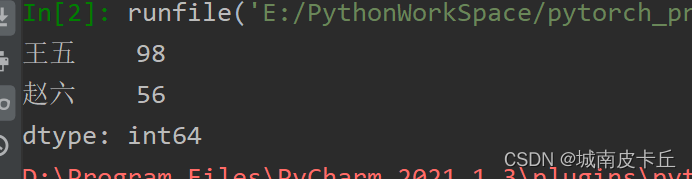
用位置索引做切片,和list列表用法一样,包头不包尾(即包含索引开始位置的数据,不包含索引结束位置的数据)
s2=pd.Series([12,4,23,12,45,67])
print(s2[1:4])#通过位置切片1~4获取数据
1.3 获取Series的索引和值
下面使用Series的index和values方法获取物理成绩的索引和值
s3=pd.Series([89,90,67,99])
print(s3.index)
print(s3.values)
二、DataFrame对象
DataFrame是Pandas库中的一种数据结构,它是由多种类型的列组成的二维表数据结构,类似于Excel、SQL或Series对象构成的字典。DataFrame是最常用的Pandas对象,它与Series对象一样支持多种类型的数据。
2.1 认识DataFrame对象
DataFrame是一个二维表数据结构,由行、列数据组成的表格。DataFrame既有行索引也有列索引,它可以看作是由Series对象组成的字典,不过这些Series对象共用一个索引。

处理DataFrame表格数据时,用index表示行或用columns表示列更直观。用这种方式迭代DataFrame的列,代码更易读懂。下面遍历DataFrame数据,输出成绩表的每一列数据,程序代码如下:
data=[[110,105,99],[105,88,115],[109,120,130]]
index=[0,1,2]
columns=['语文','数学','英语']
#创建DataFrame
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
#遍历DataFrame数据的每一列
for col in df.columns:
series=df[col]
print(series)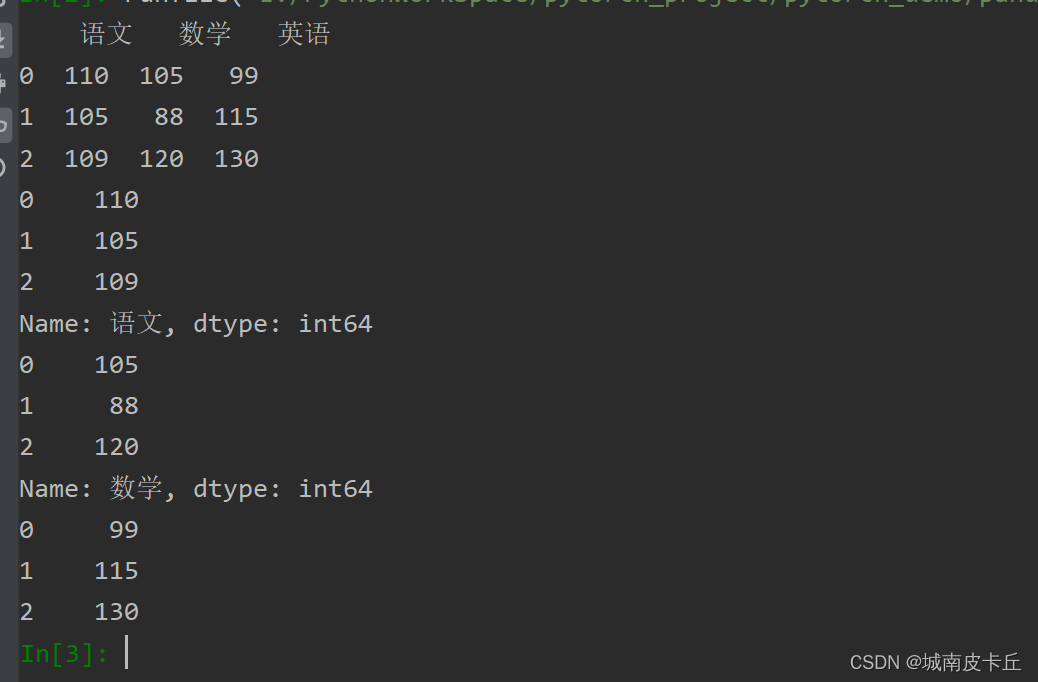
创建DataFrame主要使用Pandas的DataFrame()方法,语法如下:
