AA-RMVSNet,论文名为:AA-RMVSNet: Adaptive Aggregation Recurrent Multi-view Stereo Network,CVPR2021(CCF A)
本文是MVSNet系列的第9篇,建议看过【论文精读1】MVSNet系列论文详解-MVSNet之后再看便于理解。
一、问题引入

二、解决思路

三、论文模型
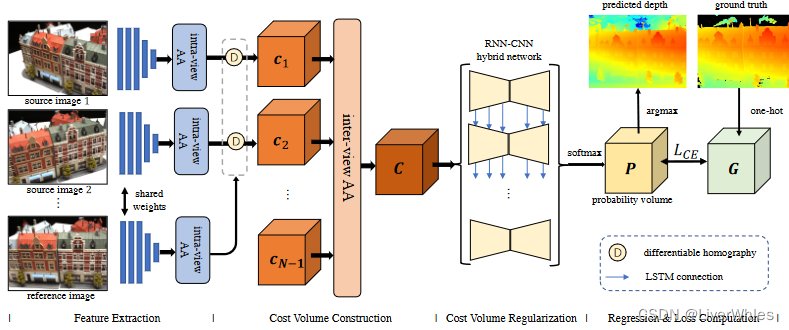
相比RMVSNet主要有三处改变:
- 在特征提取部分增加视图内自适应聚合模块(intra-view Adaptive Aggregation)
- 在代价体构建部分增加视图间自适应聚合模块(inter-view Adaptive Aggregation)
- 在代价体正则化部分讲GRU改为RNN-CNN hybrid network结构
1.特征提取 【视图内自适应聚合模块(intra-view Adaptive Aggregation)】
动机:三维重建中使用普通CNN(使用固定的2D网格感受野)提取特征时,经常会在反射、低纹理或无纹理区域出现问题,希望可以使这些区域的卷积感受野大一些、在纹理丰富的区域感受野小一些——可变形卷积核,图例如下:

为了在不同纹理丰富度的区域采样使用不同尺度的特征,设计视图内自适应聚合模块(inra-view AA)如下:
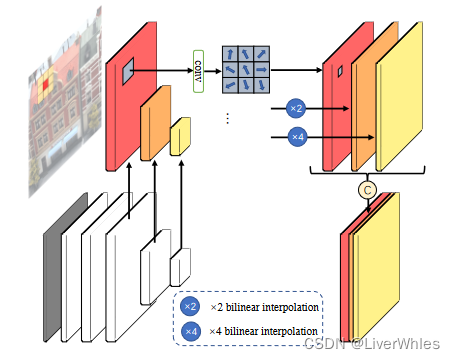
- 特征提取的Encoder部分(灰白色部分)产生不同尺寸(1,1,1,1,1/2,1/4)和通道数(8,16,16,16,16)的特征图
- 将后三层尺度为[H, ,W, 16]、[H/2, ,W/2, 16]、[H/4, ,W/4, 16]的特征图分别送入3个使用可变形卷积核(3x3)、参数不共享的卷积层
- 将三个特征层的输出尺度分别为[H, ,W, 16]、[H/2, ,W/2, 8]、[H/4, ,W/4, 8],进行x1,x2,x4的双线性插值来统一尺度为[H, ,W, 16(8)],并使用Concatenation操作进行连接最终得到[H, ,W, 16+8+8]的特征图。
以上过程通过公式表述和实现为
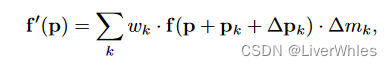
其中f(p)表示像素点p上的特征,wk和pk分别为普通卷积层中卷积核参数和固定偏移量,Δpk和Δmk为通过可变形卷积层网络自适应产生的偏移和调整权重,f’(p)为该点3层可变形卷积并插值、cancat之后对应最终的特征。