pandas.DataFrame(data,index,columns,dtype,copy)
- data:表示数据,可以是ndarray数组、Series对象、列表、字典等。
- index:表示行标签(索引)。
- columns:列标签(索引)。
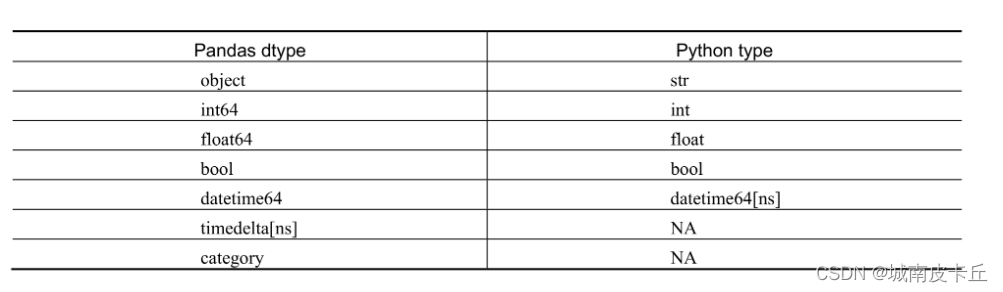
- dtype:每一列数据的数据类型,其与Python数据类型有所不同,如object数据类型对应的是Python的字符型。下表为Pandas数据类型与Python数据类型的对应表。
- copy:用于复制数据。
- 返回值:DataFrame
下面通过两种方法来创建DataFrame,即通过二维数组创建和通过字典创建。
(1)通过二维数组创建成绩表,包括语文、数学和英语,程序代码如下:
pd.set_option('display.unicode.east_asian_width',True)
data=[[110,105,99],[105,88,115],[109,120,130]]
index=[0,1,2]
columns=['语文','数学','英语']
#创建DataFrame
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
(2)通过字典创建DataFrame
通过字典创建DataFrame,需要注意:字典中的value值只能是一维数组或单个的简单数据类型,如果是数组,要求所有数组长度一致;如果是单个数据,则每行都添加相同数据。
通过字典创建成绩表,包括语文、数学、英语和班级,程序代码如下:
pd.set_option('display.unicode.east_asian_width',True)
df=pd.DataFrame({
'语文':[110,105,99],
'数学':[105,88,115],
'英语':[109,120,130],
'班级':"高二一班"
},index=[0,1,2])
print(df)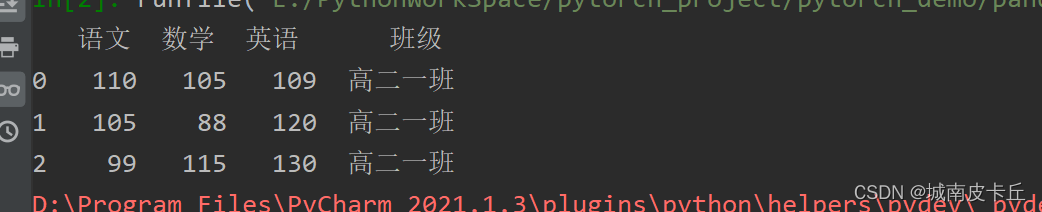
上述代码中,“班级”的value值是一个单个数据,所以每一行都添加了相同的数据“高二一班”。