2.代价体构建 【视图间自适应聚合模块(inter-view Adaptive Aggregation)】
在上一步结合intra-view AA模块构建出各视图的特征图之后,按照正常的单应变化可以构建单个特征体,论文当中省略了由源视图特征体Fi(i=1,2,…,N-1)与参考视图特征体F0构建单个代价体的步骤,以下直接自N-1个代价体开始进行聚合。
在多个特征体聚合为代价体时增加了视图间自适应聚合模块(inter-view AA),这一步思想应该借鉴了前边PVA-Net的VA模块,出于同样的动机即不同视图由于视角不同可能存在遮挡、光照等变化,所有视图的特征均匀贡献计算代价体则深度估计会存在问题,目的是让各视图的特征在构建代价体时贡献权重不同,只不过与VA模块具体实现稍有差异。
为了让不同视角根据相似程度为本视角下特征赋予不同权重,设计视图间自适应聚合模块(inter-view AA)如下: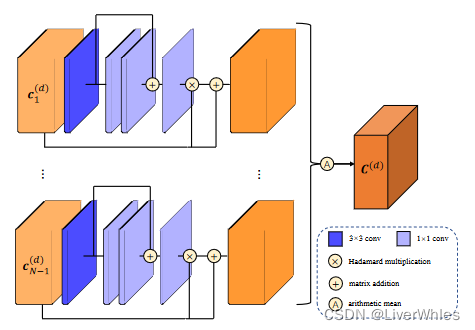
- 使用上一步的得到的各视图特征体c1 — cN-1([H,W,32,D]),沿各深度维度进行切片得到各深度假设下的特征图切片ci(d)([H,W,32])
- 另N-1个视图的特征体沿每个深度方向进行切片,并将切片通过中间通道数分别为4,4,4,1的注意力权重网络最终输出一张逐像素的注意力权重图w,让每个深度切片与其做(1+w)的哈达玛积,即逐像素位置令特征值乘以权重得到结合注意力后的特征体深度切片
- 对N-1个视图同一深度d切片下的注意力特征体求平均,得到最终代价体的深度d切片。
用公式表述和实现上述过程为:
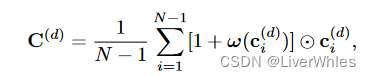
⊙ \odot ⊙表示哈达玛积,w(·)表示注意力权重网络输出的逐像素权重,通过这样最终的代价体上容易混淆匹配的像素将被抑制,而具有关键上下文信息的像素将被赋予更大的权重。
其中使用1+w(·)而不直接使用w(·)的原因是可以避免过度的平滑化。
3.代价体正则化【循环代价体正则化(Recurrent Cost Regularization)】
代价体正则化步骤是利用空间上下文信息,将匹配代价转为在D个深度假设平面上的概率分布(也即概率体),该步骤采用RNN - CNN混合方式来进行正则化。
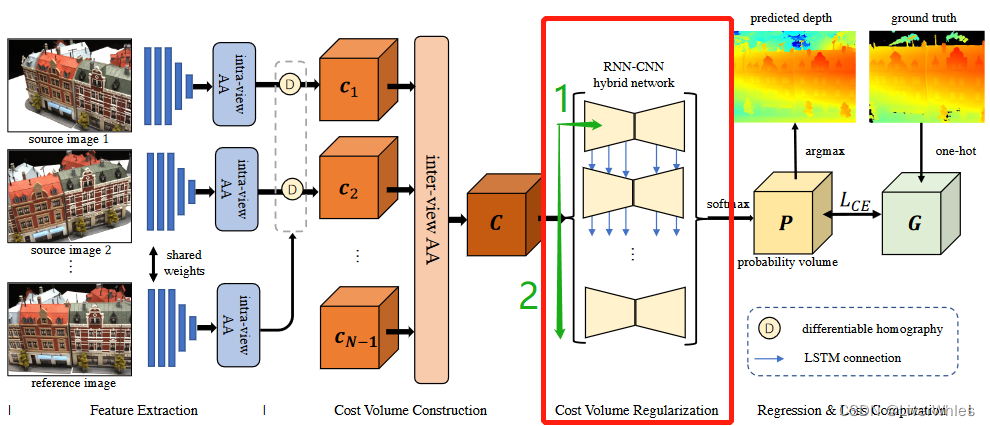