2.2 DataFrame重要属性和函数
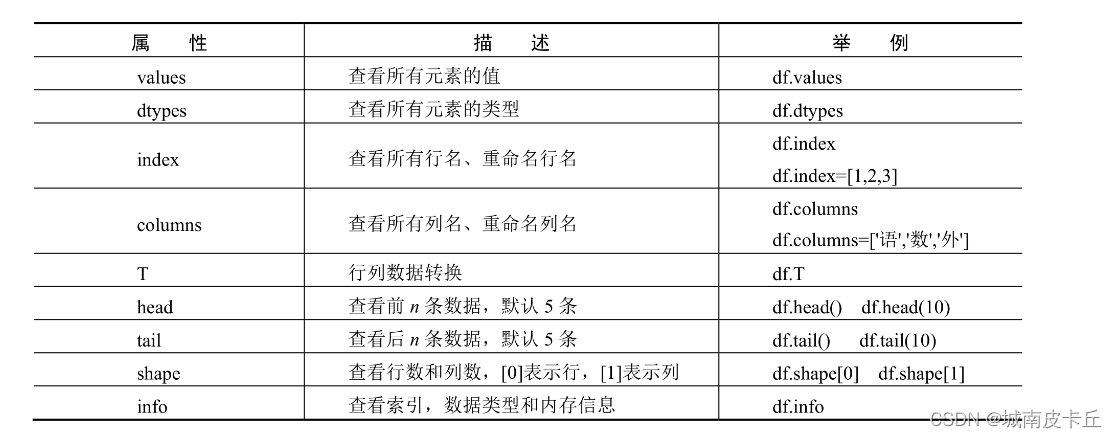
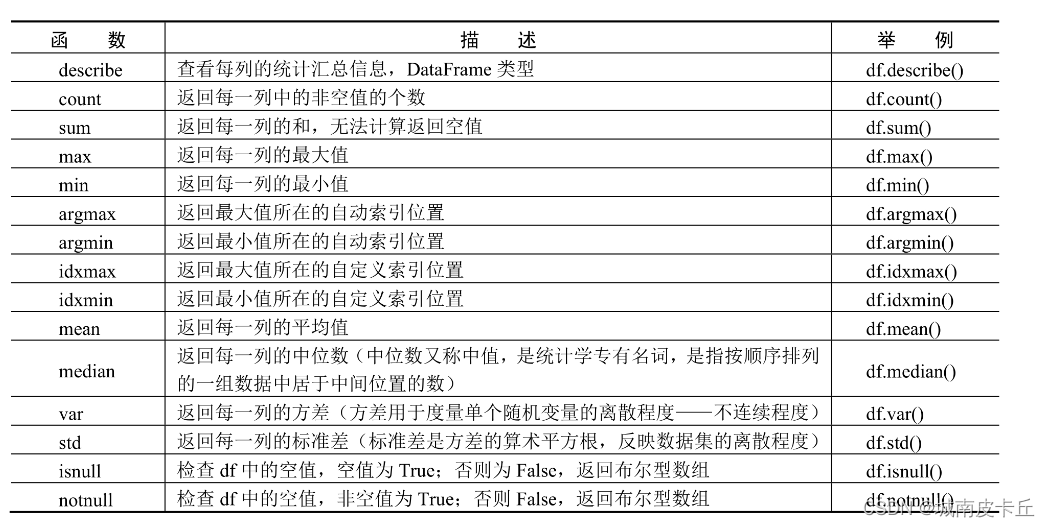
DataFrame是Pandas一个重要的对象,它的属性和函数很多,下面先简单了解DataFrame的几个重要属性和函数。重要属性,重要函数介绍如下表所示。
 三、导入外部数据
三、导入外部数据
数据分析首先就要有数据。那么,数据类型有多种,本节介绍如何导入不同类型的外部数据。
3.1 导入.xls或.xlsx文件
导入.xls或.xlsx文件主要使用Pandas的read_excel()方法,语法如下:
pandas.read_excel(io,sheet_name=0,header=0,names=None,index_col=None,usecols=None,squeeze=False,
dtype=None,engine=None,converters=None,true_values=None,false_values=None,skiprows=None,nrow=None,
na_values=None,keep_default_na=True,verbose=False,parse_dates=False,date_parser=None,thousands=None,
comment=None,skipfooter=0,conver_float=True,mangle_dupe_cols=True,**kwds)io:字符串,.xls或.xlsx文件路径或类文件对象
sheet_name:None、字符串、整数、字符串列表或整数列表,默认值为0。字符串用于工作表名称,整数为索引表示工作表位置,字符串列表或整数列表用于请求多个工作表,为None时获取所有工作表。参数值如下表

- header:指定作为列名的行,默认值为0,即取第一行的值为列名。数据为除列名以外的数据;若数据不包含列名,则设置header=None
- names:默认值为None,要使用的列名列表
- index_col:指定列为索引列,默认值为None,索引0是DataFrame的行标签
- usecols:int、list列表或字符串,默认值为None。如果为None,则解析所有列。如果为int,则解析最后一列。如果为list列表,则解析列号列表的列。如果为字符串,则表示以逗号分隔的Excel列字母和列范围列表(例如“A:E”或“A,C,E:F”)。范围包括双方
- squeeze:布尔值,默认值为False,如果解析的数据只包含一列,则返回一个Series
- dtype:列的数据类型名称或字典,默认值为None。例如{'a':np.float64,'b':np.int32}
- skiprows:省略指定行数的数据,从第一行开始。
- skipfooter:省略指定行数的数据,从尾部数的行开始
(1) 常规导入
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\12\1月.xlsx")
print(df.head())
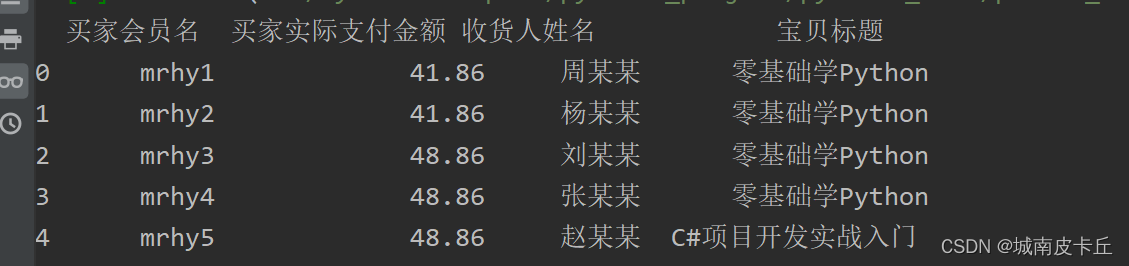
导入外部数据,必然要涉及路径问题,下面来了解一下相对路径和绝对路径。
- 相对路径:相对路径就是以当前文件为基准进行一级级目录指向被引用的资源文件。以下是常用的表示当前目录和当前目录的父级目录的标识符。
../:表示当前文件所在目录的上一级目录
./:表示当前文件所在的目录(可以省略)
/:表示当前文件的根目录(域名映射或硬盘目录)
如果使用系统默认文件路径\,那么,在Python中则需要在路径最前面加一个r,以避免路径里面的\被转义。
- 绝对路径:绝对路径是文件真正存在的路径,是指从硬盘的根目录(盘符)开始,进行一级级目录指向文件。
(2)导入指定的Sheet页
一个Excel文件包含多个Sheet页,通过设置sheet_name参数就可以导入指定Sheet页的数据。
一个Excel文件包含多家店铺的销售数据,导入其中一家店铺(莫寒)的销售数据,如下图所示:
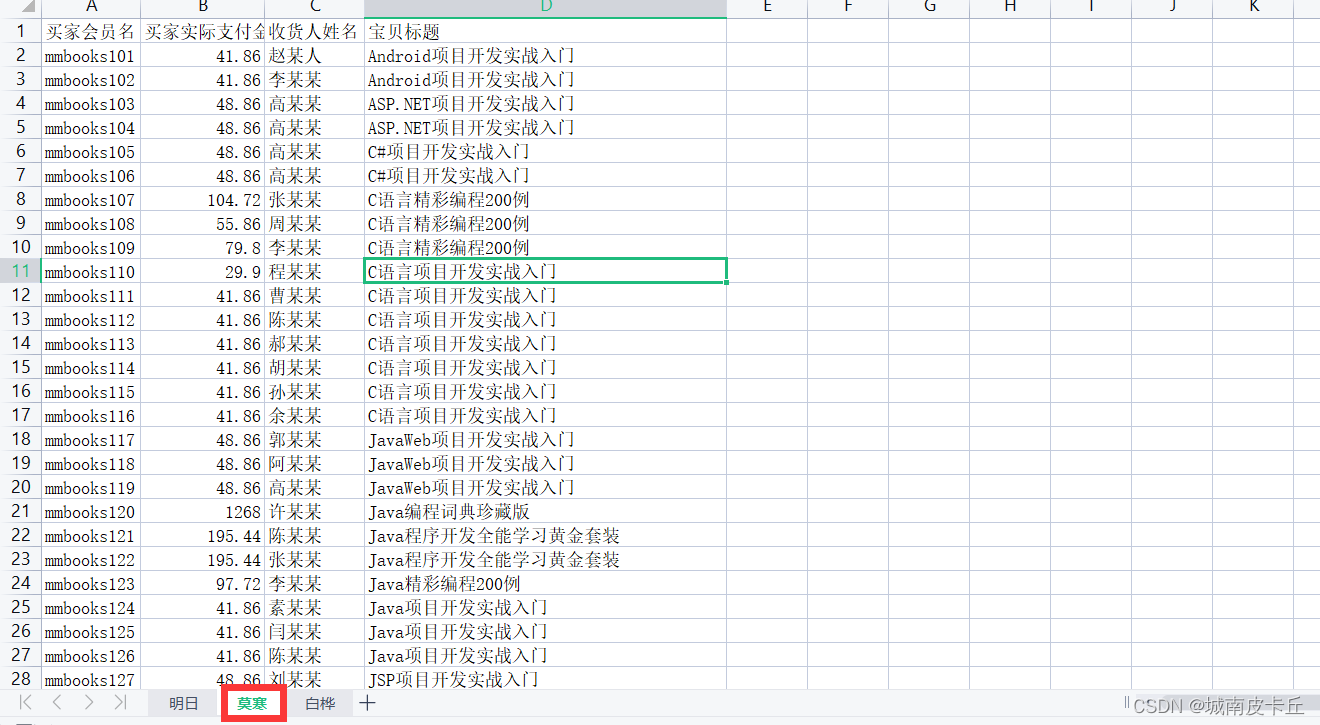