将上一步的代价体((H × W × D x 32))在深度维度上切片出D个深度代价体(H × W × 32):
- 在水平方向,通过2D CNN 使用Encoder-Decoder 结构来聚合空间上下文信息和正则化
- 在垂直方向,通过5个并行的RNN结构来将前一个ConvLSTMCell的中间输出传递给后一个ConvLSTMCell
通过这样的混合网络,既实现了空间上下文和深度方向上的信息聚合与正则化,同时减少了内存消耗(类似RMVSNet原理)
并行RNN中的ConvLSTMCell模块来自论文Dense Hybrid Recurrent Multi-view Stereo Net with Dynamic Consistency Checking(D2HC-RMVSNet),基本就是普通的LSTM模块引入,这里不展开介绍。
4.深度图推断&损失函数
这部分和RMVSNet一致,将深度推断看作逐像素的分类问题,利用交叉熵损失做Loss函数进行训练
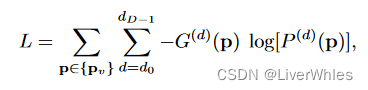
四、实验效果
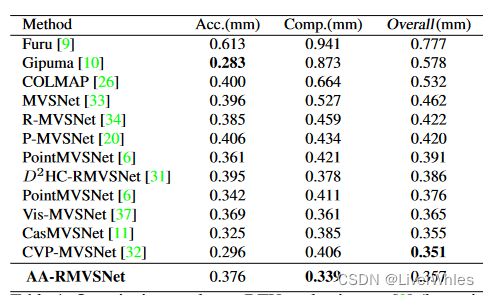
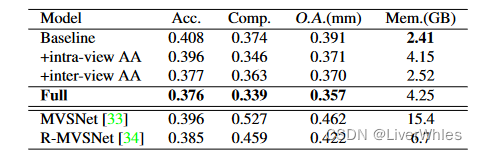
- 在DTU数据集上完整度最好,Overall与最佳的也旗鼓相当。
- 与之前的RMVSNet和D2HC-RMVSNet(同属于使用循环神经网络类)相比在精度和完整性上都有明显改善
- 这里并未与2020年的PVA-Net比较性能,看了一下精准损失低了0.003,完整损失高了0.003,overall持平…下图可视化倒是与PVA-Net进行了比较;也未与2020年的UCS-Net比较,它的精度损失高了0.038,overall损失高了0.013.…也不知是不是未发现😢
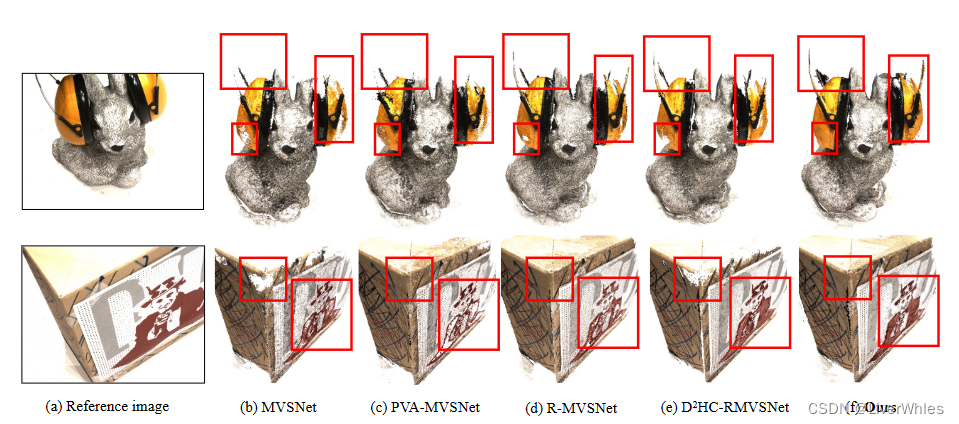
在DTU的可视化结果中可以观察到重建点云更完整,同时对于光照变化、或是边缘细节部分(红框)也恢复的更好。
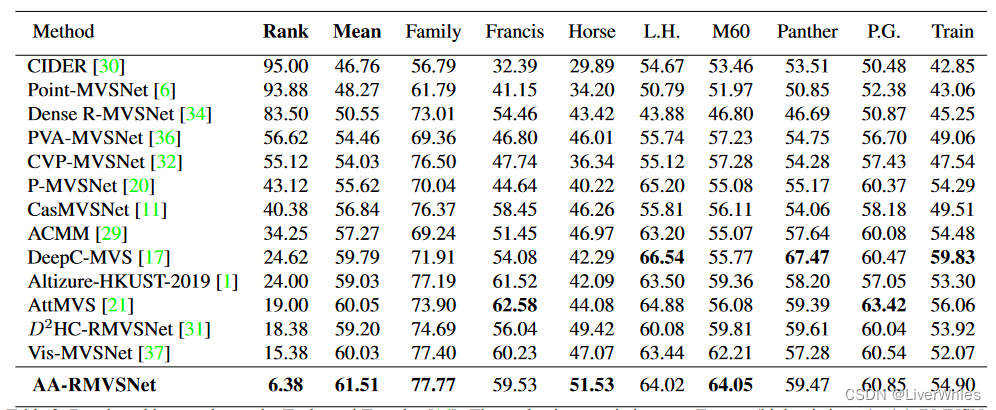
在Tanks数据集上排名第一(Rank是表示所有8个场景的平均度量,是最终排序的依据),相比在DTU上SOTA的CasMVSNet和CVP-MVSNet,在不同的场景下展现出了更强的鲁棒性和泛化性。