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\13\1月.xlsx",sheet_name='莫寒')
print(df.head())
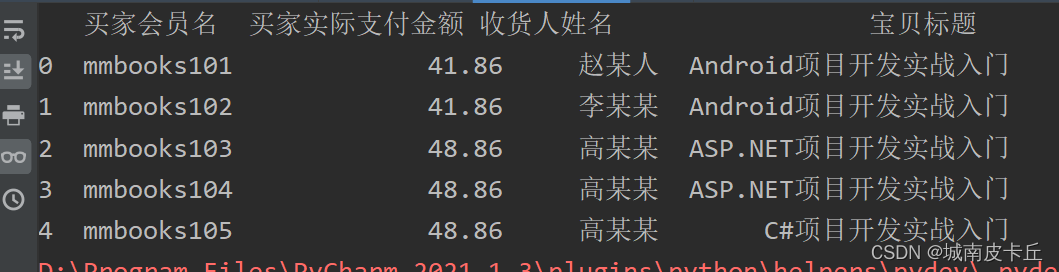
除了指定Sheet页的名字,还可以指定Sheet页的顺序,从0开始。例如,sheet_name=0表示导入第一个Sheet页的数据,sheet_name=1表示导入第二个Sheet页的数据,以此类推。如果不指定sheet_name参数,则默认导入第一个Sheet页的数据。
(3)通过行、列索引导入指定行、列数据
DataFrame是二维数据结构,因此它既有行索引又有列索引。当导入Excel数据时,行索引会自动生成,如0、1、2;而列索引则默认将第0行作为列索引(如A,B,…,J)。DataFrame行、列索引的示意图如下图所示。
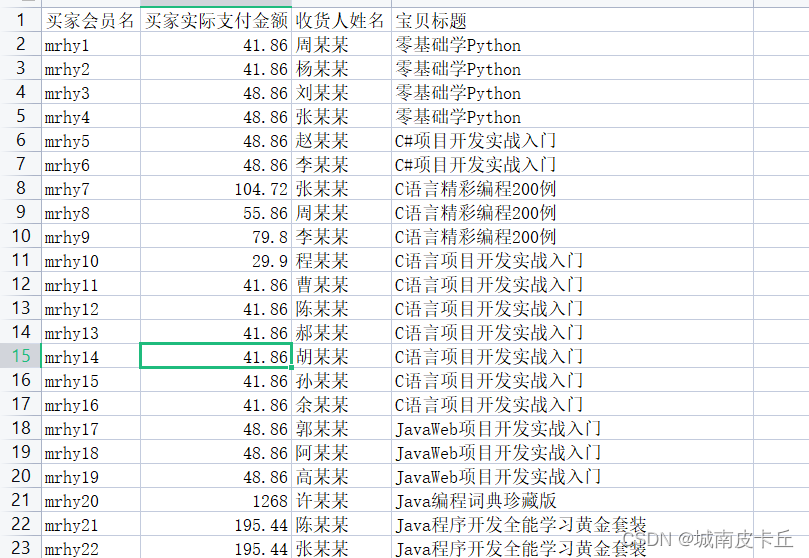
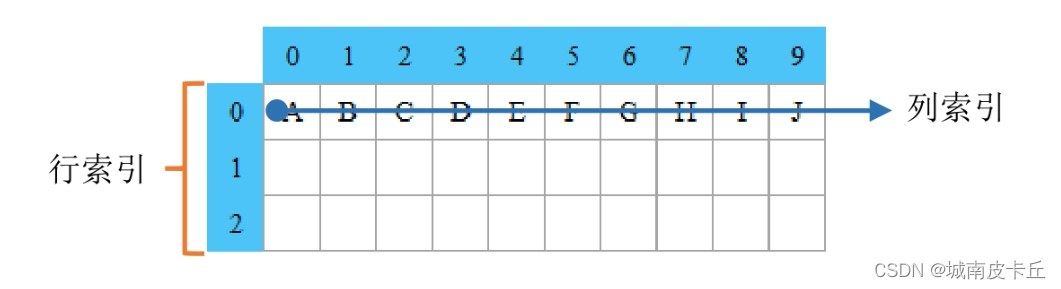
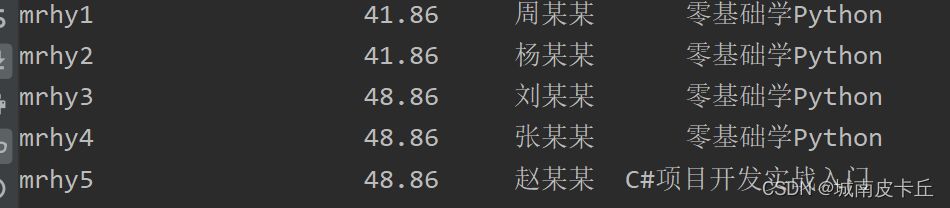
如果通过指定行索引导入Excel数据,则需要设置index_col参数。下面将“买家会员名”作为行索引(位于第0列),导入Excel数据,程序代码如下
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\14\1月.xlsx",index_col=0)
print(df.head())
如果通过指定列索引导入Excel数据,则需要设置header参数,主要代码如下:
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\14\1月.xlsx",header=1)
#设置第一行为列索引
print(df.head())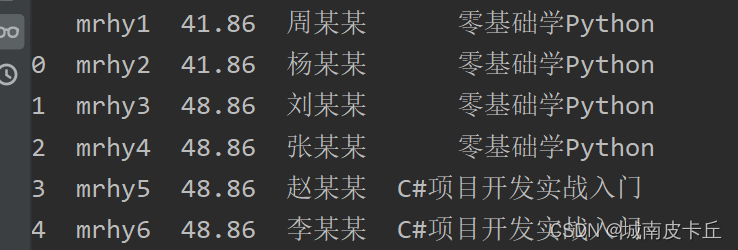
如果将数字作为列索引,可以设置header参数为None,主要代码如下:
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\14\1月.xlsx",header=None)
#设置列索引为数字
print(df.head())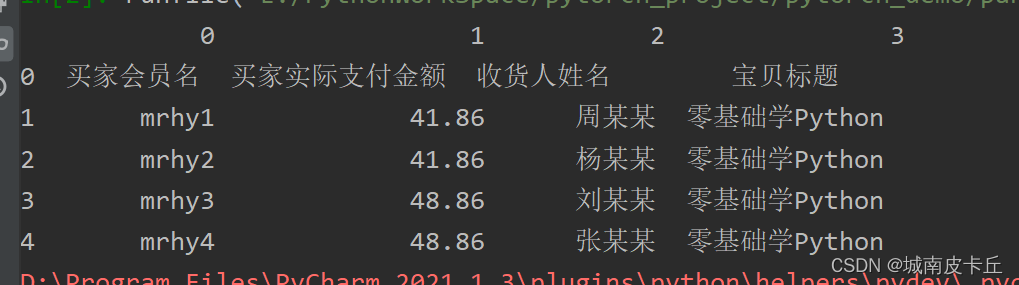 那么,为什么要指定索引呢?因为通过索引可以快速地检索数据,例如df3[0],就可以快速检索到“买家会员名”这一列数据。
那么,为什么要指定索引呢?因为通过索引可以快速地检索数据,例如df3[0],就可以快速检索到“买家会员名”这一列数据。
(4)导入指定列数据
一个Excel往往包含多列数据,如果只需要其中的几列,可以通过usecols参数指定需要的列,从0开始(表示第1列,以此类推)。
例如导入第一列数据(索引为0):
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\15\1月.xlsx",usecols=[0])
#导入第一列
print(df.head())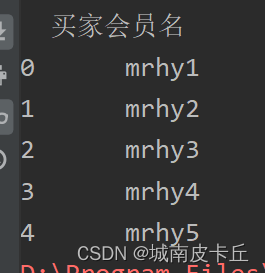
如果导入多列,可以在列表中指定多个值。例如,导入第1列和第4列,主要代码如下:
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\15\1月.xlsx",usecols=[0,3])
#导入第一列
print(df.head())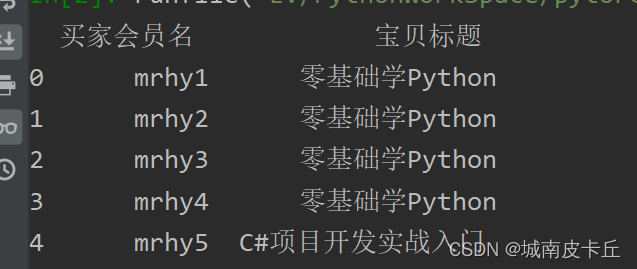
也可以指定列名称,主要代码如下:
df=pd.read_excel(r"C:\Users\zex\Desktop\MR\Code\03\15\1月.xlsx",usecols=['买家会员名','宝贝标题'])
#导入第一列
print(df.head())
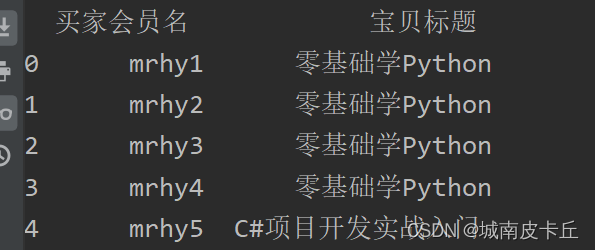
3.2 导入csv文件
导入.csv文件主要使用Pandas的read_csv()方法,语法如下:

- filepath_or_buffer:字符串,文件路径,也可以是URL链接
- sep、delimiter:字符串,分隔符