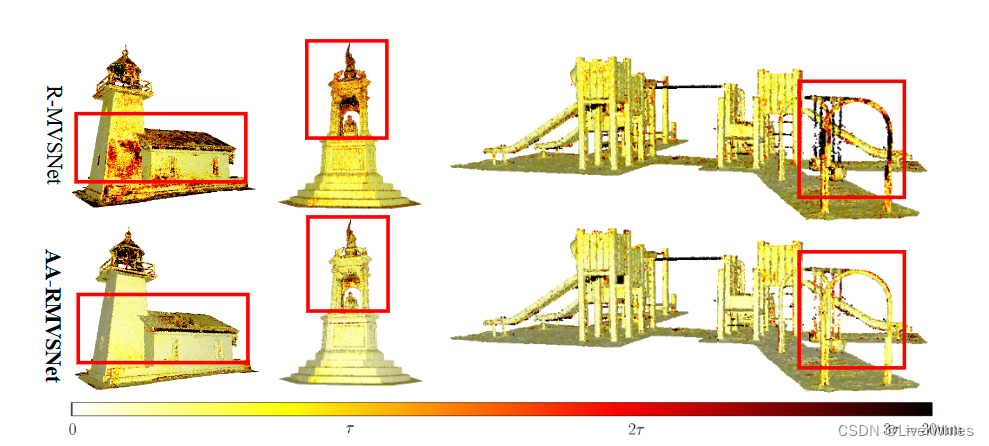
与原始的循环MVS网络RMVSNet相比,AA-RMVSNet提高了整体重建质量,特别是在低纹理平面、遮挡区域和薄物体等具有挑战性的区域,这得益于其稳健的特征提取和视图聚合方法。
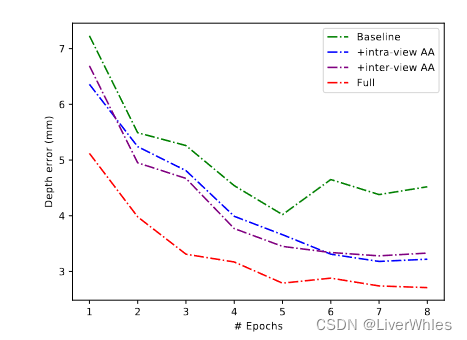
- Baseline使用通用的2D CNN进行特征提取,使用同样的混合LSTM结构进行代价体积正则化,不附加任何额外的模块。
- 消融实验上来看两个聚合模块单独都可以显著降低深度误差,并且这两个模块在全AA - RMVSNet中是互补的,同时使用可以达到最佳性能。
- 从内存消耗上看,intra-view AA 增加了约1.74 GB的内存,将完整性提高了0.28,而inter-view AA 只增加了0.11 GB的内存和0.31的精度,整体误差由0.391下降到0.357。
- 完整的AARMVSNet只需要4.25 GB就可以获得800 × 600分辨率的稠密精确深度图,内存消耗相比RMVSNet更少,但未比较时间消耗😢
五、总结
- 创新点上主要是三点,可变卷积核(intra-view AA)、不同视图代价聚合权重(inter-view AA)、以及代价体正则化的RNN-CNN模块,从效果上来说(intra-view AA)有,但内存消耗增加较多;(inter-view AA)比较有效,但思想其实与PVA-Net中的VA模块相同,只是具体操作方法变了下;RNN-CNN模块作为Baseline相比RMVNet倒是有一些提升。
- 从效果上,只是与2020年的PVA-Net打平,甚至不及UCS-Net,但比较时都未与之比较
- 内存消耗上确实比RMVSNet要少,但并未比较时间消耗
- 总体感觉有创新,但效果不深明显,对比实验上有瑕疵,消融实验融合了内存消耗对比网络模型数量较少,且未比较时间消耗,让人有点怀疑是不是刻意回避不足之处😂





![[附源码]计算机毕业设计常见Web漏洞对应PC应用系统Springboot程序](https://img-blog.csdnimg.cn/dd5be5cf2f784ed7ae4a5023f7aa6eb5.png)


![[附源码]计算机毕业设计贷款申请审核管理系统论文Springboot程序](https://img-blog.csdnimg.cn/f0a73885fe66475ba826e0f6c8ac4f3a.png)