- header:指定作为列名的行,默认值为0,即取第1行的值为列名。数据为除列名以外的数据;若数据不包含列名,则设置header=None
- names:默认值为None,要使用的列名列表
- index_col:指定列为索引列,默认值为None,索引0是DataFrame的行标签。
- usecols:int、list列表或字符串,默认值为None。如果为None,则解析所有列。如果为int,则解析最后一列。如果为list列表,则解析列号列表的列。如果为字符串,则表示以逗号分隔的Excel列字母和列范围列表(例如“A:E”或“A,C,E:F”)。范围包括双方。
- dtype:列的数据类型名称或字典,默认值为None。例如{'a':np.float64,'b':np.int32}
- parse_dates:布尔类型值、int类型值的列表、列表或字典,默认值为False。可以通过parse_dates参数直接将某列转换成datetime64日期类型。例如,df1=pd.read_csv('1月.csv', parse_dates=['订单付款时间'])。parse_dates为True时,尝试解析索引。 parse_dates为int类型值组成的列表时,如[1,2,3],则解析1、2、3列的值作为独立的日期列。parse_date为列表组成的列表,如[[1,3]],则将1、3列合并,作为一个日期列使用。parse_date为字典时,如{'总计':[1, 3]},则将1、3列合并,合并后的列名为“总计”。
- encoding:字符串,默认值为None,文件的编码格式。Python常用的编码格式是UTF-8
例如,导入csv文件,代码如下
df=pd.read_csv(r"C:\Users\zex\Desktop\MR\Code\03\16\1月.csv",encoding="GBK")
print(df.head())
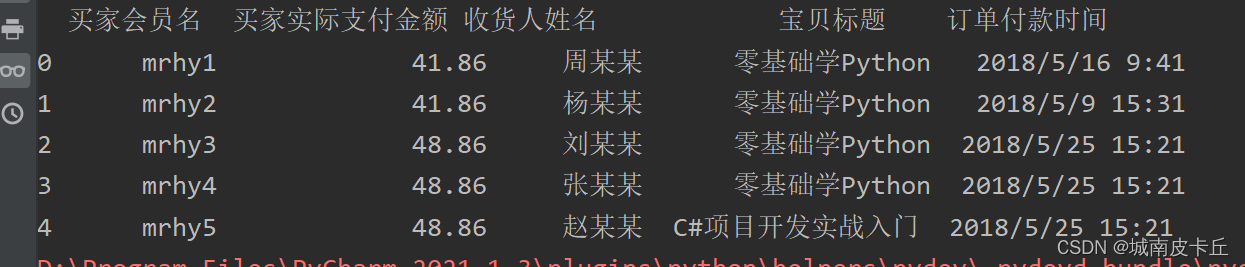
注意,上述代码中指定了编码格式,即encoding='gbk'。Python常用的编码格式是UTF-8和gbk,默认编码格式为UTF-8。导入.csv文件时,需要通过encoding参数指定编码格式。当将Excel文件另存为.csv文件时,默认编码格式为gbk,此时当编写代码导入.csv文件时,就需要设置编码格式为gbk,与源文件编码格式保持一致;否则会提示错误。
3.3 导入.txt文本文件
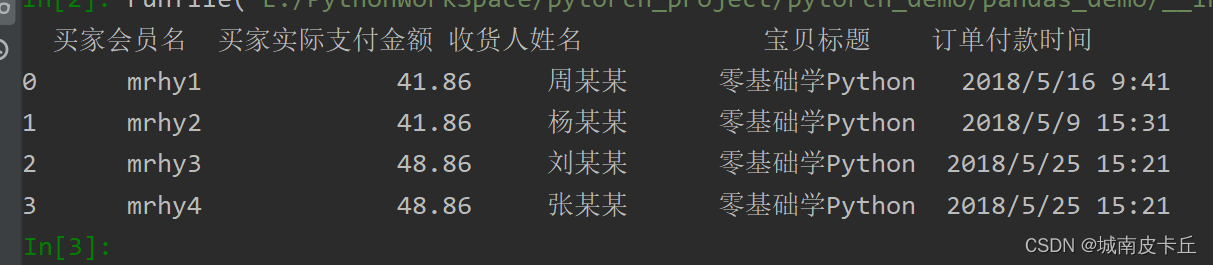
导入.txt文件同样使用Pandas的read_csv()方法,不同的是需要指定sep参数(如制表符\t)。read_csv()方法读取.txt文件返回一个DataFrame,像表格一样的二维数据结构
df=pd.read_csv(r"C:\Users\zex\Desktop\MR\Code\03\17\1月.txt",sep='\t',encoding="GBK")
print(df.head())
3.4 导入HTML网页
导入HTML网页数据主要使用Pandas的read_html()方法,该方法用于导入带有table标签的网页表格数据,语法如下:

- io:字符串,文件路径,也可以是URL链接。网址不接受https,可以尝试去掉https中的s后爬取,如http://www.mingribook.com
- match:正则表达式,返回与正则表达式匹配的表格
- flavor:解析器默认为lxml
- header:指定列标题所在的行,列表list为多重索引
- index_col:指定行标题对应的列,列表list为多重索引
- encoding:字符串,默认为None,文件的编码格式
- 返回值:返回一个DataFrame
使用read_html()方法前,首先要确定网页表格是否为table类型。例如,NBA球员薪资网页(http://www.espn.com/nba/salaries),右击该网页中的表格,在弹出的快捷菜单中选择“检查元素”命令,查看代码中是否含有表格标签<table>…</table>的字样,确定后才可以使用read_html()方法。




![[NOI2014] 随机数生成器(模拟+贪心)](https://img-blog.csdnimg.cn/14190904ddd04d929c8b64d1437a1f47.png)